






1.整体结构


Swim Transformer分为以下几个模块,Patch Partition模块,Patch Merging模块,W-MSA模块,SW-MSA模块,Relative position bias机制
2.Patch Partition和Liner Embedding

Patch Partition + Liner Embedding的实现是通过nn.Conv2d,将kernel_size和stride设置为 patch_size(将图像分为几块,这里为4)大小。其实就是一个2d卷积实现。
3.Patch Merging

如上图所示,假设输入Patch Merging的是一个6x6大小的单通道特征图(feature map),Patch Merging会将每个3x3的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map。接着将这四个feature map在深度方向进行concat拼接,然后在通过一个LayerNorm层。
作用:是在每个Stage开始前做降采样,用于缩小分辨率,调整通道数 进而形成层次化的设计,同时也能节省一定运算量
4.Swin Transformer Block
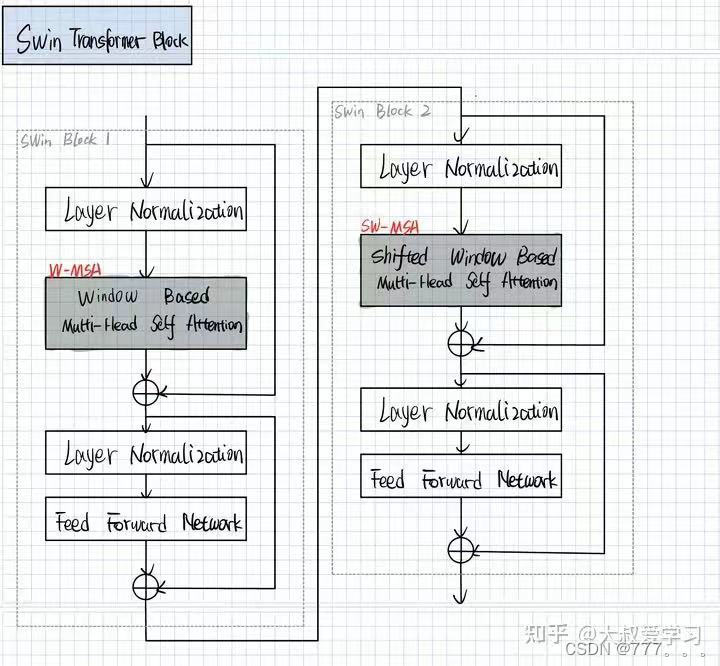
block由两部分组成,W-MSA和SW-MSA。
4.1. W-MSA


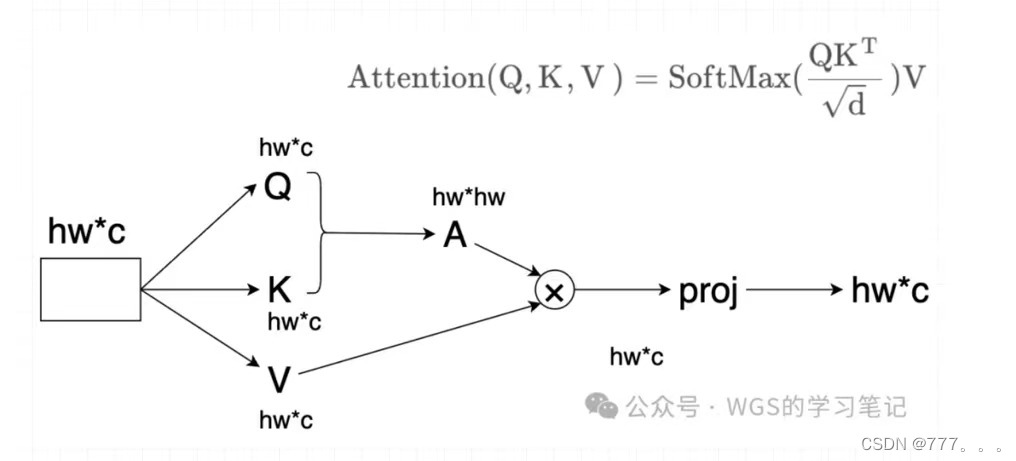
MSA 是 Multi Head Self-Attention 的缩写,在 MSA 中,会对每一个像素去求它的q、k、v,然后对于每个像素它所求得的 q,会和特征图当中的每一个像素的 k 进行匹配,然后再进行 softmax 以及后续的和 v 加权求和,也就是说特征矩阵当中的每一个像素都会和其它像素进行信息的沟通,它是全局的。然后再看一下 Swin Transformer 中提出的 Windows Multi Head Self-Attention,它首先会对特征图按照分成一个个的 Window(图例中是将特征矩阵分成大小的窗口),然后对每个窗口的内部进行 MSA 的计算。
Swin Transformer 中提出的 Windows Multi Head Self-Attention,它首先会对特征图按照分成一个个的 Window(图例中是将特征矩阵分成大小的窗口),然后对每个窗口的内部进行 MSA 的计算。
4.2.SW-MSA
4.1的Window Attention是在每个窗口下计算注意力的,为了更好的和其他window进行信息交互,Swin Transformer还引入了shifted window操作。

做一个循环移位(cyclic shift),先AC移下来,再AB移到右边。就又可以分成四宫格得到四个窗口。移位前四个,移位后也是四个,窗口数量数量固定。(未完)















 4435
4435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









