







#数据的导入
import pandas as pd
import numpy as np
#导入EXCEL表格数据;na_values=''指定了将Excel文件中的空单元格转换为NaN
df_excel=pd.read_excel('C:/Users/galax/Desktop/MBA小行星数据/4000.xls',na_values=0)
#定义0为缺失值
see_data=df_excel
#统计每一列的缺失值个数
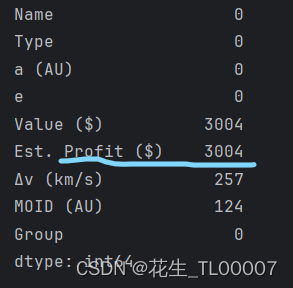
print(see_data.isnull().sum(axis=0))结果发现Asterank一共4001颗小行星,就有3004颗没有利润值y,初步想法是直接删除3004个没有值的样本,剩下的缺失数据用KNN填补。
df = pd.DataFrame(see_data)
# #方法1:
# 删除 'Est. Profit ($)' 列中包含缺失值的行
df = df.dropna(subset=['Est. Profit ($)'])
df.to_excel('C:/Users/galax/Desktop/sub.xlsx', index=False)4001个样本,删除缺失值后直接变成了997行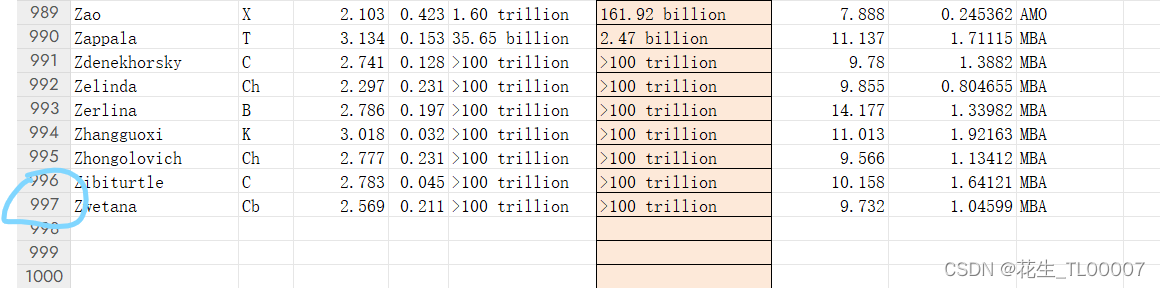
下一步就是对这997个样本进行脏数据整理:
- 处理>号
- 处理单位并转换billion,million,trillion
- 标准化归一化
#想要实现将Est.Profit列传入dataFrame-df,
#数据的导入
import pandas as pd
import numpy as np
#导入EXCEL表格数据;na_values=''指定了将Excel文件中的空单元格转换为NaN
df=pd.read_excel('C:/Users/galax/Desktop/sub.xls')
# 选择特定的列
df_selected = df['Profit']
# 显示加载后的DataFrame
#print(df_selected)
# 定义一个清洗和转换数据的函数
def clean_and_convert_value(s):
if isinstance(s, str):
# 移除大于符号
if '>' in s:
s = s.replace('>', '').strip()
# 分割数值和单位
if 'trillion' in s:
number, unit = s.split('trillion')
mult = 1e12 # 表示 trillion 单位的数值
elif 'billion' in s:
number, unit = s.split('billion')
mult = 1e9 # 表示 billion 单位的数值
elif 'million' in s:
number, unit = s.split('million')
mult = 1e6 # 表示 billion 单位的数值
else:
return s
# 转换为浮点数,并进行单位统一(统一转为million)
return float(number.strip()) * mult / 1e6
elif isinstance(s, float):
return s/1e6
