







文章目录
在将 Scrapy 项目放到各台主机运行时,你可能采用的是文件上传或者 Git 同步的方式,但这样需要各台主机都进行操作,如果有 100 台、1000 台主机,那工作量可想而知。
分布式爬虫部署方面可以采取的一些措施以方便地实现批量部署和管理。
一、 Scrapyd 分布式部署
分布式爬虫完成并可以成功运行了,但是有个环节非常烦琐,那就是代码部署。
我们设想下面的几个场景。
- 如果采用上传文件的方式部署代码,我们首先将代码压缩,然后采用 SFTP 或 FTP 的方式将文件上传到服务器,之后再连接服务器将文件解压,每个服务器都需要这样配置。
- 如果采用 Git 同步的方式部署代码,我们可以先把代码 Push 到某个 Git 仓库里,然后再远程连接各台主机执行 Pull 操作,同步代码,每个服务器同样需要做一次操作。
如果代码突然有更新,那我们必须更新每个服务器,而且万一哪台主机的版本没控制好,这可能会影响整体的分布式爬取状况。
所以我们需要一个更方便的工具来部署 Scrapy 项目,如果可以省去一遍遍逐个登录服务器部署的操作,那将会方便很多。
本节我们就来看看提供分布式部署的工具 Scrapyd。
1.1 了解 Scrapyd
Scrapyd 是一个运行 Scrapy 爬虫的服务程序,它提供一系列 HTTP 接口来帮助我们部署、启动、停止、删除爬虫程序。Scrapyd 支持版本管理,同时还可以管理多个爬虫任务,利用它我们可以非常方便地完成 Scrapy 爬虫项目的部署任务调度。
1.2 准备工作
请确保本机或服务器已经正确安装好了 Scrapyd;
1.3 访问 Scrapyd
安装并运行了 Scrapyd 之后,我们就可以访问服务器的 6800 端口看到一个 WebUI 页面了,例如我的服务器地址为 120.27.34.25,在上面安装好了 Scrapyd 并成功运行,那么我就可以在本地的浏览器中打开:http://120.27.34.25:6800,就可以看到 Scrapyd 的首页,这里请自行替换成你的服务器地址查看即可,如图所示:
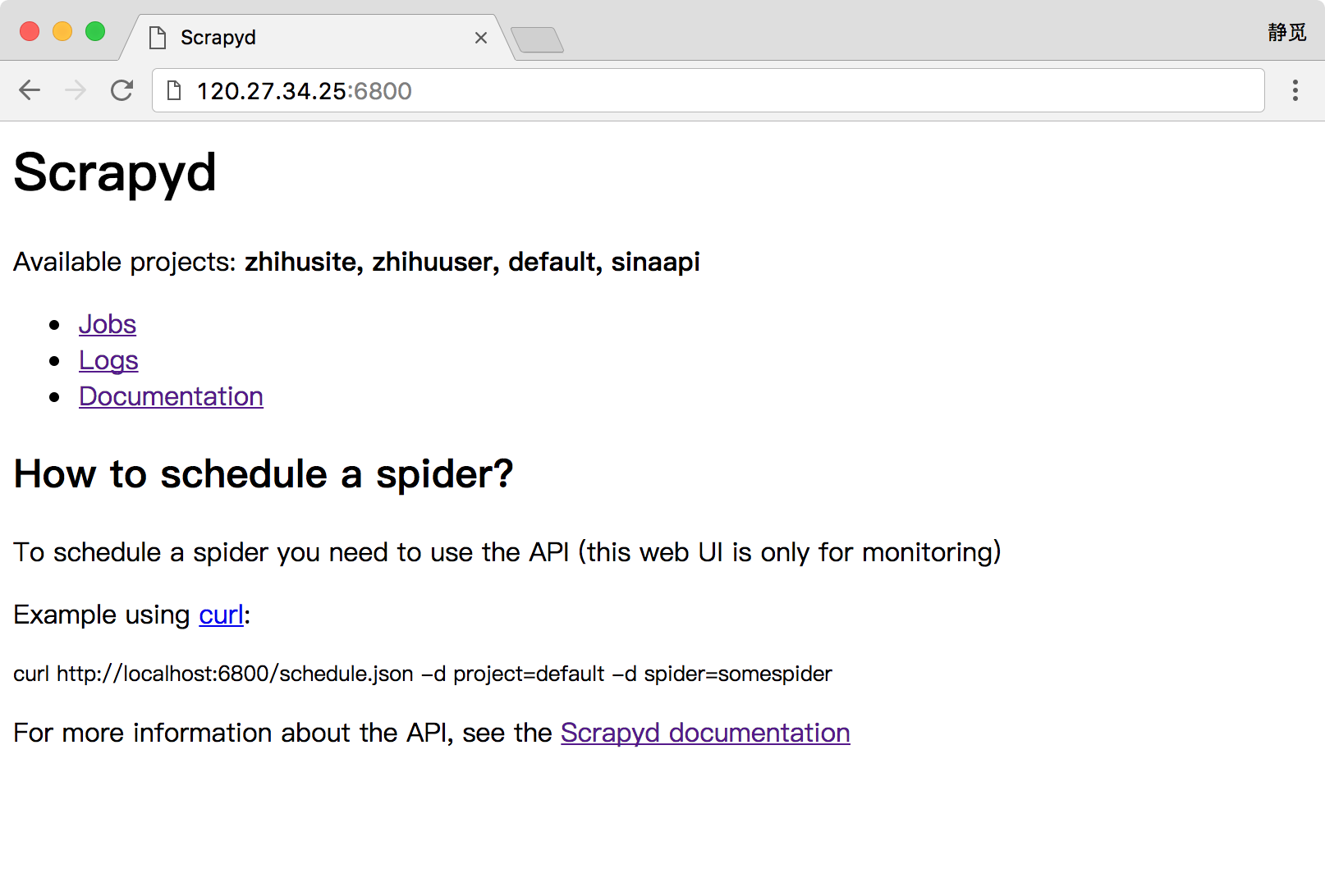
如果可以成功访问到此页面,那么证明 Scrapyd 配置就没有问题了。
1.4 Scrapyd 的功能
Scrapyd 提供了一系列 HTTP 接口来实现各种操作,在这里我们可以将接口的功能梳理一下,以 Scrapyd 所在的 IP 为 120.27.34.25 为例:
daemonstatus.json
这个接口负责查看 Scrapyd 当前的服务和任务状态,我们可以用 curl 命令来请求这个接口,命令如下:
curl http://139.217.26.30:6800/daemonstatus.json
这样我们就会得到如下结果:
{
"status": "ok", "finished": 90, "running": 9, "node_name": "datacrawl-vm", "pending": 0}
