




参考书(本章所有案例和代码都可在此书下载)
Winston chang.R数据可视化手册—北京:人民邮电出版社,2014
散点图常用于刻画两变量之间的关系,ggplot2中在绘制散点图时,也有很多需要注意的事项,下面就分别展开一些说明
一 简单散点图
运行函数geom_point(),其中可以调整适合的参数,shape表示点的形状,而size则选择点的大小(默认的为2)再选择x和y就可以画出一个简单散点图
library(gcookbook)
library(ggplot2)
heightweight[,c("ageYear","heightIn")] #选取其中两列数据作为绘图数据
ggplot(heightweight,aes(x=ageYear,y=heightIn))+geom_point(shape=12,size=1.5)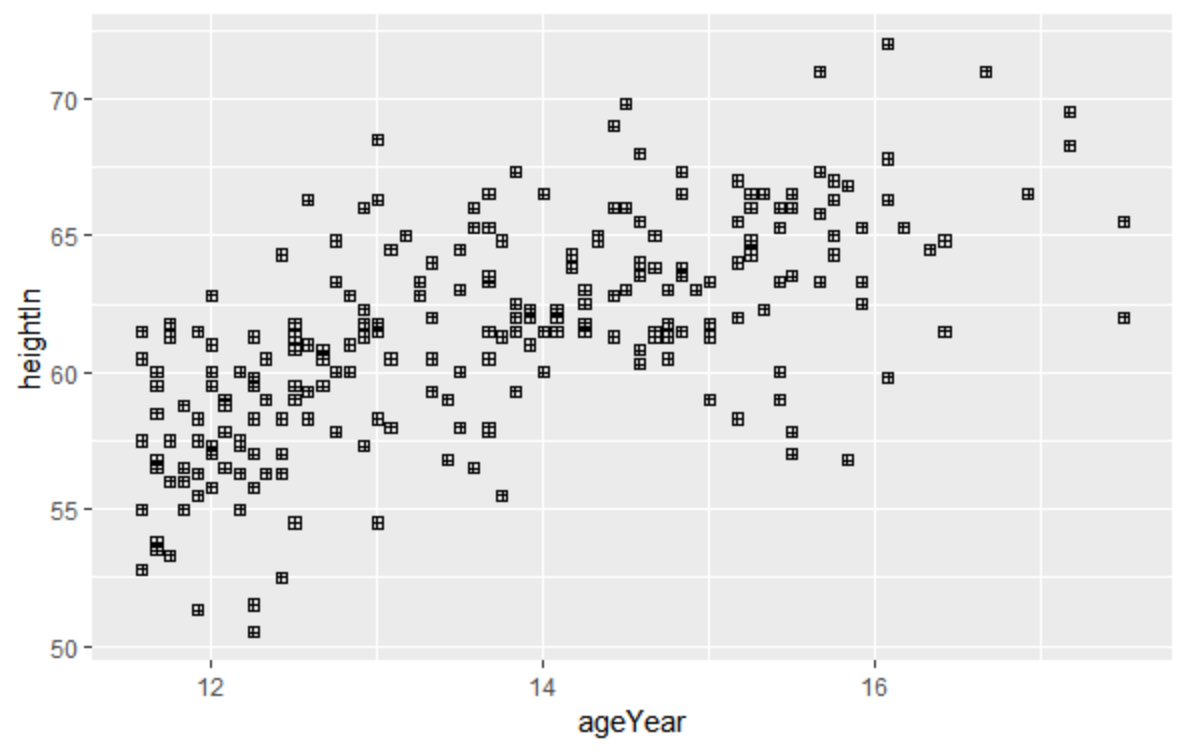
二 散点图修改
1.基于某变量对数据分组
将分组变量(必须是分类变量)映射给shape和colour属性,下面还是以上面的例子为说明,并选择数据集中的sex作为分类变量。
ggplot(heightweight,aes(x=ageYear,y=heightIn,shape=sex,colour=sex))+
geom_point()+scale_fill_manual(values = c("#6495ED","#F08080"))

2.使用不同的点形状
通过指定geom_point()中的点形shape参数可以修改,如果已有分组变量映射到shape中,则可用
scale_shape_manual()函数来修改点形。在R中,不同数字表示的点形如下:

对于点形1-20,颜色都可由colour参数来绘制,21-25边框线和实心区域的颜色分别由colour和fill参数来控制。
ggplot(heightweight,aes(x=ageYear,y=heightIn,shape=sex))+
geom_point(size=3)+scale_shape_manual(values = c(1,4))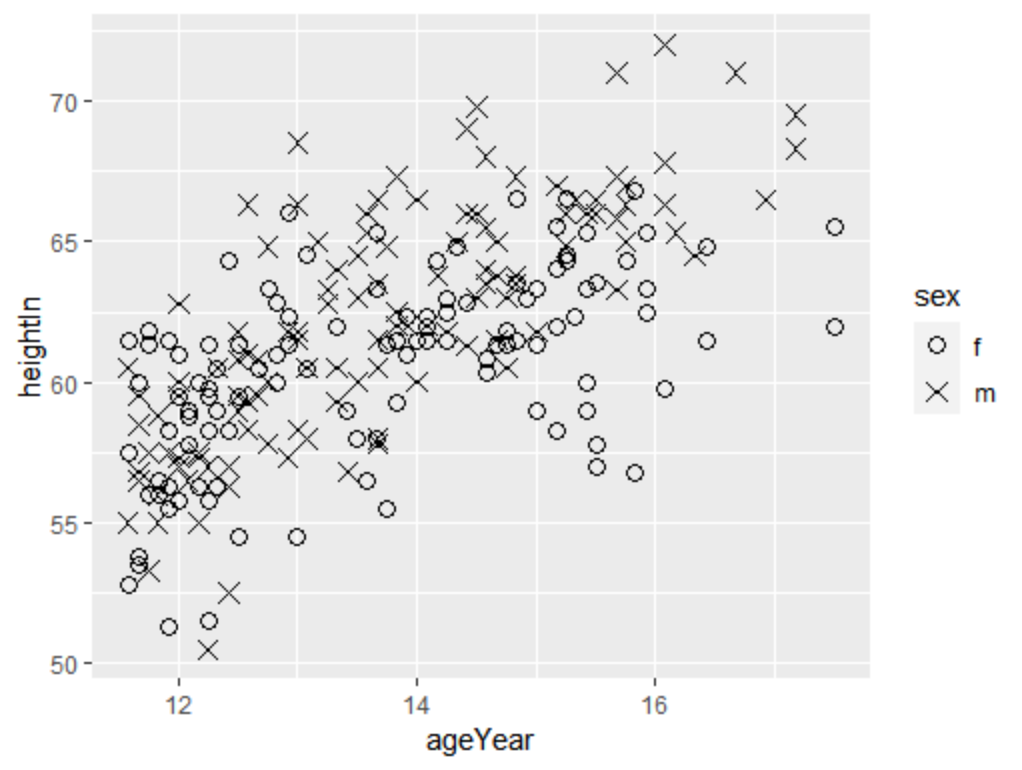
接下来增加一列分组的,并用它实现画图
hw<-heightweight #增加一个标识儿童体重是否超过100磅的列,画图
hw$weightGroup<-cut(hw$weightLb,breaks=c(-Inf,100,Inf),
labels=c("< 100",">= 100"))
ggplot(hw,aes(x=ageYear,y=heightIn,shape=sex,fill=weightGroup))+
