







准备工作
tidyverse库的安装和加载
要想使用ggplot2函数,先要安装和加载tidyverse库
install.packages("tidyverse")
library(tidyverse)
例子中使用的mpg数据框
为了做示范,我们使用tidyverse库中提供的mpg数据框。
想要了解mpg是做什么的
?mpg
数据展示的就是:1999 年至 2008 年 38 种常用车型的燃油经济性数据
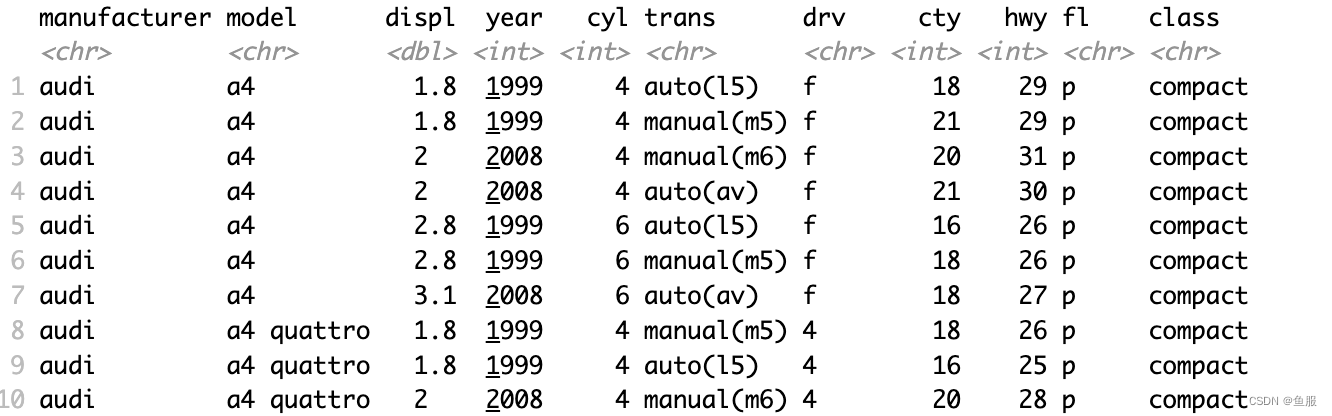
常用到的几个变量:
displ:汽车发动机尺寸
hwy:汽车在高速公路上的燃油效率,单位:英里每加仑
用ggplot创建散点图
直接创建散点图
ggplot(data=mpg)+geom_point(mapping=aes(x=displ,y=hwy))
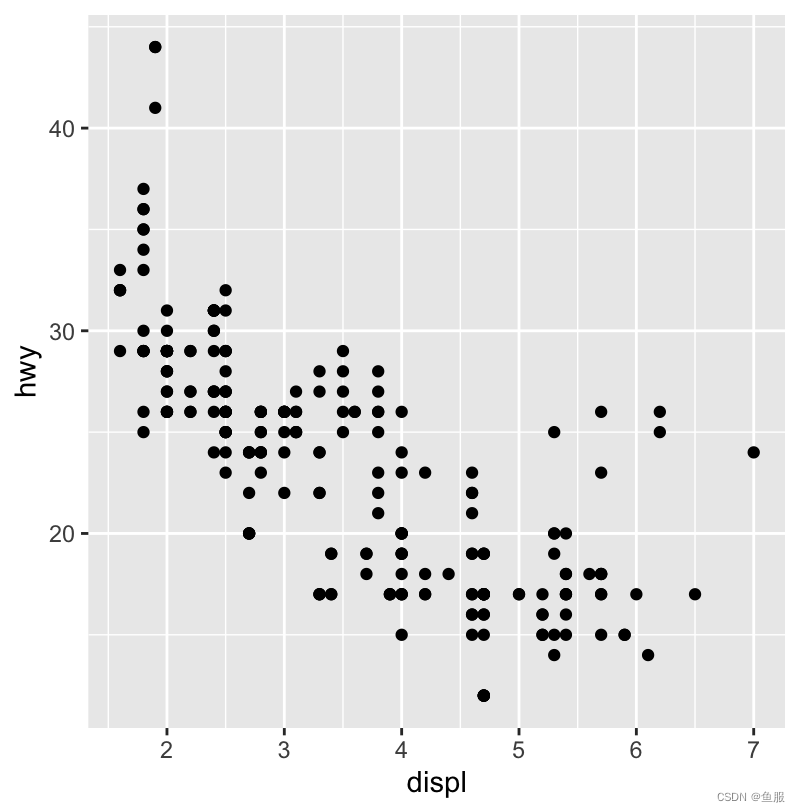
从散点图分布,发动机尺寸和燃油率总体呈现负相关。也就是说,从宽泛的角度上讲,发动机尺寸越大,燃油率越低。
