







 本文详细介绍了算法效率的衡量标准,重点讨论了时间复杂度和空间复杂度的概念。通过实例分析了斐波那契数列、冒泡排序和二分查找的时间复杂度,指出它们分别为O(n^n)、O(n^2)和O(logn)。同时,文章提及了空间复杂度的重要性,并提供了几个算法复杂度的练习题目,包括寻找数组中消失的数字问题。最后,强调了理解并优化算法复杂度对于提升程序性能的关键作用。
本文详细介绍了算法效率的衡量标准,重点讨论了时间复杂度和空间复杂度的概念。通过实例分析了斐波那契数列、冒泡排序和二分查找的时间复杂度,指出它们分别为O(n^n)、O(n^2)和O(logn)。同时,文章提及了空间复杂度的重要性,并提供了几个算法复杂度的练习题目,包括寻找数组中消失的数字问题。最后,强调了理解并优化算法复杂度对于提升程序性能的关键作用。
目录
一、算法效率的度量方式
无非就从时间和空间两方面来考虑,有事前分析和事后分析(比较程序运行时间,受环境)两方面,我们着重关注时间和事前分析这两个方面
二、算法的时间复杂度O表示法
简单介绍
这里的O表示法并不表示代码真正的执行时间,而是表示一种代码执行时间随着数据规模增长的变化趋势,也叫渐进时间复杂度,简称时间复杂度。例如,一个算法的执行时间为2n+5,就可以表示为O(n)
| 执行次数函数 | 阶 | 非正式术语 |
|---|---|---|
| 1,2,3,,, | O(1) | 常数阶 |
| 2n+3 | O(n) | 线性阶 |
| 3 | O( | 平方阶 |
| O( | 对数阶 | |
| 3 | O( | 立方阶 |
| O( | 指数阶 |
常见的时间复杂度所对应的时间从长到短依次为:
O(1)<O()<O(n)<O(
)<O(
)<O(
)<O(n!)<O(
)
斐波那契数列的时间复杂度——O( )
)
#include<stdio.h>
int fun(int num)
{
if(num==1||num==2)
return num=1;
else
return fun(num-1)+fun(num-2);
}
int main()
{
int num=0;
printf("要求第几项斐波那契数? >\n");
scanf("%d",&num);
int ret=fun(num);
printf("%d",ret);
return 0;
}调用次数

+
+
+......+
-1-X=
-X(由于树状图并不是同时结束,下半部分会缺一小块,则需要减去)
冒泡排序的时间复杂度——( )
)
#include<stdio.h>
int main()
{
int i,j;
int arr[10]={9,8,7,5,6,4,3,2,0,1};
int sz=sizeof(arr)/sizeof(arr[0]);//求数组长度
for(i=0;i<sz-1;i++)//外层循环决定排序的趟数
{
for(j=0;j<sz-1-i;j++)//内层循环确定每趟交换的次数
{
if(arr[j]>arr[j+1])//相邻两个数比较
{
int tmp=arr[j+1];
arr[j+1]=arr[j];
arr[j]=tmp;
}
}
}
//输出排好的数组
for(i=0;i<sz;i++)
{
printf("%d ",arr[i]);
}
return 0;
}冒泡排序的原理是:(相邻两个数进行比较)第一趟循环中,第一和第二个数比较,然后第二个和第三个数比较,以此类推,直至最后两个数比较,能使最大的一个数排在最后。第二趟循环中,从第二个和第三个数比较,以此类推,直至最后两个数。例如:
第一趟 第二趟 第三趟
4 3 2 1 3 2 1 4 2 1 3 4
3 4 2 1 2 3 1 4 1 2 3 4
3 2 4 1 2 1 3 4
3 2 1 4
精确计算
(n-1)+(n-2)+(n-3)+...+1=[(n-1)+1]*(n-1)/2=n*(n-1)/2
时间复杂度:O()
难点:为什么第一个for循环截止到sz-1,第二个for循环截止到sz-1-i?
原因:就拿升序举例。第一个外层决定循环的趟数,例如四个数只用循环三趟。第二个内层循环决定每趟循环比较的次数,例如第一趟循环中4个数比较3次后,把最大的数放到最后,那么第二趟循环中最后一位就不用参与比较,同理第三趟循环最后两位就不用
二分查找的时间复杂度——O(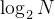 )
)
#include<stdio.h>
int binary_search(int key,int arr[],int n)
{
int low=0,high=n-1,mid,count=0,count1=0;
while(low<high)
{
count++;
mid=(low+high)/2;
if(key<arr[mid])
high=mid-1;
else if(key>arr[mid])
low=mid+1;
else if(key==arr[mid])
{
printf("查找成功\n");
count1++;//查找成功的次数
}
if(count1==0)
printf("查找失败\n");
return 0;
}
}
int main()
{
int i,key,arr[100],n;
printf("请输入元素个数:\n");
scanf("%d",&n);
printf("请输入元素:\n");
for(i=0;i<n;i++)
{
scanf("%d",&arr[i]);
}
printf("请输入要查找的元素:\n");
scanf("%d",&key);
binary_search(key,arr,n);
return 0;
} 假设一个数组有N个数,每进行一次二分查找就÷2,N/2/2/2/2......,进行x次二分查找,就多除以一个2。假设查找x次,有如下推导:
- N/2/2/2/2...=1
=N
优缺点分析
| N个数中查找 | 查找次数 |
|---|---|
| 1000 | 10 |
| 100w | 20 |
| 10亿 | 30 |
| 14亿 | 31 |
| 需要有序的元素,若无序,先排序 |
| 需要占用不小的内存放进数组中 |
三、空间复杂度
当今算法不那么关注空间复杂度,因为现在的设备的存储空间都比较大,空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度 ,也就是额外占取的空间的大小。空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。
- 斐波那契数列的空间复杂度——O(N)
- 冒泡排序的空间复杂度——O(1)
四、对复杂度的练习
1、查找消失的数字
数组nums包含从0到n的所有整数,但其中缺了一个,请编写代码找出那个数,并且在O(n)时间内完成。
- 思路一:使用快速排序,之后遍历数组,时间复杂度为O(N*
N)
- 思路二:(1+2+3+...+n)-(nums[0]+nums[1]+nums[2]+...+nums[n-1]) 时间复杂度O(N),空间复杂度O(1)
- 思路三:先给一个值X=0,X先给(0,n)内所有数按位异或,之后再和数组内的(0,n)所有数按位异或,根据其特点,相同为0,相异为1.最后X就是数组内消失的数(原理很简单,例如有数字1,2,3,4,4,3,2这七个数字,1和2按位异或的结果再和3按位异或,依次类推,最后结果一定是1,因为2,3,4经过了分别两次按位异或,大家可以将其化成二进制数,试一试)
int missingNumber(int* nums,int numsSize)
{
int x=0;
int i=0;
//先和[0,n]异或
for(i=0;i<=numsSize;i++)
{
x^=i;
}
//再和数组异或
for(i=0;i<numsSize;i++)
{
x^=nums[i];
}
retuen x;
}五、写在最后
👍🏻点赞,你的认可是我创作的动力!
⭐收藏,你的青睐是我努力的方向!
✏️评论,你的意见是我进步的财富!
















 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