geom_point(size=2.5)+scale_shape_manual(values = c(20,24))+
scale_fill_manual(values = c("blue","black"),guide=guide_legend(override.aes = list(shape=25)))
其中,cut函数把连续变量分割为类别,要将连续型变量变成离散型因子,需要对连续型变量进行切割,每个区间可成为一个因子。可以用cut函数完成连续型变量的切割工作。
函数cut()能够把数值变量切成不同的块,然后返回一个因子,对数值数据进行分组:使用cut函数对数值数据进行分组,格式为下:
cut(x,breaks,labels=NULL,include.lowest=FALSE,right=TRUE,dig.lab=3,ordered_result=FALSE,...)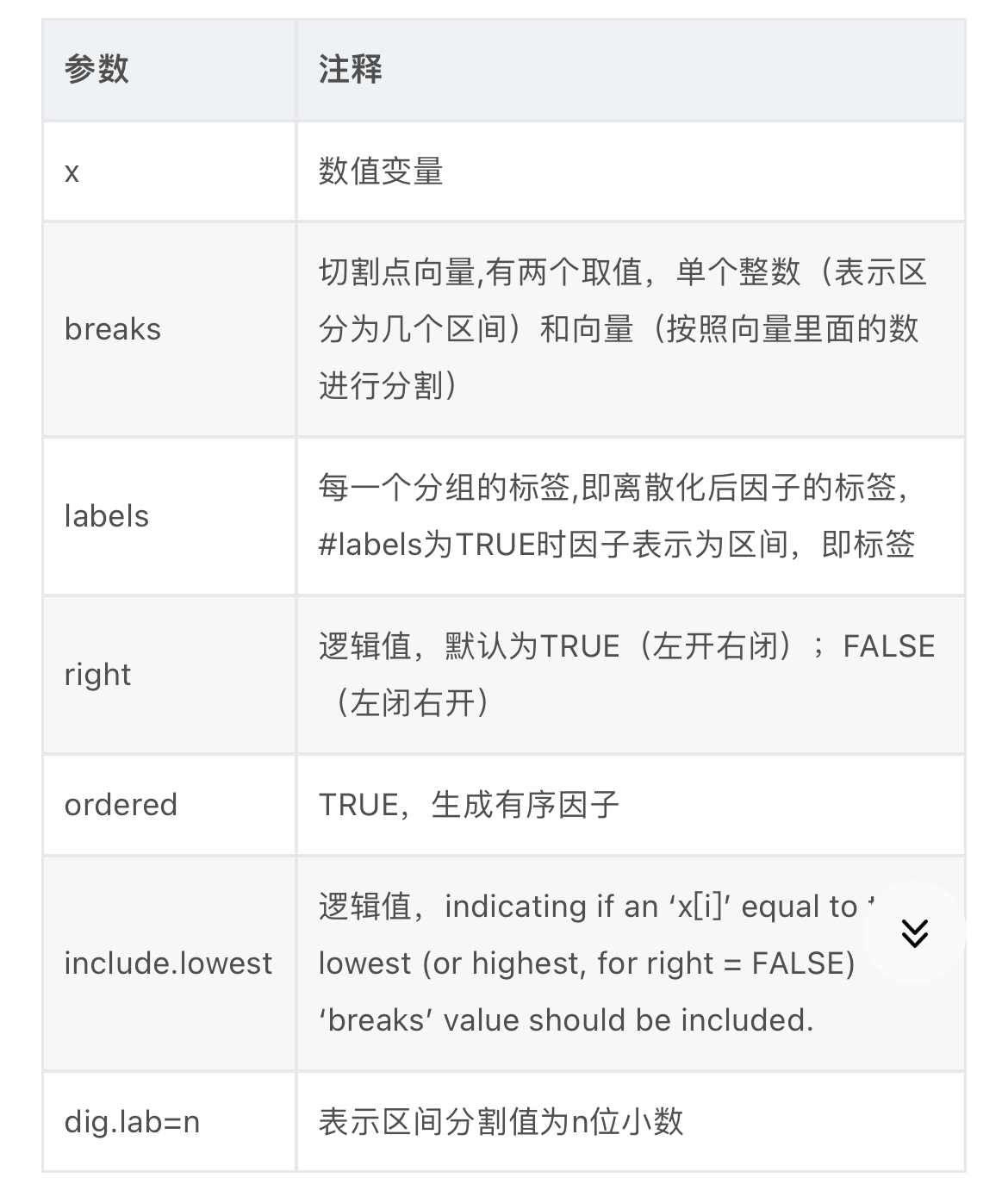
3.将连续性变量映射到点的颜色或大小属性
可通过将连续型变量映射到size或colour属性即可,如下面的例子中,引入一个连续型变量,这时可将映射放到颜色上,通过颜色作出区分。
heightweight[,c("sex","ageYear","heightIn","weightLb")]
# 展示前五行
sex ageYear heightIn weightLb
1 f 11.92 56.3 85.0
2 f 12.92 62.3 105.0
3 f 12.75 63.3 108.0
4 f 13.42 59.0 92.0
5 f 15.92 62.5 112.5
ggplot(heightweight,aes(x=ageYear,y=heightIn,colour=weightLb))+geom_point()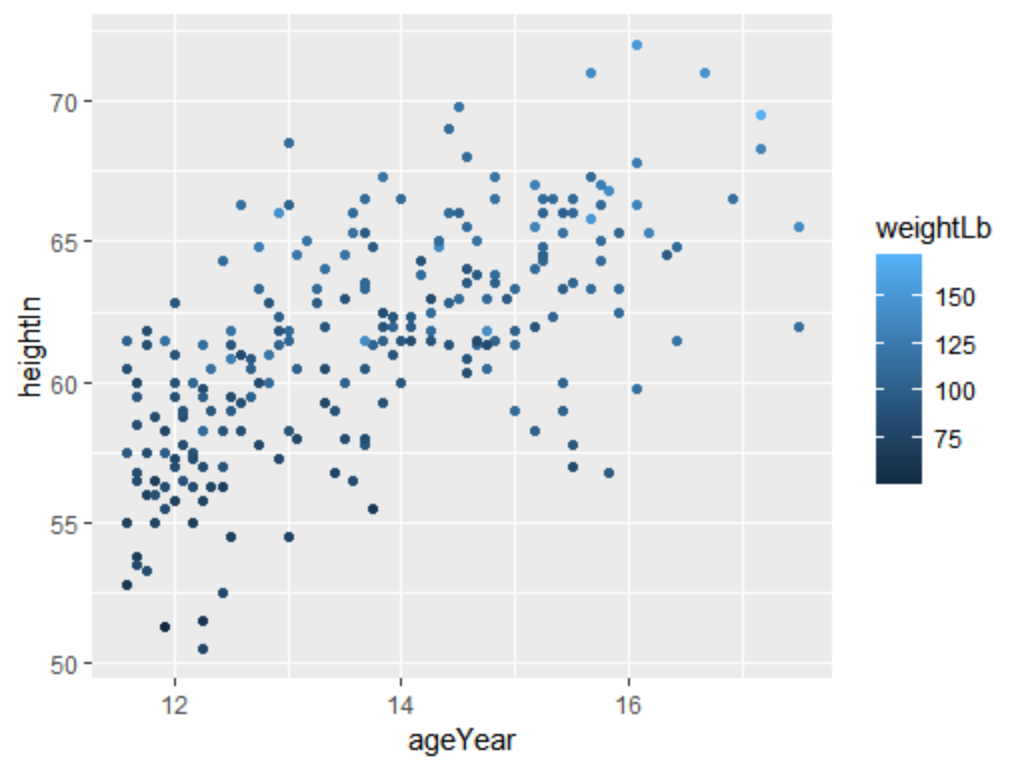
对于颜色实际上有两个参数可使用,fill和colour,大多数时候用colour,但对于点形21-25时,需用fill,当背景色很浅时,用边框线的点就可很好的区分背景与数据点,下面的例子便是这样,且将色阶设定为由黑至白。
ggplot(heightweight,aes(x=ageYear,y=heightIn,fill=weightLb))+geom_point(shape=21,size=2.5)+
scale_fill_gradient(low="black",high = "white")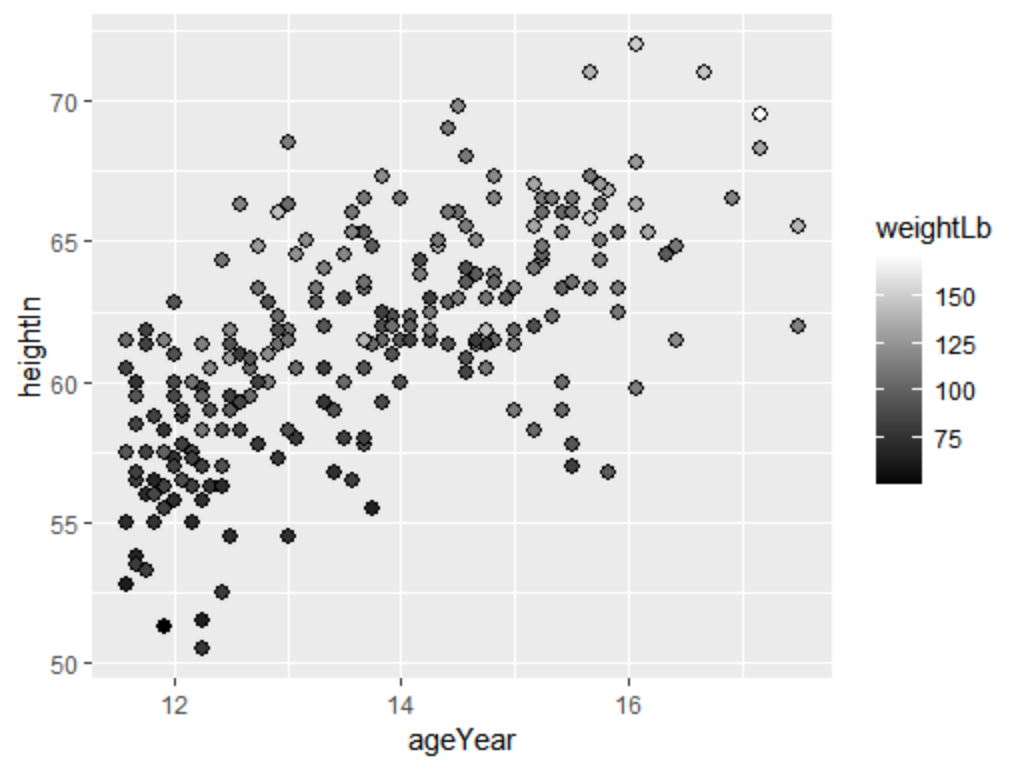
若想修改右边的图例,可以使用guide_legend(),改为离散型的图例
ggplot(heightweight,aes(x=ageYear,y=heightIn,fill=weightLb))+geom_point(shape=21,size=2.5)+
