






Rocketcore学习笔记
- 本文借鉴了不少大神的资料,主要是自己学习的记录,如有侵权,立马删除
rocketchip整体结构
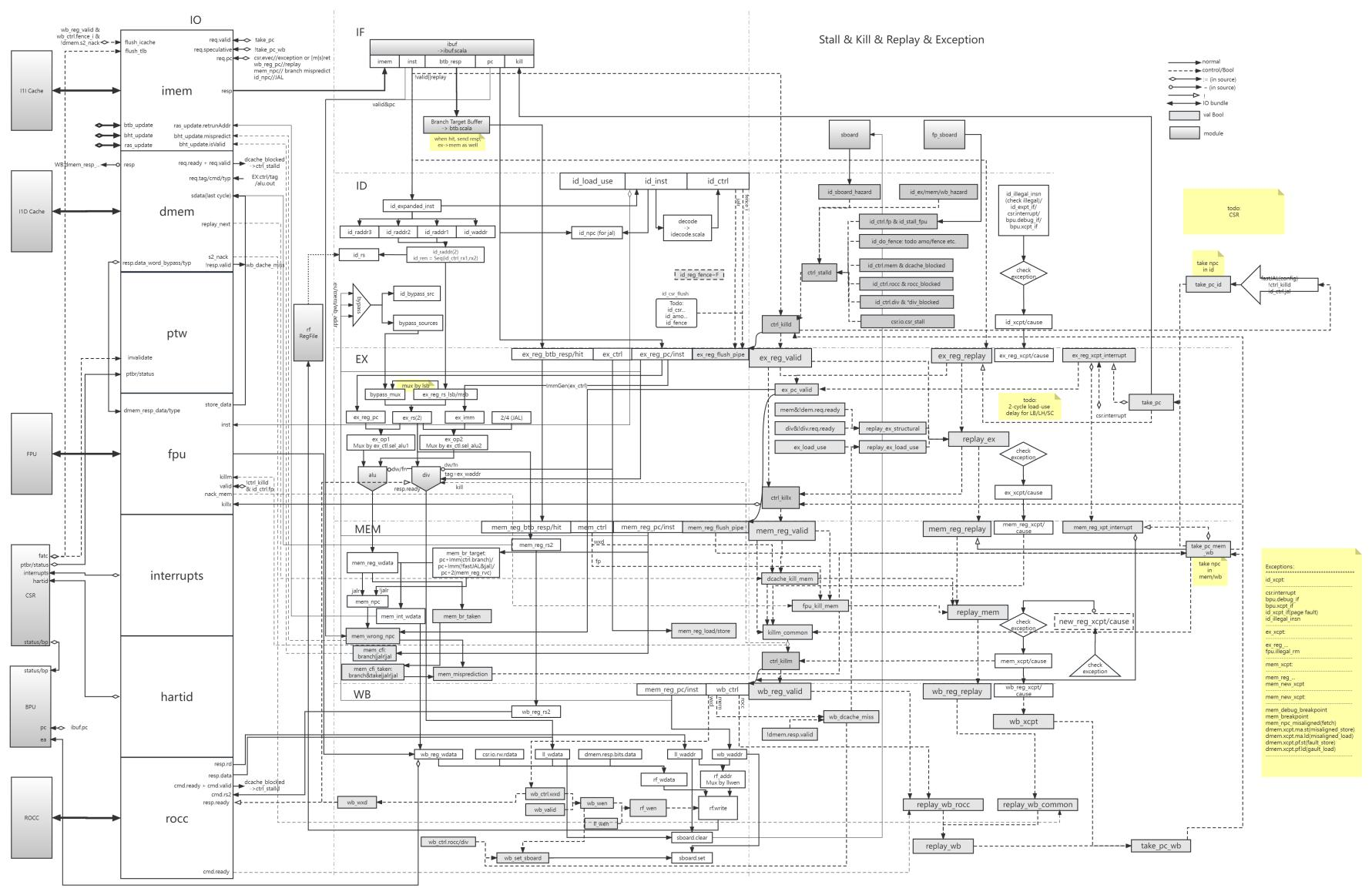
Rocketcore整体流程图
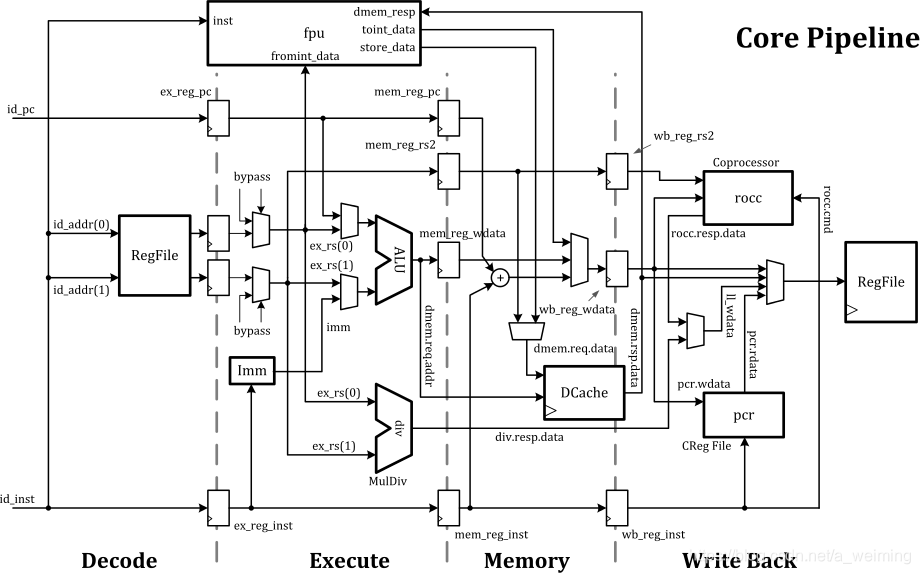
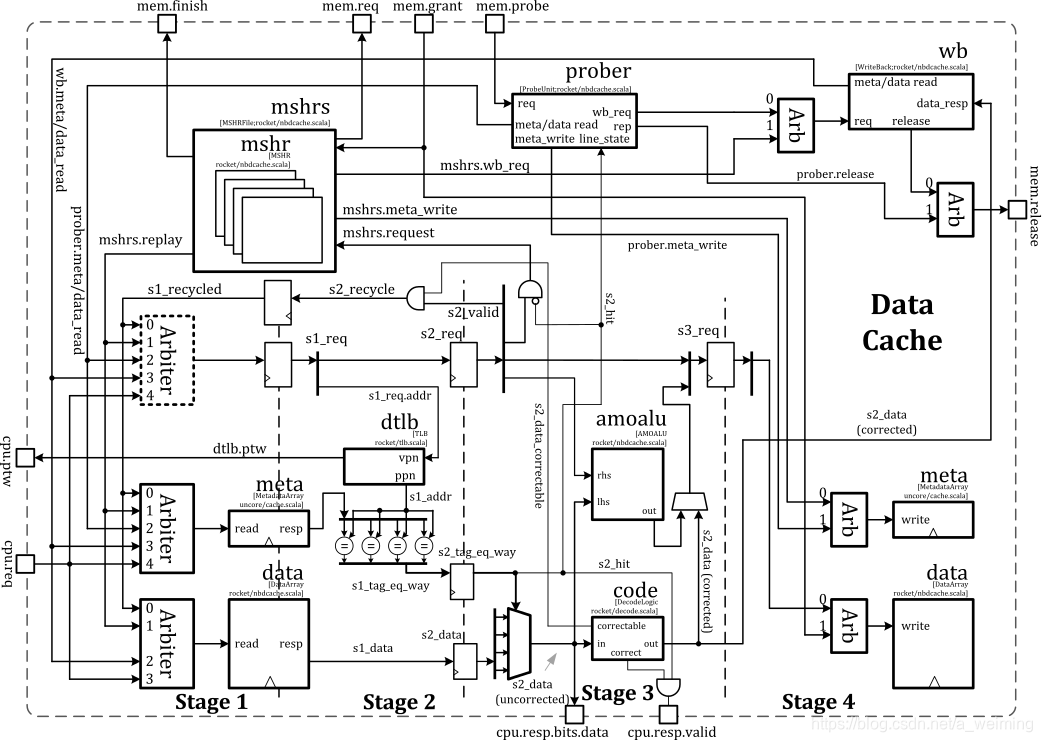
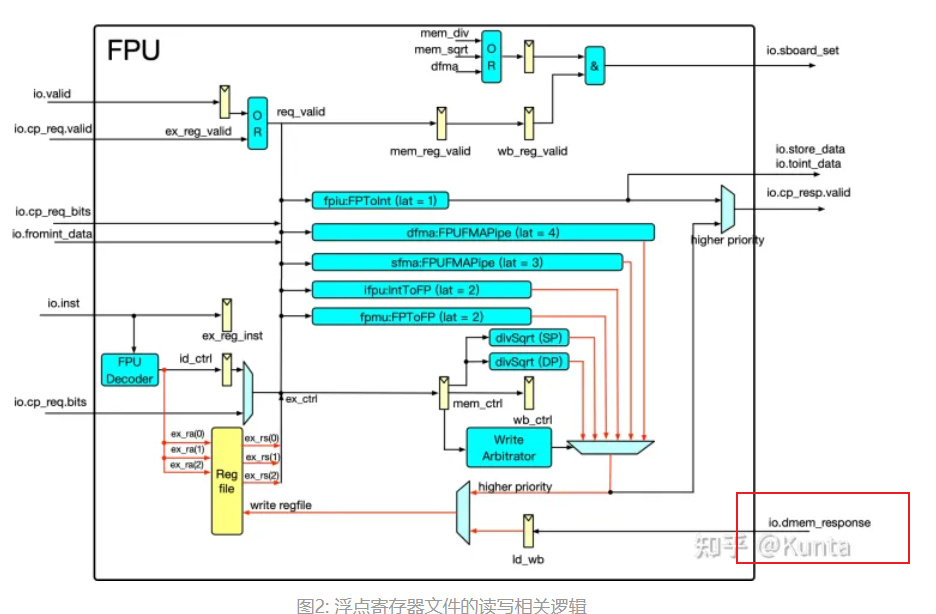
FPU
fpu<>dmem
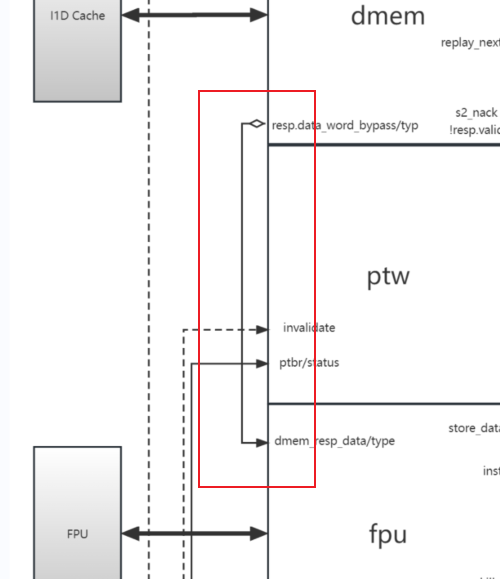
io.fpu.dmem_resp_data := (if (minFLen == 32) io.dmem.resp.bits.data_word_bypass else io.dmem.resp.bits.data)
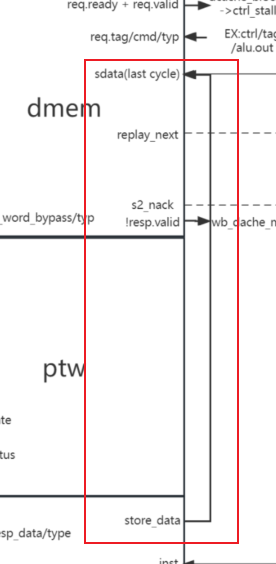
io.dmem.s1_data.data := (if (fLen == 0) mem_reg_rs2 else Mux(mem_ctrl.fp, Fill((xLen max fLen) / fLen, io.fpu.store_data), mem_reg_rs2))
异常:
val id_illegal_insn = !id_ctrl.legal ||
(id_ctrl.mul || id_ctrl.div) && !csr.io.status.isa('m'-'a') ||
id_ctrl.amo && !csr.io.status.isa('a'-'a') ||
id_ctrl.fp && (csr.io.decode(0).fp_illegal || io.fpu.illegal_rm) ||
id_ctrl.dp && !csr.io.status.isa('d'-'a') ||
ibuf.io.inst(0).bits.rvc && !csr.io.status.isa('c'-'a') ||
id_raddr2_illegal && !id_ctrl.scie && id_ctrl.rxs2 ||
id_raddr1_illegal && !id_ctrl.scie && id_ctrl.rxs1 ||
id_waddr_illegal && !id_ctrl.scie && id_ctrl.wxd ||
id_ctrl.rocc && csr.io.decode(0).rocc_illegal ||
id_ctrl.scie && !(id_scie_decoder.unpipelined || id_scie_decoder.pipelined) ||
id_csr_en && (csr.io.decode(0).read_illegal || !id_csr_ren && csr.io.decode(0).write_illegal) ||
!ibuf.io.inst(0).bits.rvc && (id_system_insn && csr.io.decode(0).system_illegal) ||
id_illegal_rnum
val (id_xcpt, id_cause) = checkExceptions(List(
(csr.io.interrupt, csr.io.interrupt_cause),
(bpu.io.debug_if, CSR.debugTriggerCause.U),
(bpu.io.xcpt_if, Causes.breakpoint.U),
(id_xcpt0.pf.inst, Causes.fetch_page_fault.U),
(id_xcpt0.gf.inst, Causes.fetch_guest_page_fault.U),
(id_xcpt0.ae.inst, Causes.fetch_access.U),
(id_xcpt1.pf.inst, Causes.fetch_page_fault.U),
(id_xcpt1.gf.inst, Causes.fetch_guest_page_fault.U),
(id_xcpt1.ae.inst, Causes.fetch_access.U),
(id_virtual_insn, Causes.virtual_instruction.U),
(id_illegal_insn, Causes.illegal_instruction.U)))
若是需要阻塞mem阶段的话则进行阻塞mem阶段,重新执行此条指令:可能是没有准备好要写回的数据:
val fpu_kill_mem = mem_reg_valid && mem_ctrl.fp && io.fpu.nack_mem
