







第七章内容:C++基础语法内容
问题在前
第一部分问题
- 程序的三种基本结构是什么?
- 三种基本结构之间的区别和特点是什么?
- switch语句和if语句的区别是什么,如何从汇编的角度解释他们的区别?以及他们各自的特点,优点和缺点?
- 关于条件判断的命中率问题和短路运算问题?
- 自定义数据结构的内存对齐问题和32位计算机的内存布局?
- VS2022如何打开低版本的VS项目?
- VS2022如何查看反汇编代码?
第二部分问题
- **三种循环语句的对比如何?Do while和for和while,从汇编的角度来看哪个效率会更高? **
- 循环语句前的注释解释循环的内容要注意,在工程项目中要学会写注释
- 掌握看汇编代码能力,暂不要求全部看懂,至少要求学会怎么查看汇编,大概了解内容
- 思考面试题目:如何更加高效的输出1+2+3+…+100?
- 理解for循环优化的要点,尽可能的在程序中使用优化的for循环
第三部分的内容
-
什么是函数?函数的特点是什么?
-
main只是应用程序的入口,不是系统程序的入口如何理解?(这个问题太难了,看了自己也不懂)
-
函数的重载是什么?区分函数的重载,重定向和重写,这是三个不同的内容
-
从汇编的角度怎么理解函数的重载?
-
如何用undname来查看“中间代码”(obj文件内的代码)理解函数的重载原理?C++是如何区分函数重载的?
-
main函数的执行过程如何(在汇编角度如何理解,如何理解压栈出栈的过程)?
在main函数中调用一个getmax函数,中间的执行过程如何?什么是cal指令?他和空的main函数执行有什么区别?
- inline函数在使用前要确定在优化中设置打开,否则不会是用inline
- inline函数的工作原理是怎么样的?为什么说他是空间换时间的模式?(查看汇编,发现在inline函数在主函数中被调用的时候,inline函数的主体被直接复制过来,没有了cal的回调过程)
- 什么时候inline函数不会被调用?编译器会自动优化判断哪些函数不能被inline?
- 递归的四个要素是什么?
- 如何理解递归中的回溯过程?能否自己画一个递归树模拟回溯递归的过程?
- 递归在调用的过程中,寄存器记录了大量的数据,递归的时间复杂度较高,对栈空间的消耗非常大。
- 如何优化递归?(循环好和尾递归)
三种基本结构
条件判断语句(if Switch)
循环语句(while do while for)
顺序结构
大概了解一下三种结构的内容,知道如何使用三种结构,并且熟悉三种结构的嵌套使用。
if 语句和 Switch语句的区别
在使用if语句的时候,要注意命中率的问题,一定要优先把判断条件命中率更高的条件放在前面,这样子会节省判断的时间
在汇编代码中,if语句的判断是树形结构,当if的判断条件越来越多的时候会呈现出效率非常低下的情况,而Switch语句更像是一种跳转表,他的效率明显会更高一点,但是缺点也很明显。

自定义数据类型
C++支持程序员自定义数据类型,如class ,struct ,union等
class和struct在默认权限上不同,class是默认私有的,struct是默认公有的
union和他们在内存的布局上有所差别不同,所有的成员共享同一块内存空间
枚举enum数据类型也是自定义的
枚举
要区分定义和声明的区别,在声明的时候是不会分配空间的,只有在定义变量的时候才会具体的分配内存的空间。

#include <iostream>
using namespace std;
int main()
{
enum wT{Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday}; // 声明wT类型
wT weekday;
//这里表示声明一个枚举类型的变量,但是这个变量并没有被初始化
weekday = Monday;
weekday = Tuesday;
//weekday = 1; // 不能直接给int值,只能赋值成wT定义好的类型值
cout << weekday << endl;
//Monday = 0; // 类型值不能做左值
int a = Wednesday;
cout << a << endl;
return 0;
}
枚举类型的特点:
1.不能对枚举类型惊醒直接赋值,比如但是可以进行强制类型的转换,但是不推荐这么做
2.枚举内的类型值不可以作为左值,他代表的是一个符号常量,是无法被赋值的
结构体和联合体
#include <string.h>
#include <iostream>
using namespace std;
int main()
{
union Score
{
double ds;
char level;
};
struct Student
{
char name[6];
int age;
Score s;
};
//cout << sizeof(Score) << endl; // 8
Student s1;
strcpy_s(s1.name, "lili");
s1.age = 16;
s1.s.ds = 95.5;
s1.s.level = 'A';
cout << sizeof(Student) << endl; // 24 18
return 0;
}