scale_fill_gradient(low="black",high = "white",breaks=seq(70,170,by=20),
guide = guide_legend())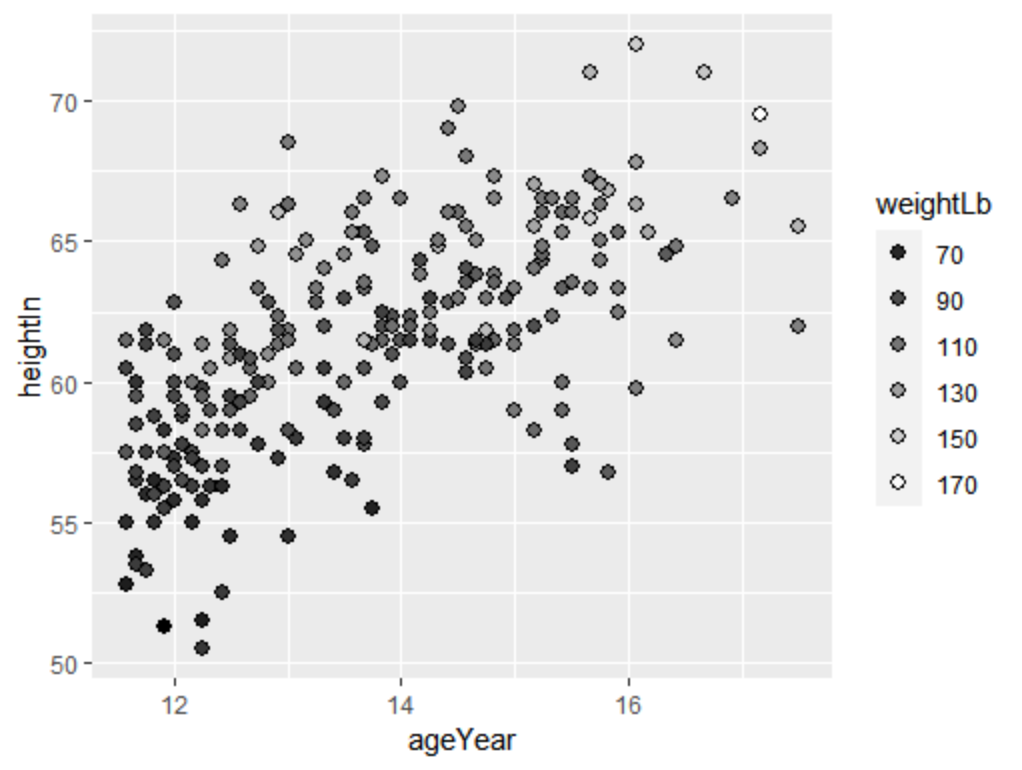
将连续性变量映射到点上时,同样可以将分类变量选择到其他图形属性中,alpha=0.5将数据点设定为半透明,scale_size_area()函数使数据点面积正比于变量值,scale_colour_brewer()则为修改颜色,使用调色盘中的颜色。
ggplot(heightweight,aes(x=ageYear,y=heightIn,size=weightLb,colour=sex))+geom_point(alpha=0.5)+
scale_size_area()+scale_colour_brewer(palette = "Set1")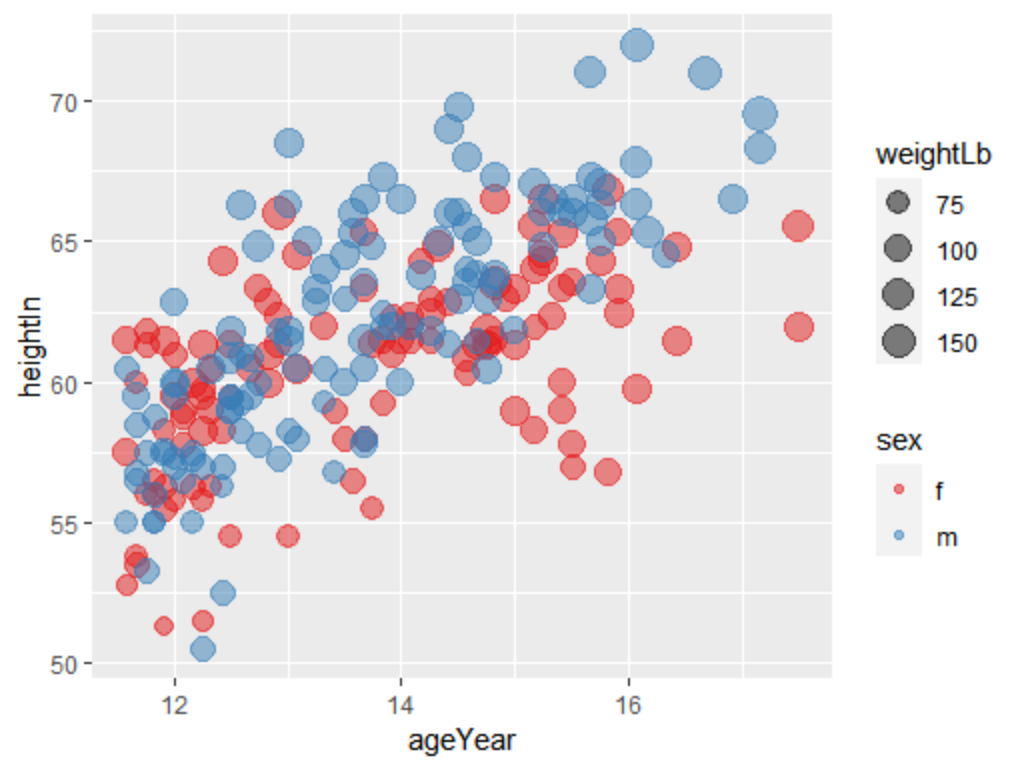
4.处理图形重叠
针对大数据集绘制散点图时,图中各个数据点会彼此遮盖,从而妨碍我们准确地评估数据的分布信息,这就是所谓的图形重叠,如果图形的重叠程度较高,下面是一系列可行的解决方案:
使用半透明的点;
将数据分箱(bin),并用矩形表示(适用于量化分析);
将数据分箱(bin),并用六边形表示;
使用箱线图。
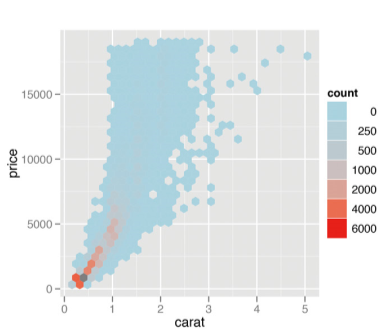
使用gcookbook包中自带数据集diamonds,它包含54000个数据点,将数据点分箱(bin),并以矩形来表示,同时将数据点的密度映射为矩形的填充色,默认情况下,stat_bin_2d() 函数分别在x 轴和y
轴方向上将数据分割为30个组,我们选择bin=50,并选择适合的颜色,最终结果如下:
sp <- ggplot(diamonds, aes(x=carat, y=price))
sp + stat_bin2d(bins=50) +
scale_fill_gradient(low="lightblue", high="red", limits=c(0, 6000))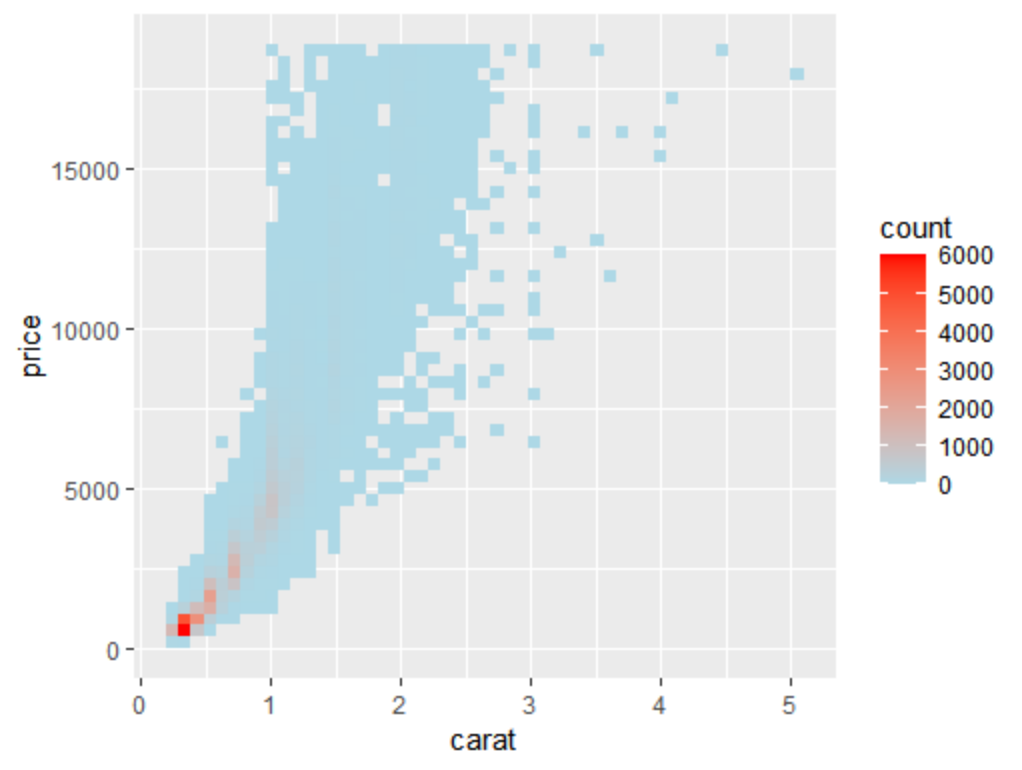
如果不想将数据分箱并以矩形表示的话,可以调用stat_binhex()函数使用六边形代替。该函数通过安装hexbin包来实现。
当散点图其中一个数据轴对应离散型变量时,也会出现数据重叠的情况,这时可以调用position_jitter()函数给数据点增加随机扰动,默认情况下,该函数在每个方向上添加的扰动值为数据点最小精度的40%,不过,也可以通过width 和height 参数对该值进行调整。