val replay_mem = dcache_kill_mem || mem_reg_replay || fpu_kill_mem
wb_reg_replay := replay_mem && !take_pc_wb
val replay_wb_common = io.dmem.s2_nack || wb_reg_replay
val replay_wb = replay_wb_common || replay_wb_rocc || replay_wb_csr
take_pc_wb := replay_wb || wb_xcpt || csr.io.eret || wb_reg_flush_pipe
val take_pc_mem_wb = take_pc_wb || take_pc_mem
val take_pc = take_pc_mem_wb
ibuf.io.kill := take_pc
ctrl_killd := !ibuf.io.inst(0).valid || ibuf.io.inst(0).bits.replay || take_pc_mem_wb || ctrl_stalld || csr.io.interrupt
val ctrl_killx = take_pc_mem_wb || replay_ex || !ex_reg_valid
val killm_common = dcache_kill_mem || take_pc_wb || mem_reg_xcpt || !mem_reg_valid
div.io.kill := killm_common && RegNext(div.io.req.fire)
val ctrl_killm = killm_common || mem_xcpt || fpu_kill_mem
输入的各种接口:
//译码阶段
//有效信号 解析出fpu指令
io.fpu.valid := !ctrl_killd && id_ctrl.fp
//判断是否有异常 若有的话终止fpu继续运行
io.fpu.killx := ctrl_killx
io.fpu.killm := killm_common
//传入输入的指令
io.fpu.inst := id_inst(0)
//从寄存器中读出的值 是一个列表 有rs1和rs2
io.fpu.fromint_data := ex_rs(0)
//此处rocket执行到ex阶段 传入地址 此时的地址是alu计算的出来的数据 即alu.io.adder_out
io.dmem.req.valid := ex_reg_valid && ex_ctrl.mem
io.dmem.req.bits.tag := ex_dcache_tag
io.dmem.req.bits.cmd := ex_ctrl.mem_cmd
io.dmem.req.bits.size := ex_reg_mem_size
io.dmem.req.bits.signed := !Mux(ex_reg_hls, ex_reg_inst(20), ex_reg_inst(14))
io.dmem.req.bits.phys := false.B
io.dmem.req.bits.addr := encodeVirtualAddress(ex_rs(0), alu.io.adder_out)
io.dmem.req.bits.idx.foreach(_ := io.dmem.req.bits.addr)
io.dmem.req.bits.dprv := Mux(ex_reg_hls, csr.io.hstatus.spvp, csr.io.status.dprv)
io.dmem.req.bits.dv := ex_reg_hls || csr.io.status.dv
//s1代表的是dcache前进一个周期,此时可能需要data,若是fpu没有计算完毕,则设置s1_kill将,又因为fpu_kill_mem,此条指令将重新执行一遍,若是没有则传入的是fpu的store data,dcache进行保存。或者是准备好读取数据的话,也不会阻塞。
io.dmem.s1_data.data := (if (fLen == 0) mem_reg_rs2 else Mux(mem_ctrl.fp, Fill((xLen max fLen) / fLen, io.fpu.store_data), mem_reg_rs2))
io.dmem.s1_kill := killm_common || mem_ldst_xcpt || fpu_kill_mem
//此刻ke'neng是没有计算完成写回数据的情况
val fpu_kill_mem = mem_reg_valid && mem_ctrl.fp && io.fpu.nack_mem
io.dmem.s2_kill := false.B
//以下fpu接的是读取完成之后输出的结果。