结构体和联合体的内存布局问题
要理解在32位计算机中内存是如何分布的
在结构体的内存分布上,他们是按照其中最大的元素的整数倍分配结构体的内存
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AieOR7iL-1687664139951)(C:\Users\13868\AppData\Roaming\Typora\typora-user-images\image-20230601115158310.png)]](https://img-blog.csdnimg.cn/f4be9241d57447148dff7ceb6a7eb707.png)
三种循环语句的对比
for循环语句
int main() {
int sum = 0;
for (int i = 1; i <= 100; i++) {
sum += i;
}
cout << sum << endl;
return 0;
}
while
int i = 1;
while (i <= 100) {
sum += i;
i++;
}
cout << sum << endl;
do while
i = 1;
do {
sum += i;
i++;
} while (i <= 100);
cout << sum << endl;
在写法上没有任何的问题,重点在于如何理解这三种循环模式的区别
-
for循环在开发中使用的频率更多,因为他更加偏向人的思维方式
-
从汇编的角度来看,do while语句的效率是最高的,但是大部分还是使用for循环为主,但是在项目中部分循环也会使用do while使用
-
while循环的使用也比较常见,汇编角度效率while第二,do while最高,for循环效率最低
三种汇编代码的比较
// while语句
int sum = 0;
002A17BE mov dword ptr [sum],0
int index = 1;
002A17C5 mov dword ptr [index],1
while (index <= 100)
002A17CC cmp dword ptr [index],64h
002A17D0 jg main+46h (02A17E6h)
{
sum += index;
002A17D2 mov eax,dword ptr [sum]
002A17D5 add eax,dword ptr [index]
002A17D8 mov dword ptr [sum],eax
index += 1;
002A17DB mov eax,dword ptr [index]
002A17DE add eax,1
002A17E1 mov dword ptr [index],eax
}
002A17E4 jmp main+2Ch (02A17CCh)
//cout << sum << endl;
// for语句
//index = 1;
sum = 0;
002A17E6 mov dword ptr [sum],0
for (index = 1; index <= 100; ++index)
002A17ED mov dword ptr [index],1
002A17F4 jmp main+5Fh (02A17FFh)
002A17F6 mov eax,dword ptr [index]
002A17F9 add eax,1
002A17FC mov dword ptr [index],eax
002A17FF cmp dword ptr [index],64h
002A1803 jg main+70h (02A1810h)
{
sum += index;
002A1805 mov eax,dword ptr [sum]
{
sum += index;
002A1808 add eax,dword ptr [index]
002A180B mov dword ptr [sum],eax
}
002A180E jmp main+56h (02A17F6h)
//cout << sum << endl;
// do-while语句
sum = 0;
002A1810 mov dword ptr [sum],0
index = 1;
002A1817 mov dword ptr [index],1
do
{
sum += index;
002A181E mov eax,dword ptr [sum]
002A1821 add eax,dword ptr [index]
002A1824 mov dword ptr [sum],eax
index += 1;
002A1827 mov eax,dword ptr [index]
002A182A add eax,1
002A182D mov dword ptr [index],eax
} while (index <= 100);
002A1830 cmp dword ptr [index],64h
002A1834 jle main+7Eh (02A181Eh)
//cout << sum << endl;
面试题目:如何更加高效的输出1+2+3+…+100?
for循环的优化案例
例题:如何判断aabb是否是一个平方数
方法一:两层for循环暴力判断
很耗费时间!