解释一下代码:
ggplot(data=mpg)+geom_point(mapping=aes(x=displ,y=hwy))
#指定了数据来源为mpg,并且创建了一个空画布。
#如果你运行这行代码,得到的是一个空页面
#后面的+geom_point()创建了一个散点图
#函数一个很重要的参数是mapping
#maping说明了散点图x坐标数据和y坐标数据。
通过颜色分类
散点图中有一些图远离了回归曲线。

这时我们推测这些异常值可能和车的种类有关系。
我们可以找到mpg的表格数据,发现class这个变量存储了车的类别信息。通过unique函数来看看到底有多少种车。
unique(mpg$class)
[1] "compact" "midsize" "suv" "2seater" "minivan" "pickup" "subcompact"
那我们想要通过ggplot显示散点图,但是要用不同的颜色标注出不同的类别来。下面的代码就诞生了。
ggplot(data=mpg)+geom_point(mapping=aes(x=displ,y=hwy,color=class))
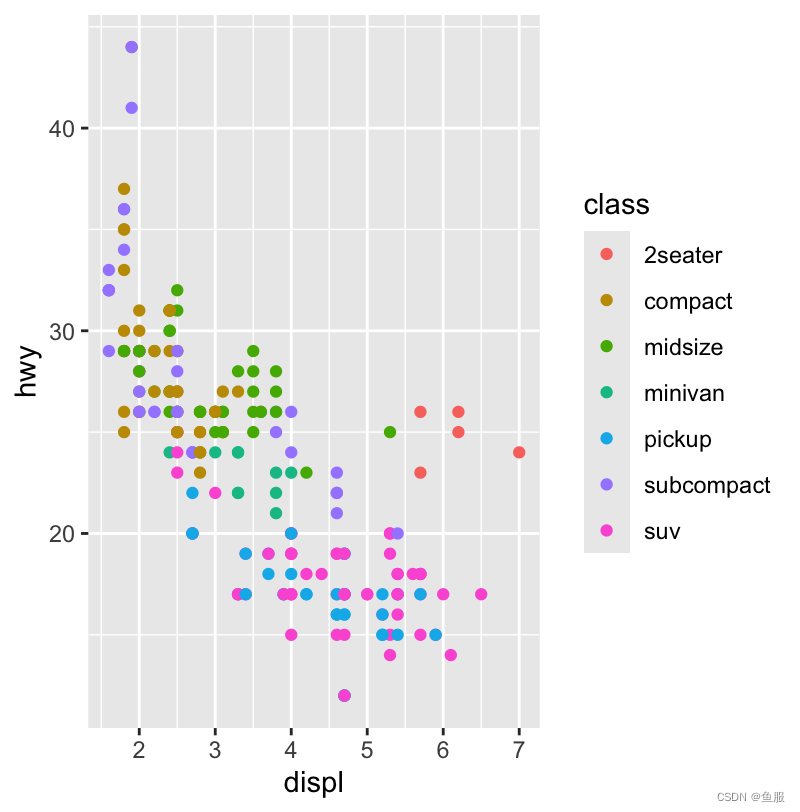
给散点图加上颜色之后,我们就能清晰得看见,异常值都属于“2seater”这一类,也就两座车相比之下虽然引擎更大,但燃油率却相对较高。
当然除了用颜色标注之外,我们还可以用散点图的散点大小来分类,也可以用散点的形状来分类。
代码修改只需要把color=class改成size=class,或alpha=class或shape=class。
要注意的点是,上述参数都要在aes()里面。
通过position=jitter来设置噪点,避免遮盖
但是我们知道mpg这个数据集有234个数据。
想确认数据集的数据个数,可以通过以下两种方式:
# view可以通过展示数据表的方式来查看
?view(mpg)
# count可以返回数据集的数量
(count(mpg))
但是能看到,以上的图片中,点数是没有200多个的。这是因为出现了遮蔽(overlapping)的问题。
