






下述笔记代码源于B站“PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】”
 https://www.bilibili.com/video/BV1hE411t7RN?p=27&spm_id_from=pageDriver&vd_source=b2ecc3cf53170c35e341f743eee0cfb4
https://www.bilibili.com/video/BV1hE411t7RN?p=27&spm_id_from=pageDriver&vd_source=b2ecc3cf53170c35e341f743eee0cfb4
Dataset类的使用(提供一种方式获取数据及其label)

1、调用dataset
from torch.utils.data import Dataset2、图片的调用
img_path = "" //图片所在路径
//注意windows中将路径中的'\'换为'\\'
img = Image.open(img_path)
img.show() //展示图片from torch.utils.data import Dataset
from PIL import Image
import os
# MyData类要继承Dataset类,重写__getitem__和__len__
class Mydata(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
# 获取数据集的列表
self.img_path = os.listdir(self.path)
# 函数作用是根据索引idx取数据集中的每一个数据(图片)及其label
def __getitem__(self, idx):
# 获取图片名称
img_name = self.img_path[idx]
# 获取图片路径
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
# 列表长度
def __len__(self):
return len(self.img_path)
root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = Mydata(root_dir, ants_label_dir)
bees_dataset = Mydata(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
Tensorboard的使用
SummaryWriter类的使用
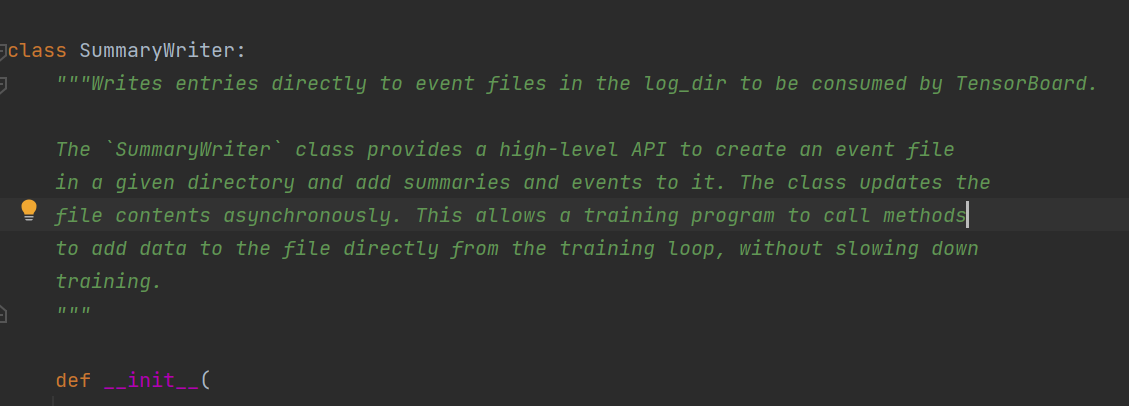
向log_dir文件夹写入事件文件,该事件文件可以被TensorBoard解析
from torch.utils.tensorboard import SummaryWriter
# SummaryWriter类实例化
writer = SummaryWriter("logs")
# 常用的两个方法,image(图片),scalar(添加标量数据)
writer.add_image()
writer.add_scalar()
writer.close()add_scalar()方法的使用
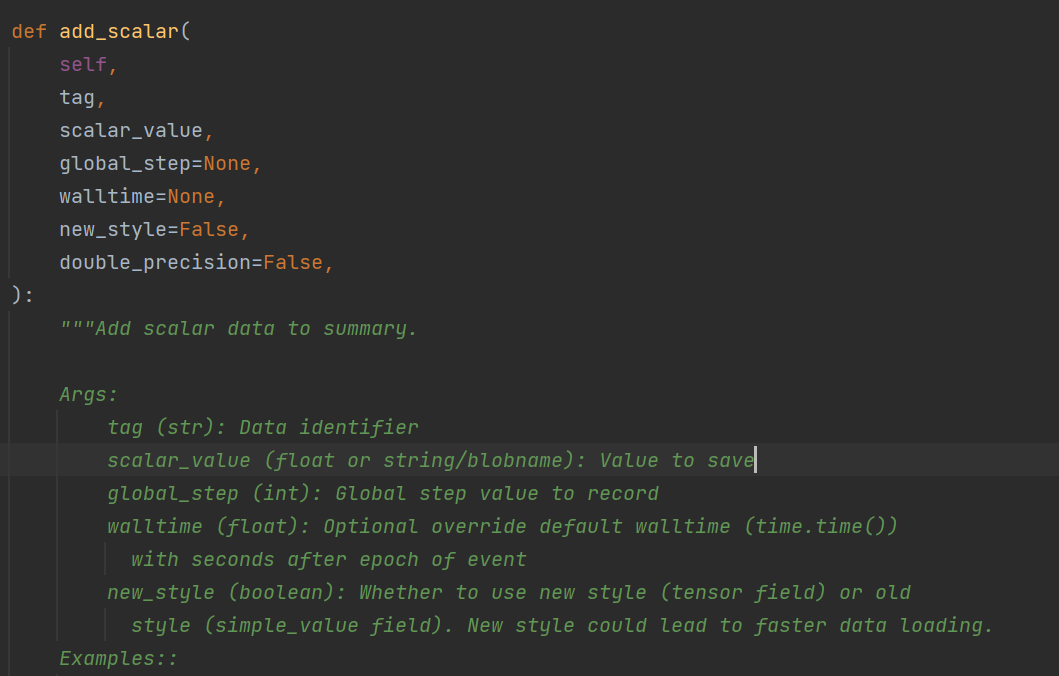
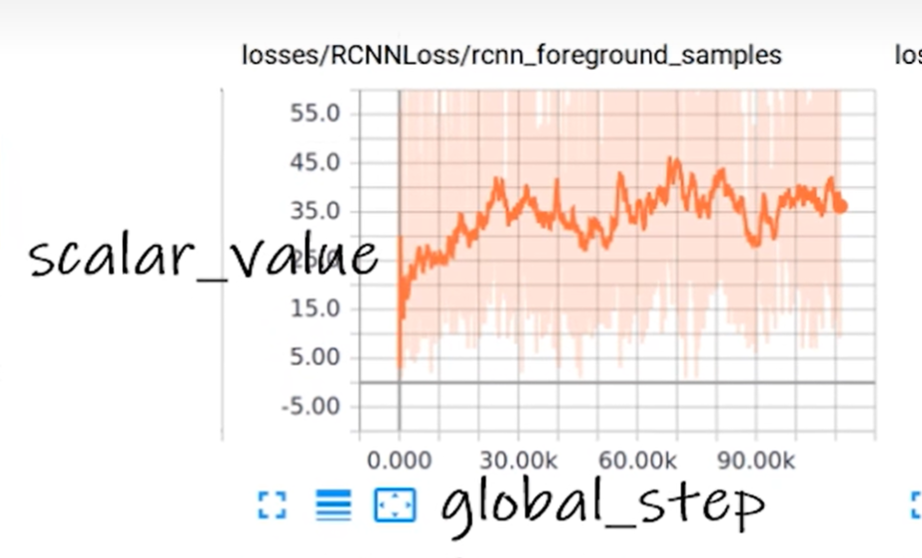
tag相当于图像的标题
scalar_value相当于图像y轴
global_step相当于图像x轴
from torch.utils.tensorboard import SummaryWriter
# SummaryWriter类实例化
writer = SummaryWriter("logs")
# y = x
for i in range(100):
writer.add_scalar("y=x", i, i)
writer.close()
# 终端运行
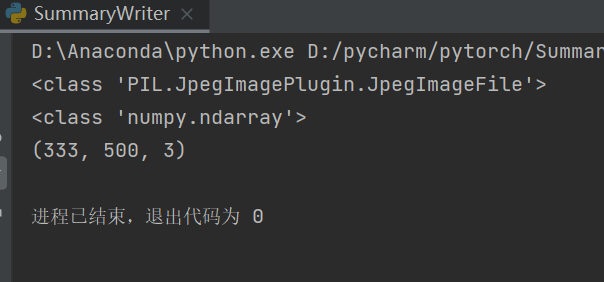
tensorboard --logdir "logs" --host=127.0.0.1 (--port=6007)add_image()方法的使用
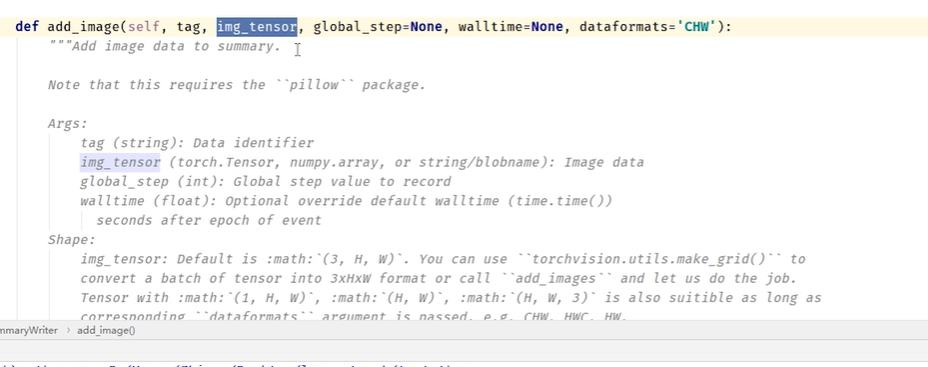