#include <math.h>
using namespace std;
int main() {
//方法一,要嵌套使用两个for循环同时调用一个math函数非常的消耗时间
int n = 0;
for (int i = 1; i < 10; i++) {
for (int j = 0; j < 10; j++) {
n = i * 1100 + j * 11;
double result = sqrt(n);
if ((result * 10 - (int)result * 10) < 0.0000000000001) {
cout << n << endl;
cout << result << endl;
}
}
}
return 0;
}
如何优化这个for循环呢
方法二
可以通过逆向的思维,我把所有在1000到9999之内的所有平方数都求出来,然后再判断哪一个是满足aabb的形式
- 如何将两层for循环化为一层for循环?尽可能的减少条件的判断,这样子会让程序的效率更高
- 可以在for循环内使用continue和break来让for循环的执行次数减少,提高for循环效率
- 学会逆向思维,对于可能会损失精度的运算尽量避免使用
#include <iostream>
using namespace std;
int main() {
//再for循环中是可以在循环内结束判断调节的,并不一定要在for的开头定义
for (int i = 33; ; i++) {
int result = i * i;
if (result < 1000) {
continue;
}
if (result > 9999) {
break;
}//比如现在的数值是1234
int high = result / 100;
int low = result % 100;
if (high / 10 == high % 10 && low / 10 == low % 10) {
cout << result << endl;
}
}
return 0;
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UbtZOzQX-1687664139952)(C:\Users\13868\AppData\Roaming\Typora\typora-user-images\image-20230601202813737.png)]
函数
看了两篇文章,视频里面也说了main函数其实不是真正的入口,其实让我挺好奇的,然后在知乎上看了几篇文章
(20 封私信 / 41 条消息) 为什么现代编程语言,逐渐都不把main函数作为真正的启动入口函数? - 知乎 (zhihu.com)
讲了main只是应用程序的入口,不是系统程序的入口
但是现在不是很理解这个内容,只是拓宽了一下我的知识面。
函数基础
函数的本质:对逻辑的封装


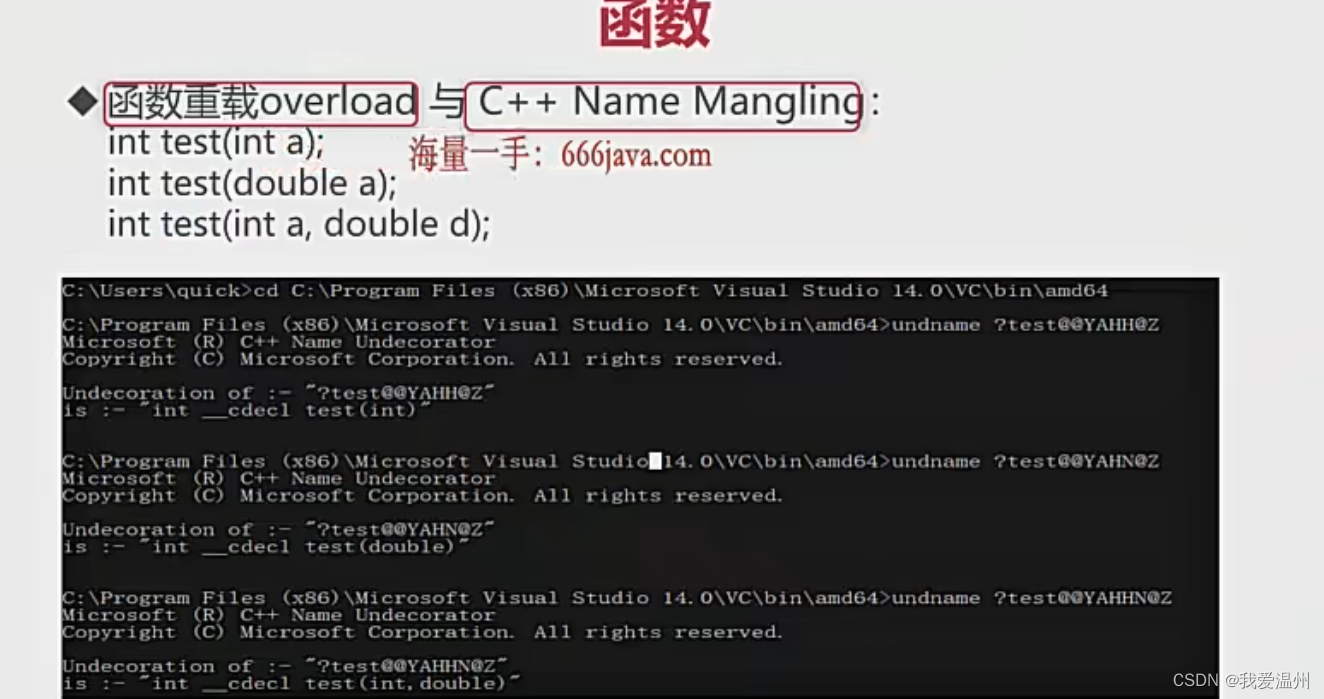
函数重载和函数的签名
首先要明确,函数的重载和函数的重写是完全不同的概念
这篇文章对函数的重载,重定义和重写的介绍非常明确
(84条消息) 函数的重载、重写和重定义简述(c/c++知识篇)_函数重写_栋哥爱做饭的博客-CSDN博客
这是函数重载时的汇编代码
我也看不懂,反正记得,函数重载不是通过函数的名称进行调用的,而是通过函数的签名!