sp1 <- ggplot(ChickWeight, aes(x=Time, y=weight))
sp1 + geom_point()
sp1 + geom_point(position="jitter") #也可以调用geom_jitter()函数,两者是等价的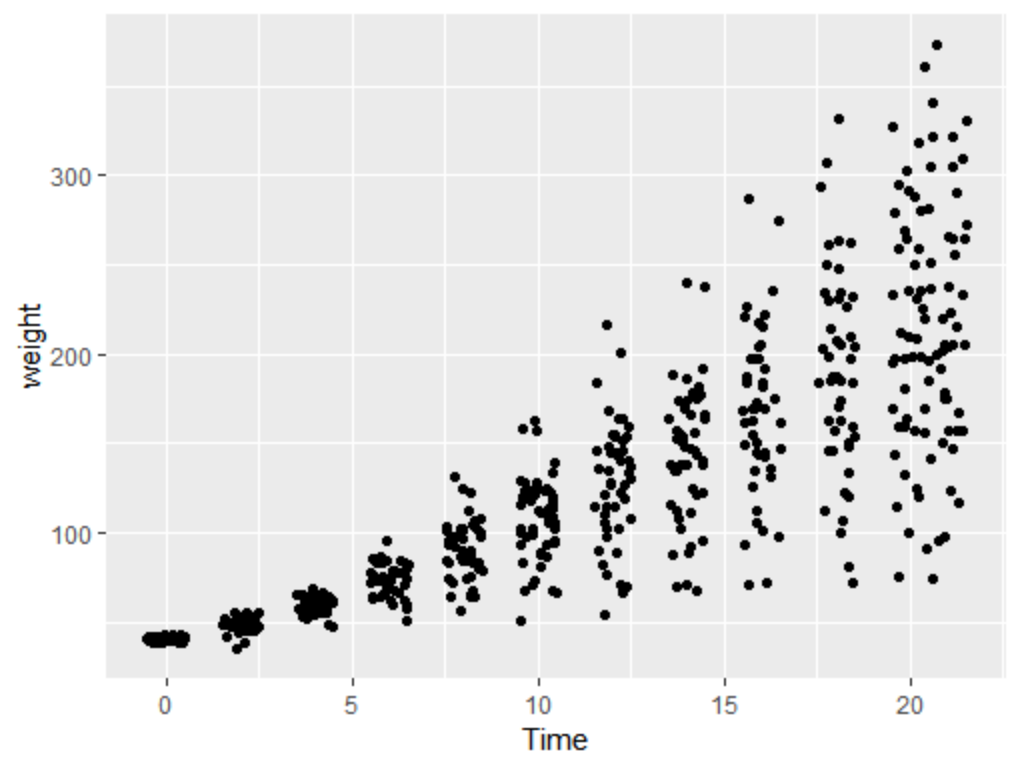
5.添加回归拟合线
(1)直接加
运行stat_smooth()函数,并设定method=lm,(默认为loess曲线,局部加权多项式)即可向散点图中添加线性回归拟合线,这将调用lm()函数对数据拟合线性模型。在默认情况下,stat_smooth() 函数会为回归拟合线添加95%的置信域,可通过level参数进行修改,若不想要置信域,可使用参数se=FALSE。
sp<-ggplot(heightweight,aes(x=ageYear,y=heightIn))
sp+geom_point()+stat_smooth(method = lm,level = 0.99)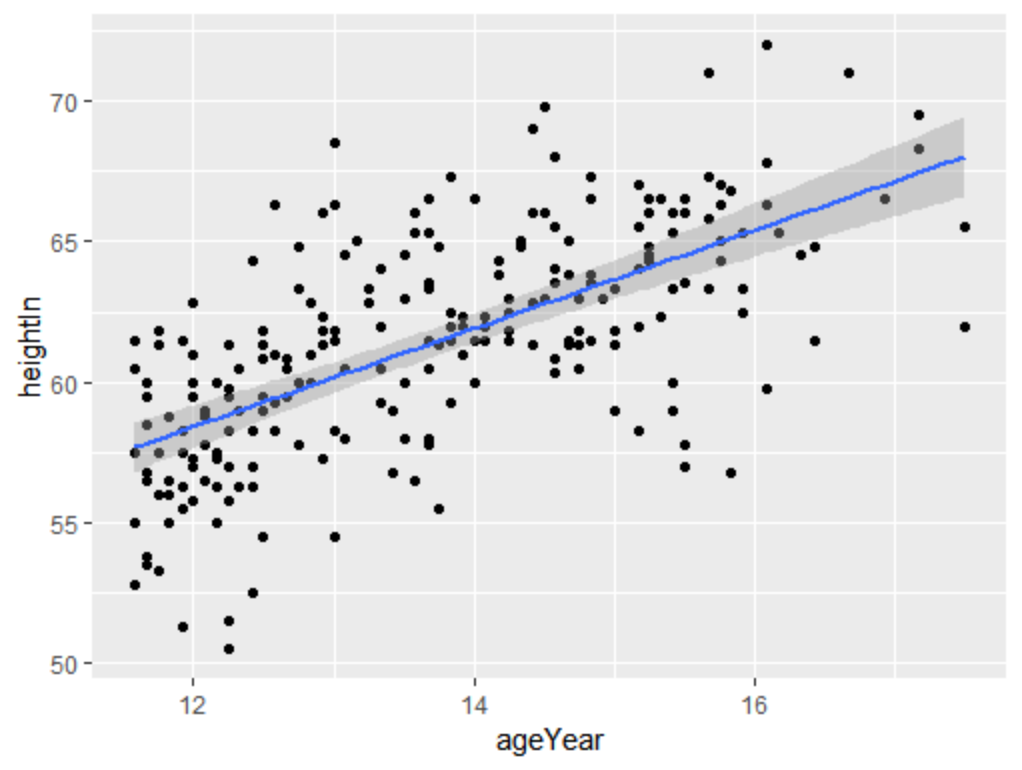
若使用逻辑回归,则method=glm,family=binomial
另外散点图对应的数据集按照某个因子型变量进行了分组,且已将分组变量映射给colour和shape属性时,也可以画出拟合线。如下面例子所示:
(若想基于数据集对拟合线进行外推,要保证模型是可以外推的,如lm,并将选项fullrange=TRUE传递给stat_smooth参数)
sps <- ggplot(heightweight, aes(x=ageYear, y=heightIn, colour=sex)) +
geom_point() +scale_colour_brewer(palette="Set1")
sps + stat_smooth()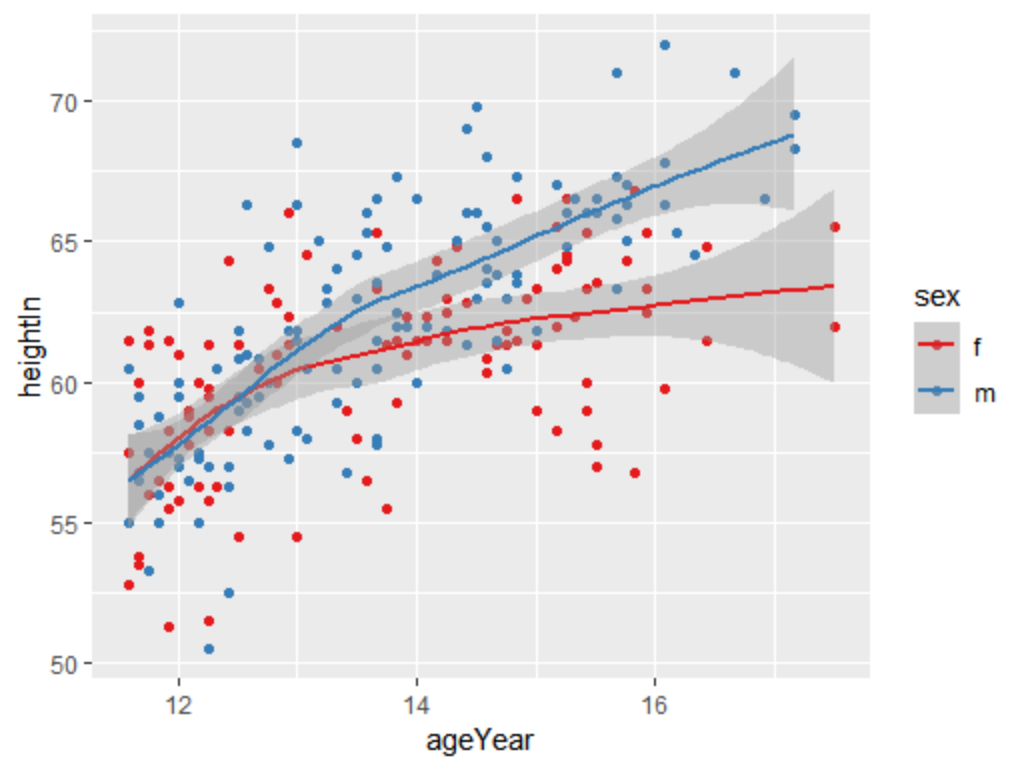
(2)根据已有模型添加
先从一个例子说起,对gcookbook包的数据集heightweight建立线性模型,并根据预测值画出画像
library(gcookbook)
model<-lm(heightIn~ageYear+I(ageYear^2),data=heightweight) #拟合模型
xmin<-min(heightweight$ageYear)
xmax<-max(heightweight$ageYear)
predicted<-data.frame(ageYear=seq(xmin,xmax,length.out=100)) #创建一个包含ageyear的列,对其进行插值
