






一, 初始数据

数据类型:文本,图片,音频,视频
数据组织形式:文件,数据库
数据的价值:不会因为不断被使用而削减,反而会因为不断重组而产生更大的价值


二、大数据时代
三次信息化浪潮:
| 第一次 | 第二次 | 第三次 |
| 1980年前后 | 1995年 | 2010年 |
| 个人计算机 | 互联网 | 物联网、云计算和大数据 |
| 信息处理 | 信息传输 | 信息爆炸 |

运营式系统阶段:数据库的出现,数据产生方式是被动的;
用户原创内容阶段:web2.0标志是 用户原创内容,数据产生方式是主动的;
感知式系统阶段(最根本):大数据的产生,数据产生方式是自动的;


三、大数据概念
大量化,快速化,多样化,价值


三、Hadoop
1.简介
1)Hadoop为用户提供了系统底层细节透明的分布式基础架构
2)Java开发;可以部署在廉价的计算机集群中;支持多种编程语言;开源
2.发展历史
*Google提出了三个处理大数据的革命性技术手段,分别是:
MapReduce:Google的分布式并行计算框架
BigTable:一个大型的分布式数据库
GFS:Google的分布式文件系统
Nutch的创始人Doug Cutting受到启发,用了若干年时间实现了DFS和MapReduce机制,使Nutch性能飙升。


2.特性
高可靠性(采用冗余数据存贮方式,即使一个副本发生故障,其他副本也可以保证对外工作的正常进行);高效性;高可扩展性(可以很容易将集群扩展到数千个节点的规模);高容错性;成本低;运行在Linux系统;支持多种编程语言


Hadoop组件:HDFS;MapReduce;YARN;Hive;HBase;Pig;Zookeeper;Storm;Flume
3.安装方式:
单机模式:Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
伪分布式模式:Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件
分布式模式:使用多个节点构成集群环境来运行Hadoop



四、HDFS
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的
设计目标:
兼容廉价的硬件设备
流数据读写:批量数据处理
大数据集:PB级别
简单的文件模型: 一次写入,多次读取
强大的跨平台兼容性:基于java
应用局限性:
不适合低延迟数据访问:适合大规模数据批量处理
无法高效存储大量小文件:搜索效率低


1.块:*1.0默认64M
*好处:支持大规模文件存储;简化系统设计;适合数据备份
*块太小的问题:无法有效分摊磁盘的读写开销
*块太大的问题:通常mapreduce的map一次只能处理一个块中的数据,如果块太大,启动的任务太少,会降低作业并行处理速度。
| *名称节点 | *数据节点 |
| 存储元数据 | 存储文件内容 |
| 元数据保存在内存中 | 文件内容保存在磁盘上 |



第二名称节点是“冷备份”
数据节点:1.数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,向名称节点定期发送自己所存储的块的列表。2.每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中.



2.冗余数据保存(一般冗余因子默认是3)
多副本方式具有以下几个优点:
(1)加快数据传输速度
(2)容易检查数据错误
(3)保证数据可靠性
HDFS具有较高的容错性,可以兼容廉价的硬件,它把硬件出错看作一种常态,而不是异常。
名称节点出错;数据节点出错(每个数据节点会定期向名称节点发送“心跳”信息,向名称节点报告自己的状态);数据出错





五、HBase概述
| BigTable | HBase | |
| 文件存储系统 | GFS | HDFS |
| 海量数据处理 | Google,MapReduce | MapReduce |
| 协同管理服务 | Chubby | Zookeeper |
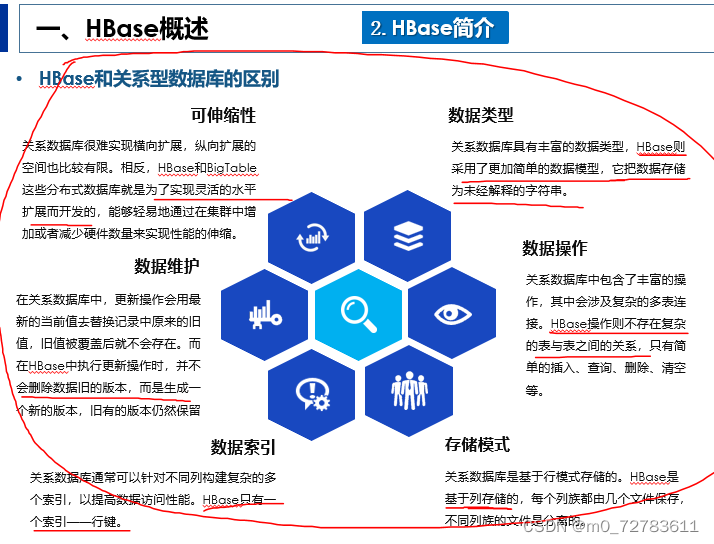
*NoSQL是一种不同于关系数据库的数据库管理系统设计方式,是对非关系型数据库的统称。BigTable和HBase属于列族数据库


