






目录
sklearn.tree.DecisionTreeClassifier()函数用于创建一个决策树分类器。
一、关于决策树
1、什么是决策树
决策树是一类常见的机器学习方法,可以帮助我们解决分类与回归两类问题。模型可解释性强,模型符合人类思维方式,是经典的树形结构。分类决策数模型是一种描述对实例进行分类的树形结构。
2、决策树的结点与边
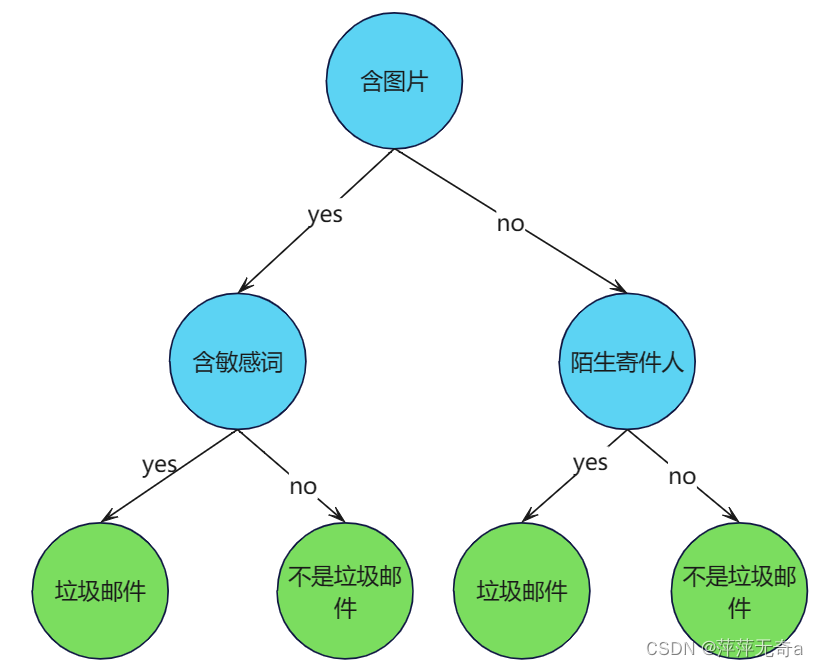
决策树由结点 (node) 和有向边 (directed edge) 组成。结点包含了一个根结点 (root node)、若干个内部结点 (internal node) 和若干个叶结点 (leaf node)。内部结点表示一个特征或属性,叶结点表示一个类别。
(蓝色的为内部结点,绿色的为叶结点。如下图)
3、决策树的优缺点以及适用数据类型
(1)优点
1)易于理解和实现
2)计算复杂度不高,对中间值的缺失不敏感
3)可以处理不相关特征数据
(2)缺点
1)可能会产生过度匹配问题
2)对有时间顺序的数据,需要很多预处理的工作。
3)当类别太多时,错误可能就会增加的比较快。
(3)适用数据类型
数值型和标称型
4、if-else规则
决策树是一个多层if-else函数,对对象属性进行多层if-else判断,获取目标属性的类别。由于只使用if-else对特征属性进行判断,所以一般特征属性为离散值,即使为连续值也会先进行区间离散化,如可以采用二分法(bi-partition)。
二、决策树的构造
1、一般流程
(1) 收集数据:可以使用任何方法。
(2) 准备数据:树构造算法只是用于标称型数据,因此数值型数据必须离散化。
(3) 分析数据:可以使用任何方法,决策树构造完成后,可以检查决策树图形是否符合预期。
(4) 训练算法:构造一个决策树的数据结构。
(5) 测试算法:使用经验树计算错误率。当错误率达到可接收范围,此决策树就可投放使用。
(6) 使用算法:此步骤可以使用适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义。
2、最优属性划分
(1)信息增益 ID3
- 熵(Entropy -1984年香农提出)的概念:一条信息的信息量大小与它的不确定性有直接关系,而熵就是用来度量这件事不确定性的大小。为什么需要了解“熵”这个概念?因为决策树模型的构建和评估都与信息熵密切相关。而 信息熵(Information Entropy)是用来度量样本纯度的指标。
- 以下是信息增益计算步骤:
输入:训练集D和属性a (这里每个属性a有V个可能的取值{ })
输出:属性a对训练数据集D的信息增益 Gain(D,a)
1. 假定样本集合D中第i类样本所占的比例为 ( i=1,2,3,...,|n|) ,需要先求信息熵
信息熵公式:
2. 求离散特征a对数据集D的条件信息熵
