




一、下载yolov5源代码
可以在github中下载也可以直接下载本文章的资源。
二、yolov5模型训练
(一)下载标注工具
1、labelimg标注工具
2、labelme标注工具
3、Robflow标注工具
4、百度标注平台
5、华为标注平台
本篇文章选用的labelimg标注工具
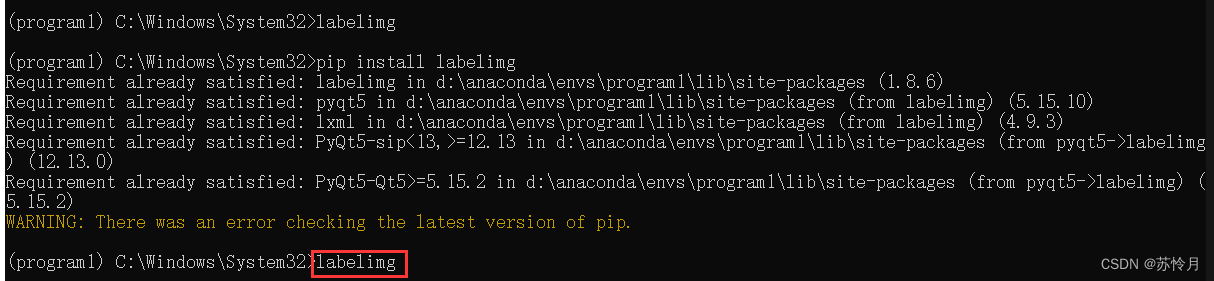
使用管理员命令提示符下载labelimg