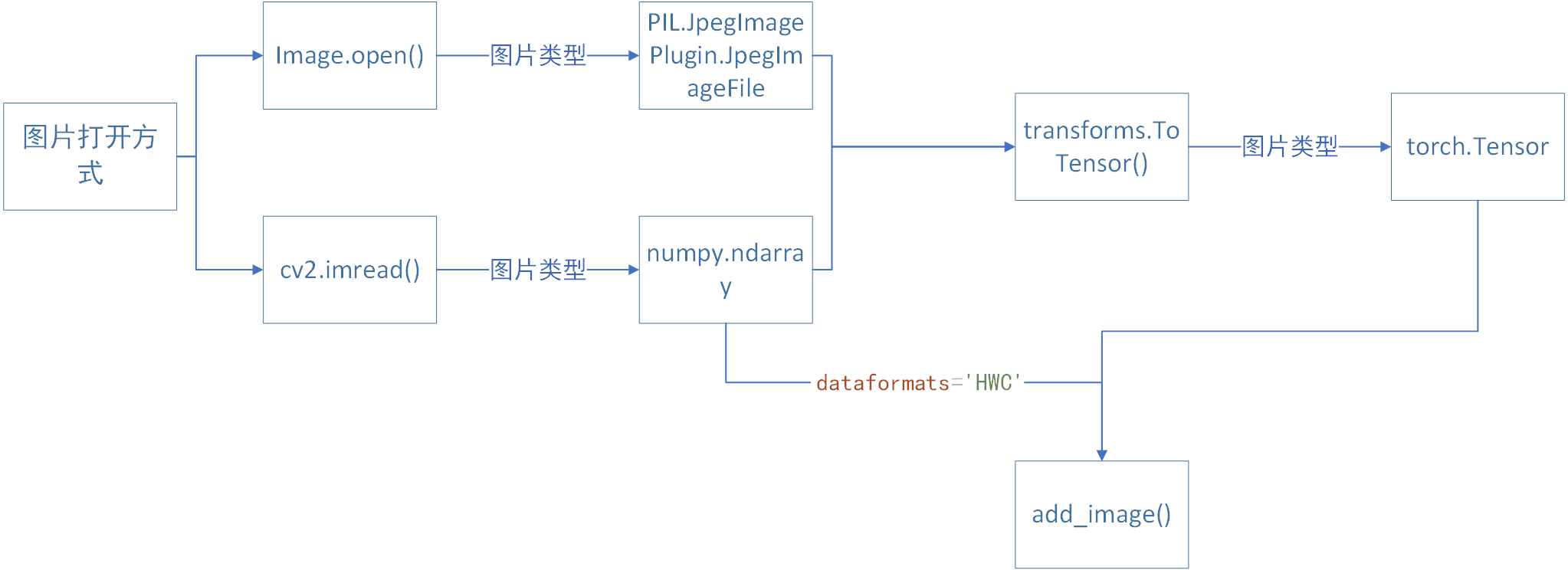
分析上述要求,img_tensor的类型必须是torch.Tensor, numpy.ndarray, or string/blobname中的一个
img_tensor的shape,为"CHW"形式的时候不用管,若是其他形式,需添加dataformats='形式'
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
# SummaryWriter类实例化
writer = SummaryWriter("logs")
image_path = "dataset/train/ants/0013035.jpg"
img_PIL = Image.open(image_path)
print(type(img_PIL))
# 使用上述函数得到的img_PIL是PIL.JpegImagePlugin.JpegImageFile类型的,不满足
# add_image()方法对img_tensor的类型要求,所以使用Image将其类型转换为numpy.ndarray
img_array = np.array(img_PIL)
print(type(img_array))
print(img_array.shape)
# img_array的shape不是"CHW"形式,而是"HWC"形式,所以要增加语句"dataformats='HWC'"
writer.add_image("test", img_array, 1, dataformats='HWC')
# y = x
for i in range(100):
writer.add_scalar("y=x", 2*i, i)
writer.close()
上述例子的输出结果
Transforms的使用
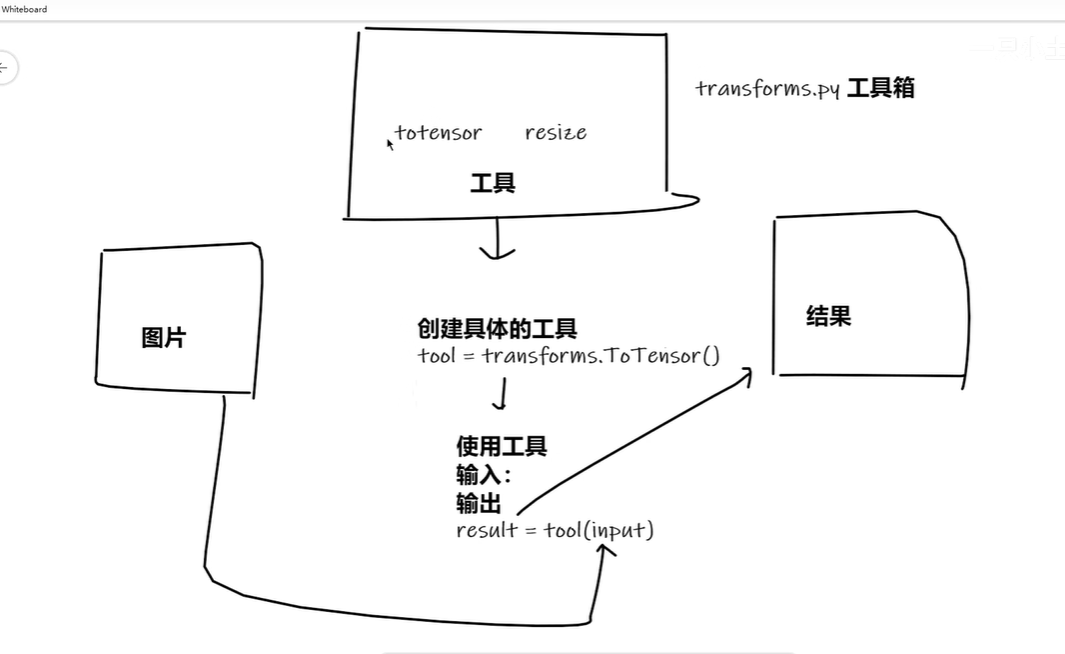
from torchvision import transformstransforms主要依赖于transforms.py文件,其相当于一个工具箱,其中的class就是各种工具,通过transforms将某一格式的图片转换为想要的结果
transforms.py中的各种class
如何使用transforms
from PIL import Image
from torchvision import transforms
# python的用法 -> tensor数据类型
# 通过 transforms.ToTensor 解决两个问题
# 绝对路径 D:\pycharm\pytorch\dataset\train\ants\20935278_9190345f6b.jpg
# 相对路径 dataset/train/ants/20935278_9190345f6b.jpg
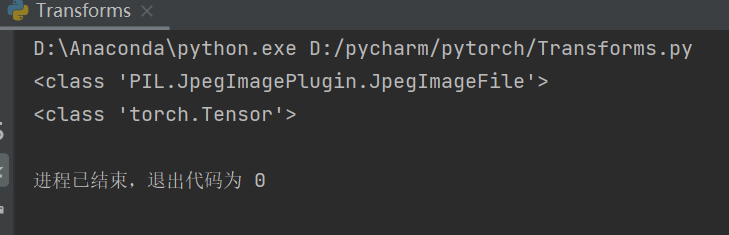
img_path = "dataset/train/ants/20935278_9190345f6b.jpg"
img = Image.open(img_path)
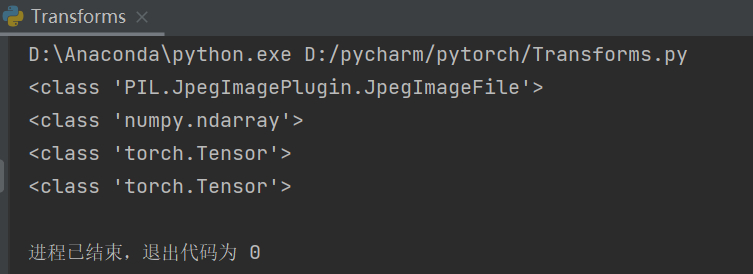
print(type(img))
# 1、transforms该如何使用
# 类不接受任何参数,要传参数必须实例化这个类,再用实例对象传参
# 所以这里tensor_trans实例化,再通过tensor_trans传参
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
# ToTensor()将对象转换为tensor类型
print(type(tensor_img))
为什么需要Tensor数据类型

综合案例1
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import cv2
img_path = "dataset/train/ants/20935278_9190345f6b.jpg"
PIL_img = Image.open(img_path)
print(type(PIL_img))
cv_img = cv2.imread(img_path)
print(type(cv_img))
writer = SummaryWriter("logs")
# 类不接受任何参数,要传参数必须实例化这个类,再用实例对象传参
# 所以这里tensor_trans实例化,再通过tensor_trans传参
tensor_trans = transforms.ToTensor()
tensor_PIL_img = tensor_trans(PIL_img)
tensor_cv_img = tensor_trans(cv_img)
print(type(tensor_PIL_img))
print(type(tensor_cv_img))
writer.add_image("Tensor_img", tensor_PIL_img, 1)
writer.add_image("Tensor_img", cv_img, 2, dataformats='HWC')
writer.add_image("Tensor_img", tensor_cv_img, 3)
writer.close()
step1与原图片一样,step2,step3为什么颜色会发生改变?