result = quickzhao::test(1);
00007FF6DA2A17B1 mov ecx,1
00007FF6DA2A17B6 call quickzhao::test (07FF6DA2A12B7h)
00007FF6DA2A17BB mov dword ptr [result],eax
result = test(2.0);
00007FF6DA2A17BE movsd xmm0,mmword ptr [__real@4000000000000000 (07FF6DA2A9BB0h)]
00007FF6DA2A17C6 call test (07FF6DA2A1127h)
00007FF6DA2A17CB mov dword ptr [result],eax
result = test(1, 2.0);
00007FF6DA2A17CE movsd xmm1,mmword ptr [__real@4000000000000000 (07FF6DA2A9BB0h)]
00007FF6DA2A17D6 mov ecx,1
00007FF6DA2A17DB call test (07FF6DA2A130Ch)
00007FF6DA2A17E0 mov dword ptr [result],eax
找到项目中obj文件,用notepad打开会发现这是一坨乱码
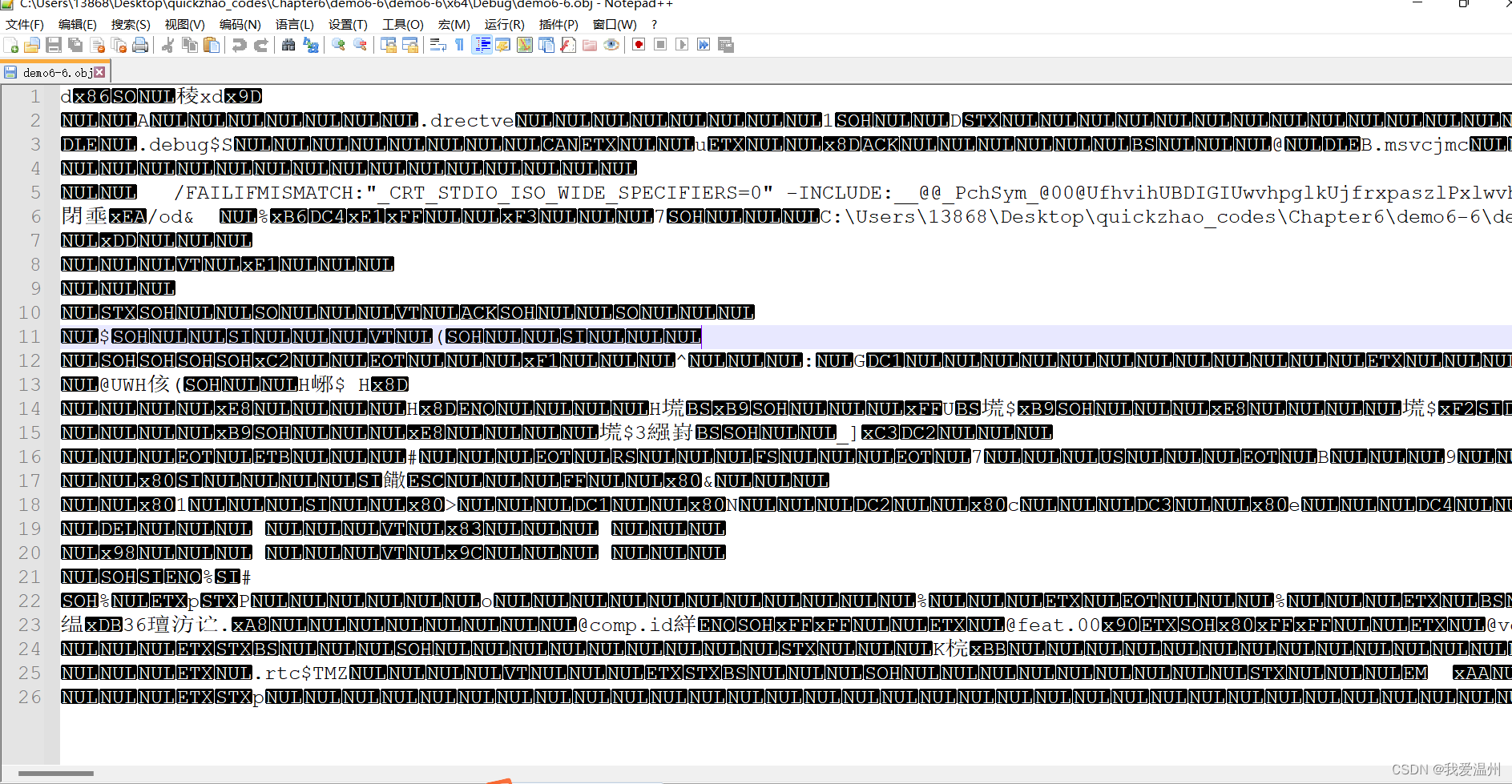
可以通过查找,搜索重载的函数text
复制粘贴下面这一行 但是不知道为什么我查找出来的和这个还是有区别的?
//?test@@YAHH@Z
//?test@@YAHN@Z
//?test@@YAHHN@Z
下载一个软件everything这个软件搜索速度很快
我自己电脑上搜索这个undname差点系统卡死了,桌面直接重启了
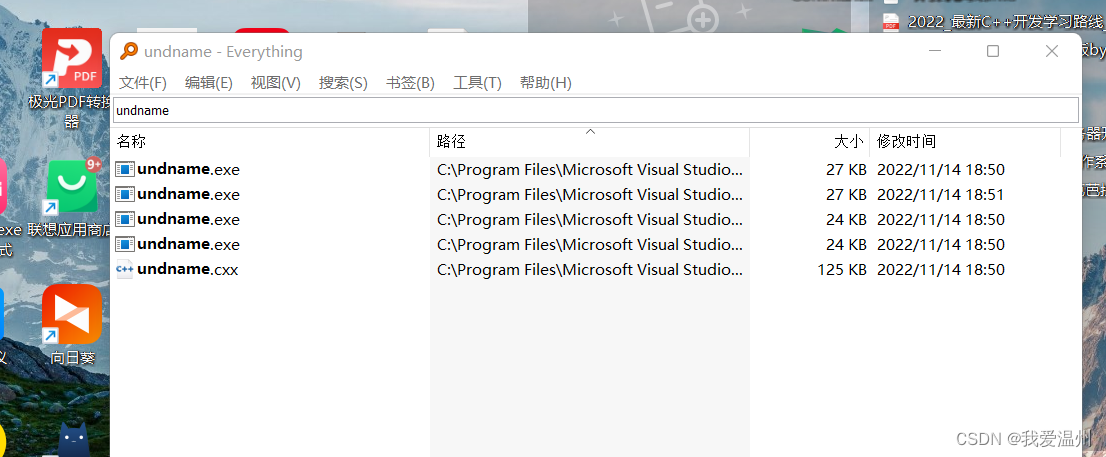
下面那个undname文件,进入到她的文件夹中
在文件夹中使用cmd命令
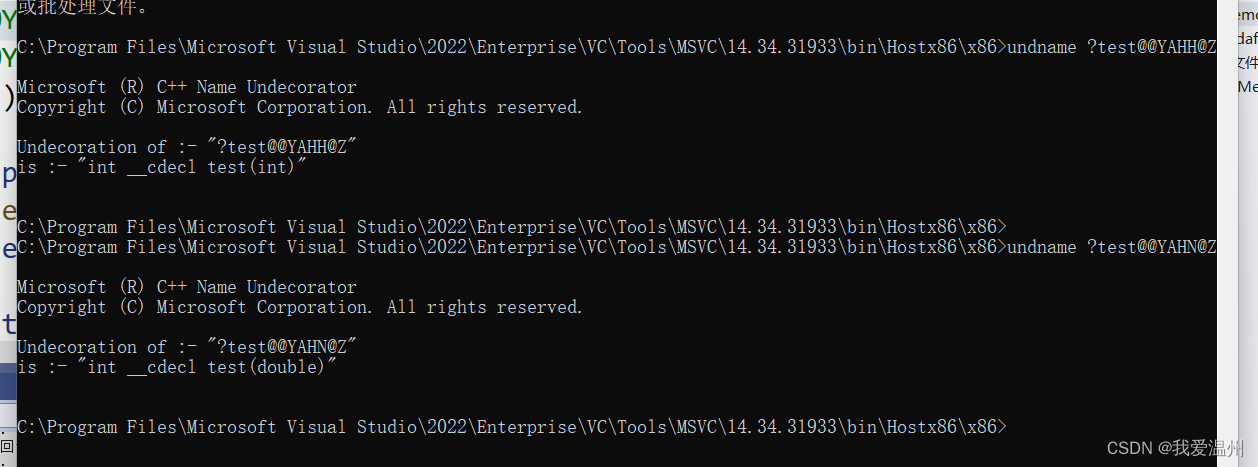
undname ?test@@YAHH@Z
undname ?test@@YAHN@Z
undname ?test@@YAHHN@Z
就会显示出下面的结果,上面这个代码其实是“中间代码”(我也暂时不知道这是神魔东西)
这样子其实就可以更加理解C++中的函数重载是怎么实现的,是通过函数的签名
inline函数
inline函数
MaxValue(x, y);
00CC167C mov eax,dword ptr [x]
00CC167F cmp eax,dword ptr [y]
00CC1682 jle main+3Fh (0CC168Fh)
