






第一章 基础理论
一、DIKW:数据,信息,知识,智慧
二、数据维度:
从数据的结构化程度看:
1.数据化:直接可以用传统关系数据库存储和管理的数据。本质:先有结构,后有数据
2.非结构化:无法用关系数据库存储和管理的数据。本质:没有统一结构的数据
3.半结构化:经过一定转换处理后可以用传统关系数据库存储和管理的数据。本质:先有数据,后有结构。
从数据的加工程度看:
1.零次数据:原始数据
2.一次数据:干净数据(预处理过的数据)
3.二次数据:增值数据(分析处理的结果)
三、大数据的四个维度:速度快(Velocity),数据量大(Volume),类型多(Variety),价值密度低(Value)。
四、数据科学项目的流程: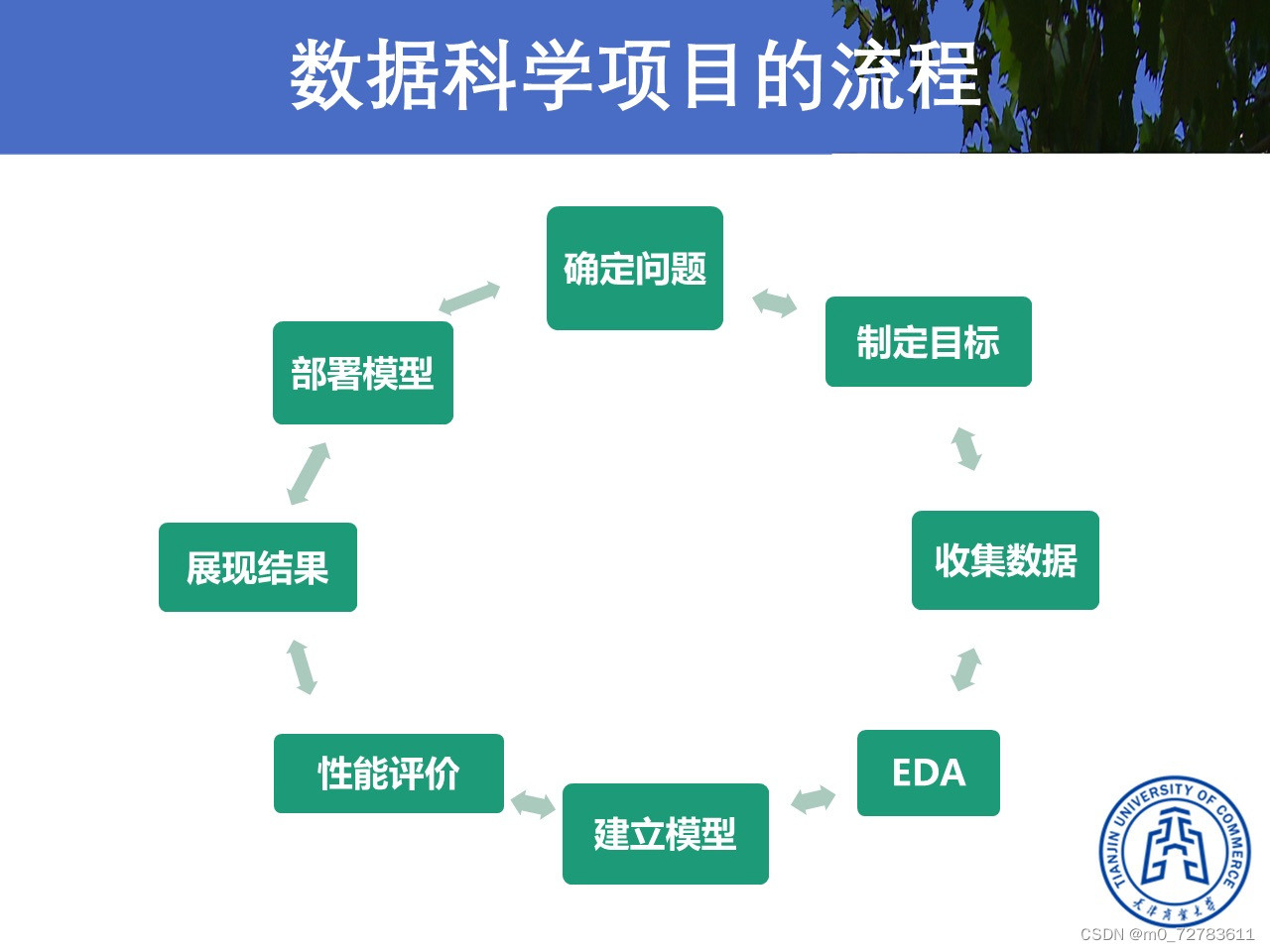
第二章 数据预处理
一、数据鉴别:消息鉴别码(鉴别本身),hash函数(鉴别本身),数字签名(鉴别主体)。
二、探索性数据分析(EDA)指对已有的数据在尽量少的先验假定下进行探索,并通过作图等手段探索数据的结构和规律的一种数据分析方法。
EDA与验证性分析方法的主要区别:
(1)EDA不需要事先假设
(2)EDA采用的方法更简单
(3)在一般数据科学项目中探索性分析在前验证性分析在后。
三、数据审计:
缺失值,噪声值,不一致值,不完整值
四、数据清洗:
缺失数据:丢弃,代替
冗余数据:过滤
噪声数据:*分箱(等深、等宽),聚类,回归
(1)等深分箱:每个箱中的成员个数相同(放的数相同)
例:
(2)等宽分箱:每个箱的取值范围相同
例:
离群点不是噪声数据(噪声 (Noise)是一个观测量中的随机错误或偏差,包括错误的值,偏离期望的孤立点;
离群点(Outlier)属于观测量,既有可能是真实数据产生的,也有可能是噪声带来的,但是总的来说是和大部分观测量之间有明显不同的观测值。)
五、数据变换:
(1)平滑处理:去除噪声数据
(2)特征构造:构造出新的特征
(3)聚集:进行粗粒度计算
(4)标准化(公式)(0-1标准化、z-score标准化):将特征值按比例缩放,使之落入一个特定的区间。
(A)0-1标准化:对原始数据的线性变换,使结果落入[0-1]之间(max和min分别为样本数据的最大值和最小值;x与x*代表标准化处理前的值和处理后的值)
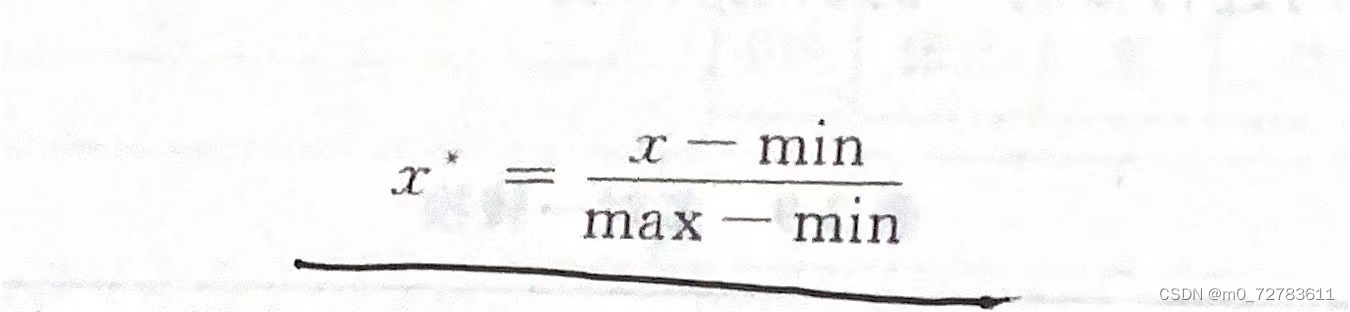
例题:

(B)z-score标准化:(经过处理后满足正态分布,即均值为0.标准差为1。μ为平均数,δ为标准差;x,z分别代表标准化处理前后的值)

例题:

(5)离散化:用去间或概念标签表示数据
第三章 数据统计
一、概率分布:二项分布,泊松分布,正态分布
二、基本分析方法:相关分析,回归分析,分类分析,聚类分析
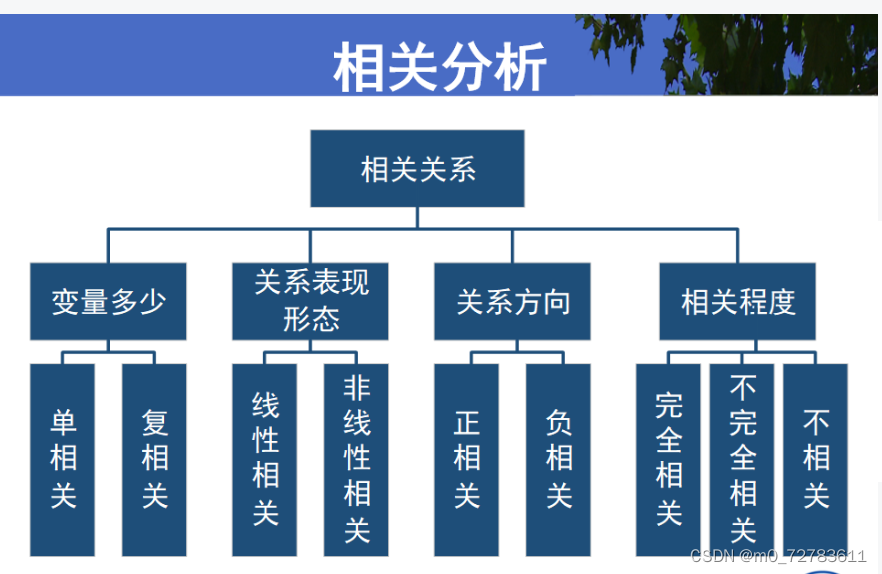
1.相关分析-相关分析的分类:
2.回归方程:一元,多元
(1)一元线性回归:

3.分类分析:
(1)决策树(信息增益、ID3)
(A)信息增益:按照某一属性,划分样本集前后的信息熵之差,信息增益越大,系统不缺定性越小,因此应该选择信息增益最大的属性作为分类依据。
(B)ID3算法:计算信息熵并得到信息增益,以此作为属性判别能力的度量。
4.聚类分析:K-means
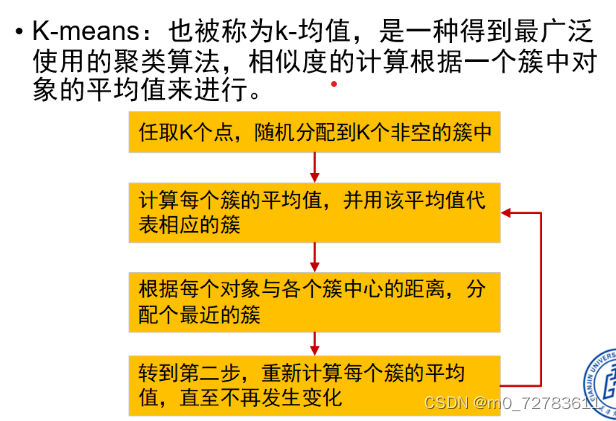 例子:
例子: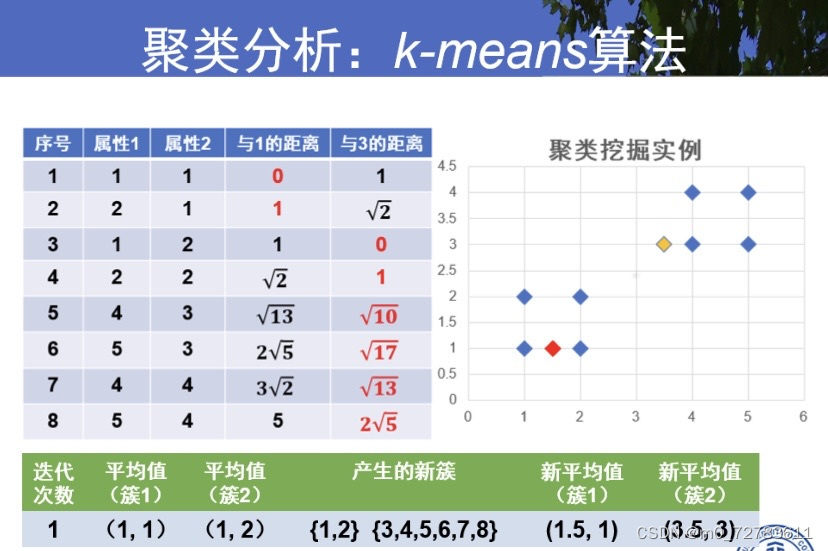