常见的Transforms
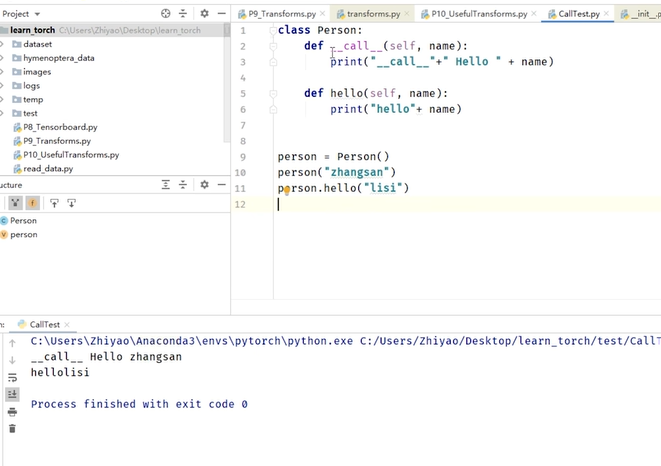
python中__call__的用法
ToTensor的使用
见上
Normalize的使用
mean:均值 std:标准差

根据公式,图片通道的输入值为[0, 1]的值,那么经过Normalize之后范围就变为[-1, 1]
(均值,标准差取其他值也可,这里0.5作为示范)
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path = "dataset/train/bees/17209602_fe5a5a746f.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs")
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
writer.add_image("ToTensor", tensor_img)
print(tensor_img[0][0][0])
# 图片有RGB三个通道,所以均值,标准差各三个值
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(tensor_img)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
writer.close()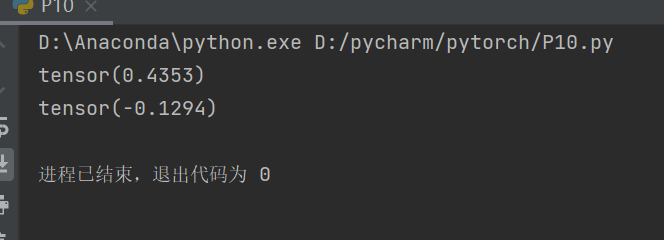
Resize的使用
对图片进行等比缩放
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path = "dataset/train/bees/17209602_fe5a5a746f.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs")
tensor_trans = transforms.ToTensor()
img_tensor = tensor_trans(img)
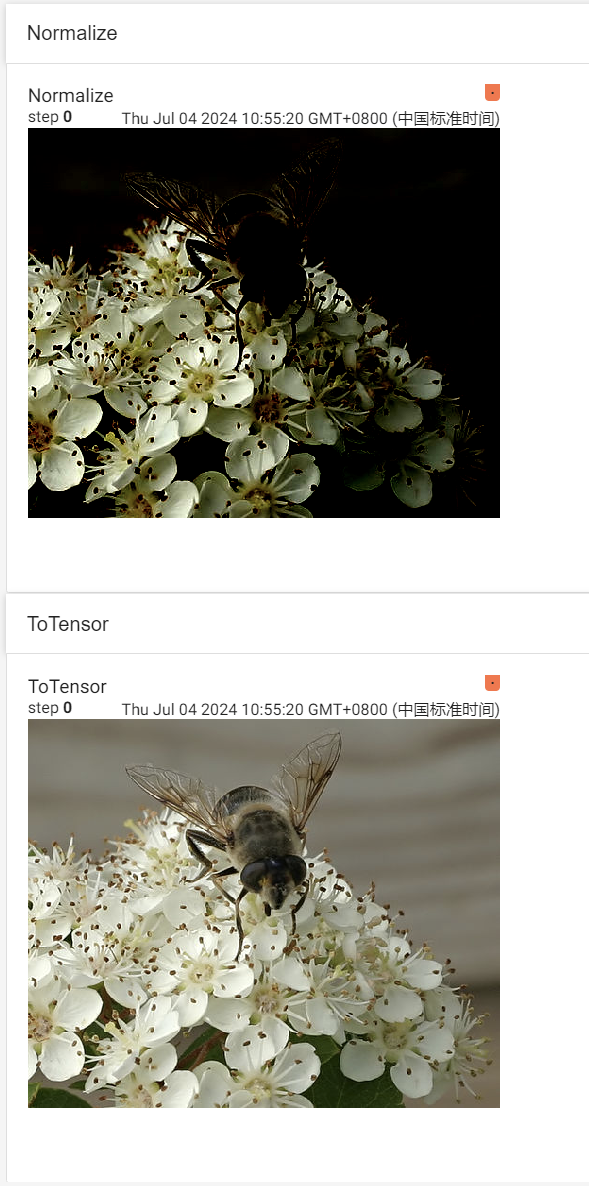
writer.add_image("Tensor", img_tensor)
print(img.size)
trans_resize = transforms.Resize((50, 50))
# img PIL -> resize -> img_resize PIL
img_resize = trans_resize(img)
print(img_resize)
# img_resize -> ToTensor -> img_resize tensor
img_resize = tensor_trans(img_resize)
writer.add_image("Resize", img_resize)
writer.close()如下所示,不过参数未设置合理,导致图片不清晰
compose的使用

transform1 = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
torchvision中的数据集使用
使用torchvision提供的标准数据集
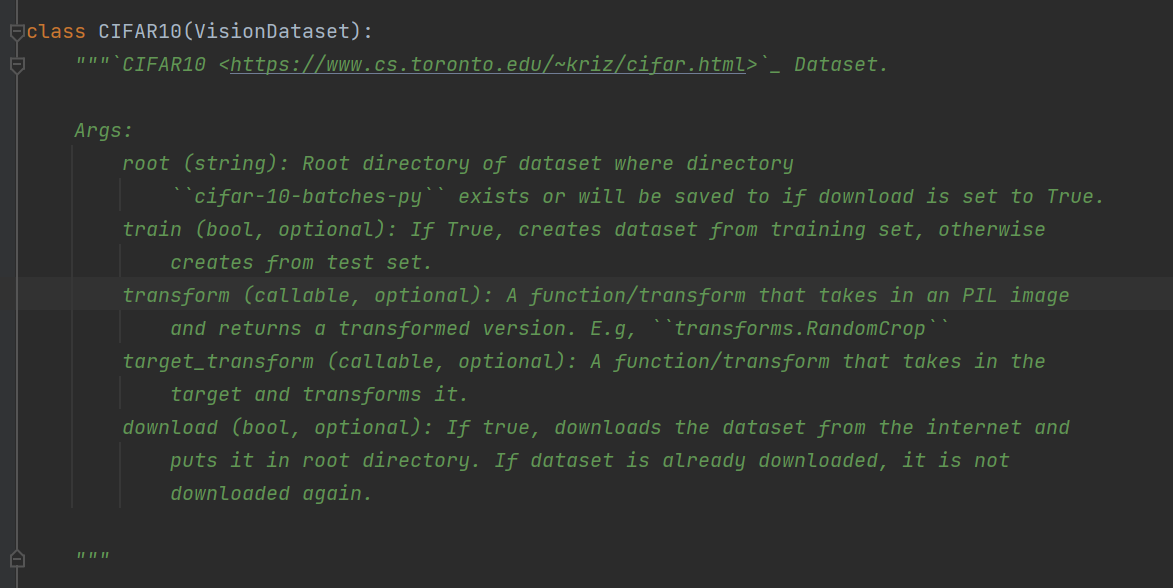
eg: CIFAR10
root: 数据在什么位置, train:为True表示创建了训练集,反之为测试集
transform:对数据集中的数据进行的transform变换
download:设置为True会自动从网上下载数据,Fasle不会
import torchvision
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, download=True)
# root表示数据集应该存放在哪个位置
print(test_set[0])
print(test_set.classes)
img, target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
img.show()import torchvision
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
# root表示数据集应该存放在哪个位置
print(test_set[0])DataLoader的使用
DataLoader是Pytorch中用来处理模型输入数据的一个工具类。组合了数据集(dataset) + 采样器(sampler),并在数据集上提供单线程或多线程(num_workers )的可迭代对象。在DataLoader中有多个参数,这些参数中重要的几个参数的含义说明如下:
1. epoch:所有的训练样本输入到模型中称为一个epoch;
2. iteration:一批样本输入到模型中,成为一个Iteration;
3. batchszie:批大小,决定一个epoch有多少个Iteration;
4. 迭代次数(iteration)=样本总数(epoch)/批尺寸(batchszie)
5. dataset (Dataset) – 决定数据从哪读取或者从何读取;
6. batch_size (python:int, optional) – 批尺寸(每次训练样本个数,默认为1)
7. shuffle (bool, optional) –每一个 epoch是否为乱序 (default: False);
8. num_workers (python:int, optional) – 是否多进程读取数据(默认为0);
9. drop_last (bool, optional) – 当样本数不能被batchsize整除时,最后一批数据是否舍弃(default: False)
10. pin_memory(bool, optional) - 如果为True会将数据放置到GPU上去(默认为false) import torchvision
from torch.utils.data import DataLoader
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
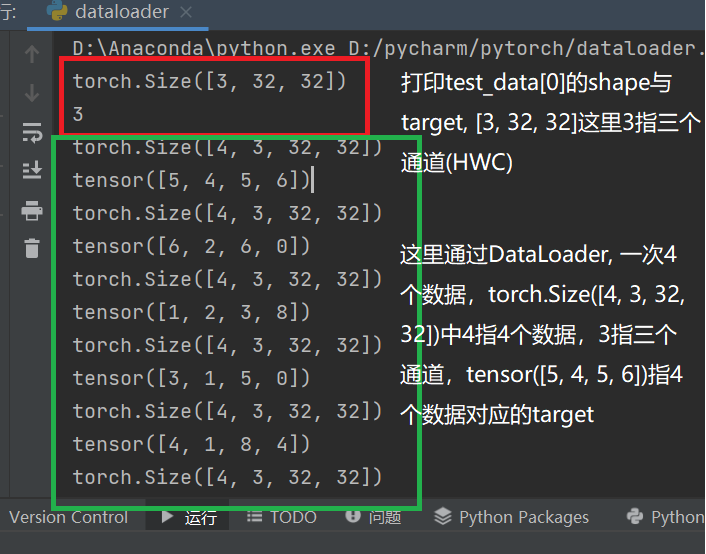
# 数据集为test_data,一次取四个数据(图片),每次不打乱顺序,不舍弃数据
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
img, target = test_data[0]
print(img.shape)
print(target)
for data in test_loader:
imgs, targets = data
print(imgs.shape)
print(targets)
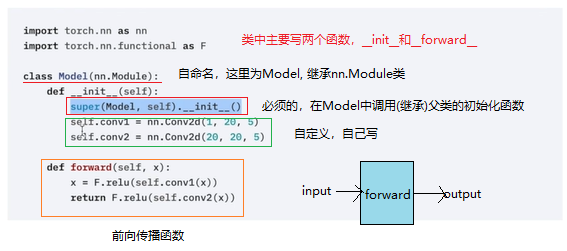
nn.Module的使用
为所有神经网络提供一个基本骨架
import torch
from torch import nn, Tensor
class Test(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
test = Test()
x = torch.tensor(1.0)
output = test(x)
print(output)卷积操作
nn.Conv1d:一维
nn.Conv2d:二维
torch.nn.functional.conv2d
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)