00CC1684 mov ecx,dword ptr [x]
00CC1687 mov dword ptr [ebp-0DCh],ecx
00CC168D jmp main+48h (0CC1698h)
00CC168F mov edx,dword ptr [y]
00CC1692 mov dword ptr [ebp-0DCh],edx
Fib(5);
011238A8 mov eax,5
011238AD test eax,eax
011238AF jne main+55h (011238B5h)
011238B1 jmp main+85h (011238E5h)
011238B3 jmp main+85h (011238E5h)
011238B5 mov ecx,5
011238BA cmp ecx,1
011238BD jne main+63h (011238C3h)
011238BF jmp main+85h (011238E5h)
011238C1 jmp main+85h (011238E5h)
011238C3 mov edx,5
011238C8 sub edx,1
011238CB push edx
011238CC call Fib (0112132Ah)
011238D1 add esp,4
011238D4 mov eax,5
函数调用堆栈
int main()
{
00C01690 push ebp
00C01691 mov ebp,esp
00C01693 sub esp,0C0h
00C01699 push ebx
00C0169A push esi
00C0169B push edi
00C0169C lea edi,[ebp-0C0h]
00C016A2 mov ecx,30h
00C016A7 mov eax,0CCCCCCCCh
00C016AC rep stos dword ptr es:[edi]
return 0;
00C016AE xor eax,eax
}
int MaxValue(int a, int b)
{
009C1690 push ebp
009C1691 mov ebp,esp
009C1693 sub esp,0C4h
009C1699 push ebx
009C169A push esi
009C169B push edi
009C169C lea edi,[ebp-0C4h]
009C16A2 mov ecx,31h
009C16A7 mov eax,0CCCCCCCCh
009C16AC rep stos dword ptr es:[edi]
return (a > b) ? a : b;
009C16AE mov eax,dword ptr [a]