io.fpu.dmem_resp_val := dmem_resp_valid && dmem_resp_fpu
io.fpu.dmem_resp_data := (if (minFLen == 32) io.dmem.resp.bits.data_word_bypass else io.dmem.resp.bits.data)
io.fpu.dmem_resp_type := io.dmem.resp.bits.size
io.fpu.dmem_resp_tag := dmem_resp_waddr
io.fpu.keep_clock_enabled := io.ptw.customCSRs.disableCoreClockGate
// don't let D$ go to sleep if we're probably going to use it soon
io.dmem.keep_clock_enabled := ibuf.io.inst(0).valid && id_ctrl.mem && !csr.io.csr_stall
//传入了waddr,此时将第0位置为是否是fp指令的标志。
val ex_dcache_tag = Cat(ex_waddr, ex_ctrl.fp)
require(coreParams.dcacheReqTagBits >= ex_dcache_tag.getWidth)
io.dmem.req.bits.tag := ex_dcache_tag
io.dmem.req.bits.tag := ex_dcache_tag
// writeback arbitration
val dmem_resp_xpu = !io.dmem.resp.bits.tag(0).asBool
val dmem_resp_fpu = io.dmem.resp.bits.tag(0).asBool
val dmem_resp_waddr = io.dmem.resp.bits.tag(5, 1)
val dmem_resp_valid = io.dmem.resp.valid && io.dmem.resp.bits.has_data
val dmem_resp_replay = dmem_resp_valid && io.dmem.resp.bits.replay
//写回阶段:
when (mem_pc_valid) {
wb_ctrl := mem_ctrl
wb_reg_sfence := mem_reg_sfence
wb_reg_wdata := Mux(mem_scie_pipelined, mem_scie_pipelined_wdata,
Mux(!mem_reg_xcpt && mem_ctrl.fp && mem_ctrl.wxd, io.fpu.toint_data, mem_int_wdata))
when (mem_ctrl.rocc || mem_reg_sfence) {
wb_reg_rs2 := mem_reg_rs2
}
wb_reg_cause := mem_cause
wb_reg_inst := mem_reg_inst
wb_reg_raw_inst := mem_reg_raw_inst
wb_reg_mem_size := mem_reg_mem_size
wb_reg_hls_or_dv := mem_reg_hls_or_dv
wb_reg_hfence_v := mem_ctrl.mem_cmd === M_HFENCEV
wb_reg_hfence_g := mem_ctrl.mem_cmd === M_HFENCEG
wb_reg_pc := mem_reg_pc
wb_reg_wphit := mem_reg_wphit | bpu.io.bpwatch.map { bpw => (bpw.rvalid(0) && mem_reg_load) || (bpw.wvalid(0) && mem_reg_store) }
}
fpu 对csr寄存器的操作
io.fpu.fcsr_rm := csr.io.fcsr_rm
csr.io.fcsr_flags := io.fpu.fcsr_flags
io.fpu.time := csr.io.time(31,0)
io.fpu.hartid := io.hartid
fpu检测冲突
val id_stall_fpu = if (usingFPU) {
val fp_sboard = new Scoreboard(32)
fp_sboard.set((wb_dcache_miss && wb_ctrl.wfd || io.fpu.sboard_set) && wb_valid, wb_waddr)
fp_sboard.clear(dmem_resp_replay && dmem_resp_fpu, dmem_resp_waddr)