*HBase对数据的定位 :四维坐标:行键、列族、列、时间戳
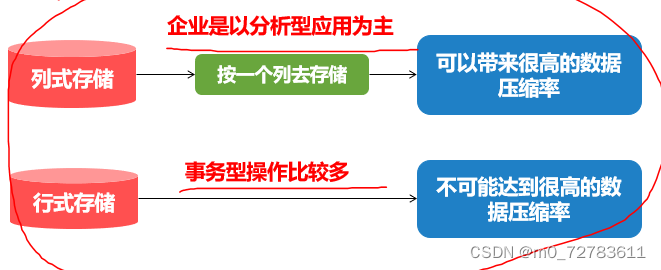
列式存储:



客户端并不依赖于Master去获得位置信息
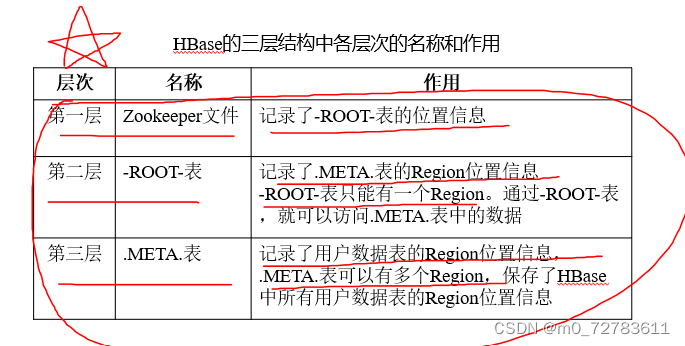
客户端访问数据时需要“三级寻址”,会不会降低数据读写效率?
为了加速寻址,客户端把寻址信息缓存下来,即把用户数据的region信息缓存起来,下次再访问时就不必经过三级寻址的步骤,可以实现更快的访问。


Zookeeper是一个很好的集群管理工具
HBase采用HLog保证系统恢复


行键是按照字典序存储



六、MapReduce
适用场景:批处理、非实时、数据密集型
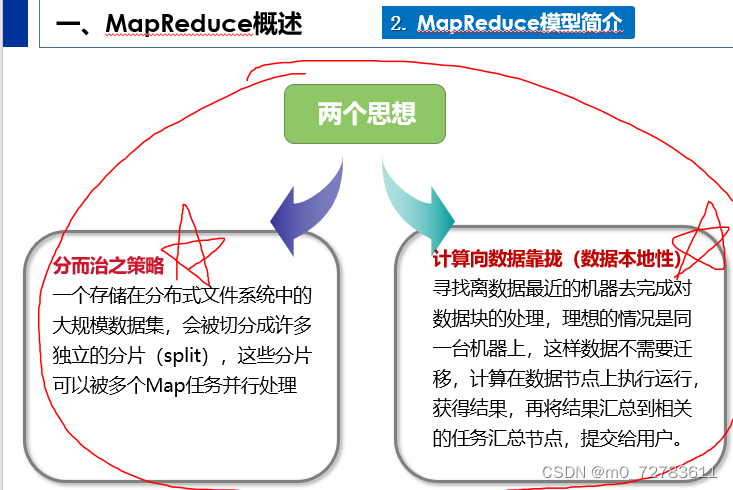
MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave。Master上运行JobTracker,Slave上运行TaskTracker
Hadoop框架是用Java实现的,但是,MapReduce应用程序则不一定要用Java来写