009C16B1 cmp eax,dword ptr [b]
009C16B4 jle MaxValue+31h (09C16C1h)
009C16B6 mov ecx,dword ptr [a]
009C16B9 mov dword ptr [ebp-0C4h],ecx
009C16BF jmp MaxValue+3Ah (09C16CAh)
009C16C1 mov edx,dword ptr [b]
009C16C4 mov dword ptr [ebp-0C4h],edx
009C16CA mov eax,dword ptr [ebp-0C4h]
}
009C16D0 pop edi
009C16D1 pop esi
009C16D2 pop ebx
}
009C16D3 mov esp,ebp
009C16D5 pop ebp
009C16D6 ret
int x = 3, y = 4;
00CC166E mov dword ptr [x],3
00CC1675 mov dword ptr [y],4
MaxValue(x, y);
00CC167C mov eax,dword ptr [x]
00CC167F cmp eax,dword ptr [y]
00CC1682 jle main+3Fh (0CC168Fh)
00CC1684 mov ecx,dword ptr [x]
00CC1687 mov dword ptr [ebp-0DCh],ecx
00CC168D jmp main+48h (0CC1698h)
00CC168F mov edx,dword ptr [y]
00CC1692 mov dword ptr [ebp-0DCh],edx
return 0;
00CC1698 xor eax,eax
主函数在调用的时候
首先会对堆栈的信息进行初始化,设置栈顶和栈底,而不是直接进入函数体中执行代码
如果在主函数中有调用其他函数,则会出现cal指令,cal指令会跳转到被调用的函数体上方,同样也会进行初始化堆栈信息,然后再执行函数体中代码
如果使用了inline函数
主函数再调用inline函数时候,不会执行cal指令(其实也不一定,因为是否inline由编译器来决定),而是在编译阶段将inline函数的主体直接拿过来,不需要再对堆栈初始化,不需要执行cal指令,节省了时间的消耗,提高了程序的执行效率。
但是编译器有时候也不会执行inline,比如遇到:递归(因为递归太长了,对空间的浪费很大,所以程序中尽可能的不使用递归函数)
递归
了解递归的四个特点:

在某一种程度上,企业开发尽可能的不会使用递归,因为递归的时间复杂度很高,对空间和资源的浪费较大,如果递归的层次比较多,对栈空间的浪费极大。