fp_sboard.clear(io.fpu.sboard_clr, io.fpu.sboard_clra)
checkHazards(fp_hazard_targets, fp_sboard.read _)
} else false.B
val ctrl_stalld =
id_ex_hazard || id_mem_hazard || id_wb_hazard || id_sboard_hazard ||
csr.io.singleStep && (ex_reg_valid || mem_reg_valid || wb_reg_valid) ||
id_csr_en && csr.io.decode(0).fp_csr && !io.fpu.fcsr_rdy ||
id_ctrl.fp && id_stall_fpu ||
id_ctrl.mem && dcache_blocked || // reduce activity during D$ misses
id_ctrl.rocc && rocc_blocked || // reduce activity while RoCC is busy
id_ctrl.div && (!(div.io.req.ready || (div.io.resp.valid && !wb_wxd)) || div.io.req.valid) || // reduce odds of replay
!clock_en ||
id_do_fence ||
csr.io.csr_stall ||
id_reg_pause ||
io.traceStal
fpu写回寄存器
wb_reg_wdata := Mux(mem_scie_pipelined, mem_scie_pipelined_wdata,
Mux(!mem_reg_xcpt && mem_ctrl.fp && mem_ctrl.wxd, io.fpu.toint_data, mem_int_wdata))
当执行到mul或者div指令的时候的话可能会发生乱序执行
//以下仅对mul指令进行讨论
//wb_wxd代表的是wb阶段的指令是否会写入寄存器
val wb_wxd = wb_reg_valid && wb_ctrl.wxd
//ready代表的是可以接收mul模块的信号,即wb阶段没有需要写入寄存器
div.io.resp.ready := !wb_wxd
//div.io.resp.fire代表乘除法器准备好信号(valid)且rocket准备好接受信号(ready)
val ll_wdata = WireDefault(div.io.resp.bits.data)
val ll_waddr = WireDefault(div.io.resp.bits.tag)
val ll_wen = WireDefault(div.io.resp.fire)
val rf_wdata = Mux(dmem_resp_valid && dmem_resp_xpu, io.dmem.resp.bits.data(xLen-1, 0),
Mux(ll_wen, ll_wdata,
Mux(wb_ctrl.csr =/= CSR.N, csr.io.rw.rdata,
Mux(wb_ctrl.mul, mul.map(_.io.resp.bits.data).getOrElse(wb_reg_wdata),
wb_reg_wdata))))
when (rf_wen) { rf.write(rf_waddr, rf_wdata) }
- 若是执行指令的顺序如下所示:

则mul执行的是一个多周期的指令,假如mul操作寄存器和add不发生冲突的话,将会先执行add指令写回,之后nop到wb阶段时,加入mul模块valid(准备好),则在此阶段写回mul指令执行的结果,这样的话mul完成就会在add指令之后了。
想了很长时间不太理解的问题
若是由于fpu执行周期过长导致rocket在mem阶段replay的话,那么rockeet重新取值之后,在exe阶段对重新对fpu发送相同的replay指令的话不会对fpu造成影响吗?相当于fpu执行了两条相同的指令。
val fpu_kill_mem = mem_reg_valid && mem_ctrl.fp && io.fpu.nack_mem
io.nack_mem := write_port_busy || divSqrt_write_port_busy || divSqrt_inFlight
猜测:
nack_mem信号是令rocket重新执行的信号,其中的divSqrt_inFlight只是检测divSqrt这个模块是否存在结构冲突,若是不存在结构冲突的话,则不会nack_mem,即使这条指令会执行多个周期:
fpu的执行,访存和写回与rocket同步,而写回的第一个周期就能计算出tointdata,所以的话不会影响rocket的执行同时若是fpu正在执行的话会nack住下一条fpu的信号。令下一条fpu信号重新执行。
CSR
读写控制信号
//rocket.scala
csr.io.rw.addr := wb_reg_inst(31,20)
csr.io.rw.cmd := CSR.maskCmd(wb_reg_valid, wb_ctrl.csr)
csr.io.rw.wdata := wb_reg_wdata
//csr.scala
// mask a CSR cmd with a valid bit
def maskCmd(valid: Bool, cmd: UInt): UInt = {
// all commands less than CSR.I are treated by CSRFile as NOPs
cmd & ~Mux(valid, 0.U, CSR.I)
}
val SZ = 3
def X = BitPat.dontCare(SZ)
def N = 0.U(SZ.W)
def R = 2.U(SZ.W)
def I = 4.U(SZ.W)
def W = 5.U(SZ.W)
def S = 6.U(SZ.W)
def C = 7.U(SZ.W)
io.rw.rdata := Mux1H(for ((k, v) <- read_mapping) yield decoded_addr(k) -> v)
val decoded_addr = {
val addr = Cat(io.status.v, io.rw.addr)
val pats = for (((k, _), i) <- read_mapping.zipWithIndex)
yield (BitPat(k.U), (0 until read_mapping.size).map(j => BitPat((i == j).B)))
val decoded = DecodeLogic(addr, Seq.fill(read_mapping.size)(X), pats)
val unvirtualized_mapping = (for (((k, _), v) <- read_mapping zip decoded) yield k -> v.asBool).toMap
for ((k, v) <- unvirtualized_mapping) yield k -> {
val alt = CSR.mode(k) match {
case PRV.S => unvirtualized_mapping.lift(k + (1 << CSR.modeLSB))
case PRV.H => unvirtualized_mapping.lift(k - (1 << CSR.modeLSB))
case _ => None
}
alt.map(Mux(reg_mstatus.v, _, v)).getOrElse(v)
}
}
when (decoded_addr(CSRs.vstart)) { set_vs_dirty := true.B; reg_vstart.get := wdata }
when (decoded_addr(CSRs.vxrm)) { set_vs_dirty := true.B; reg_vxrm.get := wdata }
when (decoded_addr(CSRs.vxsat)) { set_vs_dirty := true.B; reg_vxsat.get := wdata }
csr信号含义

csrrw和csrrs的差距仅在ctrl信号
val SZ = 3
def X = BitPat.dontCare(SZ)
def N = 0.U(SZ.W)
def R = 2.U(SZ.W)
def I = 4.U(SZ.W)
def W = 5.U(SZ.W)
def S = 6.U(SZ.W)
def C = 7.U(SZ.W)
def readModifyWriteCSR(cmd: UInt, rdata: UInt, wdata: UInt) = {
(Mux(cmd(1), rdata, 0.U) | wdata) & ~Mux(cmd(1,0).andR, wdata, 0.U)
}
csr中也有某些指令的译码:
val decode_table = Seq( ECALL-> List(Y,N,N,N,N,N,N,N,N),
EBREAK-> List(N,Y,N,N,N,N,N,N,N),
MRET-> List(N,N,Y,N,N,N,N,N,N),
CEASE-> List(N,N,N,Y,N,N,N,N,N),
WFI-> List(N,N,N,N,Y,N,N,N,N)) ++