比如:
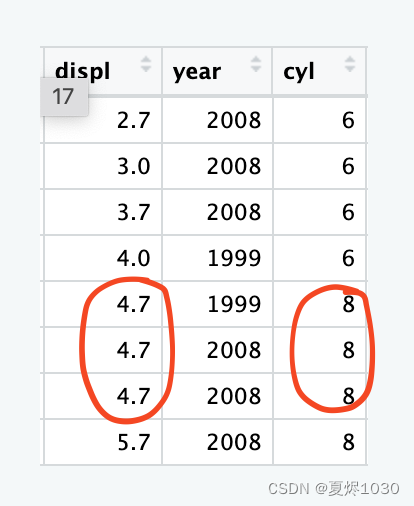
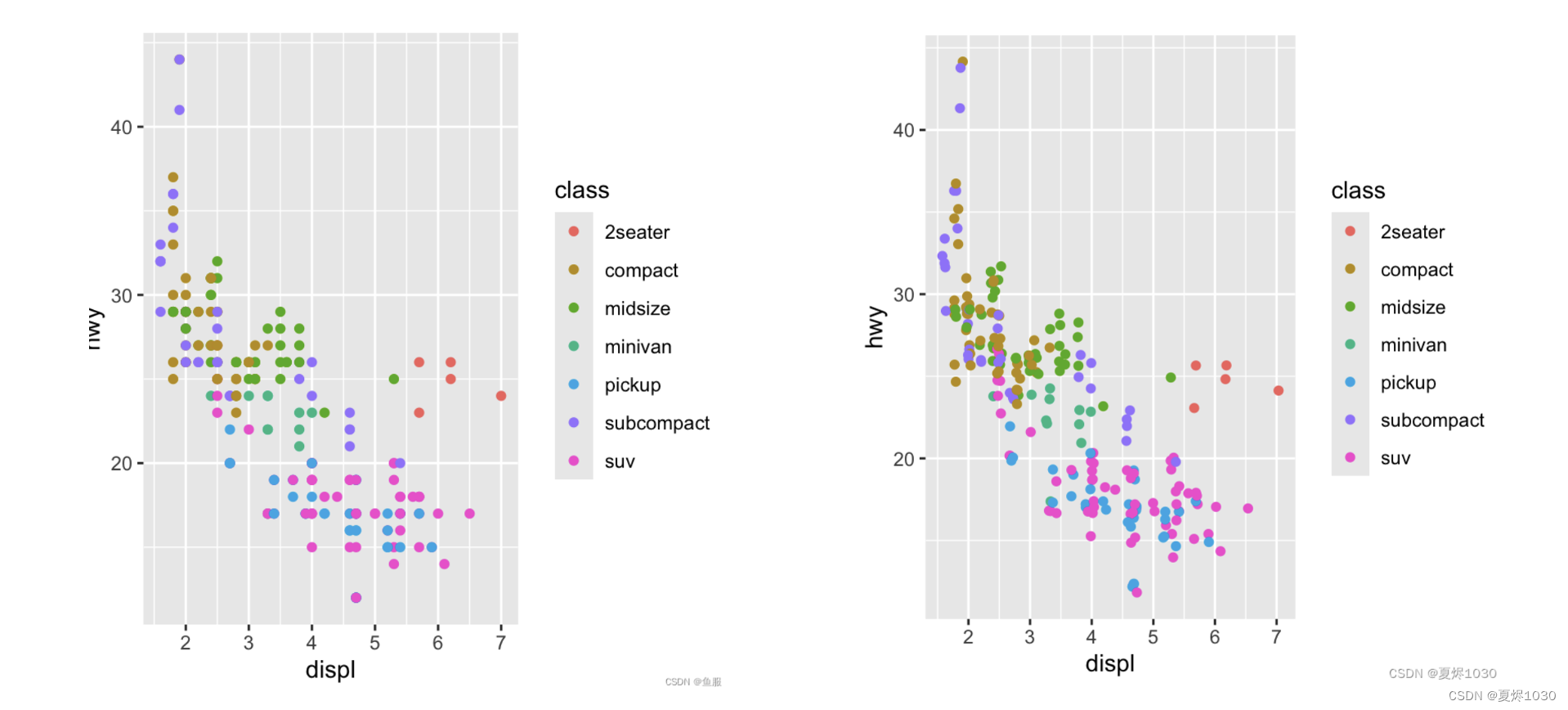
这三个数据集就是重合的,这个时候,我们可以通过position=“jitter”的方式来创造除一种散点的感觉。当然,这样图片展示得就不那么精确了,好处是展现了数据的全部。
ggplot(data=mpg)+geom_point(mapping=aes(x=displ,y=hwy,color=class),position="jitter")
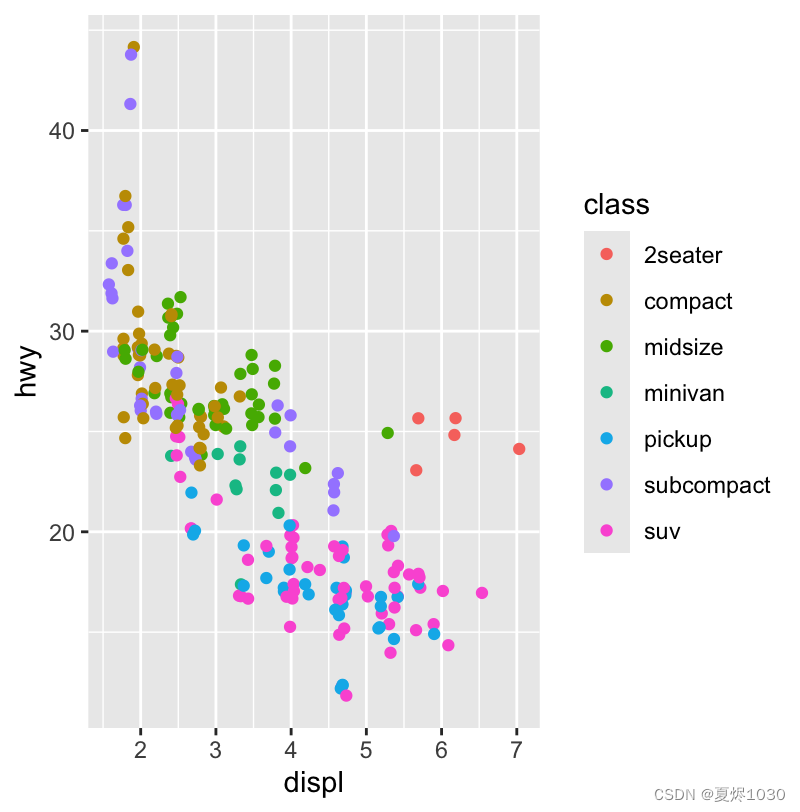
可以和前面的图对比一下:
通过facet_wrap来分类
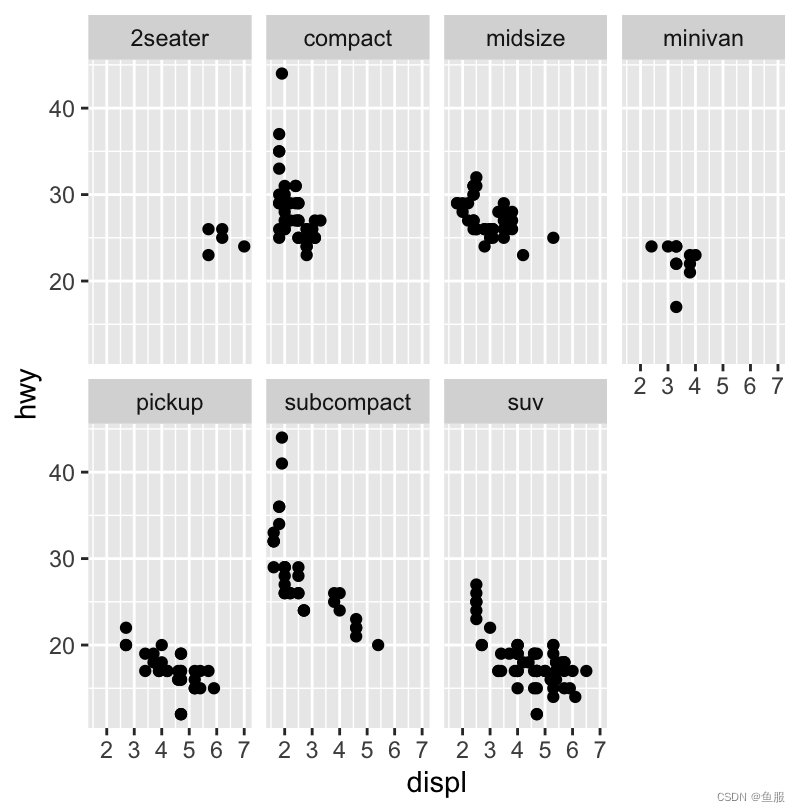
刚刚我们是通过给点做出不同的样式,以便对数据分类。也可以通过facet_wrap函数添加更多的分类变量。
