






问题如下
1.什么是硬注意力机制和软注意力机制
2.GoogleNet平均池化代替全连接
3.lstm的dropout有什么不同
解答如下
1.软注意力机制的数学公式如下:

对于软注意力,注意力模块相对于输入是可微的,因此整个系统仍然可以通过标准的反向传播方法进行训练
硬注意力机制的数学公式如下:
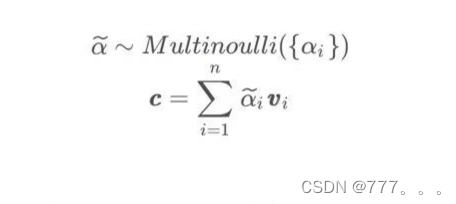
与软注意力模型相比,硬注意力模型的计算成本更低,因为它不需要每次都计算所有元素的注意力权重,模块不可微。
区别:软注意力机制更适合需要关注输入数据中多个重要部分的任务,而硬注意力机制则更适合需要选择输入数据中最重要部分的任务。
2.
平均池化内容如下
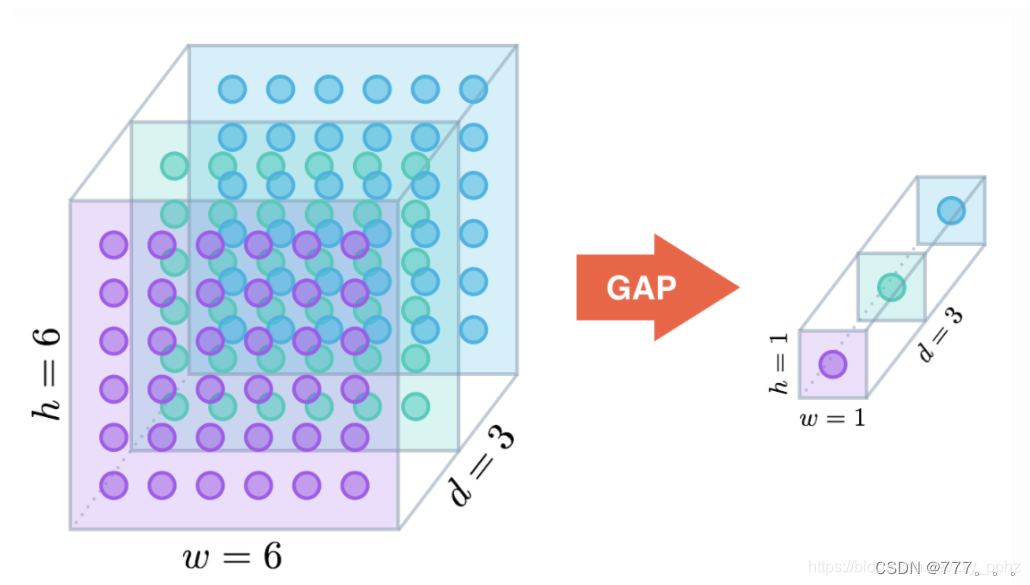
将h x w x c化成1 x 1 x d
优点:减少模型的参数数量,还使得模型具有更好的泛化能力和鲁棒性。
3.

上图中新加的D代表dropout

作者指出,dropout一定要设置在网络的非循环部分,否则信息将会因循环而逐渐丢失。我们把dropout设置在输入神经元上,如上图中虚线,那么因dropout造成的信息损失则与循环的次数无关,而仅仅与网络的层数相关。















 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