usingDebug.option( DRET-> List(N,N,Y,N,N,N,N,N,N)) ++
usingNMI.option( MNRET-> List(N,N,Y,N,N,N,N,N,N)) ++
coreParams.haveCFlush.option(CFLUSH_D_L1-> List(N,N,N,N,N,N,N,N,N)) ++
usingSupervisor.option( SRET-> List(N,N,Y,N,N,N,N,N,N)) ++
usingVM.option( SFENCE_VMA-> List(N,N,N,N,N,Y,N,N,N)) ++
usingHypervisor.option( HFENCE_VVMA-> List(N,N,N,N,N,N,Y,N,N)) ++
usingHypervisor.option( HFENCE_GVMA-> List(N,N,N,N,N,N,N,Y,N)) ++
(if (usingHypervisor) hlsv.map(_-> List(N,N,N,N,N,N,N,N,Y)) else Seq())
val insn_call :: insn_break :: insn_ret :: insn_cease :: insn_wfi :: _ :: _ :: _ :: _ :: Nil = {
val insn = ECALL.value.U | (io.rw.addr << 20)
DecodeLogic(insn, decode_table(0)._2.map(x=>X), decode_table).map(system_insn && _.asBool)
}
查看ecall,ebreak,mret指令的区别,发现他们的不同在于io.rw.addr所以这也是他们能拼接成一条完整指令的原因。
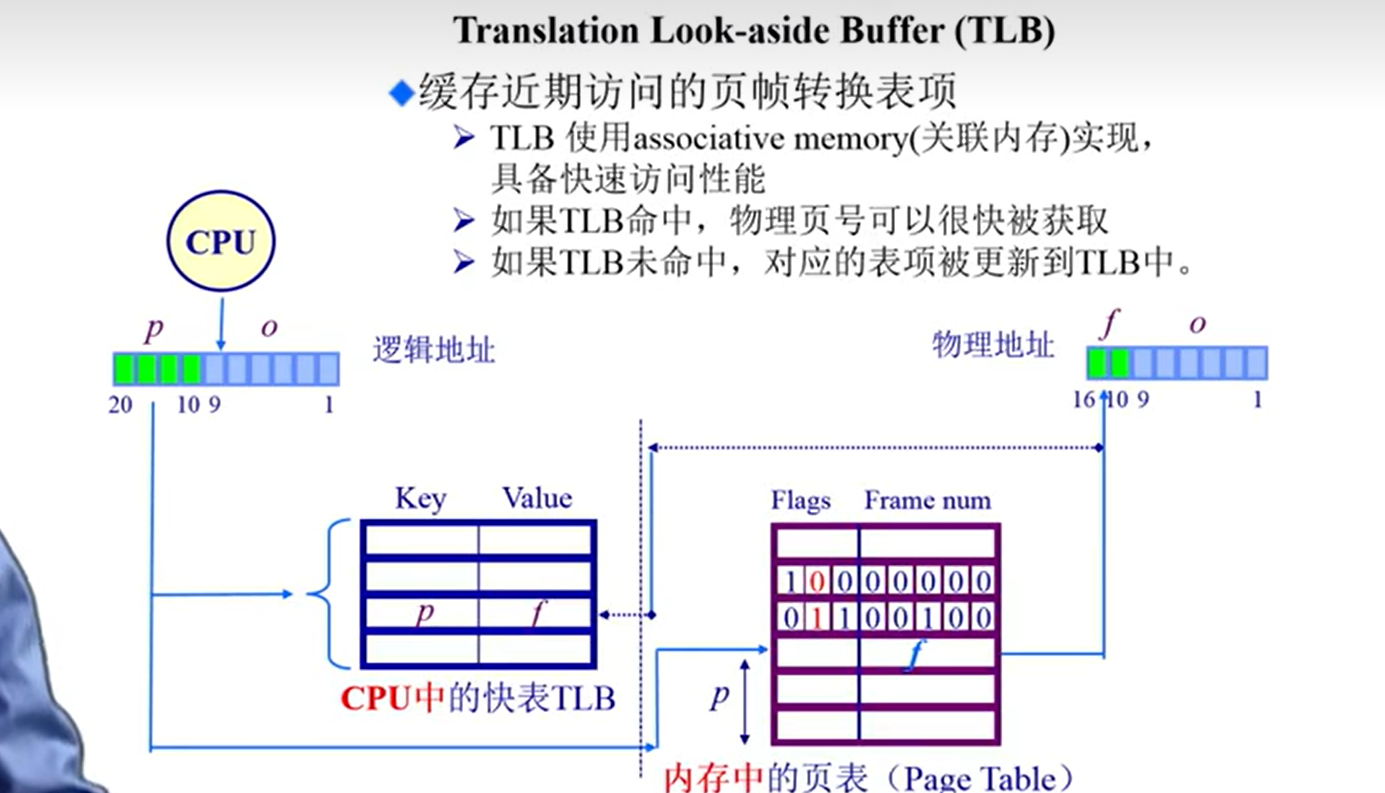
TLB
已看完:p10-p20(除p19) p23-p24
分段分页的基本概念
-
分段机制(了解)
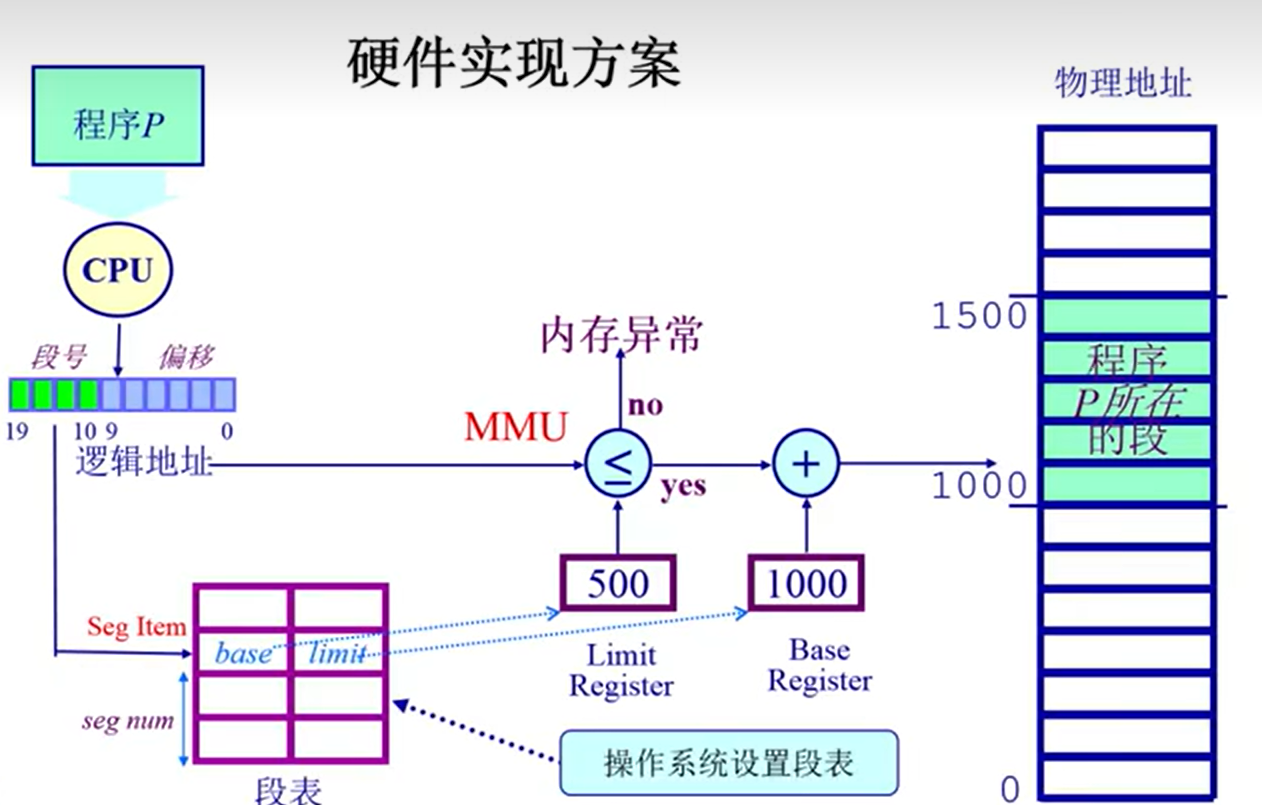
分段和分页的最大区别:段的大小是可变的,页的大小是不变的。
注意:page逻辑页 frame物理页
-
分页机制
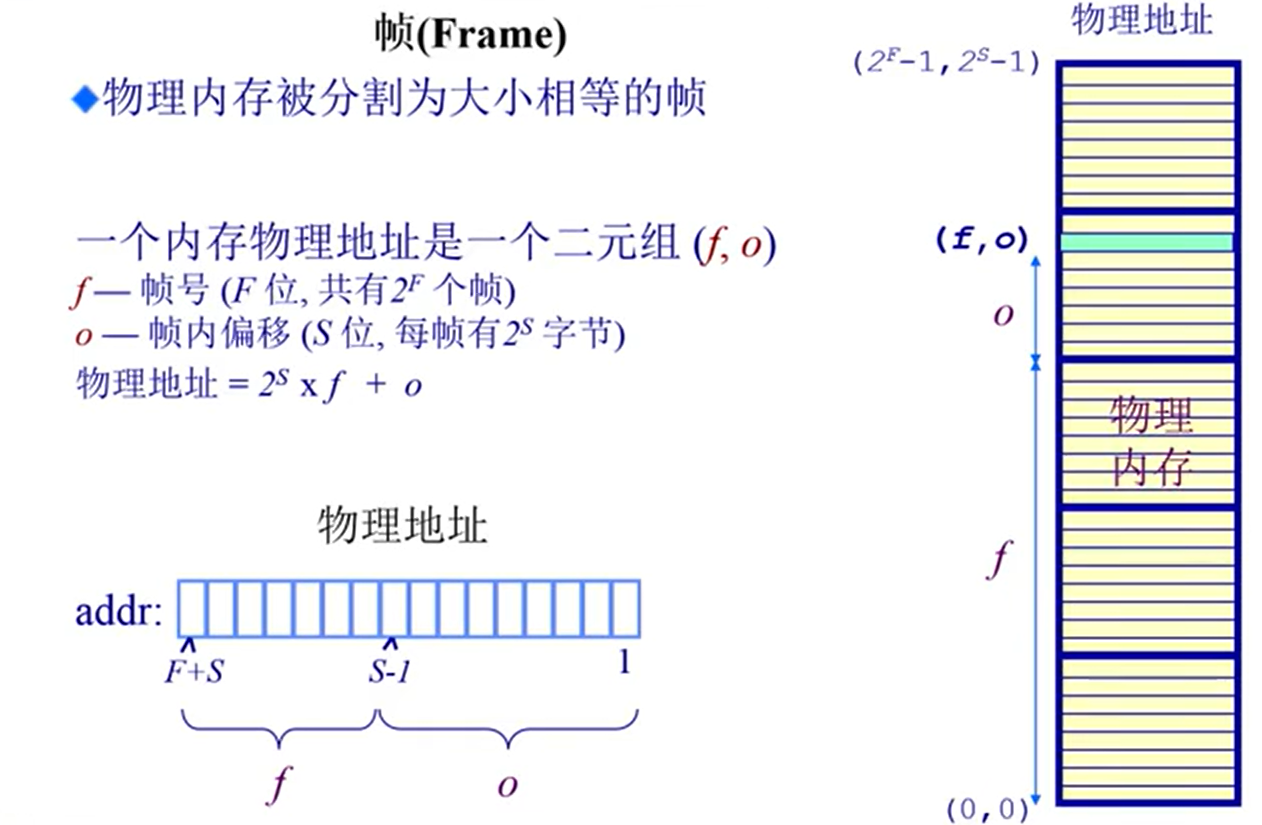
1. 页帧对应物理地址
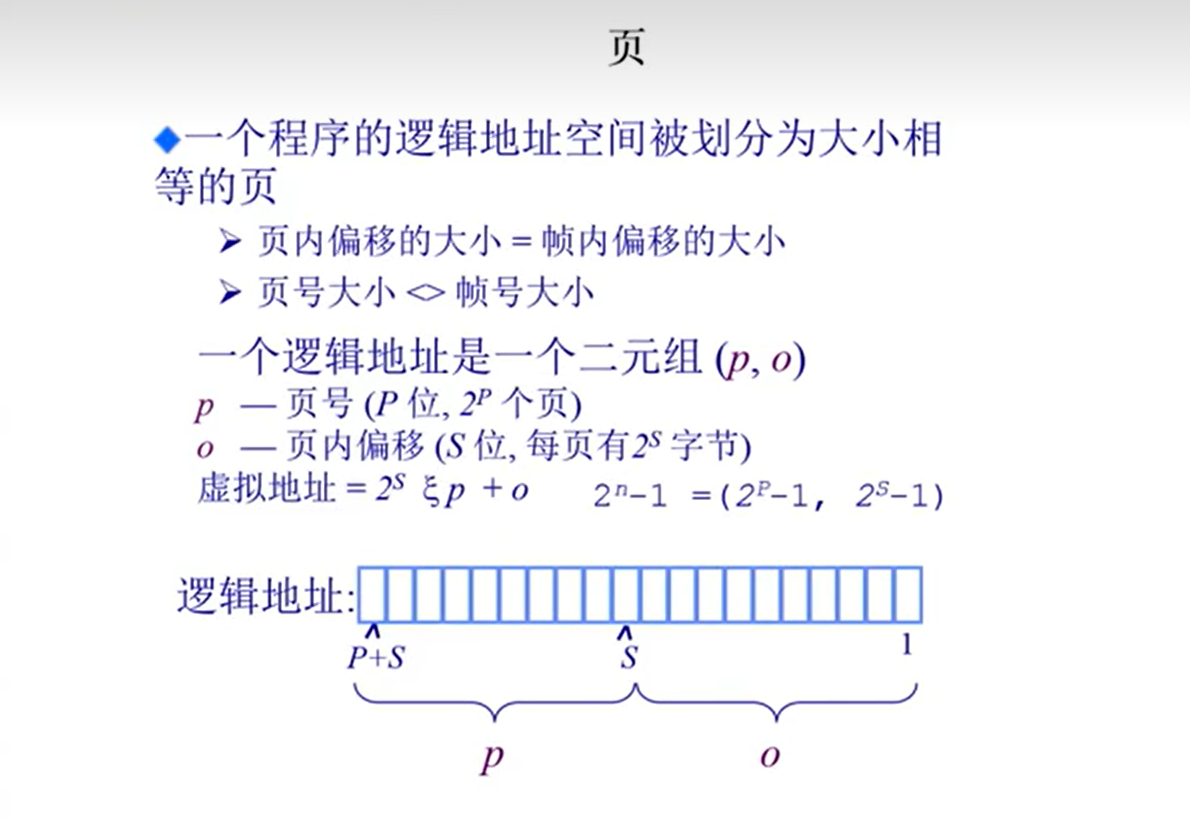
- 页对应逻辑地址
页寻址机制:
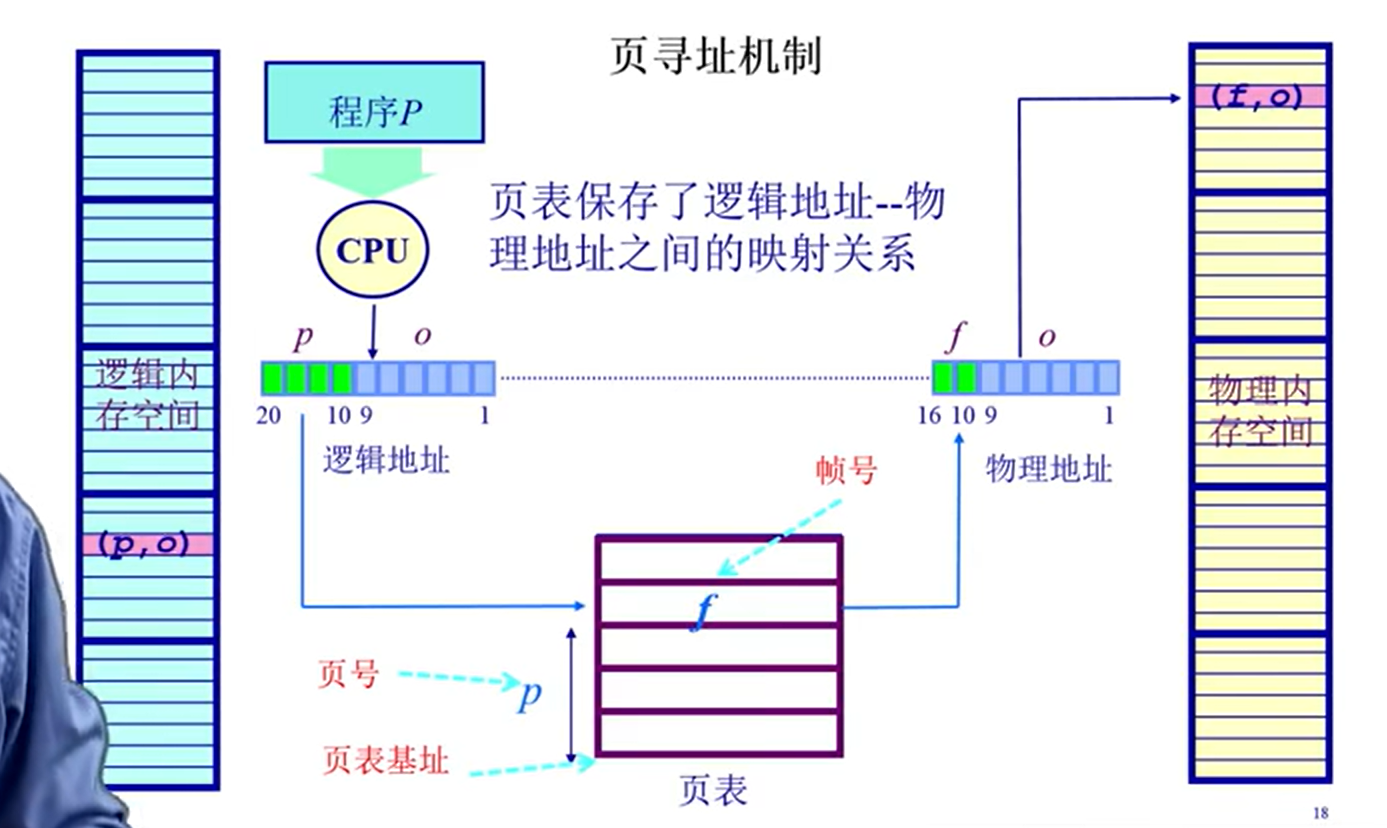
注:逻辑地址大于等于物理地址
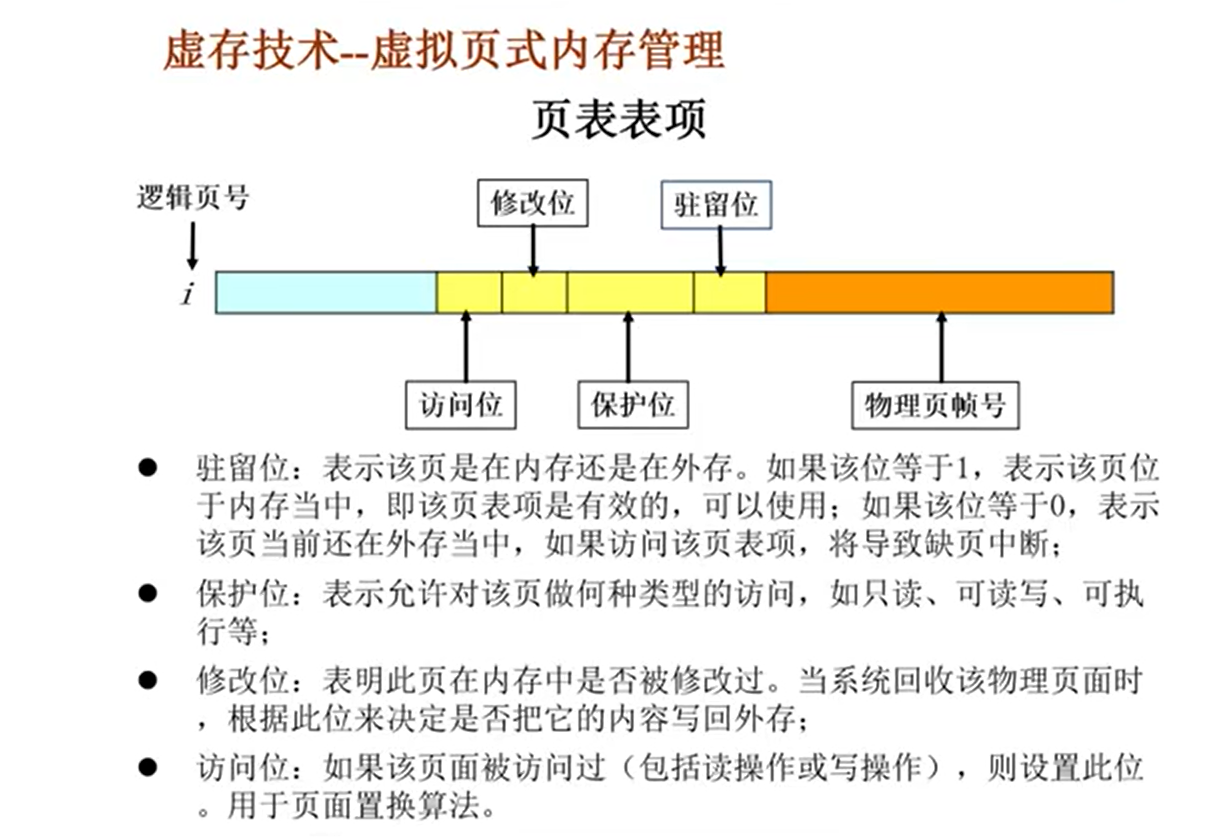
页表的实现
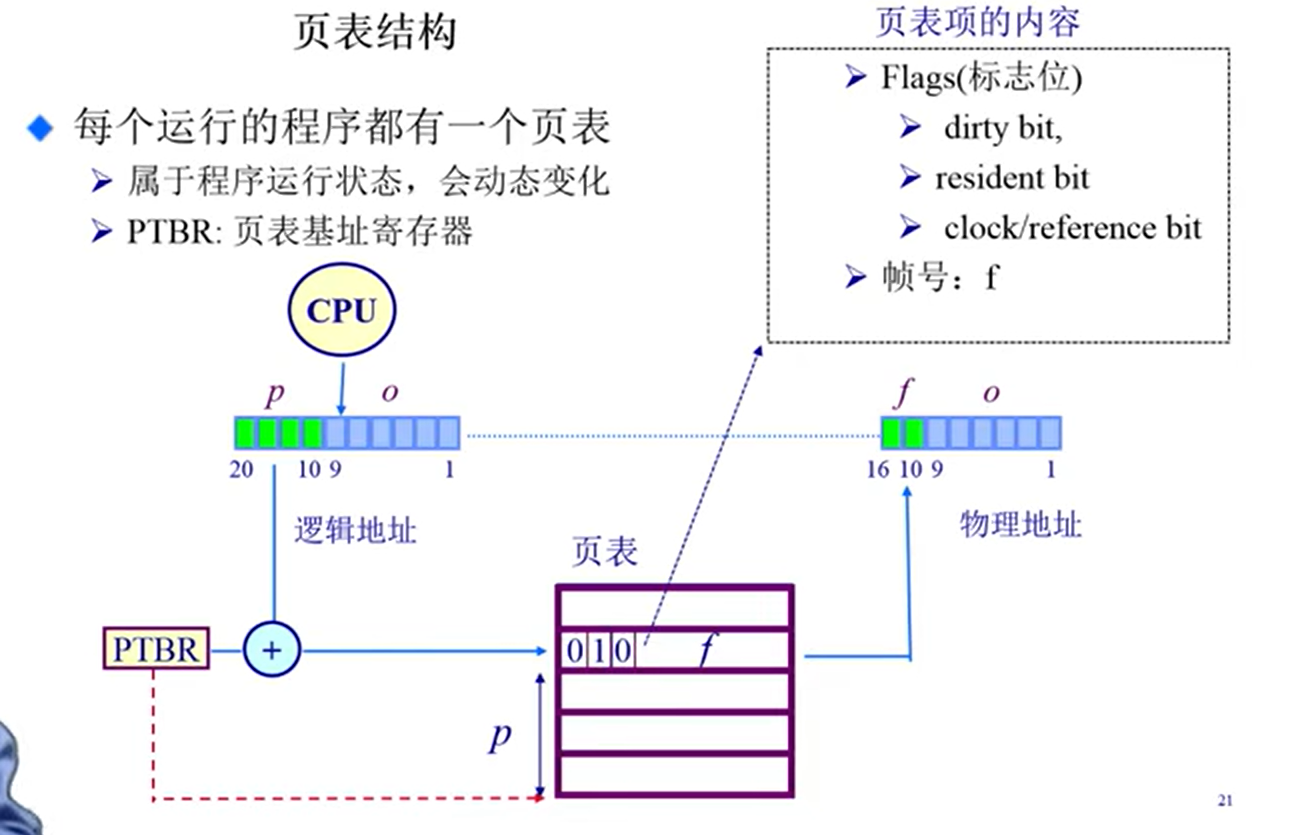
注意:页表中保存的不一定只有页帧号,可能还有其他的东西,不如是否存在,是否读写过
-
存在的问题

- 解决访问时间问题:TLB(类似cache:缓存的是页表中的内容)
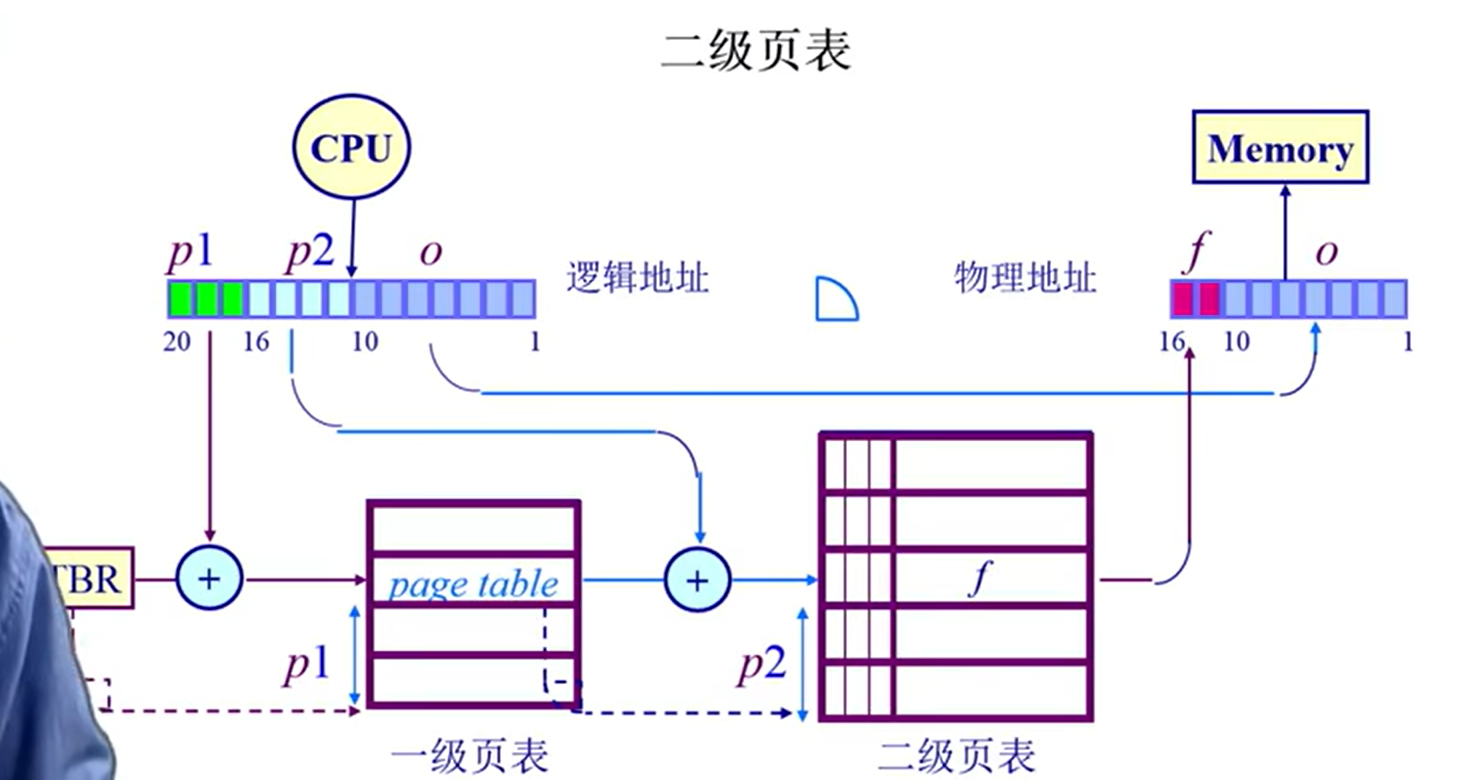
- 解决空间问题:多级页表项 为什么可以减少:若不存在的话,可以没有二级页表,节省内存空间
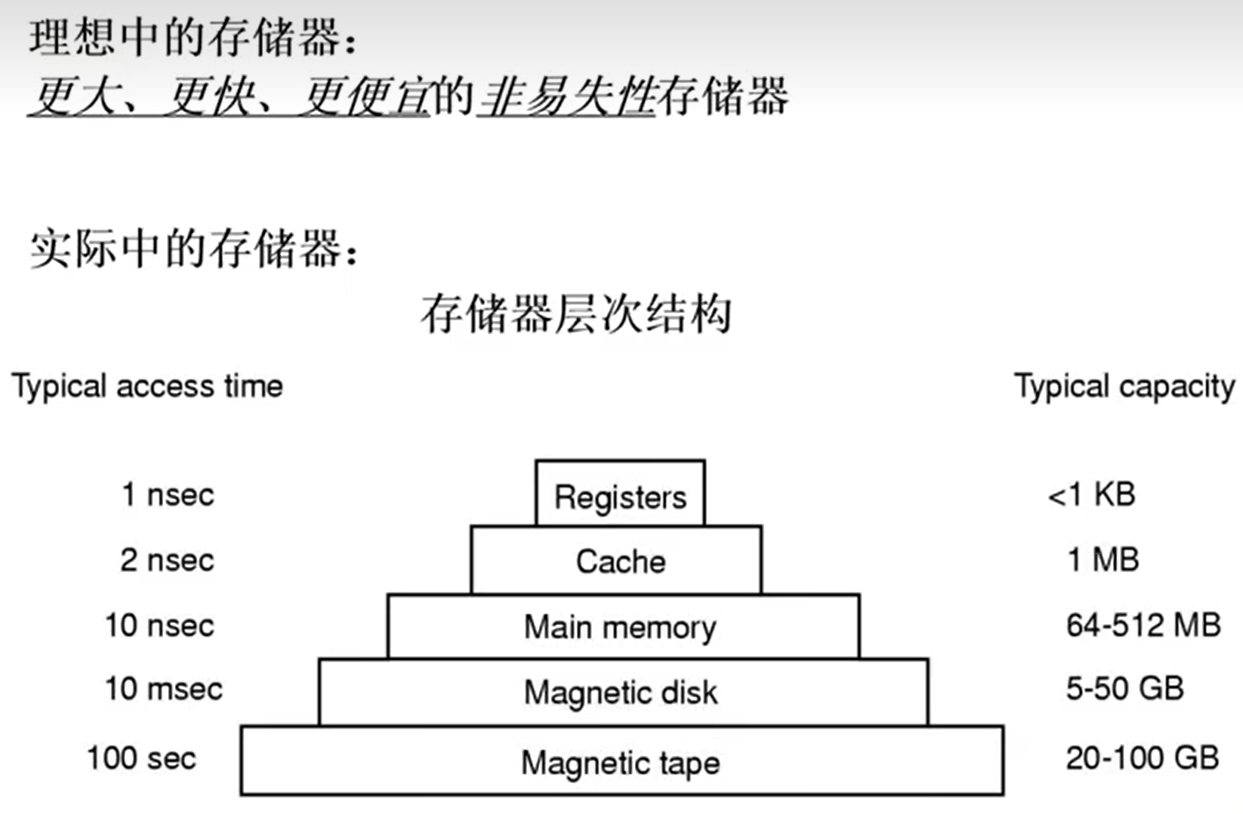
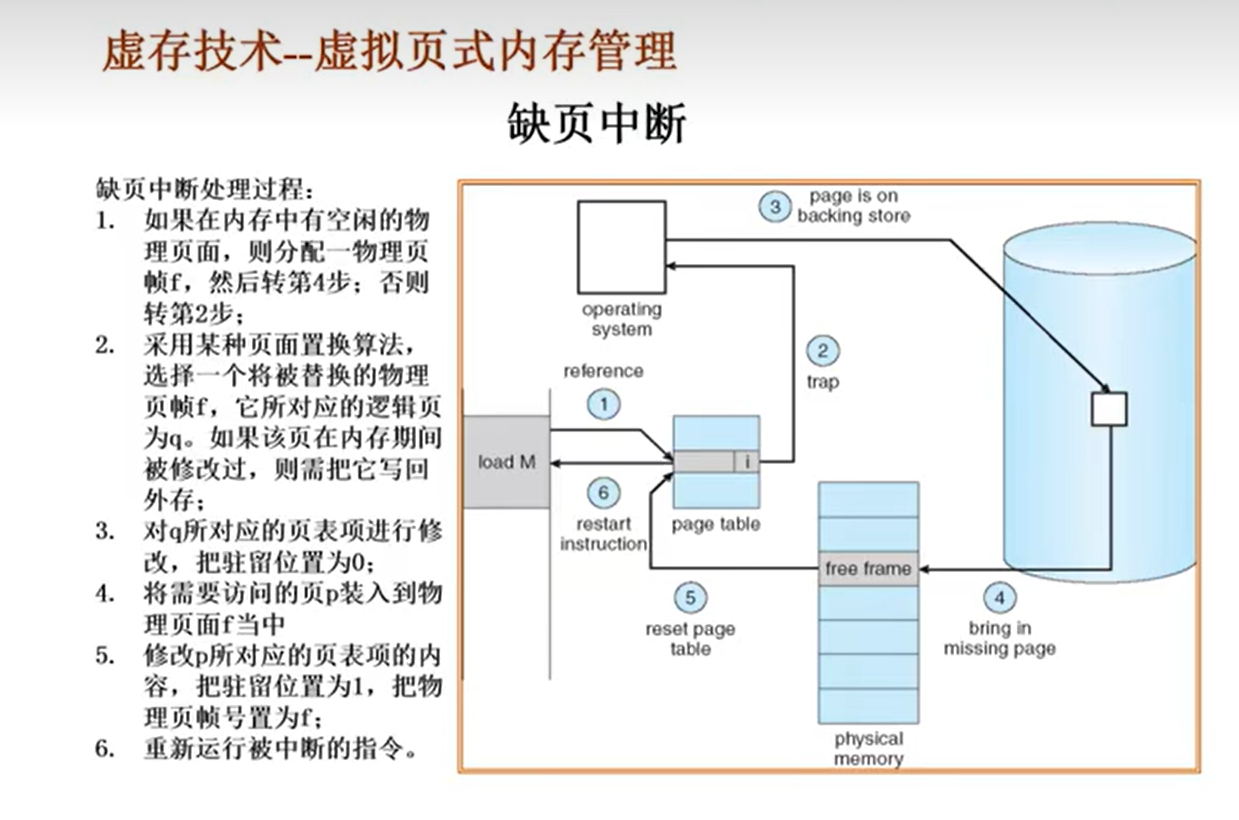
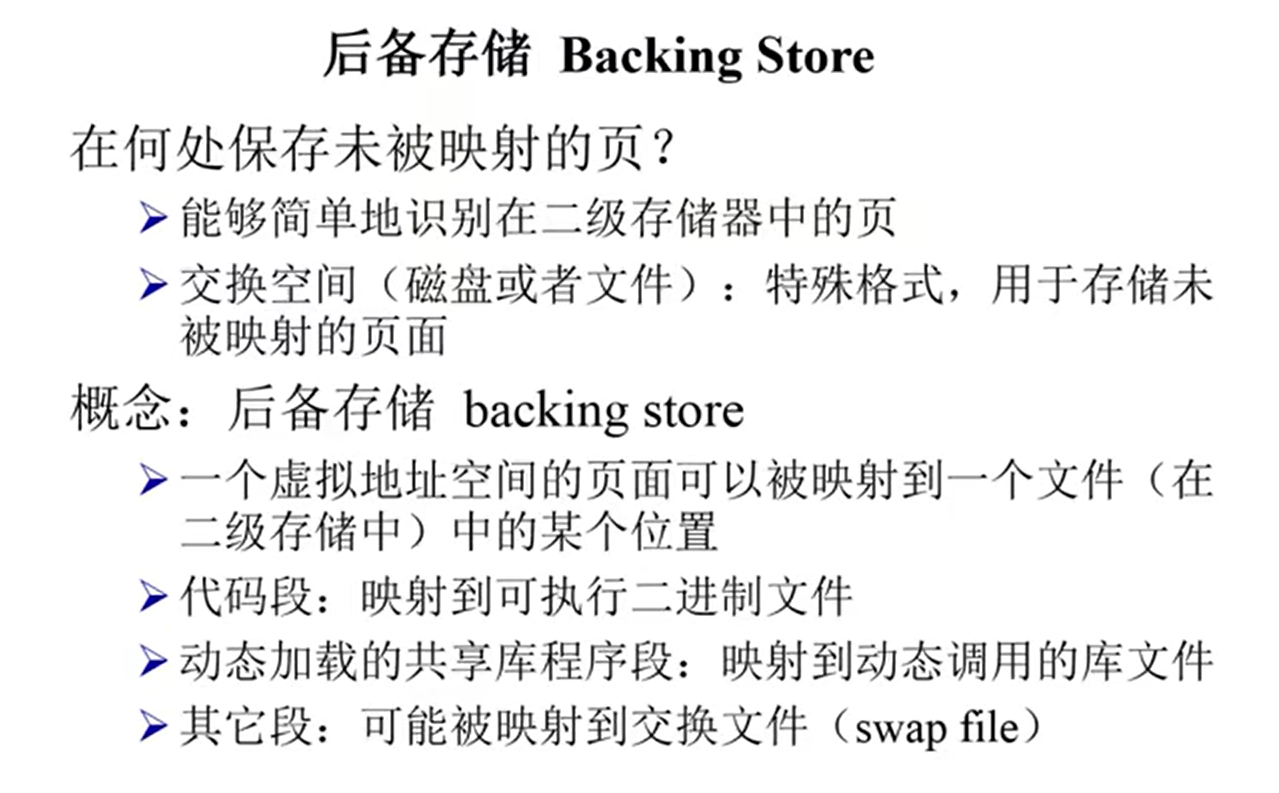
虚拟内存产生的原因:

虚拟内存技术
整体结构
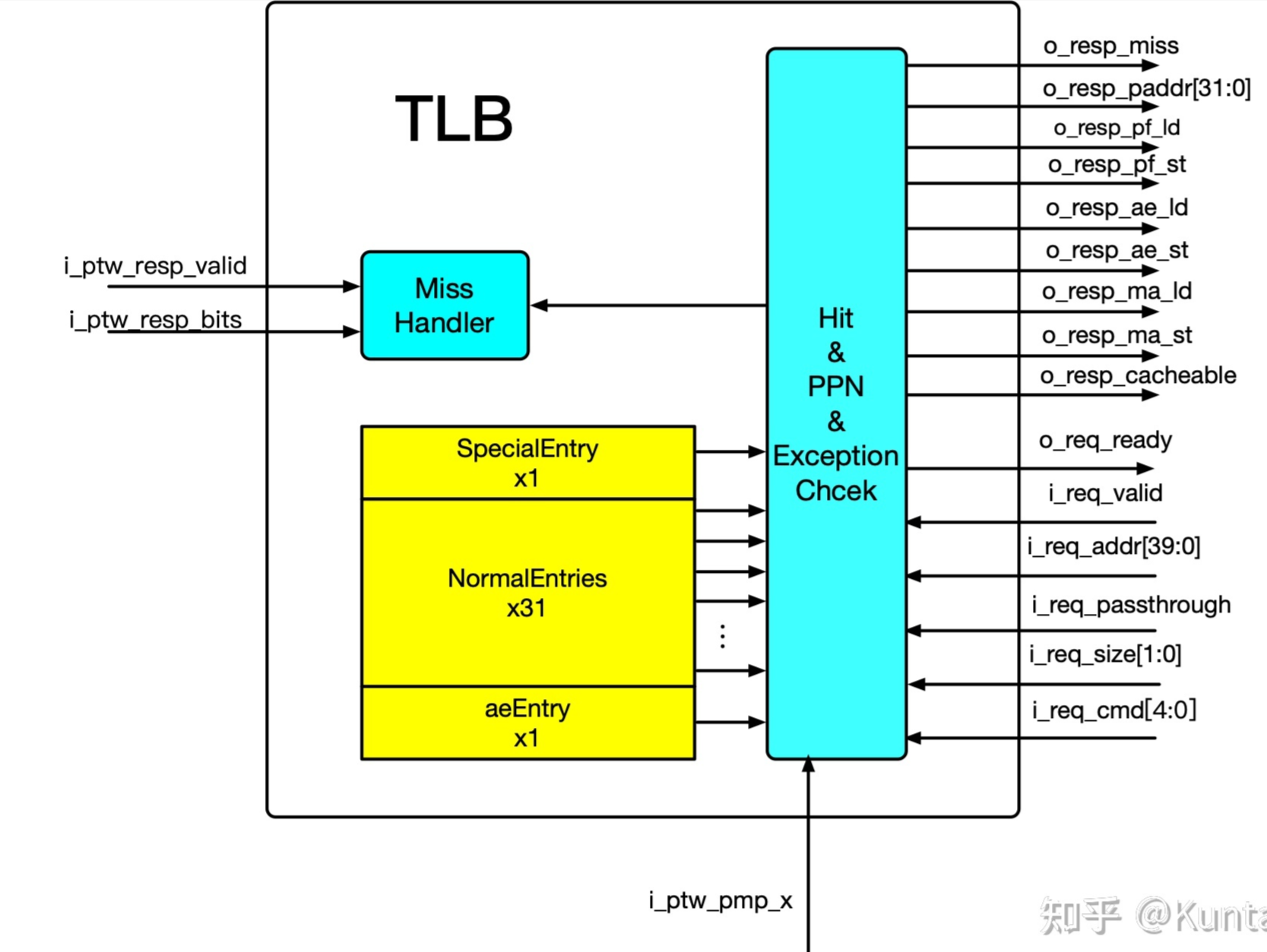
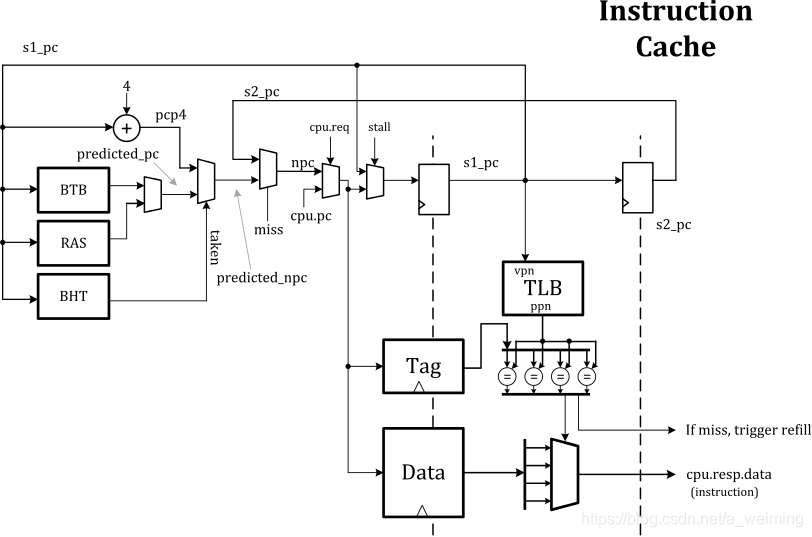
ICache
猜测:从cache有存取两个视角
存的视角
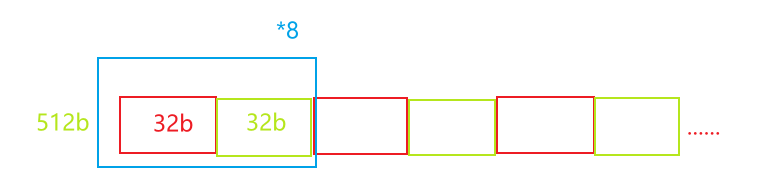
存的视角是把相同组的拼接起来再进行填充。
取的视角
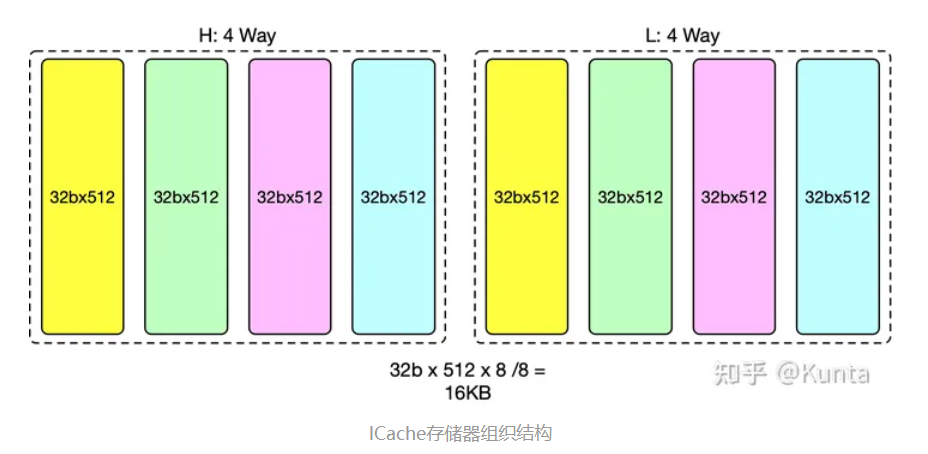
- 由于TL(Tilelink)的D包的数据宽度为64b,每条指令的宽度为32b,因此存储器首先划分为高低(H/L)两个半区。每个半区各组织成4路组相连,因此共计8个32b x 512的存储体(16KB)。图中着色相同的存储体属于相同的组相连路号。
- 单个存储体为512行,高低两个半区的共计1024行。
- 取指虚地址记为(s0_vaddr[38:0])。s0_vaddr[2]用于区分高低半区。s0_vaddr[11:3]用于确定在单个存储体(32b x 512)中的位置。因此,每次访问存储体,会从高半区或低半区中的4个存储体中取出共计4个32b指令数据。保存在s2_dout站台。根据组相连比较的结果,再从s2_dout的4个结果中选出1个作为最终的输出。