上述参数shape要求
input:batch,输入图像的通道数,高,宽
weight("权重",即卷积核kernel):卷积产生的通道数,in_channels/groups,高,宽
groups参数的作用是控制分组卷积,默认不分组,为1组
padding:在图像两边进行填充,用于决定填充大小,默认不填充
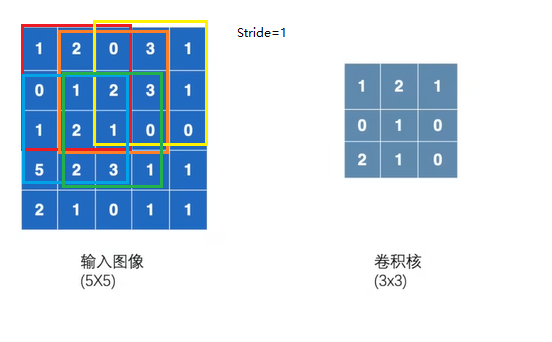
卷积核与输出图像3*3方格依次相乘得到结果

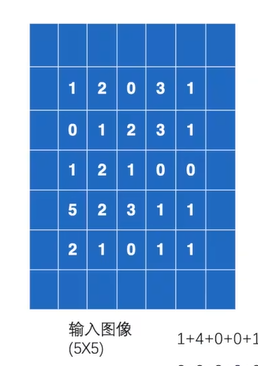
padding=1
import torch
import torch.nn.functional as F
# 二维矩阵,输入图像
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 卷积核
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
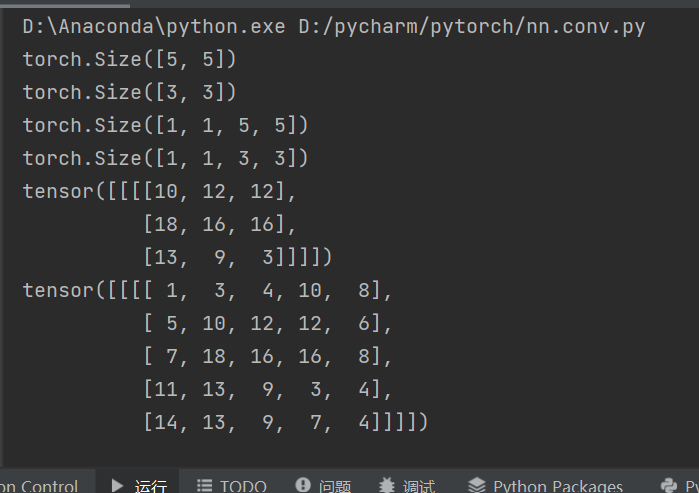
# 由输出可知,input与kernel的shape只有两个参数高和宽,与nn.Conv2d要求的四个参数不符
print(input.shape)
print(kernel.shape)
# reshape进行尺寸变换
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)
# 进行卷积
output1 = F.conv2d(input, kernel, stride=1)
print(output1)
# 在原输入图像四周都插入一行,值为0
output2 = F.conv2d(input, kernel, stride=1, padding=1)
print(output2)
神经网络——卷积层
torch.nn.Conv2d
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=’zeros’)
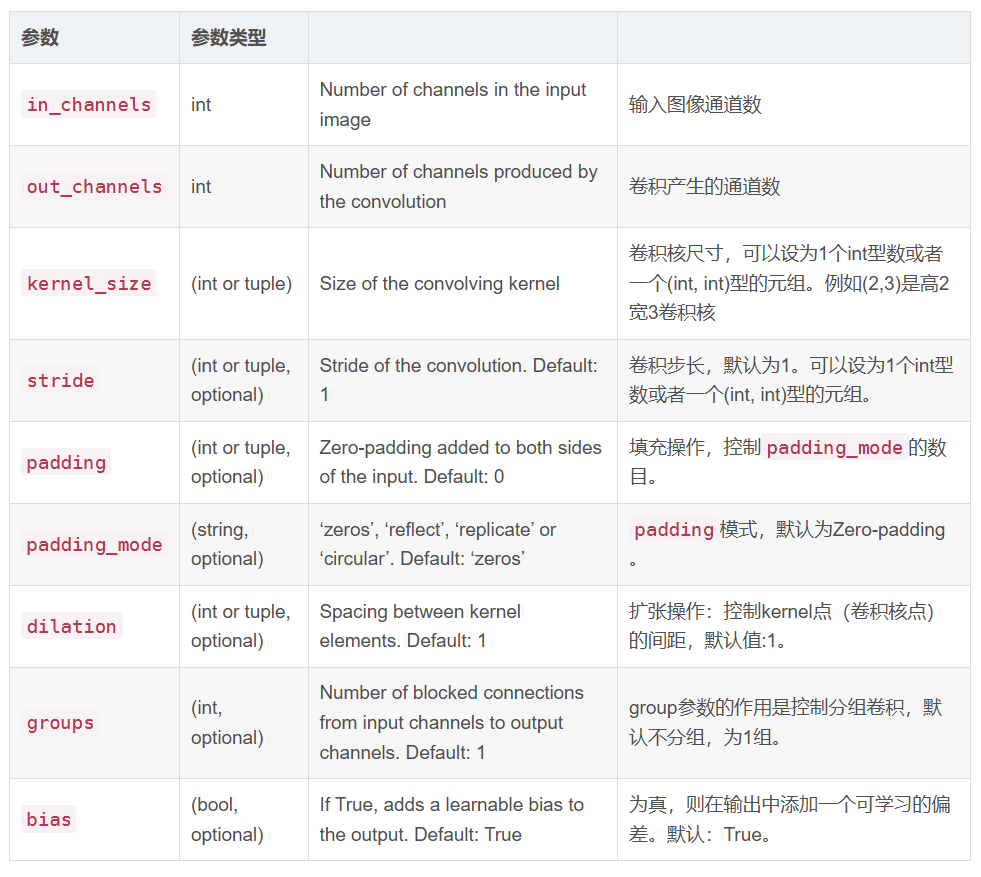
import torch
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=64)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
writer = SummaryWriter("logs")
step = 0
model = Model()
for data in dataloader:
imgs, targets = data
output = model(imgs)
# imgs:channels=3
print(imgs.shape)
# output:channels=6
print(output.shape)
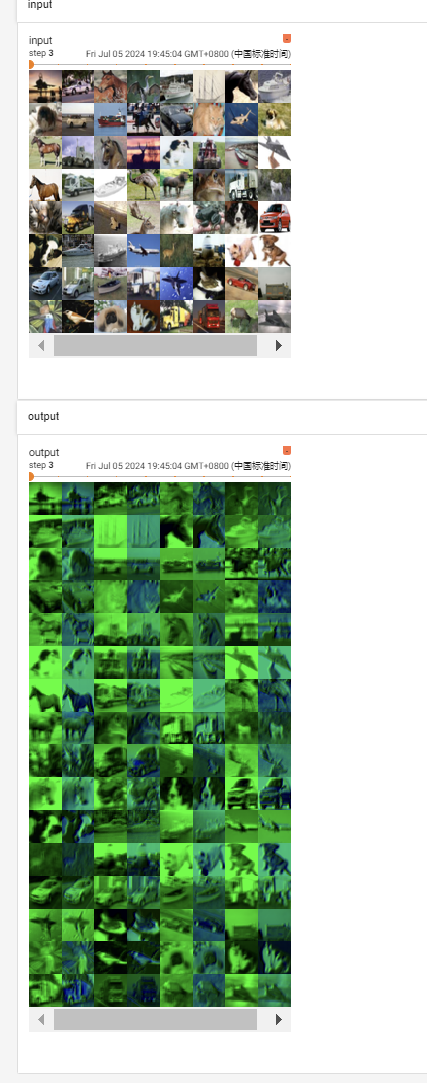
# 注意这里是add_images,因为一次读取多张图片,add_image只针对一张图片
# add_images : dataformats = "NCHW"
# add_image : dataformats = "CHW"
# imgs.shape:torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# output.shape:torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30]
# [-1, 3, 30, 30]不知道通道由6变为3后N为多少,填-1则会根据后三个数据自动得出N的值
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step += 1
writer.close()
神经网络——最大池化的使用
MaxPool2d作用:保留特征而数据量减小