比如调用斐波那契数列,递归的调用会造成大量的重复运算出现,时间和空间的浪费很大,从汇编的角度来看:每一次递归都会占用寄存器来保存栈的信息数据,总而言之:递归非常占用栈空间,时间复杂度很大
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G90f98SM-1687664139955)(C:\Users\13868\AppData\Roaming\Typora\typora-user-images\image-20230603085623205.png)]
递归的优化
第一种是使用循环来代替递归
比如while循环
第二种则是尾递归的形式
int bfs(int n, int x, int y) {
if (n == 0) {
return x;
}
if (n == 1) {
return y;
}
return bfs(n - 1, y, x + y);
}
这是代码随想录中通过动态规划的方式优化斐波那契数列
class Solution {
public:
int fib(int n) {
if(n <= 1){
return n;
}
vector<int> result(n+1);
result[0] = 0;
result[1] = 1;
for(int i = 2; i < result.size(); i++){
result[i] = result[i-1] + result[i-2];
}
return result[n];
}
};
信息数据,总而言之:递归非常占用栈空间,时间复杂度很大
递归的优化
第一种是使用循环来代替递归
比如while循环
第二种则是尾递归的形式
int bfs(int n, int x, int y) {
if (n == 0) {
return x;
}
if (n == 1) {
return y;
}
return bfs(n - 1, y, x + y);
}
这是代码随想录中通过动态规划的方式优化斐波那契数列
class Solution {
public:
int fib(int n) {
if(n <= 1){
return n;
}
vector<int> result(n+1);
result[0] = 0;
result[1] = 1;
for(int i = 2; i < result.size(); i++){
result[i] = result[i-1] + result[i-2];
}
return result[n];
}
};















 111
111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