- 我的理解,本质上是512b*64的四路组相联cache
代码解析
* considering sets = 64, cachelineBytes =64
* use vaddr[11:6] to access tag_array
- 两个256b拼接起来为512b,即为64B,所以一行的大小为64B
- 由于2^56=64 所以可以区分64行,又因为32*512/256=64所以[11:6]可以访问tagarray
Rocket区分store指令和load指令的方式
如下图所示,为store指令:

如下图所示,为load指令:

他们的不同为(13,12)位,在idecode.scala中他们的控制信号都是相同的,唯一不同的是mem_size即对内存操作长度不同,在rocketchip中通过如下命令来实现:
//Rocketchip.scala
ex_reg_mem_size := Mux(usingHypervisor.B && id_system_insn, id_inst(0)(27, 26), id_inst(0)(13, 12))
//NBDcache.scala
amoalu.io.mask := new StoreGen(s2_req.size, s2_req.addr, 0.U, xLen/8).mask
//AMOALU.scala
class StoreGen(typ: UInt, addr: UInt, dat: UInt, maxSize: Int) {
val size = typ(log2Up(log2Up(maxSize)+1)-1,0)
def misaligned: Bool =
(addr & ((1.U << size) - 1.U)(log2Up(maxSize)-1,0)).orR
def mask = {
var res = 1.U
for (i <- 0 until log2Up(maxSize)) {
val upper = Mux(addr(i), res, 0.U) | Mux(size >= (i+1).U, ((BigInt(1) << (1 << i))-1).U, 0.U)
val lower = Mux(addr(i), 0.U, res)
res = Cat(upper, lower)
}
res
}
protected def genData(i: Int): UInt =
if (i >= log2Up(maxSize)) dat
else Mux(size === i.U, Fill(1 << (log2Up(maxSize)-i), dat((8 << i)-1,0)), genData(i+1))
def data = genData(0)
def wordData = genData(2)
}
补:此处有点不太懂,猜测由地址和mem_size来产生mask,估计可能和cache的机制有关
| 原始值(x) | 转化值(y) |
|---|---|
| 0 | 0000 0001 |
| 1 | 0000 0011 |
| 2 | 0000 1111 |
| 3 | 1111 1111 |
y=1<<2^x-1=1<<(1<<x)-1;
分析Config文件中chisel的高级用法:Parameters

private class PartialParameters(
f: (View, View, View) => PartialFunction[Any, Any])
extends Parameters {
protected[config] def chain[T](
site: View,
here: View,
up: View,
pname: Field[T]
) = {
val g = f(site, here, up)
if (g.isDefinedAt(pname)) Some(g.apply(pname).asInstanceOf[T])
else up.find(pname)
}
}
chain[T]方法是受保护的,只能在包含它的类或对象以及位于同一包(或包对象)config内的类或对象中访问。- 在
config包之外的地方,chain[T]方法是不可见的,不能被访问或调用
在 Scala 中,
isDefinedAt是用于检查部分函数(Partial Function)的一个方法。部分函数是一种特殊的函数,它只在某些输入值上有定义,而在其他输入值上没有定义。通常,部分函数是使用case语句定义的。以下是
isDefinedAt方法的用法示例:// 定义一个部分函数,它只在某些输入值上有定义 val divide: PartialFunction[Int, Int] = { case x if x != 0 => 10 / x } // 使用 isDefinedAt 方法检查输入是否在部分函数的定义域内 println(divide.isDefinedAt(5)) // 输出 true println(divide.isDefinedAt(0)) // 输出 false // 使用部分函数 println(divide(5)) // 输出 2,因为 10 / 5 = 2在上面的示例中,我们首先定义了一个部分函数