条件信息熵公式:
3. 计算信息增益(Information Gain)
信息增益公式:
- 信息熵Ent(D)的值越小,则样本集合(D)的纯度越高。
(2)增益率 C4.5
-
因为信息增益对可取值较多的属性有所偏好,为减少这种偏好可能带来的不利影响,不直接使用信息增益,而使用增益率来选择最优划分属性。
1. 根据ID3的信息熵和条件信息熵 求信息增益
信息增益公式:
2. 计算属性a的固有值IV(a)
固有值计算公式:
3. 根据信息增益和固有值求信息增益率
信息增益率计算公式:
(3)基尼指数 CART
- CART决策树(Classification and Regression Tree)独立于另外两种决策树,一方面它使用基尼指数(Gini Index)作为划分依据,另一方面它既可以做分类,也可以做回归。Python中的sklearn决策树模型就是采用的CART来选择分支的。
步骤:
1. 计算基尼指数
2. 对于属性a计算条件基尼指数
三、代码实现
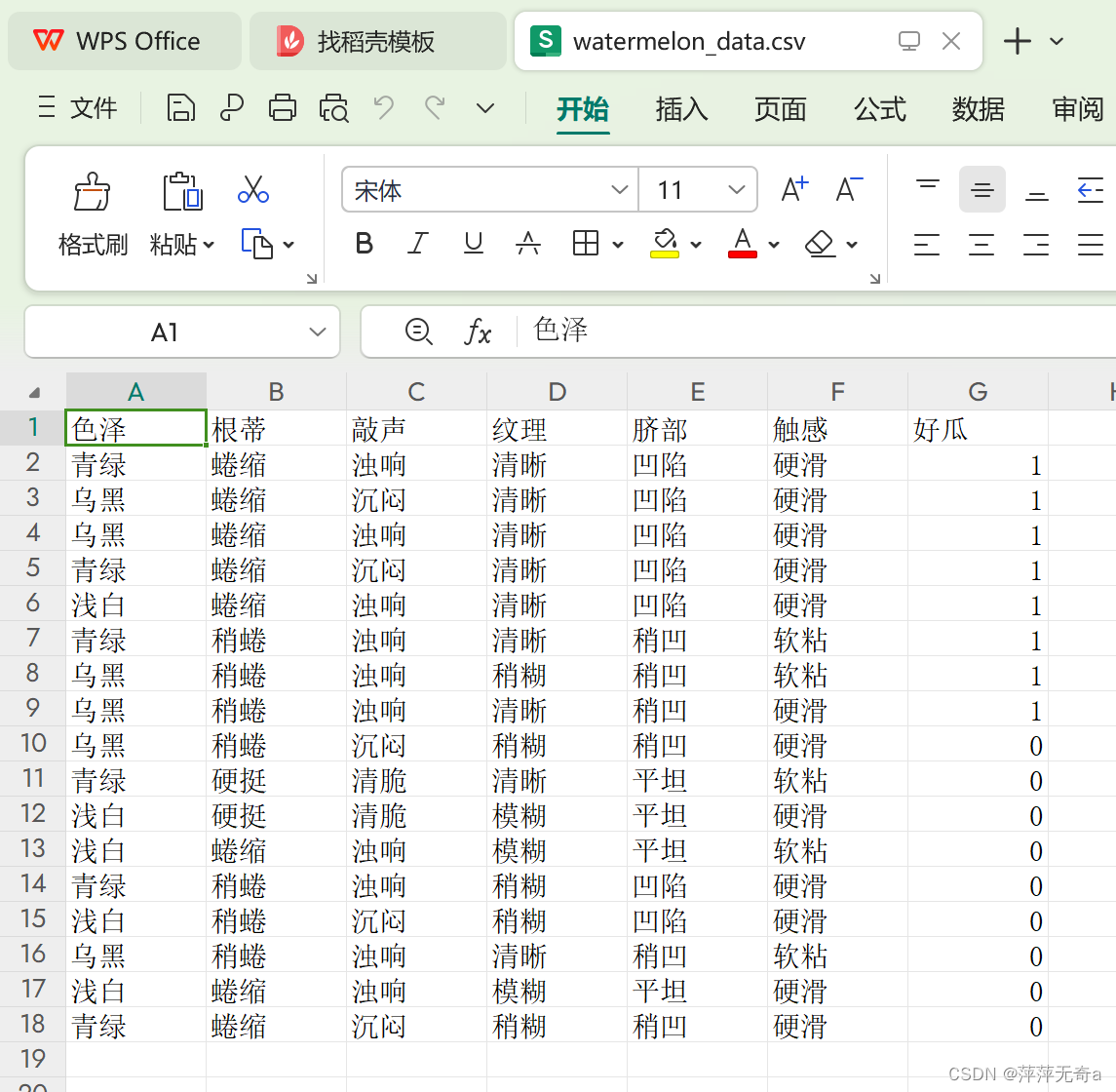
1、数据集展示
2、ID3决策树代码实现
(1)函数分装
- 信息熵的计算
def cal_information_entropy(data):
data_label = data.iloc[:,-1]
label_class =data_label.value_counts() #总共有多少类
Ent = 0
for k in label_class.keys():
p_k = label_class[k]/len(data_label)
Ent += -p_k*np.log2(p_k)
return Ent- 数据集中属性值为a的信息增益
def cal_information_gain(data, a):
Ent = cal_information_entropy(data)
feature_class = data[a].value_counts() #特征有多少种可能
gain = 0
for v in feature_class.keys():
weight = feature_class[v]/data.shape[0]
Ent_v = cal_information_entropy(data.loc[data[a] == v])
gain += weight*Ent_v
return Ent - gain-
获取标签多的类别
def get_most_label(data):
data_label = data.iloc[:,-1]
label_sort = data_label.value_counts(sort=True)
return label_sort.keys()[0]- 挑选最优特征,即信息增益最大的特征
def get_best_feature(data):