HDFS 以固定大小的block为基本单位存储数据,而对于MapReduce而言,其处理单位是split(分片)。
*大多数情况下,理想的分片大小是一个HDFS块。
排序是默认的操作
JobTracker会一直监测Map任务的执行,并通知Reduce任务来领取数据
*合并(Combine)和归并(Merge)的区别:两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>;如果归并,会得到<“a”,<1,1>>
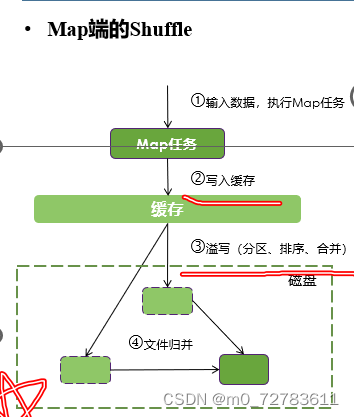
所有的数据交换都是通过MapReduce框架自身去实现的




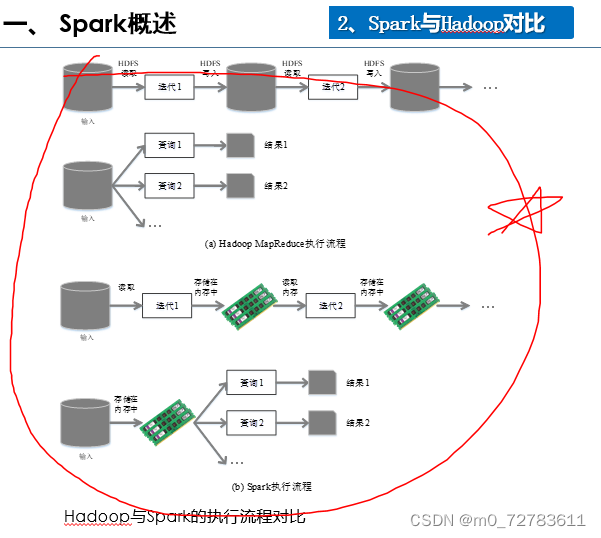
七、Spark
三大分布式计算系统开源项目之一(Hadoop、Spark、Storm)。
特点:运行速度快,运行模式多样,容易使用,通用性
Spark支持scala、Java、Python、R作为编程语言








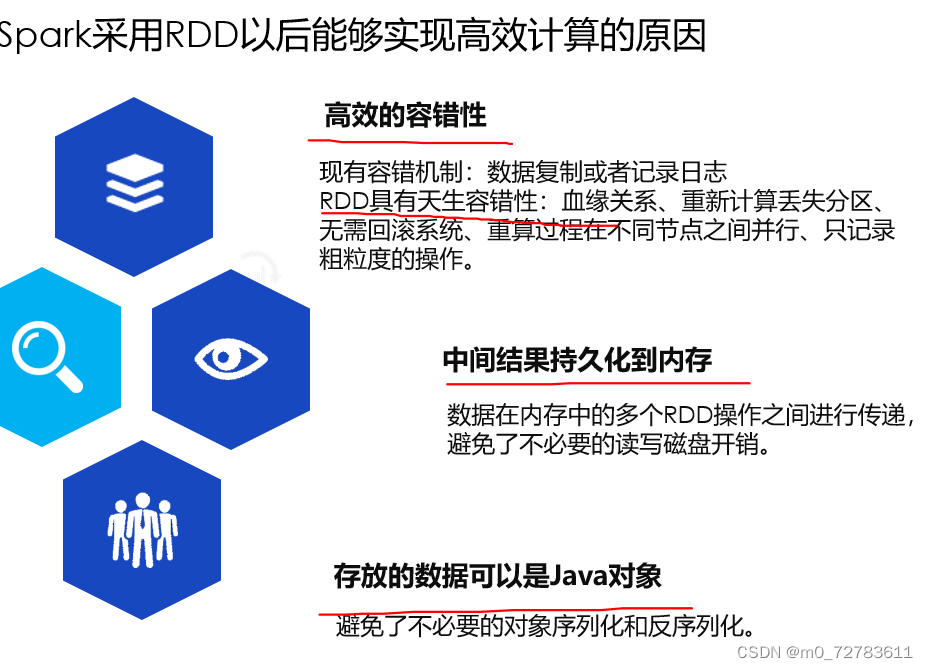
Spark采用RDD以后能够实现高效计算的原因:高效的容错性;中间结果持久化到内存;存放的数据可以是Java对象。





八、大数据影响,应用



-
















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