注意:stride的大小默认为kernel的大小
import torch
from torch import nn
from torch.nn import MaxPool2d
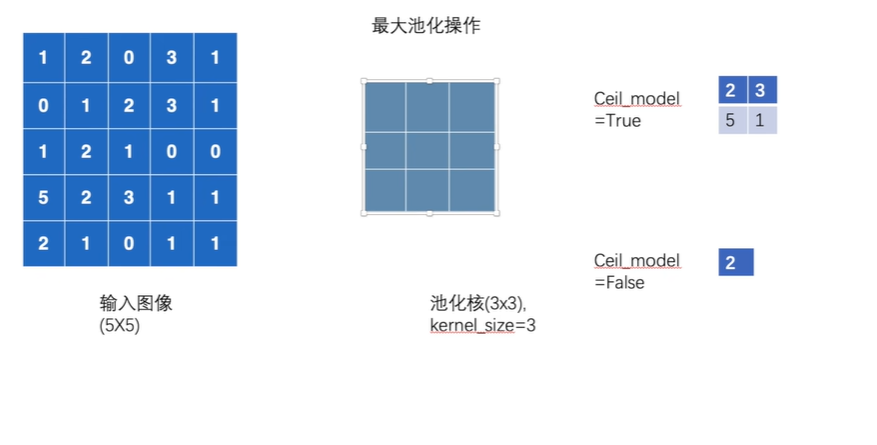
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
input = torch.reshape(input, (-1, 1, 5, 5))
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool(input)
return output
model = Model()
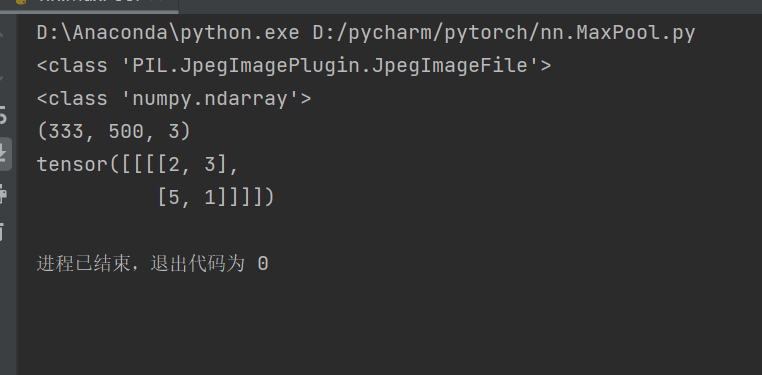
output = model(input)
print(output)ceil_mode=True
ceil_mode=False
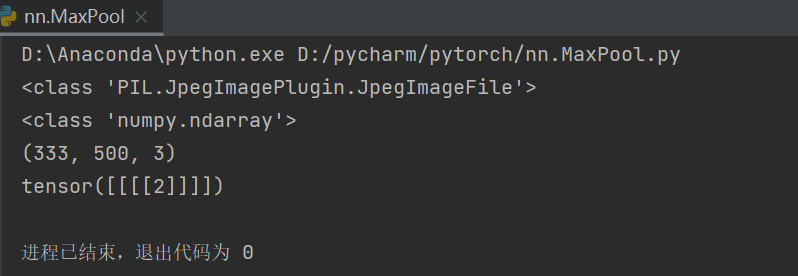
数据集最大池化示例
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=64)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool(input)
return output
model = Model()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data
output = model(imgs)
writer.add_images("input", imgs, step)
writer.add_images("output", output, step)
step += 1
writer.close()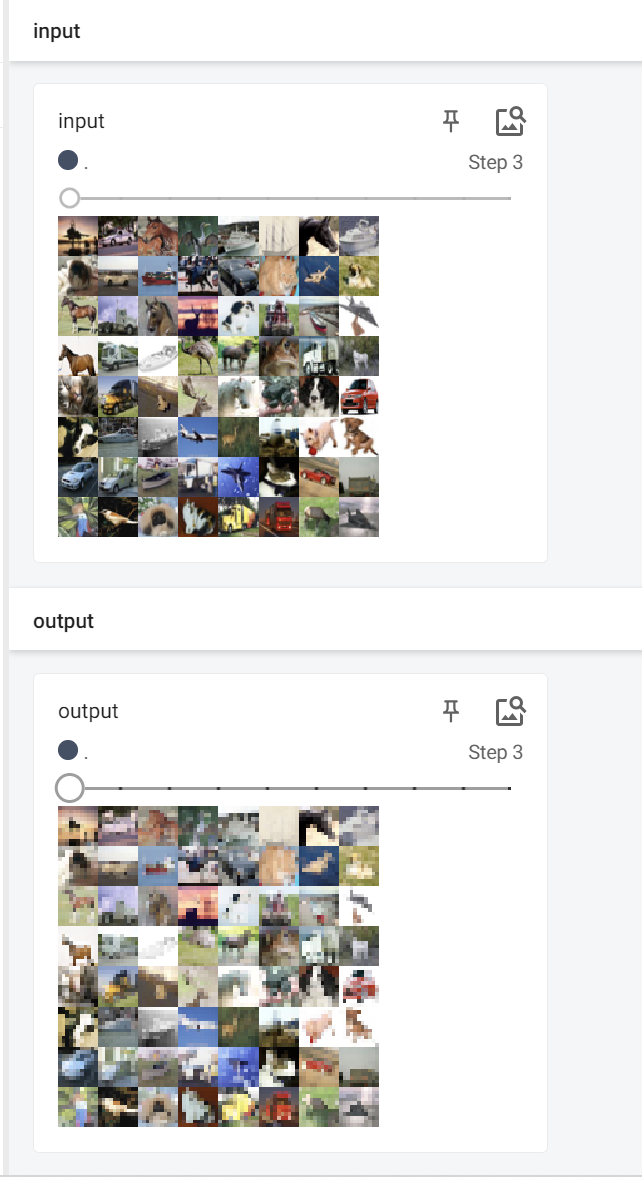
神经网络——非线性激活
引入非线性特征,训练出符合各种曲线的模型
RELU
小于0时进行截断
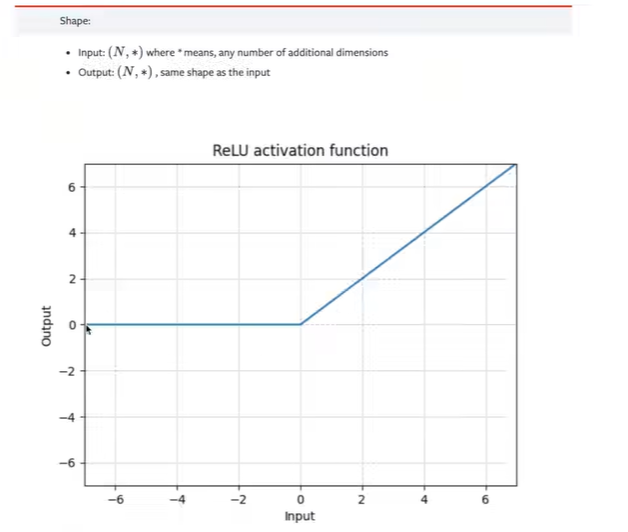