返回结果是 Json 字符串,status 是当前运行状态, finished 代表当前已经完成的 Scrapy 任务,running 代表正在运行的 Scrapy 任务,pending 代表等待被调度的 Scrapyd 任务,node_name 就是主机的名称。
addversion.json
这个接口主要是用来部署 Scrapy 项目用的,在部署的时候我们需要首先将项目打包成 Egg 文件,然后传入项目名称和部署版本。
我们可以用如下的方式实现项目部署:
curl http://120.27.34.25:6800/addversion.json -F project=wenbo -F version=first -F egg=@weibo.egg
在这里 -F 即代表添加一个参数,同时我们还需要将项目打包成 Egg 文件放到本地。
这样发出请求之后我们可以得到如下结果:
{
"status": "ok", "spiders": 3}
这个结果表明部署成功,并且其中包含的 Spider 的数量为 3。
此方法部署可能比较繁琐,在后文会介绍更方便的工具来实现项目的部署。
schedule.json
这个接口负责调度已部署好的 Scrapy 项目运行。
我们可以用如下接口实现任务调度:
curl http://120.27.34.25:6800/schedule.json -d project=weibo -d spider=weibocn
在这里需要传入两个参数,project 即 Scrapy 项目名称,spider 即 Spider 名称。
返回结果如下:
{
"status": "ok", "jobid": "6487ec79947edab326d6db28a2d86511e8247444"}
status 代表 Scrapy 项目启动情况,jobid 代表当前正在运行的爬取任务代号。
cancel.json
这个接口可以用来取消某个爬取任务,如果这个任务是 pending 状态,那么它将会被移除,如果这个任务是 running 状态,那么它将会被终止。
我们可以用下面的命令来取消任务的运行:
curl http://120.27.34.25:6800/cancel.json -d project=weibo -d job=6487ec79947edab326d6db28a2d86511e8247444
在这里需要传入两个参数,project 即项目名称,job 即爬取任务代号。
返回结果如下:
{
"status": "ok", "prevstate": "running"}
status 代表请求执行情况,prevstate 代表之前的运行状态。
listprojects.json
这个接口用来列出部署到 Scrapyd 服务上的所有项目描述。
我们可以用下面的命令来获取 Scrapyd 服务器上的所有项目描述:
curl http://120.27.34.25:6800/listprojects.json
这里不需要传入任何参数。
返回结果如下:
{
"status": "ok" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