predicted$heightIn<-predict(model,predicted) #计算变量heightIn的预测值
#展示predicted前六行
ageYear heightIn
1 11.58000 56.82624
2 11.63980 57.00047
3 11.69960 57.17294
4 11.75939 57.34363
5 11.81919 57.51255
6 11.87899 57.67969
spc <- ggplot(heightweight, aes(x=ageYear, y=heightIn)) +
geom_point(colour="grey40")
spc+geom_line(data=predicted,size=1)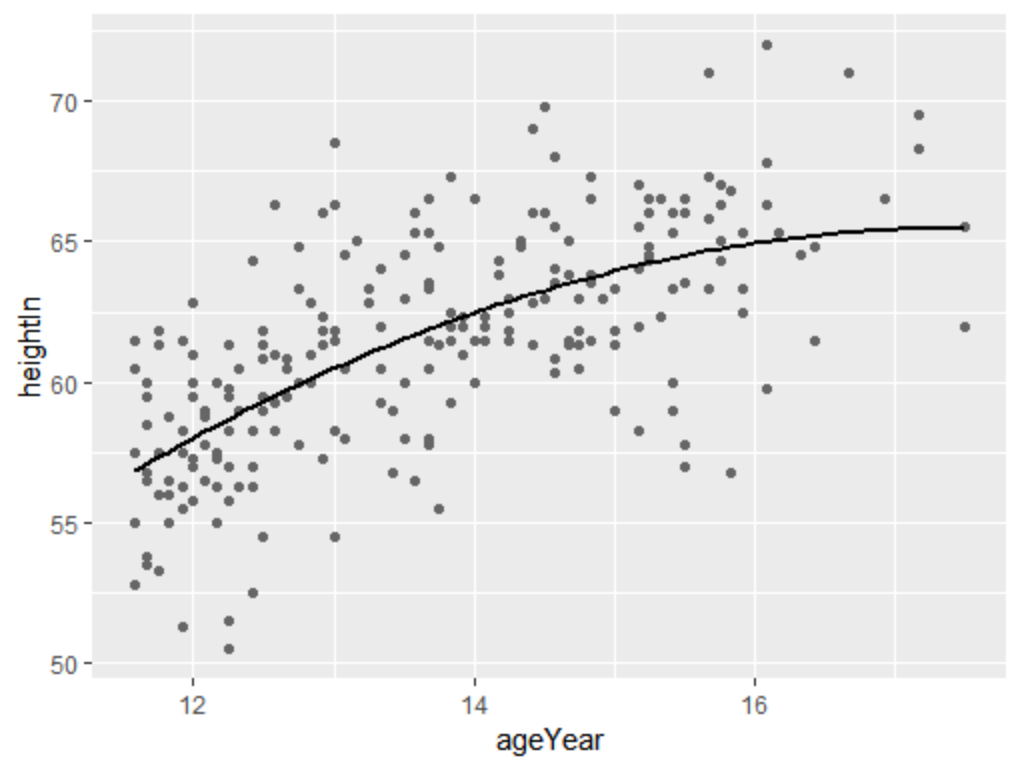
无论哪种模型,只要有对应的predict()方法,则其都可用来绘制拟合线,如loess()函数对应的predict()方法是predict.loess()。
可应用下面定义的predictvals()函数,简化向散点图添加模型拟合线的过程。使用时,只需向其传递一个模型作为参数,该函数就会自动查询变量名、预测变量范围、并返回一个包含预测变量和模型预测值的数据框。将该数据框传递给geom_line()函数,即可绘制我们在前面看到的模型拟合线:
#predictvals函数
# 根据模型和变量xvar预测变量yvar
# 仅支持单一预测变量的模型
# xrange: x轴范围,当值为NULL时,等于模型对象中提取的x轴范围;当设定为包含两个数字的
# 向量时,两个数字分别对应于x轴范围的上下限
# sample:x轴上包含的样本数量
# ...: 可传递给predict()函数的其他参数
predictvals<-function(model,xvar,yvar,xrange=NULL,samples=100,...){
# 如果xrange没有输入,则从模型对象中自动提取x轴范围作为参数
# 提取xrange参数的方法视模型而定
if(is.null(xrange)) {
if (any(class(model) %in% c("lm","glm")))
xrange <- range(model$model[[xvar]])
else if (any(class(model) %in% "loess"))
xrange <- range(model$x)
}
newdata <- data.frame(x = seq(xrange[1], xrange[2], length.out = samples))
names(newdata) <- xvar
newdata[[yvar]] <- predict(model, newdata = newdata, ...)