inplace是指是否对源数据进行修改,一般选择False,防止源数据的缺失
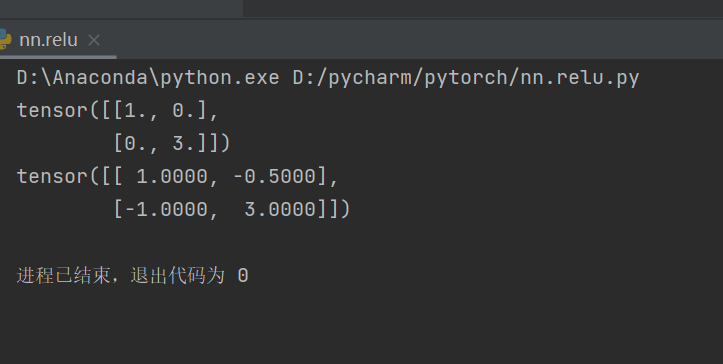
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1, -0.5],
[-1, 3]])
output = torch.reshape(input, (-1, 1, 2, 2))
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.relu1 = ReLU()
def forward(self, input):
output = self.relu1(input)
return output
model = Model()
output = model(input)
print(output)
print(input)
Sigmoid
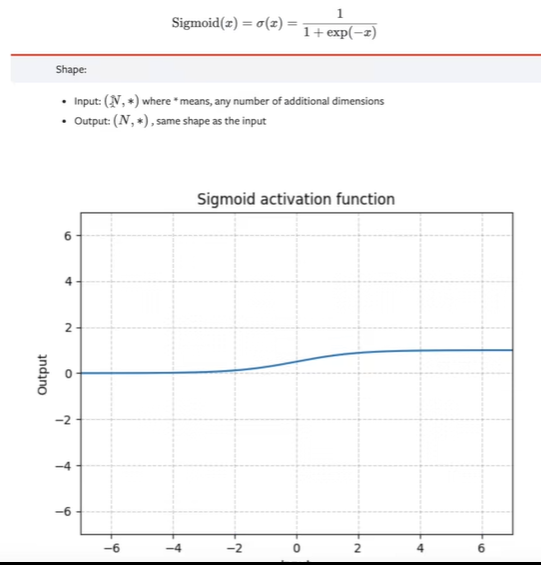
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=64)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
model = Model()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data
output = model(imgs)
writer.add_images("input", imgs, step)
writer.add_images("output", output, step)
step += 1
writer.close()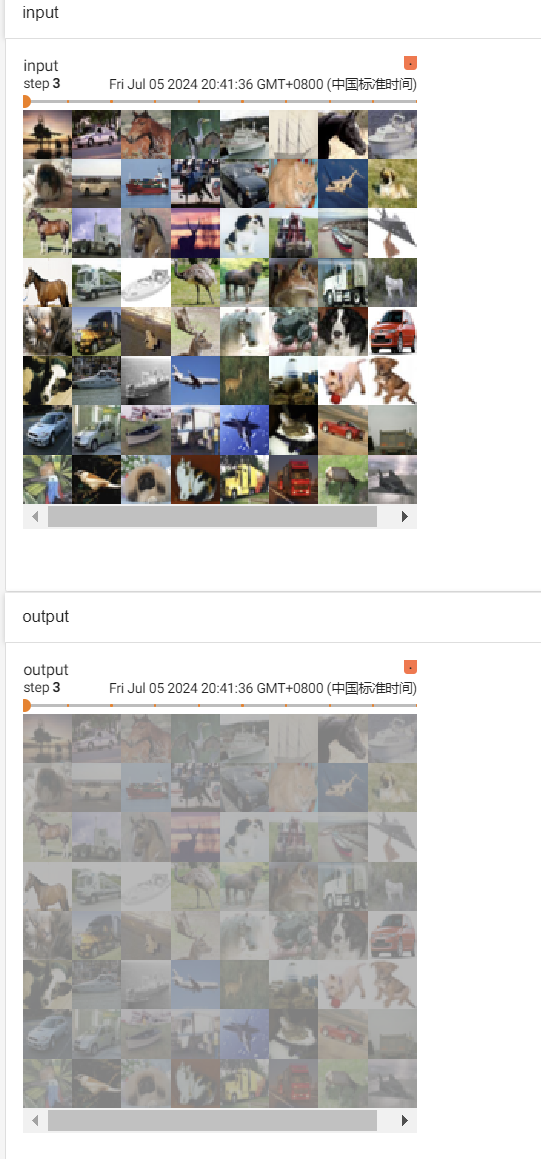
神经网络——线性层(Linear Layers)


in_features指下图中Input layer的个数d
out_features指下图中Onput layer的个数m
bias为True,则存在偏置向量b,反之不存在
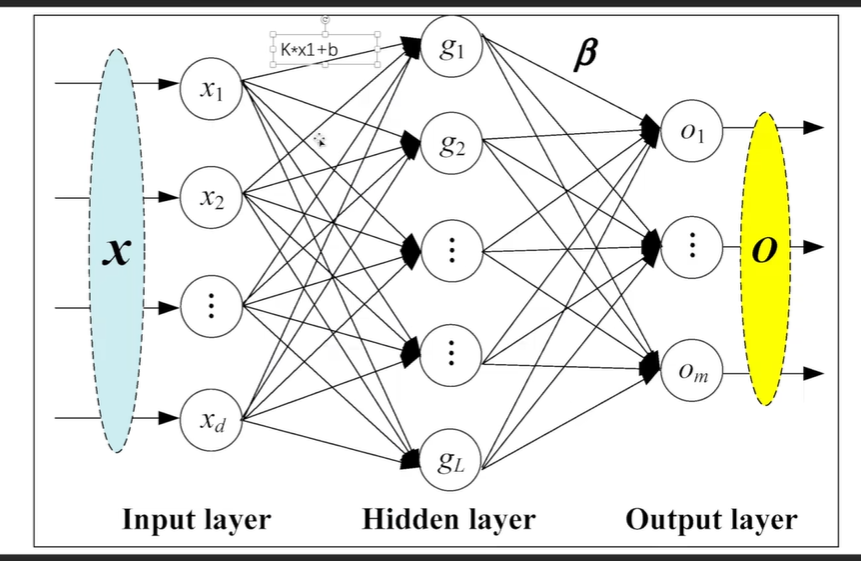
eg:将5*5图片展成一行,有25个,将一行25个通过线性层变为一行3个
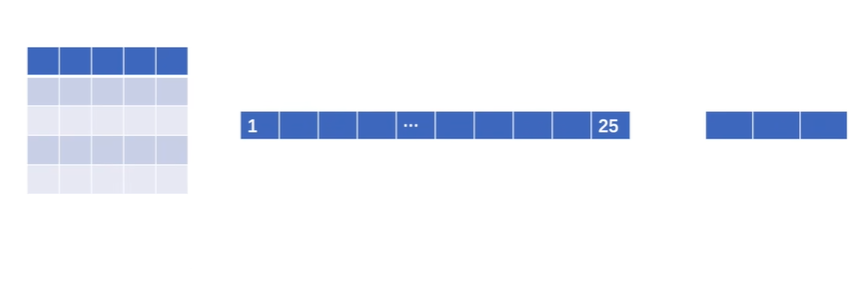
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=64, drop_last=True)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
model = Model()
for data in dataloader:
imgs, targets = data
# imgs.shape : [64, 3, 32, 32]
print(imgs.shape)
# output.shape : [1, 1, 1, 196608]
# output = torch.reshape(imgs, (1, 1, 1, -1))
# torch.flatten把多维的输入一维化, 效果同torch.reshape(imgs, (1, 1, 1, -1))
# output.shape : [196608]
output = torch.flatten(imgs)
print(output.shape)
# output.shape : [1, 1, 1, 10]
output = model(output)
print(output.shape)
神经网络——搭建小实战和Sequential的使用
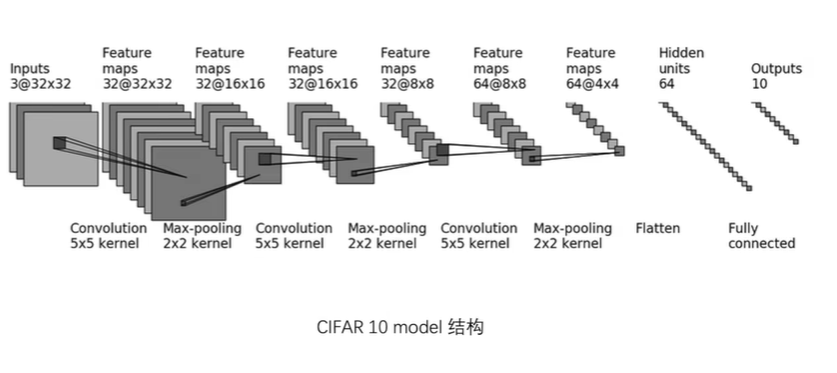
Flatten之后应该先是一行1024=64*4*4,然后经过线性层变为64再变为10
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
# self.conv1 = Conv2d(3, 32, 5, padding=2)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32, 32, 5, padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32, 64, 5, padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(1024, 64)
# self.linear2 = Linear(64, 10)
# Sequential将代码简洁化,class中注释部分代码与剩余代码等价
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
x = self.model1(x)
return x
model = Model()
# 创建一个输入,用于检查网络的正确性
input = torch.ones((64, 3, 32, 32))
output = model(input)
# output.shape : [64, 10], 符合
print(output.shape)
# 该模型也可使用tensorboard可视化
writer = SummaryWriter("logs")
writer.add_graph(model, input)
writer.close()
损失函数与反向传播

L1Loss
L1Loss — PyTorch 2.3 documentation
MSELoss(平方差)
MSELoss — PyTorch 2.3 documentation
CrossEntropyLoss(交叉熵)
CrossEntropyLoss — PyTorch 2.3 documentation