features = data.columns[:-1]
res = {}
for a in features:
temp = cal_information_gain(data, a)
res[a] = temp
res = sorted(res.items(),key=lambda x:x[1],reverse=True)
return res[0][0]-
将数据转化为(属性值:数据)的元组形式返回,并删除之前的特征列
def drop_exist_feature(data, best_feature):
attr = pd.unique(data[best_feature])
new_data = [(nd, data[data[best_feature] == nd]) for nd in attr]
new_data = [(n[0], n[1].drop([best_feature], axis=1)) for n in new_data]
return new_data-
创建决策树
def create_tree(data):
data_label = data.iloc[:,-1]
if len(data_label.value_counts()) == 1: #只有一类
return data_label.values[0]
if all(len(data[i].value_counts()) == 1 for i in data.iloc[:,:-1].columns): #所有数据的特征值一样,选样本最多的类作为分类结果
return get_most_label(data)
best_feature = get_best_feature(data) #根据信息增益得到的最优划分特征
Tree = {best_feature:{}} #用字典形式存储决策树
exist_vals = pd.unique(data[best_feature]) #当前数据下最佳特征的取值
if len(exist_vals) != len(column_count[best_feature]): #如果特征的取值相比于原来的少了
no_exist_attr = set(column_count[best_feature]) - set(exist_vals) #少的那些特征
for no_feat in no_exist_attr:
Tree[best_feature][no_feat] = get_most_label(data) #缺失的特征分类为当前类别最多的
for item in drop_exist_feature(data,best_feature): #根据特征值的不同递归创建决策树
Tree[best_feature][item[0]] = create_tree(item[1])
return Tree- ds
