








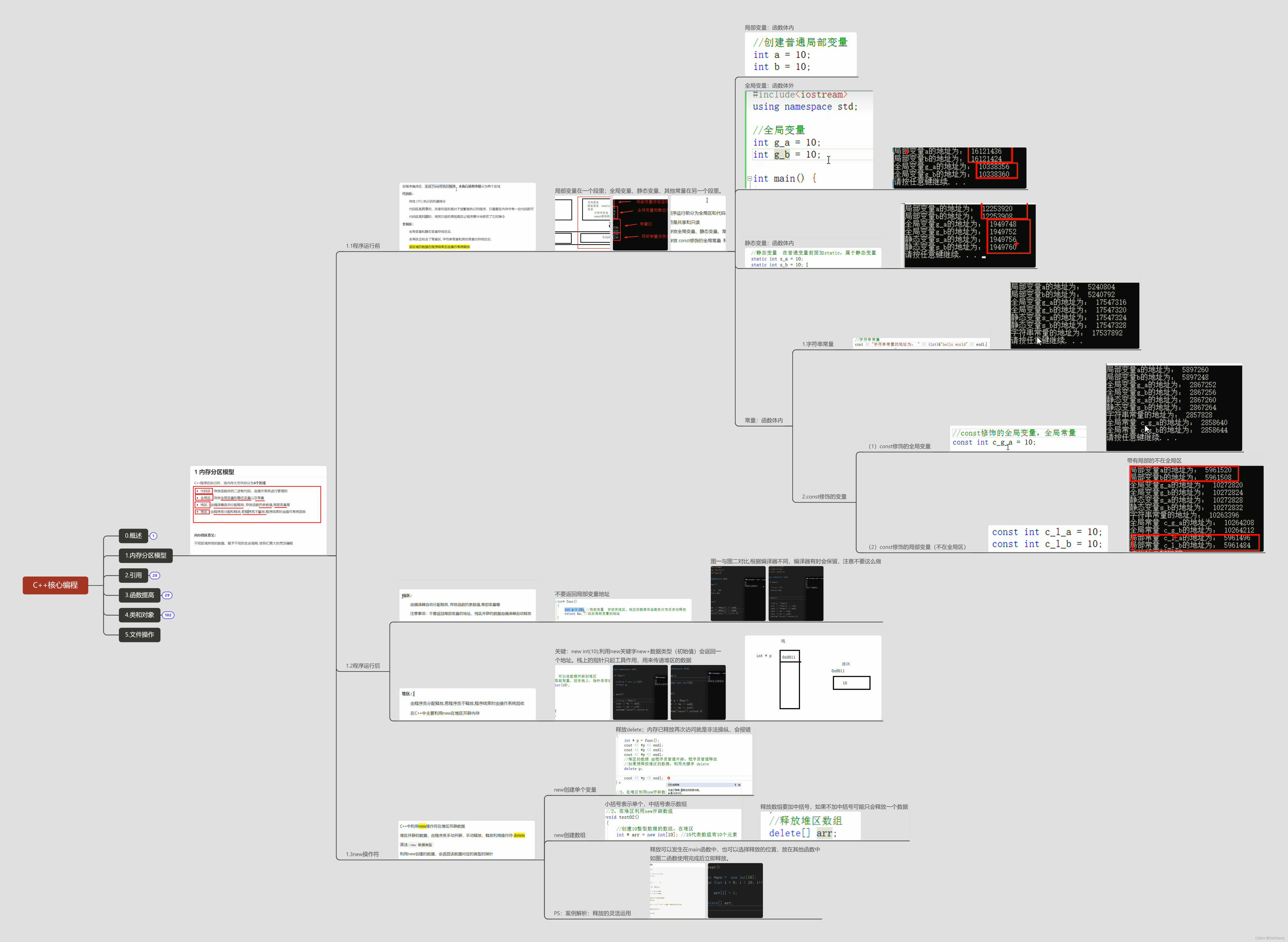
内存分区模型
C++程序在执行时,将内存大方向划分为5个区域
运行前:
-
代码区:存放函数体的二进制代码,由操作系统进行管理的
-
全局区(静态区):存放全局变量和静态变量以及常量
-
常量区:常量存储在这里,不允许修改
运行后:
-
栈区:由编译器自动分配释放, 存放函数的参数值,局部变量等
-
堆区:由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收
内存四区意义:
不同区域存放的数据,赋予不同的生命周期, 给我们更大的灵活编程
程序运行前
分析
在程序编译后,生成了exe可执行程序,未执行该程序前分为两个区域
代码区:
存放 CPU 执行的机器指令
代码区是共享的,共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可
代码区是只读的,使其只读的原因是防止程序意外地修改了它的指令
全局区:
全局变量和静态变量存放在此.
全局区还包含了常量区, 字符串常量和其他常量也存放在此.
==该区域的数据在程序结束后由操作系统释放==.
示例
原理:对比不同类型数据的地址区分区域划分。
//全局变量
int g_a = 10;
int g_b = 10;
//const修饰的全局变量:全局常量
const int c_g_a = 10;
const int c_g_b = 10;
int main() {
//局部变量
int a = 10;
int b = 10;
cout << "局部变量a地址为: " << (int)&a << endl;//(int)将地址信息转成10进制
cout << "局部变量b地址为: " << (int)&b << endl;
cout << "全局变量g_a地址为: " << (int)&g_a << endl;
cout << "全局变量g_b地址为: " << (int)&g_b << endl;
//静态变量
static int s_a = 10;
static int s_b = 10;
cout << "静态变量s_a地址为: " << (int)&s_a << endl;
cout << "静态变量s_b地址为: " << (int)&s_b << endl;
//常量
//1,字符串常量
cout << "字符串常量地址为: " << (int)&"hello world" << endl;
cout << "字符串常量地址为: " << (int)&"hello world1" << endl;
//2.1const修饰的全局变量:全局常量
cout << "全局常量c_g_a地址为: " << (int)&c_g_a << endl;
cout << "全局常量c_g_b地址为: " << (int)&c_g_b << endl;
//2.2const修饰的局部变量
const int c_l_a = 10;
const int c_l_b = 10;
cout << "局部常量c_l_a地址为: " << (int)&c_l_a << endl;
cout << "局部常量c_l_b地址为: " << (int)&c_l_b << endl;
system("pause");
return 0;
}
打印结果:
局部变量在一个段里;全局变量、静态变量、其他常量在另一个段里。