# 应用这个函数到DataFrame的列
df['value_numeric'] =df['Profit'].apply(clean_and_convert_value)
print(df['value_numeric'])
df.to_excel('C:/Users/galax/Desktop/Profit_cleaned4.xlsx', index=False)运行结果:
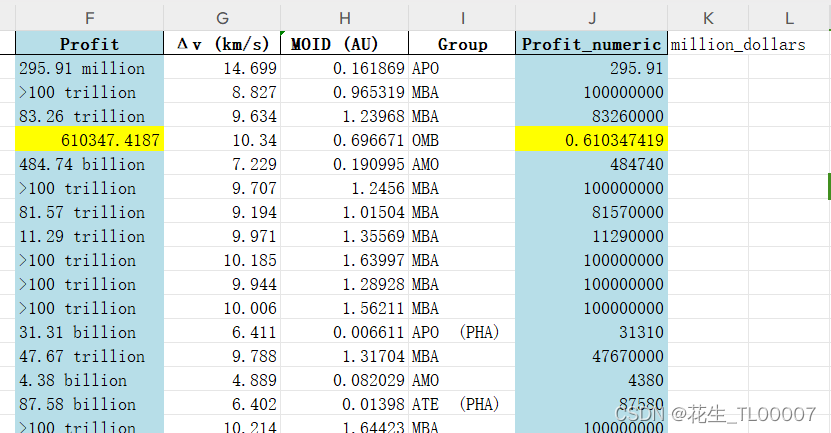
下一步是对derta_V列中的缺失值进行KNN插补 ,整体代码如下:
#数据的导入
import pandas as pd
import numpy as np
from sklearn.impute import KNNImputer
#导入EXCEL表格数据;na_values=''指定了将Excel文件中的空单元格转换为NaN
df_excel=pd.read_excel('C:/Users/galax/Desktop/Profit_cleaned4.xls',na_values=' ')
#定义空为缺失值
#统计每一列的缺失值个数
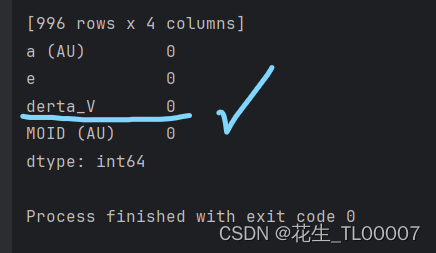
print(df_excel.isnull().sum(axis=0))
print("Now I'm going to fix null of derta_V with method KNN..")
df=pd.DataFrame(df_excel)
print("未使用KNN填补缺失值的derta_V如下:")
print(df['derta_V'])
#df.to_excel('C:/Users/galax/Desktop/original_V.xlsx', index=False)
#创建一个KNNImputer对象
imputer=KNNImputer(n_neighbors=10)
df_impu=df.iloc[:, 2:6] # 选择第2到第6列的数据,因为KNN只处理数值型数据
#对缺失值进行插补,使用5个邻居
imputed_data=imputer.fit_transform(df_impu)
#将插补后的数据保存到新的数据框中
imputed_df=pd.DataFrame(imputed_data,columns=df_impu.columns)
print("使用KNN填补缺失V值后的数据:")
#df['derta_V']=imputed_df['derta_V']
print(imputed_df)
imputed_df.to_excel('C:/Users/galax/Desktop/imputed_dertaV111.xlsx', index=False)
print(imputed_df.isnull().sum(axis=0))
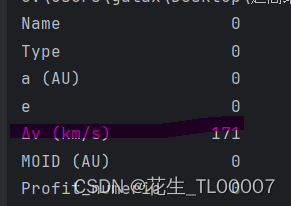
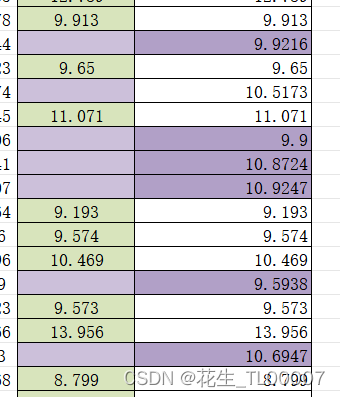
如下图所示,左列为含有缺失值的derta_V数据,右列为KNN插补缺失值后的derta_V数据















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