def predict(Tree , test_data):
first_feature = list(Tree.keys())[0]
second_dict = Tree[first_feature]
input_first = test_data.get(first_feature)
input_value = second_dict[input_first]
if isinstance(input_value , dict): #判断分支还是不是字典
class_label = predict(input_value, test_data)
else:
class_label = input_value
return class_label
- 主函数
if __name__ == '__main__':
#读取数据
data = pd.read_csv('C://Users//小羔//Desktop//机器学习//watermelon_data.csv')
#统计每个特征的取值情况作为全局变量
column_count = dict([(ds, list(pd.unique(data[ds]))) for ds in data.iloc[:, :-1].columns])
#创建决策树
dicision_Tree = create_tree(data)
print(dicision_Tree)
#测试数据
test_data_1 = {'色泽':'青绿','根蒂':'蜷缩','敲声':'浊响','纹理':'稍糊','脐部':'凹陷','触感':'硬滑'}
test_data_2 = {'色泽': '乌黑', '根蒂': '稍蜷', '敲声': '浊响', '纹理': '清晰', '脐部': '凹陷', '触感': '硬滑'}
result = predict(dicision_Tree,test_data_1)
print('青绿,蜷缩,浊响,稍糊,凹陷,硬滑的西瓜为'+'好瓜'if result == 1 else '青绿,蜷缩,浊响,稍糊,凹陷,硬滑的西瓜为坏瓜')
result2 = predict(dicision_Tree,test_data_2)
print('乌黑,稍蜷,浊响,清晰,凹陷,硬滑的西瓜为'+'好瓜'if result2 == 1 else '乌黑, 稍蜷, 浊响,清晰,凹陷,硬滑的西瓜为坏瓜')结果截图:

(2)决策树可视化
- 设置文本框和箭头格式
decisionNode = dict(boxstyle = "sawtooth", fc = "0.8")
leafNode = dict(boxstyle = "round4", fc = "0.8")
arrow_args = dict(arrowstyle = "<-")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.family'] = 'sans-serif'
