






目录
一、朴素贝叶斯原理
1、简单解释
贝叶斯分类算法是统计学中的一种概率分类方法,朴素贝叶斯分类是贝叶斯分类中最简单的一种。其分类原理就是利用贝叶斯公式根据某特征的先验概率计算出其后验概率,然后选择具有最大后验概率作为该特征所属的类。朴素贝叶斯 (Naive Bayes) 是贝叶斯分类算法中最简单的一个,一般用于处理二分类或多分类任务。该算法围绕着一个核心进行展开:贝叶斯定理。
之所以称之为“朴素”,是因为贝叶斯分类只做最原始、最简单的假设:所有的特征之间是相对独立的。
2、算法核心
(1)条件概率与全概率公式
对于事件A与事件B, 有条件概率公式:
因为 P(AB) = P(BA) , 所以:
将 P(A) 除到左边,得到:
对于全概率公式,如果事件{}构成一个完备事件且都有正概率,那么对于任意一个事件B有:
所以有:
(2)朴素贝叶斯推断
根据条件概率和全概率公式,可以得到贝叶斯公式如下:
P(A) 称为先验概率(prior probability),即在B事件发生之前,我们对A事件概率的一个判断;
P(A∣B) 称为后验概率(posterior probability),即在B事件发生之后,我们对A事件概率的重新评估;
P(B∣A)/P(B) 称为可能性函数(Likely hood),这是一个调整因子,使得预估概率更接近真实概率。
3、朴素贝叶斯算法优缺点
(1)优点
1、在数据较少的情况下仍然有效,可以处理多类别问题。
2、对缺失数据不太敏感,算法也比较简单,常用于文本分类。
(2)缺点
1、对于输入数据的准备方式较为敏感。
2、需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候,会由于假设的先验模型的原因导致预测效果不佳。
(3)适用数据类型
标称型数据
4、算法流程
(1)收集数据:可以使用任何方法。
(2)准备数据:需要数值型或者布尔型数据。
(3)分析数据:有大量特征时,绘制特征作用不大,此时使用直方图效果更好。
(4)训练算法:计算不同的独立特征的条件概率。
(5)测试算法:计算错误率。
(6)使用算法:一个常见的朴素贝叶斯应用是文档分类。可以在任意的分类场景中使用朴
素贝叶斯分类器,不一定非要是文本。
二、数据集及代码实现
1、数据集
西瓜数据集(点击可下载)
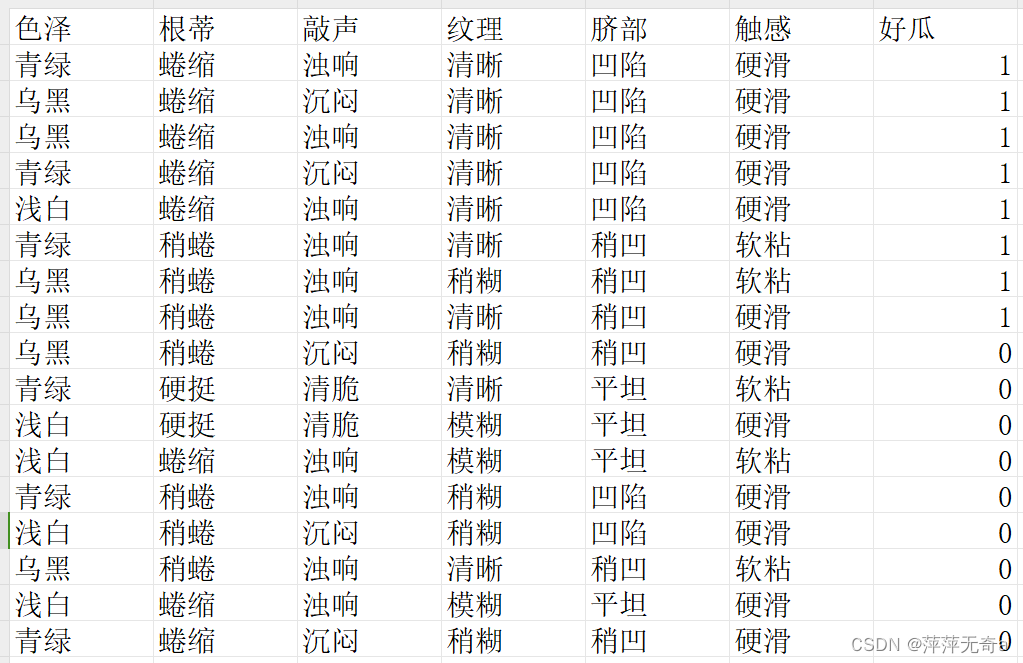
2、代码实现
根据贝叶斯公式
有:

(1)计算先验概率
首先计算好瓜,坏瓜概率;
即P(类别):P(好瓜)、P(坏瓜)
代码:
# 计算先验概率
def P_B(data):
label = data.iloc[:,-1]
g_melon = 0
b_melon = 0
for i in label:
if i == 1:
g_melon += 1
else:
b_melon += 1
return {1:g_melon/len(label) , 0:b_melon/len(label)}输出结果:

(2)计算条件概率
然后计算在好瓜和坏瓜的条件下,各特征发生的概率;
即P(特征|类别):
P(浅白|好瓜)、P(乌黑|好瓜)、P(青绿|好瓜)、P(稍蜷|好瓜)、P(硬挺|好瓜)、P(蜷缩|好瓜)、P(清脆|好瓜)、P(浊响|好瓜)、P(沉闷|好瓜)、P(稍糊|好瓜)、P(清晰|好瓜)、P(模糊|好瓜)、P(稍凹|好瓜)、P(平坦|好瓜)、P(凹陷|好瓜)、P(软粘|好瓜)、P(硬滑|好瓜)
P(浅白|坏瓜)、P(乌黑|坏瓜)、P(青绿|坏瓜)、P(稍蜷|坏瓜)、P(硬挺|坏瓜)、P(蜷缩|坏瓜)、P(清脆|坏瓜)、P(浊响|坏瓜)、P(沉闷|坏瓜)、P(稍糊|坏瓜)、P(清晰|坏瓜)、P(模糊|坏瓜)、P(稍凹|坏瓜)、P(平坦|坏瓜)、P(凹陷|坏瓜)、P(软粘|坏瓜)、P(硬滑|坏瓜)
代码:
#计算条件概率
def P_C(data):
c_p = {}
for i in range(len(data.columns) - 1): #舍去最后一行(标签)
c_p[i] = {}
for value in set(data.iloc[:, i]):
c_p[i][value] = {}
for label in [1, 0]:
count = sum([1 for index, item in data.iterrows() if item[i] == value and item[-1] == label])
c_p[i][value][label] = count / sum([1 for index, item in data.iterrows() if item[-1] == label])
return c_p结果截图:

(3)计算后验概率
计算各特征之和下,瓜是好瓜还是坏瓜;
即P(类别|特征),后验概率;
例如:
#计算后验概率(贝叶斯分类器)
def Bayes(features, prior, c_p):
pro = {}
for label in [1, 0]:
pro[label] = prior[label]
for i, feature in enumerate(features):
pro[label] *= c_p[i][feature][label]
return max(pro, key=pro.get)(4)实验测试
随机生成西瓜特征以进行判断西瓜的类别
def create_MarriageData():
p0=['青绿','乌黑','浅白']
p1=['蜷缩','稍蜷','硬挺']
p2=['浊响','沉闷','清脆']
p3=['清晰','稍糊','模糊']
p4=['凹陷','稍凹','平坦']
p5=['硬滑','软粘']
dataset = []#创建样本
dataset.append(random.choice(p0))#每个样本随机选择
dataset.append(random.choice(p1))#同理,随机选择
dataset.append(random.choice(p2))#同理
dataset.append(random.choice(p3))#同理
dataset.append(random.choice(p4))#同理
dataset.append(random.choice(p5))#同理
print("随机产生西瓜为:",dataset)
return dataset测试代码:
#单例测试
test_data = ['青绿', '稍蜷', '浊响', '清晰', '凹陷', '软粘']
result = Bayes(test_data, prior, c_p)
print(test_data,"分类结果:", result)
#随机测试
for i in range(1,5):
print('测试结果:', Bayes(create_MarriageData(),prior, c_p))结果截图:
- 单例测试:

- 随机测试:

三、实验总结
1、总结学习
1、 本次实验为西瓜的好瓜坏瓜分类,从条件概率的格式推演到csv文件分类的基本实现,再到最终的好瓜坏瓜分类,做了一系列的操作。利用朴素贝叶斯来进行的好处就是,朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率,并且算法也比较简单,容易实现,对于小规模的数据效果很不错。
2、通过此次实验,对朴素贝叶斯算法的整体流程以及原理有了更加深刻的理解,并且能进行简单的应用。
3、朴素贝叶斯算法易于理解,操作简单。
2、遇到的问题
- 怎么样才能一次性测试多个不同特征的西瓜是好瓜还是坏瓜。
解决:通过学习其他博主的博客以及python随机数生成的函数来实现以此测试多个西瓜是好瓜还是坏瓜。
















 1688
1688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