代码
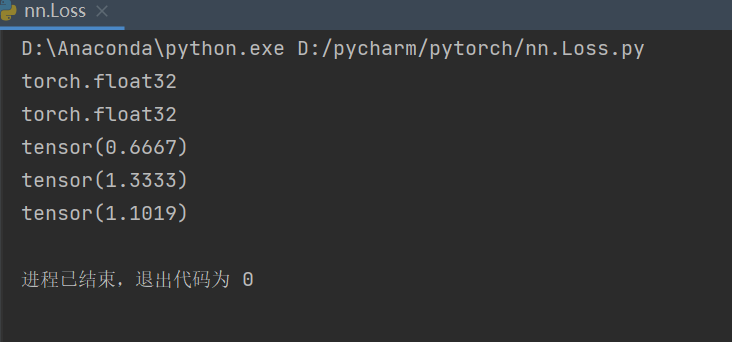
import torch
from torch.nn import L1Loss, MSELoss, CrossEntropyLoss
# # L1Loss()要求输入数据为浮点数,torch.int64 -> torch.float32
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
print(inputs.dtype)
print(targets.dtype)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
# L1Loss()计算targets和inputs之差的绝对值的平均值
loss = L1Loss()
result = loss(inputs, targets)
# MSELoss()计算平方差, targets和inputs之差的平方的平均值
loss_mse = MSELoss()
result_mse = loss_mse(inputs, targets)
print(result)
print(result_mse)
# 交叉熵
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)
在神经网络中用到损失函数
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
# CIFAR10神经网络,将图片分为10类
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
model = Model()
for data in dataloader:
imgs, targets = data
outputs = model(imgs)
# 根据outputs和targets来判断选择什么损失函数
# print(outputs)
# print(targets)
# 分类问题使用交叉熵
result = loss(outputs, targets)
# print(result)
# 反向传播,计算梯度
result.backward()
print("ok")
优化器
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
# CIFAR10神经网络,将图片分为10类
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
model = Model()
# 设置优化器,lr(学习速率)不能太大也不能太小,太大不稳定,太小速度太慢,一般可以开始时大一些,之后减小
optim = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(20):
running_loss = 0.0
# 对数据进行一轮学习
for data in dataloader:
imgs, targets = data
outputs = model(imgs)
result_loss = loss(outputs, targets)
# .grad属性在反向传播过程中是累加的,每一次反向传播梯度都会累加之前的梯度
# 但上一次的梯度对这一次是没有用的,所以反向传播前一定要把梯度清零
optim.zero_grad()
# 反向传播,计算梯度
result_loss.backward()
# 调用优化器对参数进行调优
optim.step()
running_loss = running_loss + result_loss
print(running_loss)现有网络模型的使用与修改
import torchvision
# pretrained=False, 网络模型参数为默认的, 模型将使用随机初始化的权重
# pretrained=True, 网络模型参数为训练好的, 模型将使用预先训练好的权重
from torch import nn
vgg16_False = torchvision.models.vgg16(pretrained=False)
vgg16_True = torchvision.models.vgg16(pretrained=True)
# vgg16_True的网络架构, 最后out_features=1000
print(vgg16_True)
print(vgg16_False)
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
# 使用CIFAR10数据集训练vgg16模型, 那么要令out_features=10, 实现out_features=1000 -> out_features=10
# 再添加一个线性层
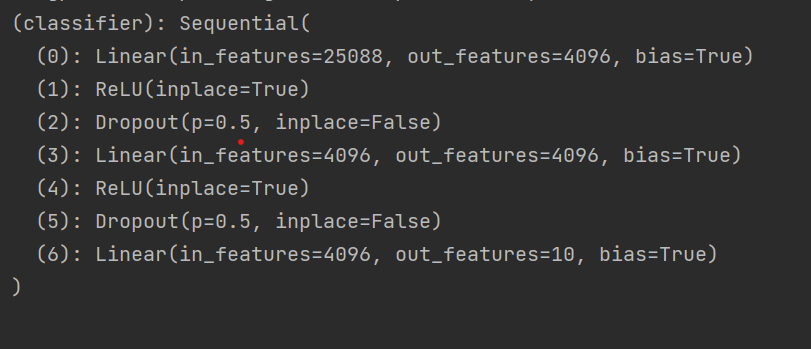
vgg16_True.add_module("add_linear", nn.Linear(1000, 10))
# vgg16_True.classifier.add_module会将线性层添加在classifier下
# vgg16_True.classifier.add_module("add_linear", nn.Linear(1000, 10))
print(vgg16_True)
# 对原先的out_features进行修改
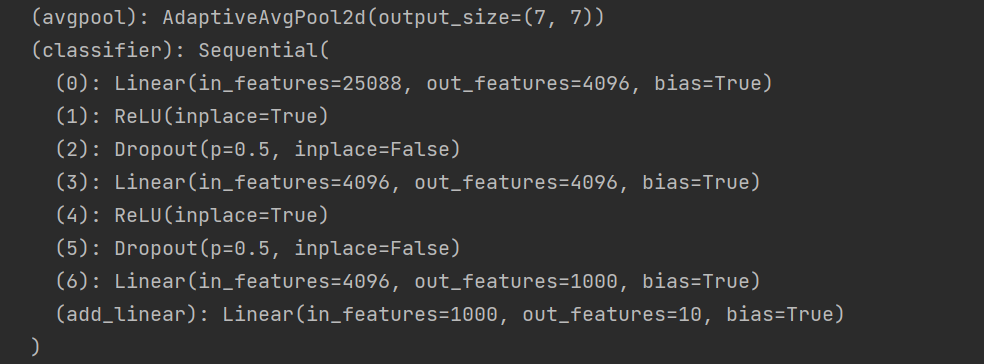
vgg16_False.classifier[6] = nn.Linear(4096, 10)
print(vgg16_False)
修改前
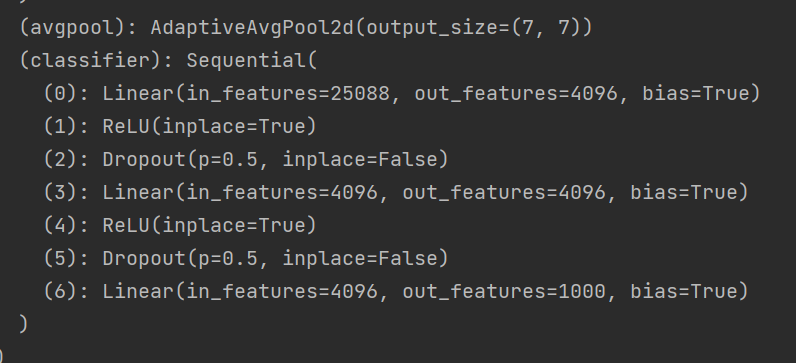
修改后
vgg16_True:
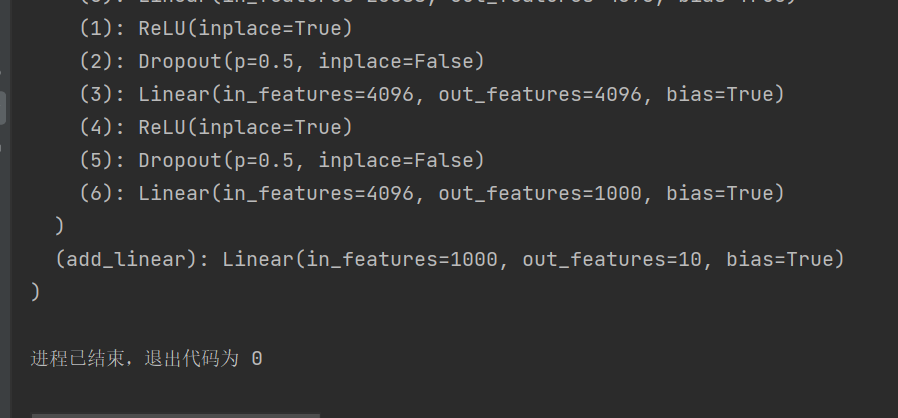
vgg16_False:
网络模型的保存与读取
import torch
import torchvision
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1, 此方式不仅保存了网络模型的结构而且保留了网络模型的参数
# torch.save(模型, 保存路径)
torch.save(vgg16, "vgg16_method1.pth")
# 保存方式2, 不保存网络结构, 保存参数
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
import torch
# 方式1 -> 保存方式1, 加载模型
import torchvision
model1 = torch.load("vgg16_method1.pth")
print(model1)
# 方式2 -> 保存方式2, 加载模型
model2 = torch.load("vgg16_method2.pth")
print(model2)
# 使用方式2将参数保存为字典,如何恢复为网络模型
# 新建网络模型结构
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(model2)
print(vgg16)完整的模型训练套路(以CIFAR10数据集为例)
分类模型求正确率的思路