- 画出结点
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy = parentPt,\
xycoords = "axes fraction", xytext = centerPt, textcoords = 'axes fraction',\
va = "center", ha = "center", bbox = nodeType, arrowprops = arrow_args)
- 获取决策树的叶子结点树
def getNumLeafs(myTree):
leafNumber = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if(type(secondDict[key]).__name__ == 'dict'):
leafNumber = leafNumber + getNumLeafs(secondDict[key])
else:
leafNumber += 1
return leafNumber- 采用递归法获取决策树的高度
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
#测试以查看节点是否是字典,如果不是,则它们是叶节点
if type(secondDict[key]).__name__=='dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth- 在父子结点前添加相关信息
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
- 画出决策树
def plotTree(myTree, parentPt, nodeTxt):#如果第一个键告诉你在什么特征处
numLeafs = getNumLeafs(myTree) #被拆分了,这决定了这棵树的 x 宽度
depth = getTreeDepth(myTree)
firstStr = list(myTree.keys())[0] #此结点的标签应为以下内容
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
plotTree(secondDict[key],cntrPt,str(key)) #递归
else: #这是叶子结点,输出
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
- 初始化画布
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (0.5,1.0), '')
plt.show()
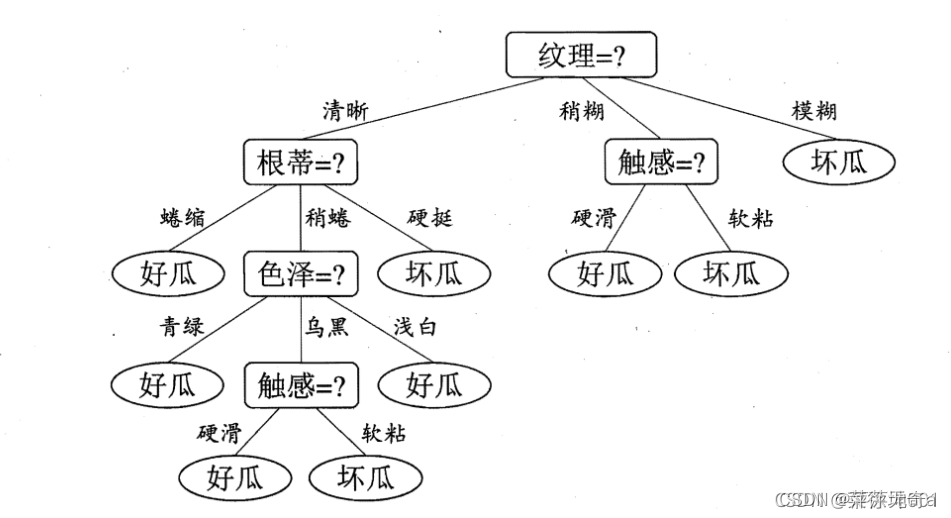