ggplot(data=mpg)+geom_point(mapping=aes(x=displ,y=hwy))+facet_wrap(~class,nrow=2)
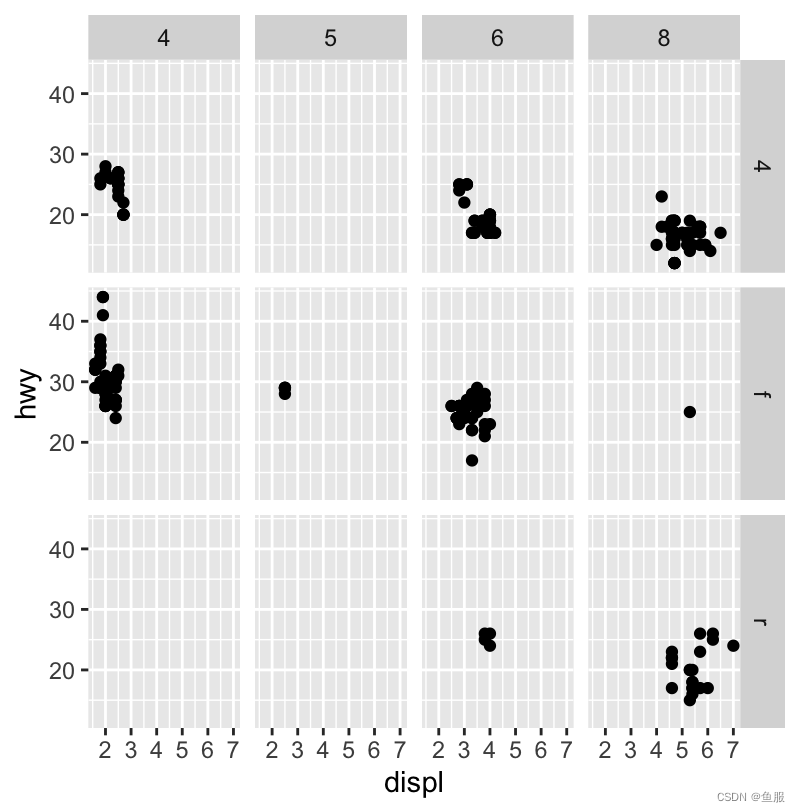
通过facet_grid来分类(可添加两个变量)
ggplot(data=mpg)+geom_point(mapping=aes(x=displ,y=hwy))+facet_grid(drv~cyl)
# drv:驱动系统的类型,其中f =前轮驱动,r =后轮驱动,4 =四轮驱动
# cyl:气缸数
如果你只是想要一个变量,可以
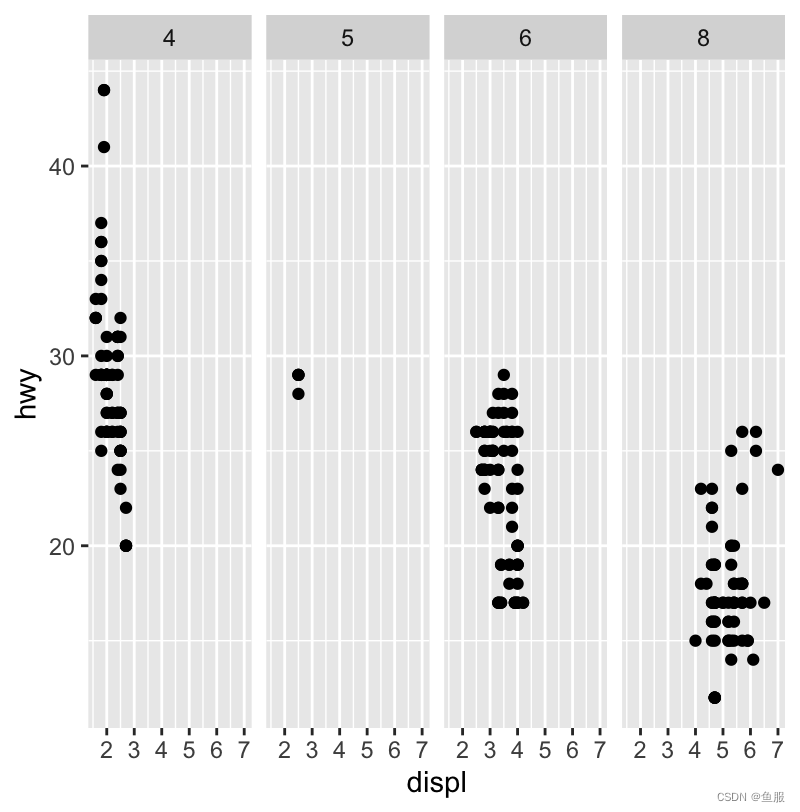
ggplot(data=mpg)+geom_point(mapping=aes(x=displ,y=hwy))+facet_grid(.~cyl)














 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









