







引言
集成学习:让机器学习效果更好,单个不行,群殴走起。
分类
1. Bagging:训练多个分类器取平均![]() (m代表树的个数)。
(m代表树的个数)。
2.Boosting(提升算法):从弱学习器开始加,通过加权来进行训练。(它与上面的不同在于它不是随机几颗树取平均,而是加入一棵树要比原来强)
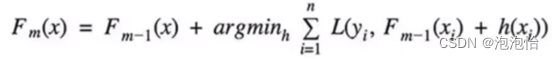
3.Stacking:聚合多个分类或回归模型(可以分阶段来做)
介绍
Bagging全称(bootstrap aggregation)在其算法中训练每一棵树之间是没有影响的,说白了就是并行训练一堆分类器。
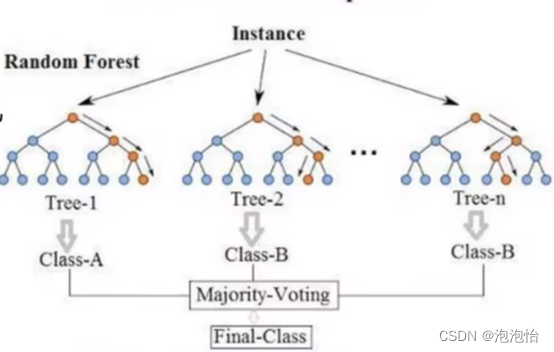
典型代表随机森林:随机代表数据采样随机,特征选择随机,为了避免重复,但算法已经固定为了增加多样性则就是数据的采样要随机。森林代表很多个决策树并行放在一起。
随机森林中分类和回归的做法:
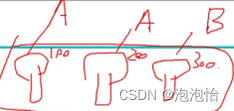
在做分类任务的时候两个类别被分为A一个被分为B,那么则选择少数服从多数最后类别为A。
在做回归任务的时候分别为100、200、300,则最终结果为(100+200+300)/3
随机森林的优点:
1.可解释性强,便于分析。(对于神经网络、深度学习都是黑盒子,我们只能得到输入和输出内部很复杂看不到。)
2.在训练结束,它能够给出特征重要型排序,如下图:
3.并行化方法,速度快
软投票和硬投票
一、硬投票:直接用类别值,少数服从多数
(1)准备数据并且可视化
%matplotlib inline
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X,y=make_moons(n_samples=500,noise=0.30,random_state=42)
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=42)
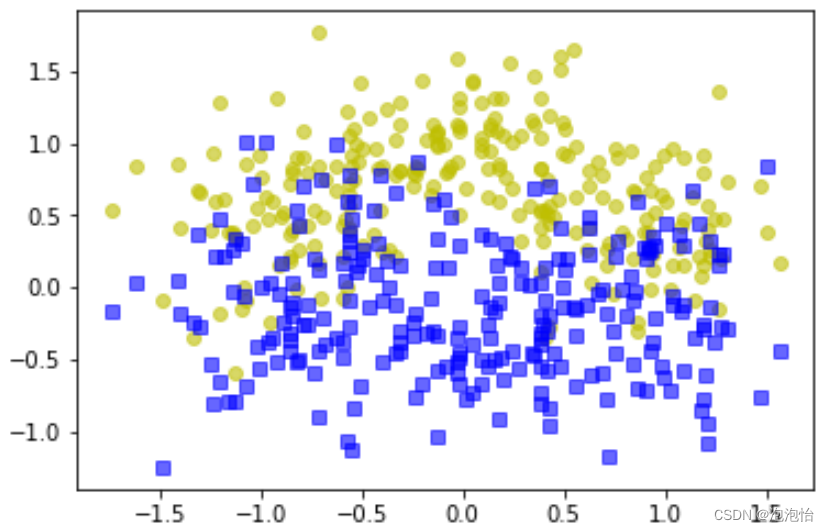
plt.plot(X[:,0][y==0],X[:,1][y==0],'yo',alpha=0.6)#alpha 代表透明程度
plt.plot(X[:,0][y==0],X[:,1][y==1],'bs',alpha=0.6)结果如图所示:
(2)硬投票
from sklearn.ensemble import RandomForestClassifier,VotingClassifier #随机森林和投票器
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
#进行实例化
log_clf=LogisticRegression()
rnd_clf=RandomForestClassifier()
svm_clf=SVC()
voting_clf=VotingClassifier(estimators=[('lr',log_clf),('rf',rnd_clf),('svc',svm_clf)],voting='hard')
voting_clf.fit(X_train,y_train)(3)模型评价
from sklearn.metrics import accuracy_score
for clf in (log_clf,rnd_clf,svm_clf,voting_clf):
clf.fit(X_train,y_train)
y_pred=clf.predict(X_test)
print(clf.__class__.__name__,accuracy_score(y_test,y_pred))结果如下:

二、软投票:各自分类器的概率值进行加权平均
数据不变,只需要将上面代码进行修改。代码如下:
from sklearn.ensemble import RandomForestClassifier,VotingClassifier #随机森林和投票器
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
#进行实例化
log_clf=LogisticRegression()
rnd_clf=RandomForestClassifier()
svm_clf=SVC(probability=True)
voting_clf=VotingClassifier(estimators=[('lr',log_clf),('rf',rnd_clf),('svc',svm_clf)],voting='soft')
voting_clf.fit(X_train,y_train)
from sklearn.metrics import accuracy_score
for clf in (log_clf,rnd_clf,svm_clf,voting_clf):
clf.fit(X_train,y_train)
y_pred=clf.predict(X_test)
print(clf.__class__.__name__,accuracy_score(y_test,y_pred))模型评价结果如图:

明显比上一个效果好。















 5471
5471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