结果截图:
2、C4.5决策树代码实现
(1)构建决策树
- 数据导入
data = pd.read_csv('C://Users//小羔//Desktop//机器学习//watermelon_data.csv')
x = data[["色泽","根蒂","敲声","纹理","脐部","触感"]].copy()
y = data['好瓜'].copy()
print(data)
- 将特征值数值化
for i in ["色泽","根蒂","敲声","纹理","脐部","触感"]:
for j in range(len(x)):
if(x[i][j] == "青绿" or x[i][j] == "蜷缩" or data[i][j] == "浊响" \
or x[i][j] == "清晰" or x[i][j] == "凹陷" or x[i][j] == "硬滑"):
x[i][j] = 1
elif(x[i][j] == "乌黑" or x[i][j] == "稍蜷" or data[i][j] == "沉闷" \
or x[i][j] == "稍糊" or x[i][j] == "稍凹" or x[i][j] == "软粘"):
x[i][j] = 2
else:
x[i][j] = 3
y = y.copy()
for i in range(len(y)):
if(y[i] == 0):
y[i] = int(1)
else:
y[i] = int(-1) -
转化数据x,y格式,数据框dataframe
x = pd.DataFrame(x).astype(int)
y = pd.DataFrame(y).astype(int)
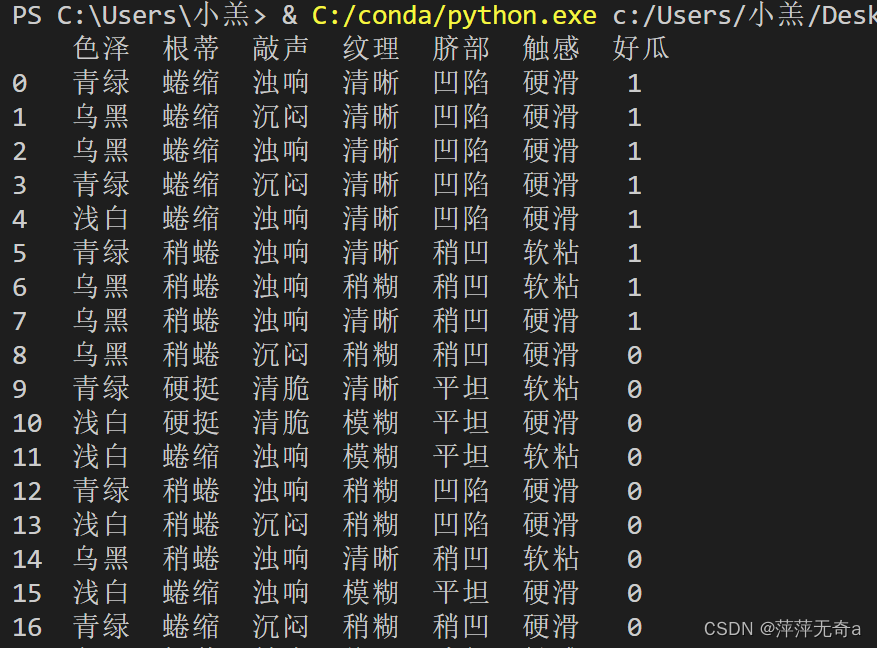
print(x)
print(y)
结果截图:

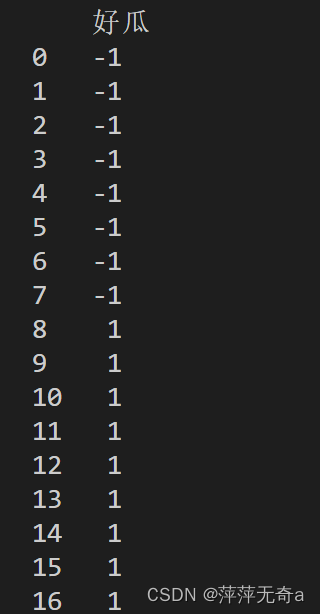
- 将80%数据用于训练,20%数据用于测试
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2)
print(x_train)
结果截图:
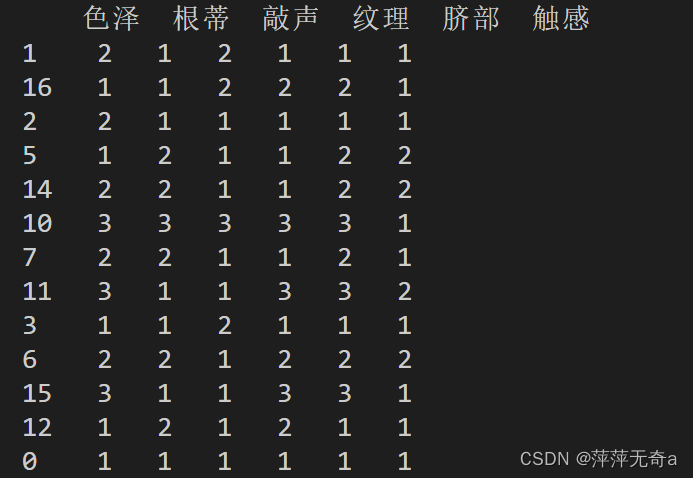
(2)决策树可视化
sklearn.tree.DecisionTreeClassifier()函数用于创建一个决策树分类器。
具体可参考:DecisionTreeClassifier()函数解析
export_graphviz此函数生成决策树的 graphviz 表示
具体可参考:
clf = tree.DecisionTreeClassifier(criterion='gini', splitter='best', max_depth=None, min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None,