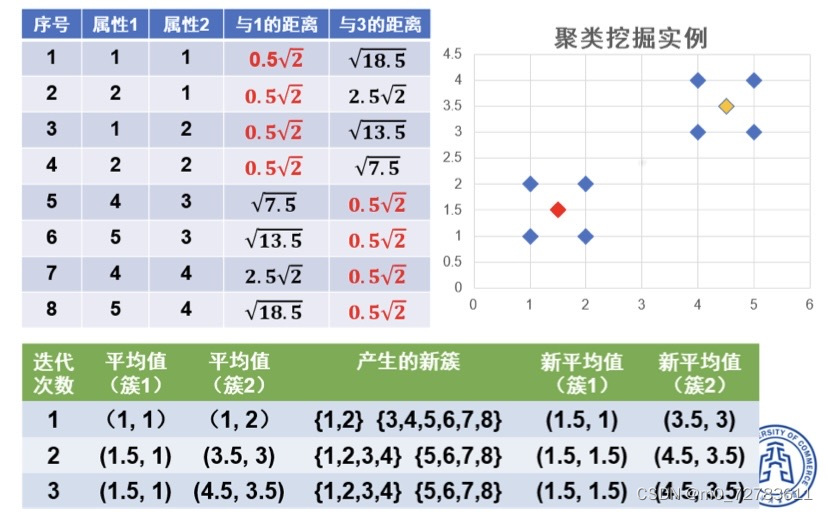
直到簇相同停止迭代。
第四章 机器学习
一、分类:
1.监督学习方法:分类,回归
2.半监督学习:半监督分类,半监督回归,半监督聚类,半监督降维
3.无监督学习方法:聚类,降维
4.强化学习:动态规划,时序差分,蒙特卡洛方法
二、机器学习模型:输入训练集--学习--输出--应用
三、数据准备:实体,文本,图(邻接矩阵)
四、KNN:距离指标,用来计算对象间的邻近程度。
1.欧式距离,曼哈顿距离:
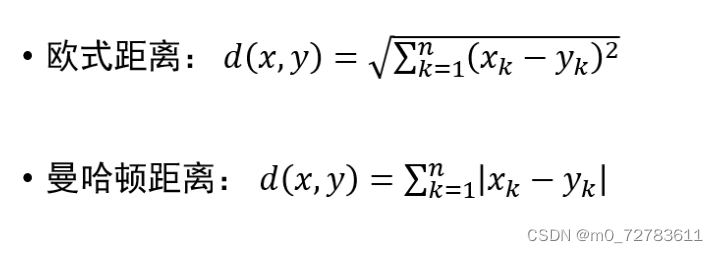
五、人工神经网络:
一层以及简单的二层神经网络模型及计算
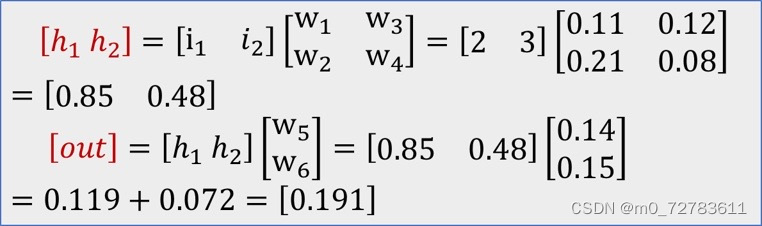
i1 ,i2为两个输入向量。
第二层的权重:
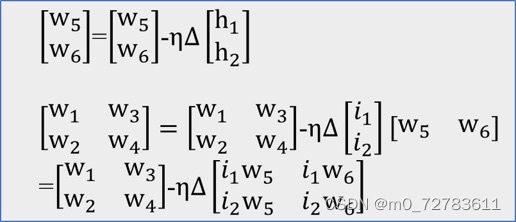
Δ=第一层的out值➖1
第五章 数据可视化
一、类型
1.科学可视化(标量场,向量场,张量场):主要面向自然科学
2.信息可视化:更关注抽象,非结构数据集合的可视化问题,一般有具体问题导向
如:文本,图表,层次结构,复杂系统
3.可视分析学:以实现人机协同完成可视化任务为主要目的的分析推理类学科。
二、模型:顺序模型,循环模型和分析模型
顺序模型:数据转换-可视化映射-视图变换-用户交互
可视化映射是整个可视化流程的核心。
三、视觉通道分类:位置、颜色、尺寸、形状。
第六章 数据计算
一、计算模型:集中式,分布式,网格式,云计算
二、MapReduce:

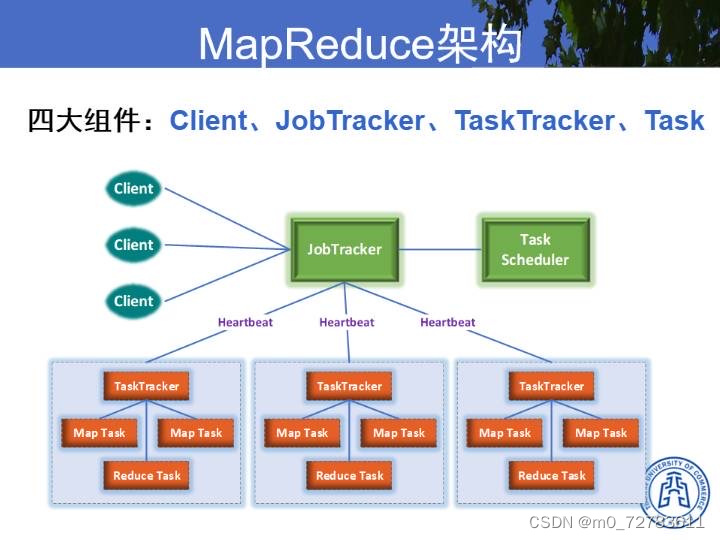
客户端Client:提交Map Reduce作业job
JobTracker:协调作业的运行
Task Tracker:运行作业划分后的任务
有多个Map Task ,只有一个Reduce Task
Reduce Task的输入是所有MapTask的输出。
第七章 数据管理
















 4528
4528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