newdata
}
#建立不同模型
modlinear<-lm(heightIn~ageYear,heightweight)
modloess<-loess(heightIn~ageYear,heightweight)
#针对模型调用上面的函数
lm_predicted <- predictvals(modlinear, "ageYear", "heightIn")
loess_predicted <- predictvals(modloess, "ageYear", "heightIn")
spc + geom_line(data=lm_predicted, colour="red", size=.8) +
geom_line(data=loess_predicted, colour="blue", size=.8)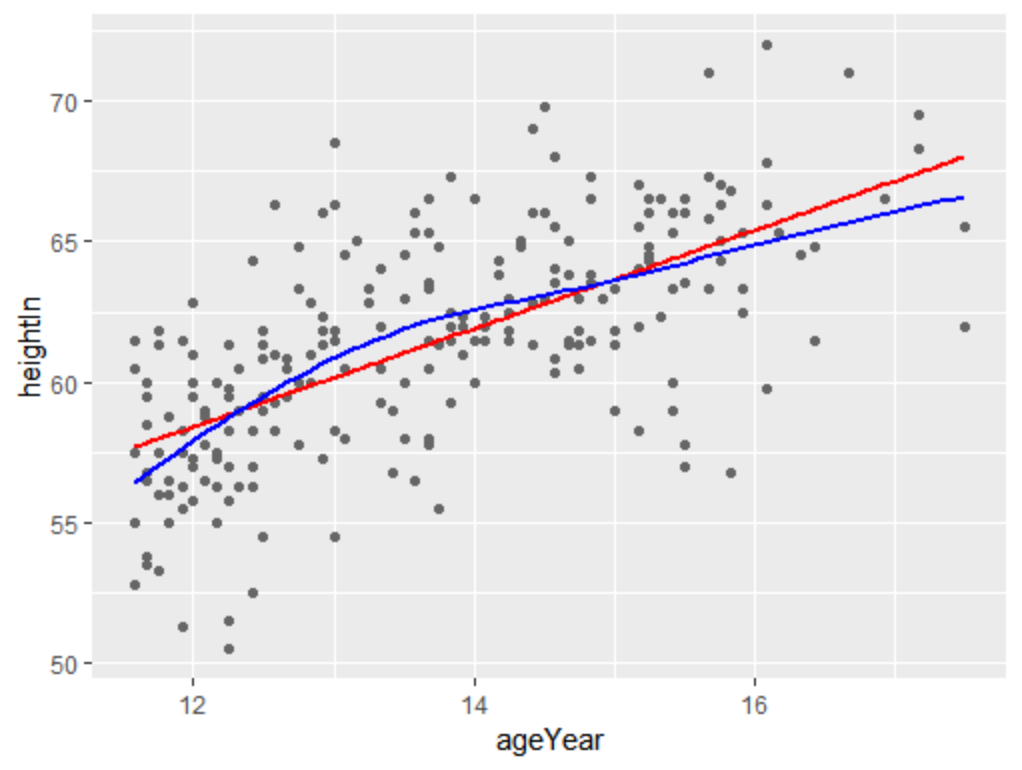
对于具有非线性连接函数的glm模型,需要将predictvals()函数的参数设定为type="response"
。这样做的原因是,默认情况下该函数返回的预测结果是基于线性项的,而不是基于响应变量的。
以MASS包中的biopsy数据为例,现将calss响应变量的值转为0和1,再画图
#数据集处理
library(MASS)
b<-biopsy
b$classn[b$class=="benign"]<-0
b$classn[b$class=="malignant"]<-1
#拟合模型
fitlogistic<-glm(classn~V1,b,family = binomial)
# 获取预测值
glm_predicted <- predictvals(fitlogistic, "V1", "classn", type="response")
ggplot(b, aes(x=V1, y=classn)) +
geom_point(position=position_jitter(width=.3, height=.08), alpha=0.4,
shape=21, size=1.5) +
geom_line(data=glm_predicted, colour="#1177FF", size=1)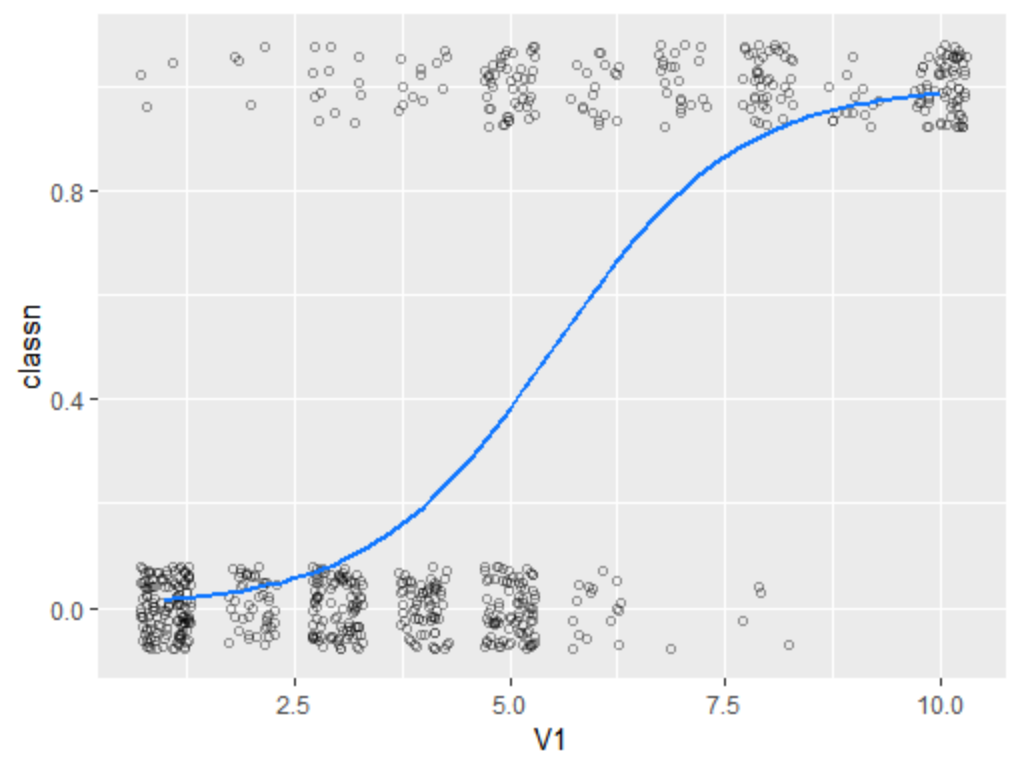
(3)添加多个模型的拟合曲线
可使用上述的predictvals函数和plyr包处理数据就可实现。
例如前面的例子中,可根据变量sex的水平对heightweight数据集进行分组,调用lm()函数对每组数据分别建立线性模型,并将模型结果存放在一个列表内。随后,通过下面定义的make_model()函数建立模型。调用该函数时,向其输入一个数据框作为参数,该函数会返回一个lm对象。也可以根据数据集自定义模型:
make_model <- function(data) {
lm(heightIn ~ ageYear, data)
}有了上面的函数之后,可以调用dlply()函数分别针对数据集的各个子集建立模型。在执行过程中,函数会根据分组变量sex将数据框切分为不同的子集,并对各个子集执行make.model()函数。本例中,heightweight数据集被切分为男性组和女性组,make_model()函数分别对两个组的数据建立模型。调用dlply()函数将模型结果输出到列表中,并返回列表:
library(plyr)
models<-dlply(heightweight,"sex",.fun = make_model)
predvals <- ldply(models, .fun=predictvals, xvar="ageYear", yvar="heightIn")
ggplot(heightweight, aes(x=ageYear, y=heightIn, colour=sex)) +
geom_point() + geom_line(data=predvals) 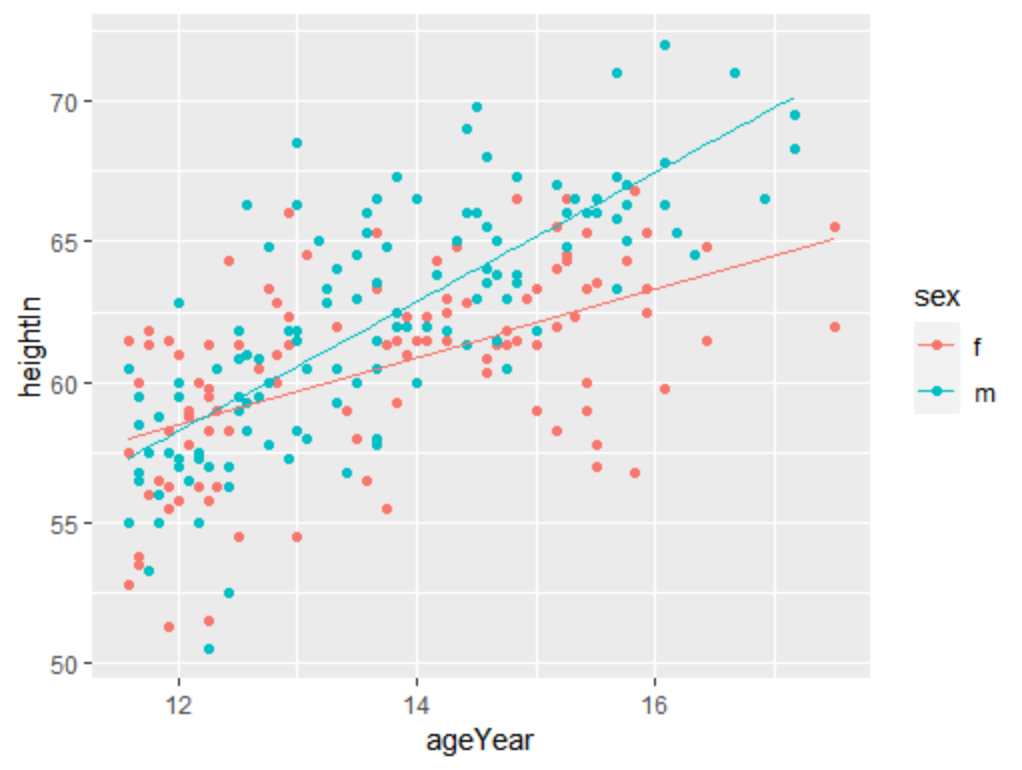
(4)向散点图添加模型系数
对于简单的文本,可以注释形式添加到图形上,以下面的例子为例,为图形添加注释:
model <- lm(heightIn ~ ageYear, data=heightweight)
summary(model)
pred<-predictvals(model,"ageYear","heightIn") #生成预测值
spa<-ggplot(heightweight, aes(x=ageYear, y=heightIn)) + geom_point() +
geom_line(data=pred)
spa+annotate("text",label="r^2==0.42",parse=TRUE,x=16.5,y=52)设置parse=TRUE调用R的数学表达式语法来输入公式,若想使用纯文本字符串当注释的话,可以不设置
使用数学公式作为注释时,必须使用正确的语法才能保证系统输出一个合法的R表达式对象。把公式封装在expression()内部,检验其输出结果可以辅助判断R表达式的有效性(确保公式两边没有引号)。
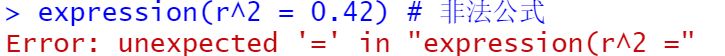
6.向散点图添加边际地毯
边际地毯图本质上是一个一维的散点图,它可被用于展示每个坐标轴上数据的分布情况。可调用geom_rug()函数实现,如下面例子所示:
ggplot(faithful, aes(x=eruptions, y=waiting)) + geom_point() +
geom_rug(position="jitter", size=0.2)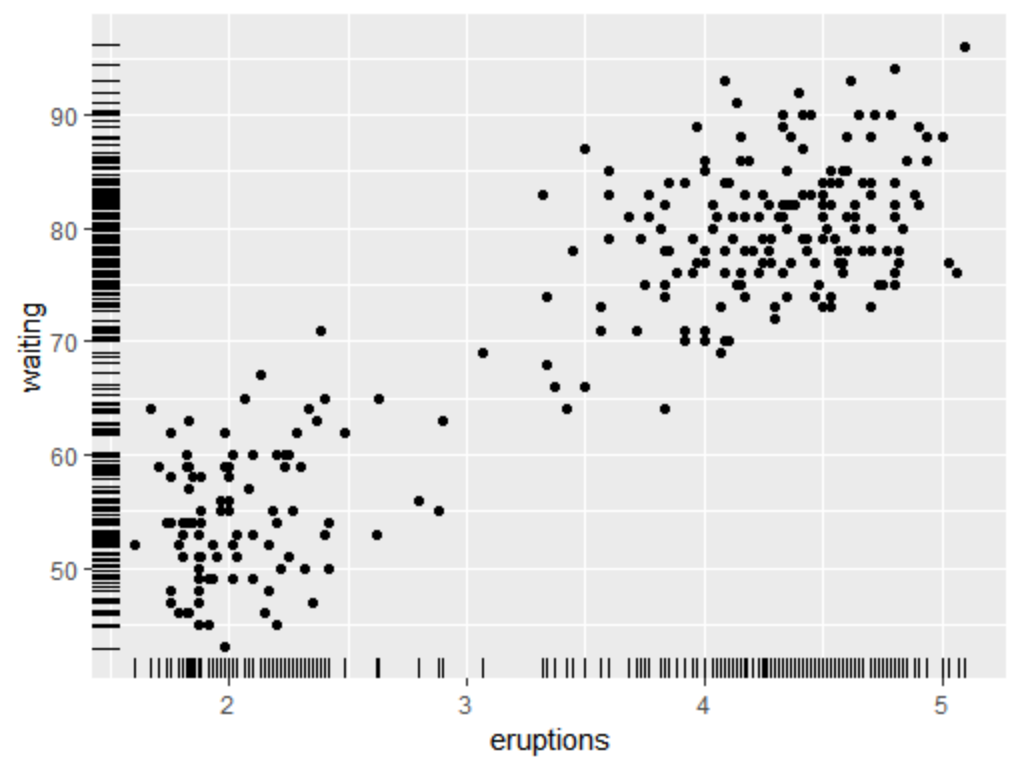
7.向散点图添加标签
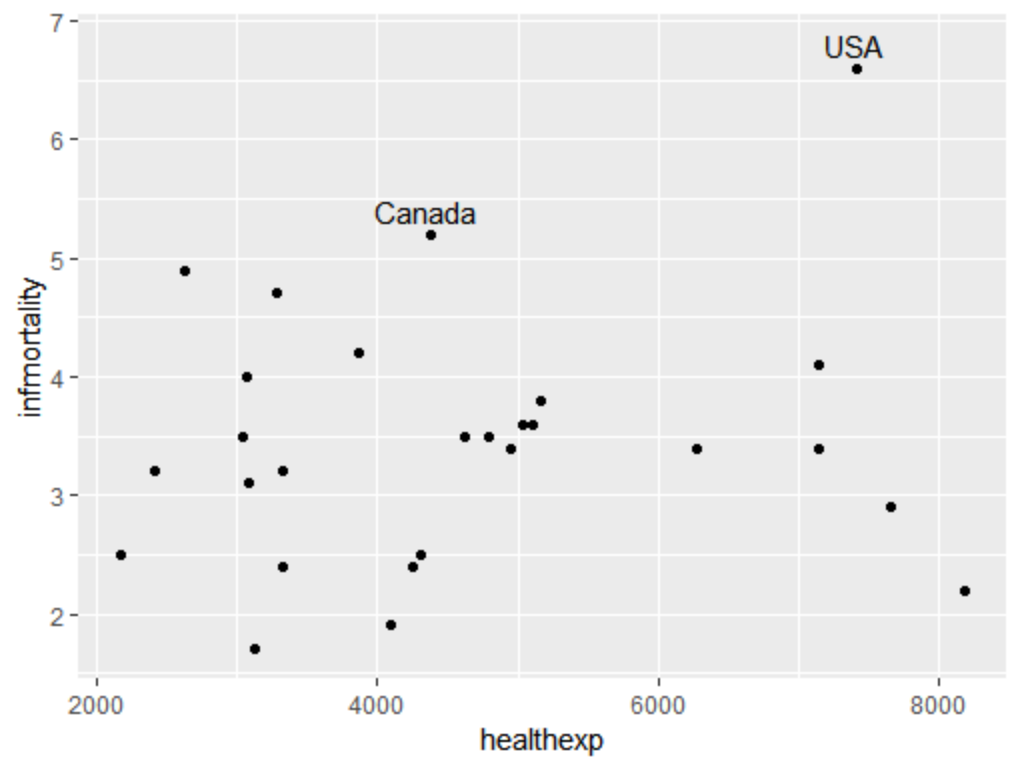
调用annotate()函数或者geom_text() 函数可以为一个或几个数据点添加标签,下面以countries数据集为例,为了便于操作,选取人均支出大于2000美元的国家的数据子集进行分析:
a<-subset(gcookbook::countries, Year==2009 & healthexp>2000) #选取gcookbook中的此数据集
spd<- ggplot(a,aes(x=healthexp, y=infmortality)) +geom_point()