divide,它只在输入值不等于零的情况下有定义,否则会抛出异常。然后,我们使用isDefinedAt方法来检查输入是否在部分函数的定义域内。最后,我们调用部分函数divide来进行计算。
isDefinedAt方法允许你在应用部分函数之前先检查输入是否有效,以避免因为无效的输入而导致运行时错误。这在处理可能存在不完整数据或无效输入的情况下非常有用。
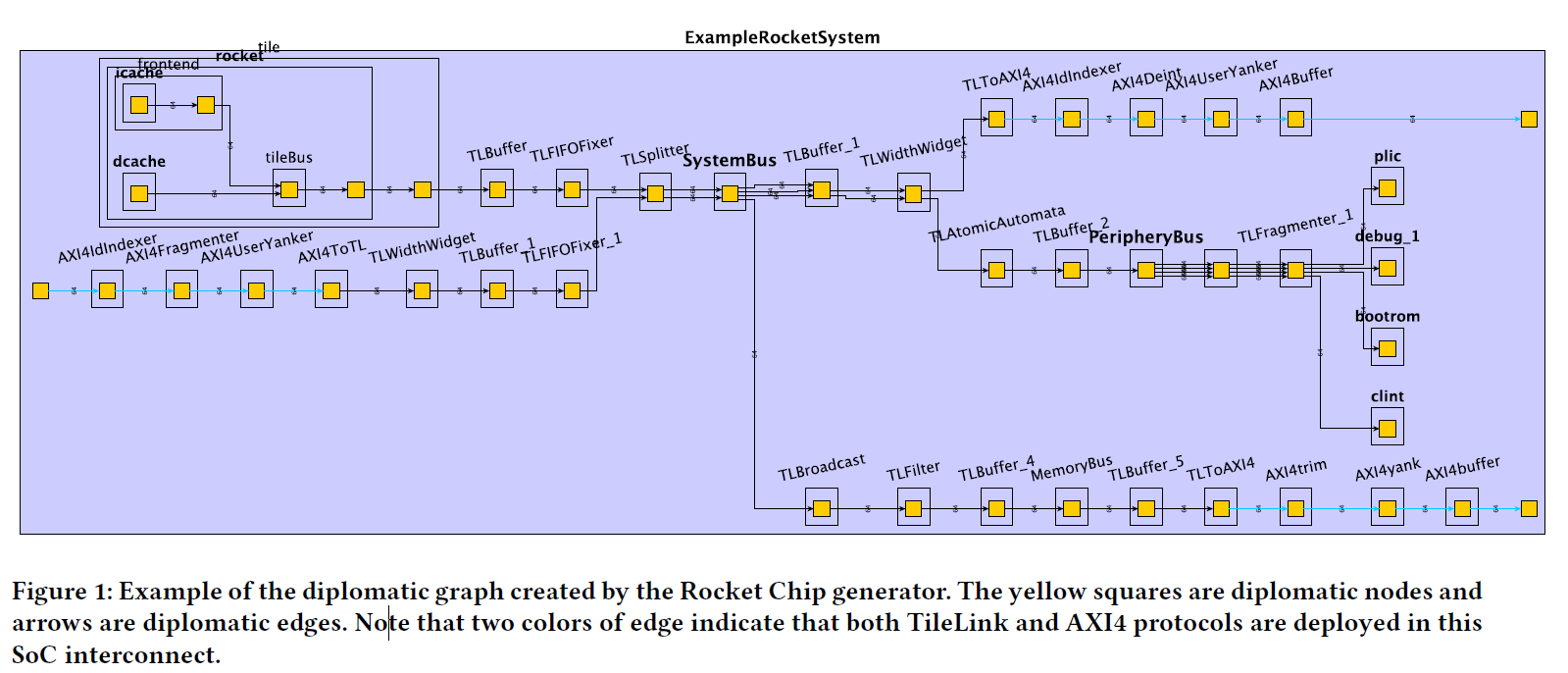
ExampleRocketSystem
- 结构图
mul/div数据通路:
- bypass:
def id_sboard_clear_bypass(r: UInt) = {
// ll_waddr arrives late when D$ has ECC, so reshuffle the hazard check
if (!tileParams.dcache.get.dataECC.isDefined) ll_wen && ll_waddr === r
else div.io.resp.fire && div.io.resp.bits.tag === r || dmem_resp_replay && dmem_resp_xpu && dmem_resp_waddr === r
}
- scoreboard
class Scoreboard(n: Int, zero: Boolean = false)
{
def set(en: Bool, addr: UInt): Unit = update(en, _next | mask(en, addr))
def clear(en: Bool, addr: UInt): Unit = update(en, _next & ~mask(en, addr))
def read(addr: UInt): Bool = r(addr)
def readBypassed(addr: UInt): Bool = _next(addr)
private val _r = RegInit(0.U(n.W))
private val r = if (zero) (_r >> 1 << 1) else _r
private var _next = r
private var ens = false.B
private def mask(en: Bool, addr: UInt) = Mux(en, 1.U << addr, 0.U)
private def update(en: Bool, update: UInt) = {
_next = update
ens = ens || en
when (ens) { _r := _next }
}
}
取指部分
补:分支指令(branch instructions):在处理器中,有条件分支指令通常会根据某些条件(如条件码或条件寄存器的值)来确定分支的方向。如果条件满足,分支被称为 “taken”,表示程序会执行分支指令指定的分支。如果条件不满足,分支被称为 “not taken”,表示程序会继续执行顺序指令。
next(addr)
private val _r = RegInit(0.U(n.W))
private val r = if (zero) (_r >> 1 << 1) else _r
private var _next = r
private var ens = false.B
private def mask(en: Bool, addr: UInt) = Mux(en, 1.U << addr, 0.U)
private def update(en: Bool, update: UInt) = {
_next = update
ens = ens || en
when (ens) { _r := _next }
}
}
## 取指部分
[参考链接](https://www.jianshu.com/u/920968825c5b)
补:分支指令(branch instructions):在处理器中,有条件分支指令通常会根据某些条件(如条件码或条件寄存器的值)来确定分支的方向。如果条件满足,分支被称为 "taken",表示程序会执行分支指令指定的分支。如果条件不满足,分支被称为 "not taken",表示程序会继续执行顺序指令。

















 5395
5395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