import torch.optim
import torchvision
# 准备数据集
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
# 准备测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 求训练集与数据集的大小
# train_data_size : 5000 test_data_size : 1000
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
# DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 搭建神经网络
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = nn.Sequential(
Conv2d(3, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, 1, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 创建网络模型
test = Model()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(test.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("logs")
for i in range(epoch):
print("----------第{}轮训练开始----------".format(i+1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
output = test(imgs)
loss = loss_fn(output, targets)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 优化
optimizer.step()
total_train_step = total_train_step + 1
# 设置训练次数整除100时输出,不然输出太多
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
# 进行测试时不需要对模型进行调优,只需要测试当前的模型
# 使用with torch.no_grad(), 在该模块下, 所有计算得出的tensor的requires_grad都自动设置为False
total_test_loss = 0
# 设置total_test_loss为求整个数据集上的误差
total_accuracy = 0
# total_accuracy表示整体数据集上预测正确的个数
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = test(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
# 保存每一轮的模型
torch.save(test, "test_{}.pth".format(i))
print("模型已保存")
writer.close()训练结果
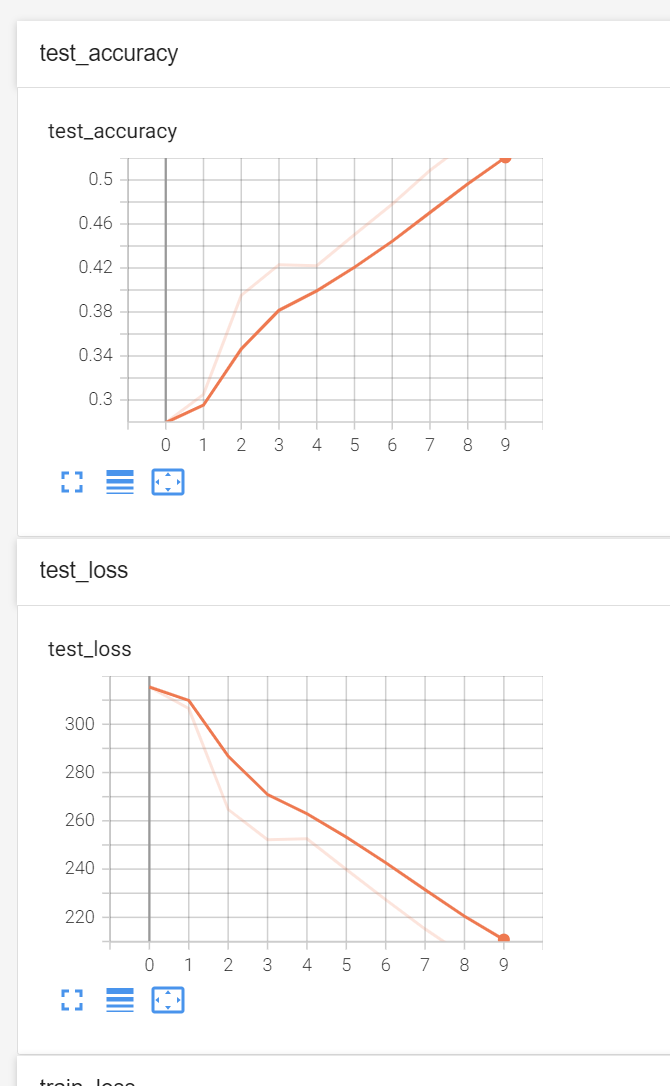
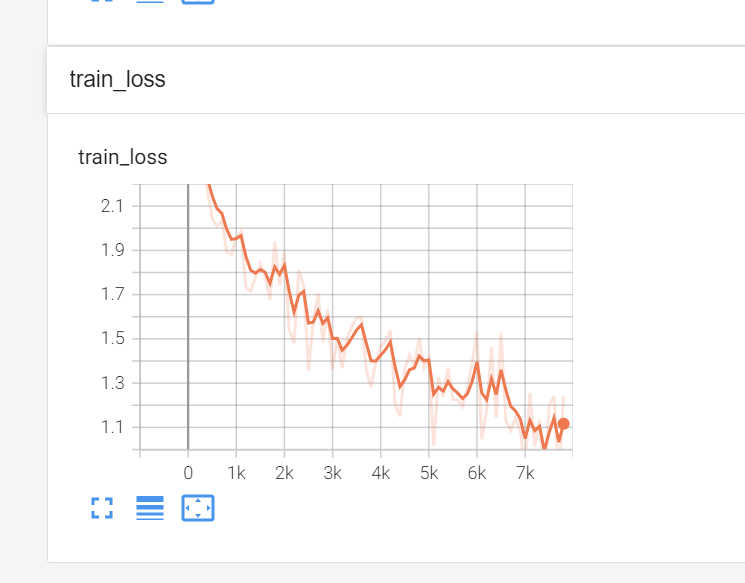
----------第1轮训练开始----------
训练次数:100, Loss:2.283215284347534
训练次数:200, Loss:2.273301362991333
训练次数:300, Loss:2.2619173526763916
训练次数:400, Loss:2.1740665435791016
训练次数:500, Loss:2.043680191040039
训练次数:600, Loss:2.0078063011169434
训练次数:700, Loss:2.0369791984558105
整体测试集上的Loss:315.44848096370697
整体测试集上的正确率:0.2793999910354614
模型已保存
----------第2轮训练开始----------
训练次数:800, Loss:1.8925695419311523
训练次数:900, Loss:1.8815284967422485
训练次数:1000, Loss:1.9579211473464966
训练次数:1100, Loss:1.9866347312927246
训练次数:1200, Loss:1.7322381734848022
训练次数:1300, Loss:1.7161788940429688
训练次数:1400, Loss:1.7776185274124146
训练次数:1500, Loss:1.8390902280807495
整体测试集上的Loss:306.5503889322281
整体测试集上的正确率:0.3050999939441681
模型已保存
----------第3轮训练开始----------
训练次数:1600, Loss:1.7818511724472046
训练次数:1700, Loss:1.6749036312103271
训练次数:1800, Loss:1.939049243927002
训练次数:1900, Loss:1.7411251068115234
训练次数:2000, Loss:1.8905267715454102
训练次数:2100, Loss:1.541244626045227
训练次数:2200, Loss:1.481217384338379
训练次数:2300, Loss:1.811253547668457
整体测试集上的Loss:264.73111140727997
整体测试集上的正确率:0.3950999975204468
模型已保存
----------第4轮训练开始----------
训练次数:2400, Loss:1.7392919063568115
训练次数:2500, Loss:1.3581598997116089
训练次数:2600, Loss:1.5800917148590088
训练次数:2700, Loss:1.7040119171142578
训练次数:2800, Loss:1.4848672151565552
训练次数:2900, Loss:1.6343492269515991
训练次数:3000, Loss:1.3605941534042358
训练次数:3100, Loss:1.5044081211090088
整体测试集上的Loss:252.148371219635
整体测试集上的正确率:0.4230000078678131
模型已保存
----------第5轮训练开始----------
训练次数:3200, Loss:1.3668797016143799
训练次数:3300, Loss:1.5041455030441284
训练次数:3400, Loss:1.5554728507995605
训练次数:3500, Loss:1.594862461090088
训练次数:3600, Loss:1.5979830026626587
训练次数:3700, Loss:1.359714150428772
训练次数:3800, Loss:1.2804844379425049
训练次数:3900, Loss:1.3986715078353882
整体测试集上的Loss:252.56154763698578
整体测试集上的正确率:0.4221000075340271
模型已保存
----------第6轮训练开始----------
训练次数:4000, Loss:1.464833378791809
训练次数:4100, Loss:1.4888604879379272
训练次数:4200, Loss:1.5387232303619385
训练次数:4300, Loss:1.2037707567214966
训练次数:4400, Loss:1.1494269371032715
训练次数:4500, Loss:1.363844394683838
训练次数:4600, Loss:1.4272754192352295
整体测试集上的Loss:239.84667336940765
整体测试集上的正确率:0.450300008058548
模型已保存
----------第7轮训练开始----------
训练次数:4700, Loss:1.3823521137237549
训练次数:4800, Loss:1.5041996240615845
训练次数:4900, Loss:1.3676064014434814
训练次数:5000, Loss:1.4104959964752197
训练次数:5100, Loss:1.0177537202835083
训练次数:5200, Loss:1.326189637184143
训练次数:5300, Loss:1.2392587661743164
训练次数:5400, Loss:1.3710061311721802
整体测试集上的Loss:227.33132886886597
整体测试集上的正确率:0.4779999852180481
模型已保存
----------第8轮训练开始----------
训练次数:5500, Loss:1.2255291938781738
训练次数:5600, Loss:1.2250580787658691
训练次数:5700, Loss:1.1944059133529663
训练次数:5800, Loss:1.2820557355880737
训练次数:5900, Loss:1.3910796642303467
训练次数:6000, Loss:1.5298365354537964
训练次数:6100, Loss:1.0463011264801025
训练次数:6200, Loss:1.1761547327041626
整体测试集上的Loss:215.13847064971924
整体测试集上的正确率:0.5088000297546387
模型已保存
----------第9轮训练开始----------
训练次数:6300, Loss:1.4632166624069214
训练次数:6400, Loss:1.1424564123153687
训练次数:6500, Loss:1.5280565023422241
训练次数:6600, Loss:1.1311086416244507
训练次数:6700, Loss:1.0858980417251587
训练次数:6800, Loss:1.1430498361587524
训练次数:6900, Loss:1.084077000617981
训练次数:7000, Loss:0.91594398021698
整体测试集上的Loss:204.22233402729034
整体测试集上的正确率:0.5346999764442444
模型已保存
----------第10轮训练开始----------
训练次数:7100, Loss:1.255588412284851
训练次数:7200, Loss:1.0144896507263184
训练次数:7300, Loss:1.133514404296875
训练次数:7400, Loss:0.8338384628295898
训练次数:7500, Loss:1.1964503526687622
训练次数:7600, Loss:1.2427127361297607
训练次数:7700, Loss:0.8704733848571777
训练次数:7800, Loss:1.2402838468551636
整体测试集上的Loss:196.44293236732483
整体测试集上的正确率:0.5564000010490417
模型已保存训练结果如上,10轮训练后正确率由27.94%提升到了55.64%

















 1749
1749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