(二)标注数据
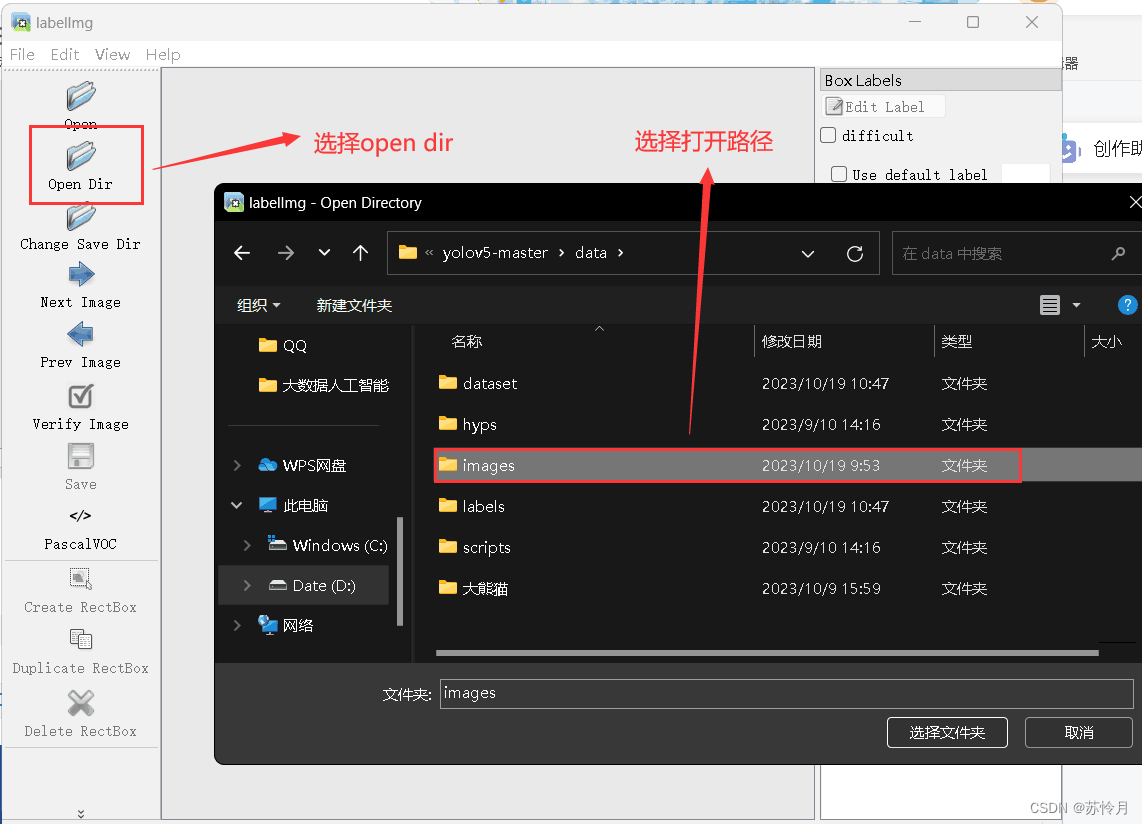
在data文件夹中的images之中放入需要标注的图片
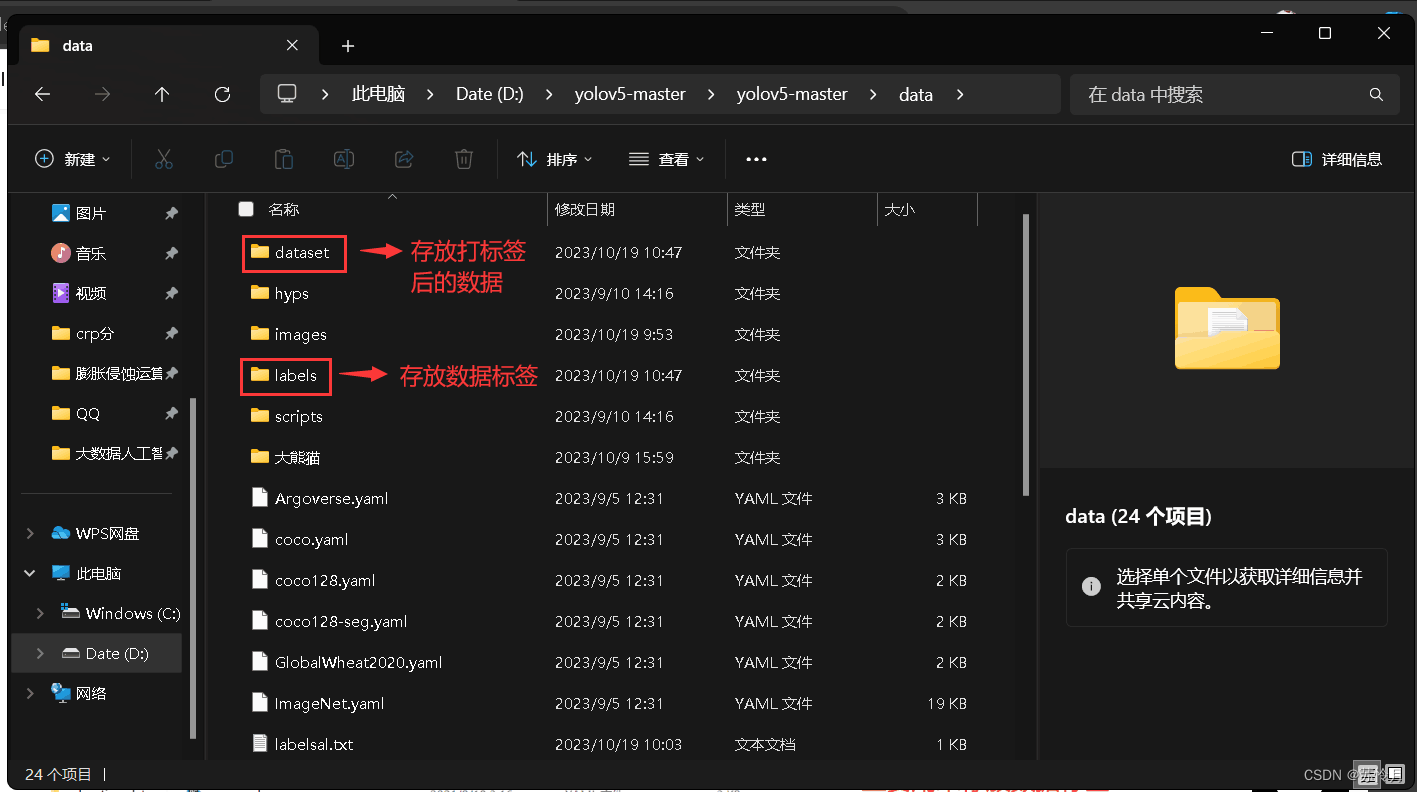
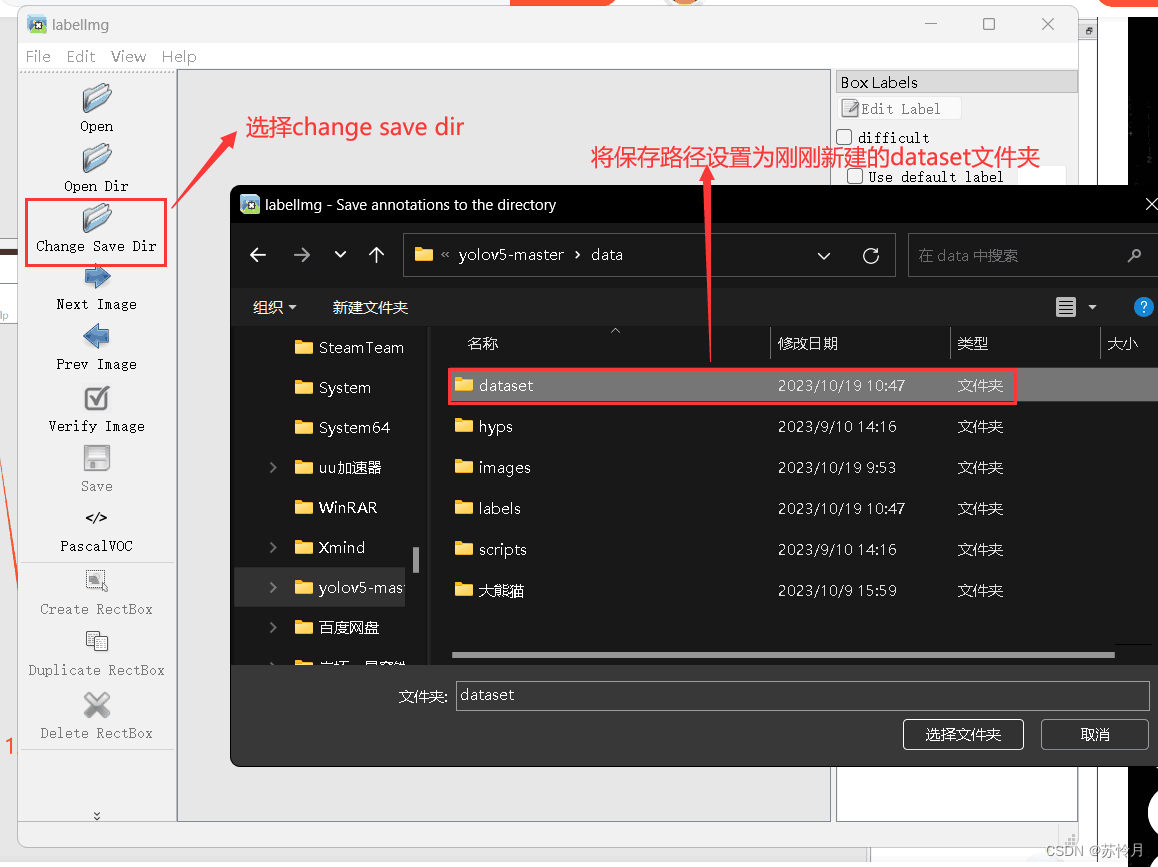
在工程中的data文件夹下新建两个文件夹,分别为dataset、labels。其中,datasets主要用来存放打好标签后的数据集,labels主要用来存放数据标签。具体如下图所示:
启动labelimg
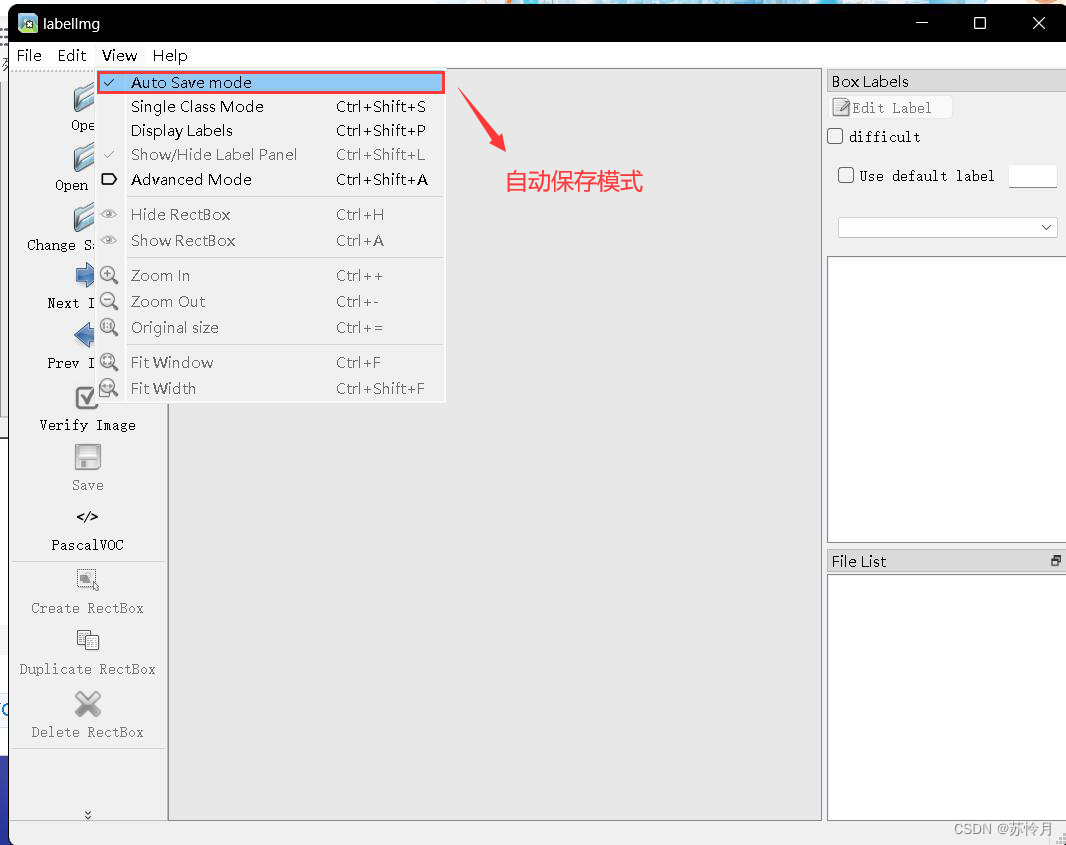
启动后的界面
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5370
5370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