random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0,
class_weight=None)
feature_name = ["色泽","根蒂","敲声","纹理","脐部","触感"]
clf.fit(x_train,y_train)
dot_data = tree.export_graphviz(clf,feature_names= feature_name,class_names=["好瓜","坏瓜"]
,filled=True
,rounded=True
,out_file =None
)
graph = graphviz.Source(dot_data)
graph.save('C://Users//小羔//Desktop//机器学习//watermelon_tree.dot') #保存结果截图:
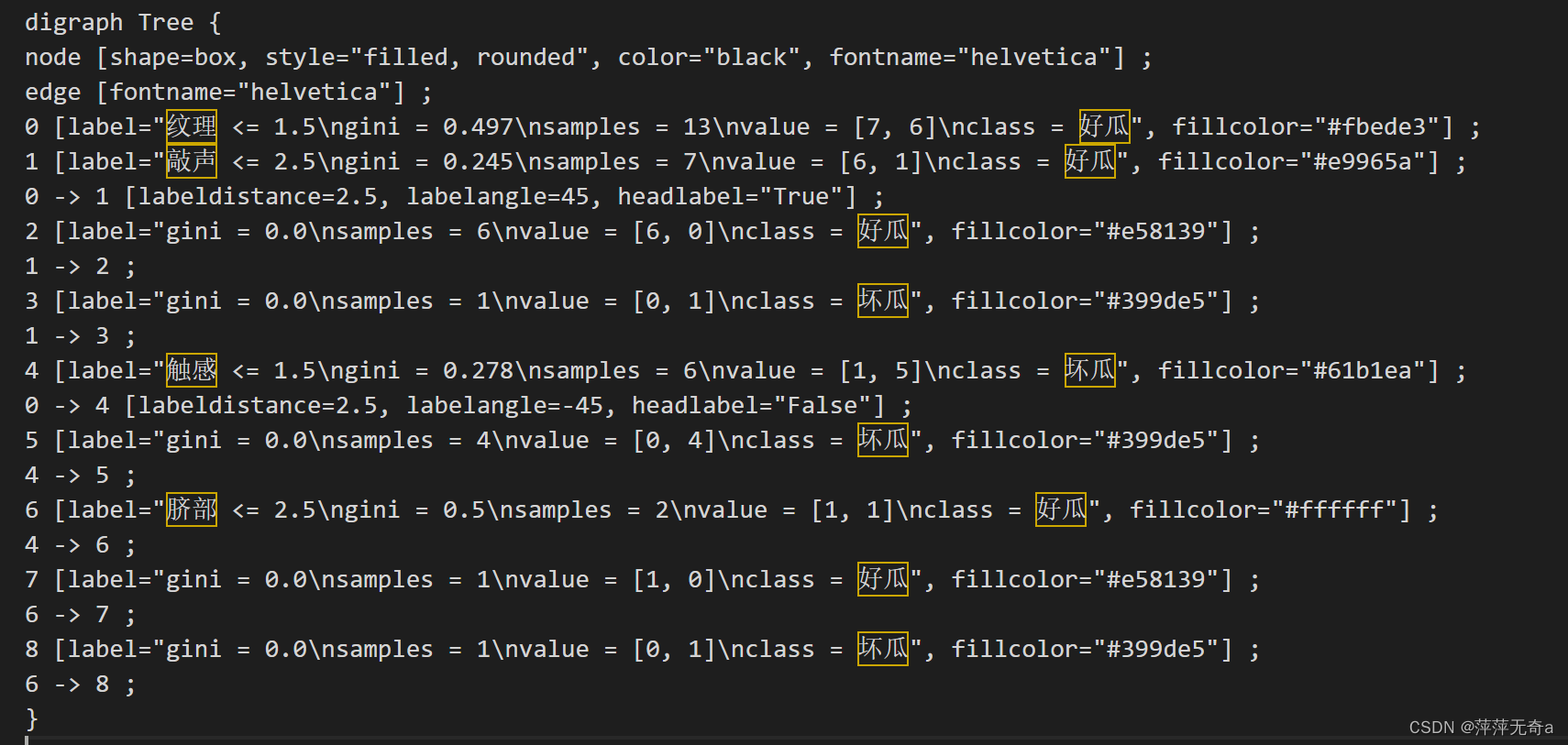
四、实验总结
1、决策树作为经典分类算法,具有计算复杂度低、结果直观、分类效率高等优点。
2、学习通过用sk-learn库对西瓜数据集,进行ID3算法代码实现,通过sklearn库和graphviz库C4.5的算法代码实现。
3、采用C4.5算法的决策树可视化使用的是graphviz库,在可视化时采用时,由于没有安装graphviz所以保存下来的dot文件只能打开为文本文件。
五、错误总结
- 使用决策树分类器函数时报错,内部参数使用错误。

解决过程:通过网上查阅资料得知,“_init_() got an unexpected keyword argument'min_impurity_split”是一个经常遇到的错误信息,它通常出现在使用Scikit-earn库建立决策树、随机森林等模型时。它的产生是因为Scikit-learn库在版本更新后取消了min_impurity_split这个参数。该参数是用于设置节点停止分裂的阈值,如果纯度(impurity)小于该值,则终止分裂。在Salkit-earn库0.23及以后的版本中,min_impurity_Split被替换为min_impurity_decrease,该参数的作用与min_impurity_split大致相同,但它计算方式略有不同。
- 在进行测试数据之前没有对模型进行实例化,我的理解就是在测试数据之前,我们只是定义了决策树模型,而没有对决策树模型输入数据,进行训练,所以模型不知道怎么进行预测。

解决:测试之前加入:clf.fit(x_train,y_train) 进行实例化,问题解决。解决后正常输出结果。
















 1272
1272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