实例刨析:

局部变量:函数体内(栈区)
全局变量:函数体外
静态变量:函数体内(普通变量前加static)
常量:函数体内
1.字符串常量
2.const修饰的变量
(1)const修饰的全局变量:全局常量
(2)const修饰的局部变量(不在全局区;栈区)
总结
-
C++中在程序运行前分为全局区和代码区
-
代码区特点是共享和只读
-
全局区中存放全局变量、静态变量、常量
-
全局区的常量区中存放 const修饰的全局常量 和 字符串常量
易混点
区分静态变量(static)与const修饰的局部变量
程序运行后
栈区分析
栈区:
由编译器自动分配释放, 存放函数的参数值,局部变量等
示例
int * func()
{
int a = 10;//局部变量存放在栈区,栈区的数据在函数执行完成后自动释放。
return &a;//返回局部变量的地址
}
int main() {
int *p = func();
cout << *p << endl;
cout << *p << endl;
system("pause");
return 0;
}
易错点
不要返回局部变量的地址,栈区开辟的数据由编译器自动释放,函数运行结束后函数内的局部变量被释放,将无法使用传回的函数体内的局部变量的地址!
注意:根据编译器不同,编译器有时会保留,但是注意不要这么做!

图片刨析:假设编译器只会保留一次函数体内局部变量的地址,即传出的地址只能调用一次。
如果假设成立,那么*func()的调用将不受次数限制,因为func()每次传回的都是最新的地址,而*p只能调用一次,因为*p经过了局部变量的存储,编译器保留了一次地址后将地址释放之后p地址将失效,无法继续访问。
堆区分析
堆区:
由程序员分配释放,若程序员不释放,程序结束时由操作系统回收
在C++中主要利用new在堆区开辟内存
示例
int* func()
{
int* a = new int(10);//利用new关键字将数据开辟到堆区
return a;//只针的本质是局部变量,放在栈上,指针保存的数据是放在堆区的
}
int main() {
int *p = func();
cout << *p << endl;
cout << *p << endl;
system("pause");
return 0;
}
注意点
int(10)是编译器在栈区暂时虚拟出的一块空间,上图代码int* a表示并给这块内存起名为a,类比与4.2.2构造函数中的匿名对象:Person(10)单独写就是匿名对象(等同于int(10)存于栈上,加上new关键字就存在与堆区了。),特点:当前行结束之后,马上析构,即系统立即回收掉匿名对象。
构造函数相关代码对比:
//1、构造函数分类
// 按照参数分类分为 有参和无参构造 无参又称为默认构造函数
// 按照类型分类分为 普通构造和拷贝构造
class Person {
public:
//无参(默认)构造函数
Person() {
cout << "无参构造函数!" << endl;
}
//有参构造函数
Person(int a) {
age = a;
cout << "有参构造函数!" << endl;
}
//拷贝构造函数
Person(const Person& p) {
age = p.age;
cout << "拷贝构造函数!" << endl;
}
//析构函数
~Person() {
cout << "析构函数!" << endl;
}
public:
int age;
};
//2、构造函数的调用
void test01() {
//2.1 括号法(常用)
Person p1;//调用无参构造函数,默认构造函数的调用
Person p2(10);//有参构造函数
Person p3(p2);//拷贝构造函数
//注意1:调用无参构造函数不能加括号,如果加了编译器认为这是一个函数声明
//Person p2()
//2.2 显式法
Person p2 = Person(10); //相当于给匿名对象Person(10)起个名字叫p2
Person p3 = Person(p2);
//Person(10)单独写就是匿名对象(等同于int(10)存于栈上),特点:当前行结束之后,马上析构,即系统立即回收掉匿名对象。
//2.3 隐式转换法(简化的显示法)
Person p4 = 10; // Person p4 = Person(10);
Person p5 = p4; // Person p5 = Person(p4);
//注意2:不能利用 拷贝构造函数 初始化匿名对象 编译器认为是对象声明
//Person (p5);等同于Person p5;
}
int main() {
test01();
system("pause");
return 0;
}
易错点
new int(10)返回的是地址,需要用指针接收!
总结:
堆区数据由程序员管理开辟和释放
堆区数据利用new关键字进行开辟内存
new操作符
C++中利用==new==操作符在堆区开辟数据
堆区开辟的数据,由程序员手动开辟,手动释放,释放利用操作符 ==delete==
语法:new 数据类型
利用new创建的数据,会返回该数据对应的类型的指针
示例1: 基本语法
int* func()
{
int* a = new int(10);
return a;
}
int main() {
int *p = func();
cout << *p << endl;
cout << *p << endl;
//利用delete释放堆区数据
delete p;
//cout << *p << endl; //报错,释放的空间不可访问
system("pause");
return 0;
}
示例2:开辟数组
//堆区开辟数组
int main() {
int* arr = new int[10];
for (int i = 0; i < 10; i++)
{
arr[i] = i + 100;
}
for (int i = 0; i < 10; i++)
{
cout << arr[i] << endl;
}
//释放数组 delete 后加 []
delete[] arr;
system("pause");
return 0;
}
易错点
释放数组要加中括号,如果不加中括号可能只会释放一个数据!
导图


扩展
而C语言的内存模型分为5个区:栈区、堆区、静态区、常量区、代码区。每个区存储的内容如下:
1、栈区:存放函数的参数值、局部变量等,由编译器自动分配和释放,通常在函数执行完后就释放了,其操作方式类似于数据结构中的栈。栈内存分配运算内置于CPU的指令集,效率很高,但是分配的内存量有限,比如iOS中栈区的大小是2M。
2、堆区:就是通过new、malloc、realloc分配的内存块,编译器不会负责它们的释放工作,需要用程序区释放。分配方式类似于数据结构中的链表。“内存泄漏”通常说的就是堆区。
3、静态区:全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后,由系统释放。
4、常量区:常量存储在这里,不允许修改。
5、代码区:顾名思义,存放代码
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