spd+ annotate("text", x=4350, y=5.4, label="Canada") +
annotate("text", x=7400, y=6.8, label="USA")
若要根据数据集自动向散点图添加数据标签,可以使用geom_text()函数,此时,只需映射一个因子型或者字符串型的向量给标签(label)属性,如geom_text(aes(label=Name), size=5)
若想对文本位置进行调整时,可使用vjust(上下)或hjust(左右)
三 绘制气泡图
调用geom_point() 和scale_size_area()函数即可绘制气泡图。下面以countries 数据集的子集为例:
cdat <- subset(gcookbook::countries, Year==2009 &
Name %in% c("Canada", "Ireland", "United Kingdom", "United States",
"New Zealand", "Iceland", "Japan", "Luxembourg",
"Netherlands", "Switzerland"))
#展示cdat前六行
Name Code Year GDP laborrate healthexp infmortality
1733 Canada CAN 2009 39599.04 67.8 4379.761 5.2
4436 Iceland ISL 2009 37972.24 77.5 3130.391 1.7
4691 Ireland IRL 2009 49737.93 63.6 4951.845 3.4
4946 Japan JPN 2009 39456.44 59.5 3321.466 2.4
5864 Luxembourg LUX 2009 106252.24 55.5 8182.855 2.2
7088 Netherlands NLD 2009 48068.35 66.1 5163.740 3.8
p <- ggplot(cdat, aes(x=healthexp, y=infmortality, size=GDP)) +
geom_point(shape=21, colour="black", fill="cornsilk")
# 将GDP映射给面积,得到一个略大的圆圈
p + scale_size_area(max_size=15)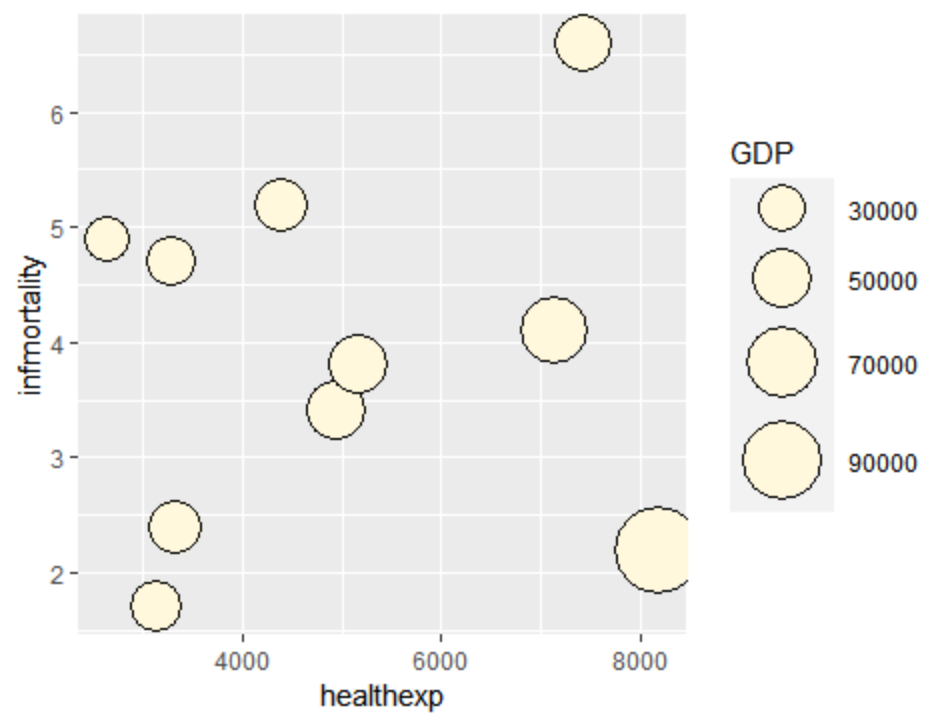
四 散点图矩阵
散点图矩阵是一种对多个变量两两之间关系进行可视化的有效方法。调用R基础绘图系统中的pairs()
函数可绘制。
library(gcookbook) # 为了使用数据
c2009 <- subset(gcookbook::countries, Year==2009,
select=c(Name, GDP, laborrate, healthexp, infmortality))
pairs(c2009[,2:5])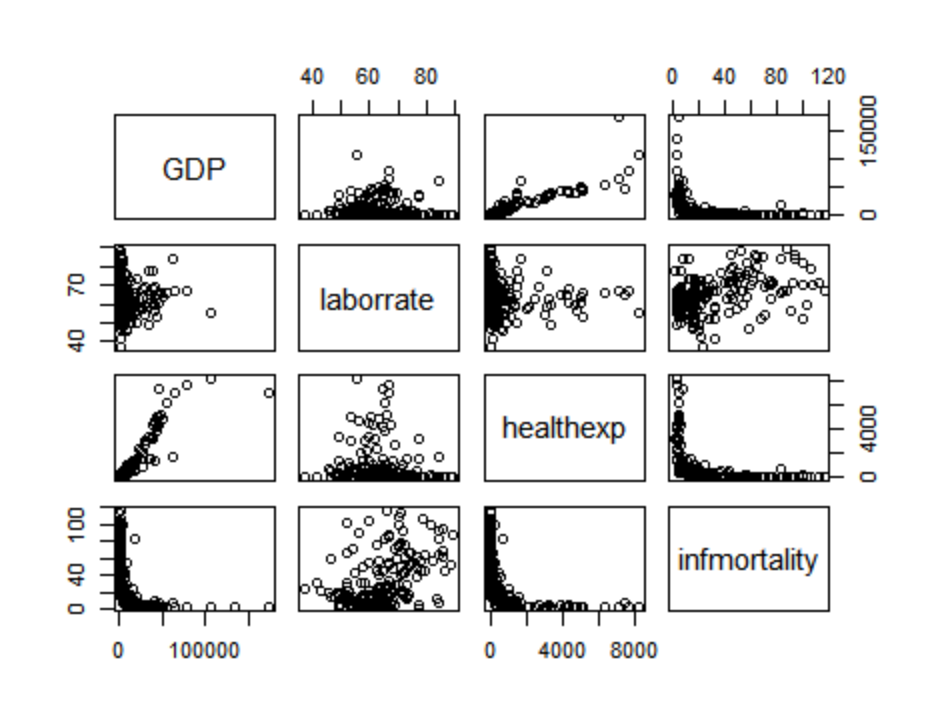


















 584
584



 到【灌水乐园】发言
到【灌水乐园】发言








