







想要获得一个城市的历史天气,可以在天气后报网站上查询获得
如果要通过大量历史天气数据做分析,可以通过爬虫的方式获得。
网站:天气,天气预报查询,24小时,今天,明天,未来一周7天,10天,15天,40天查询_2345天气预报
可以查看到某个城市的历史天气信息如下图所示:
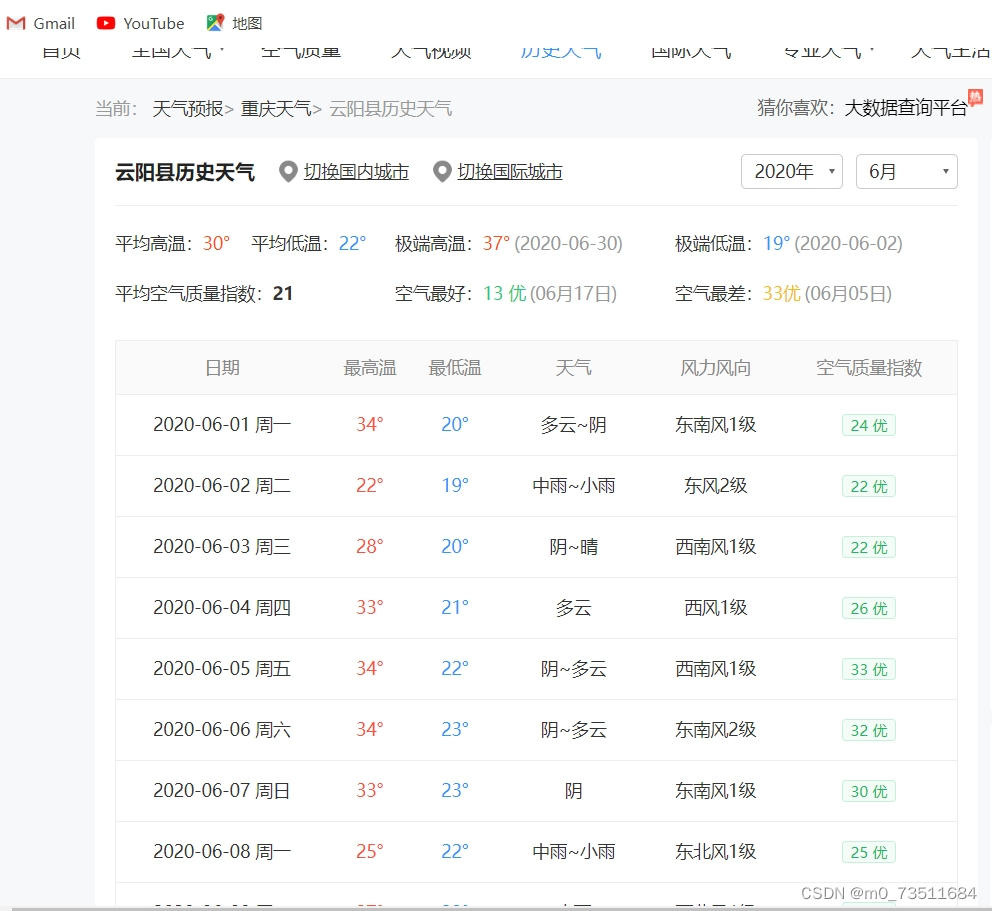
上图就是我们要爬取的网页以及数据
这里切换年份和月份,网站的url是不会改变的,表明该网页是后台异步加载,需要进行抓包分析,点击检查点击network来到下图所示:
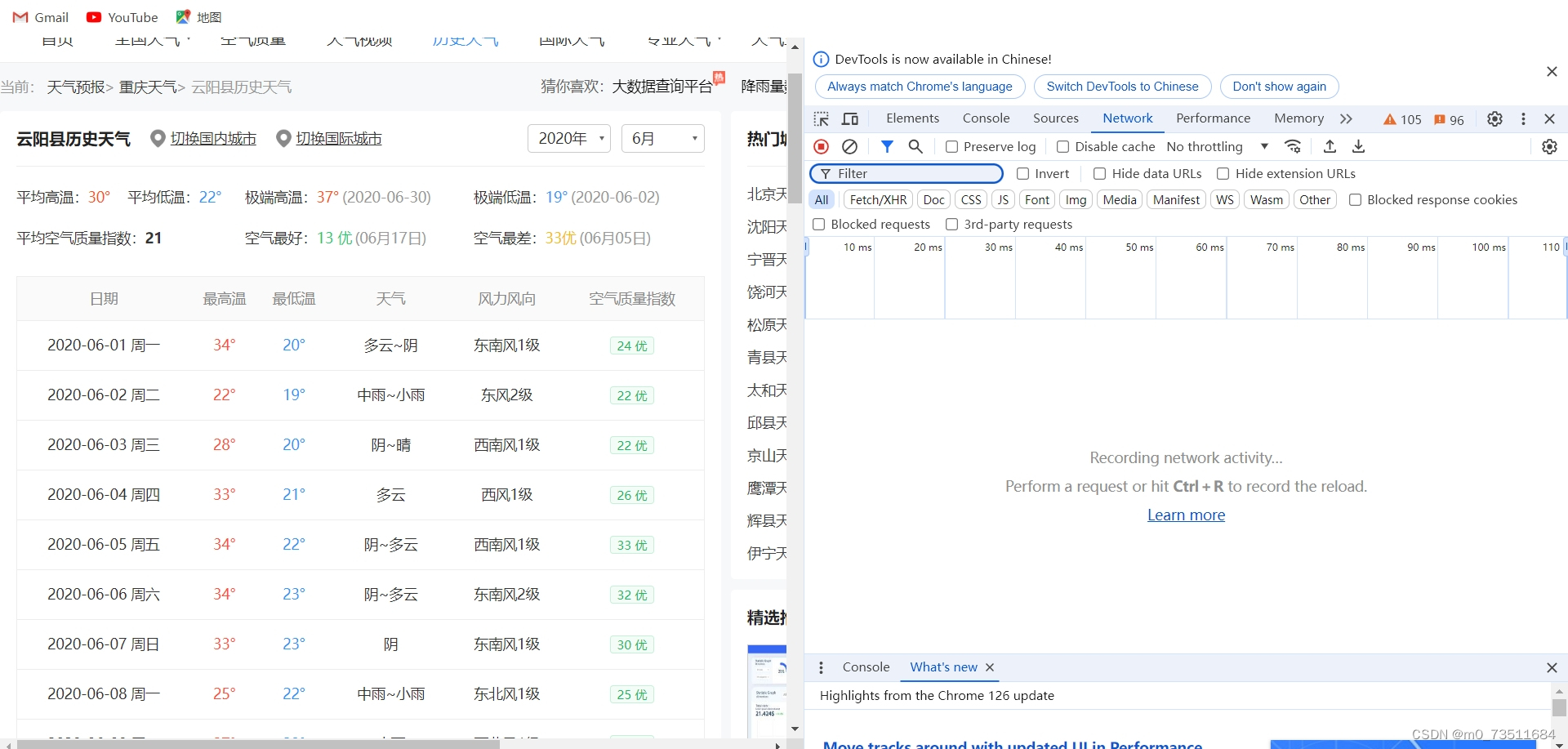
先不要刷新网页我们切换年份和月份试试:
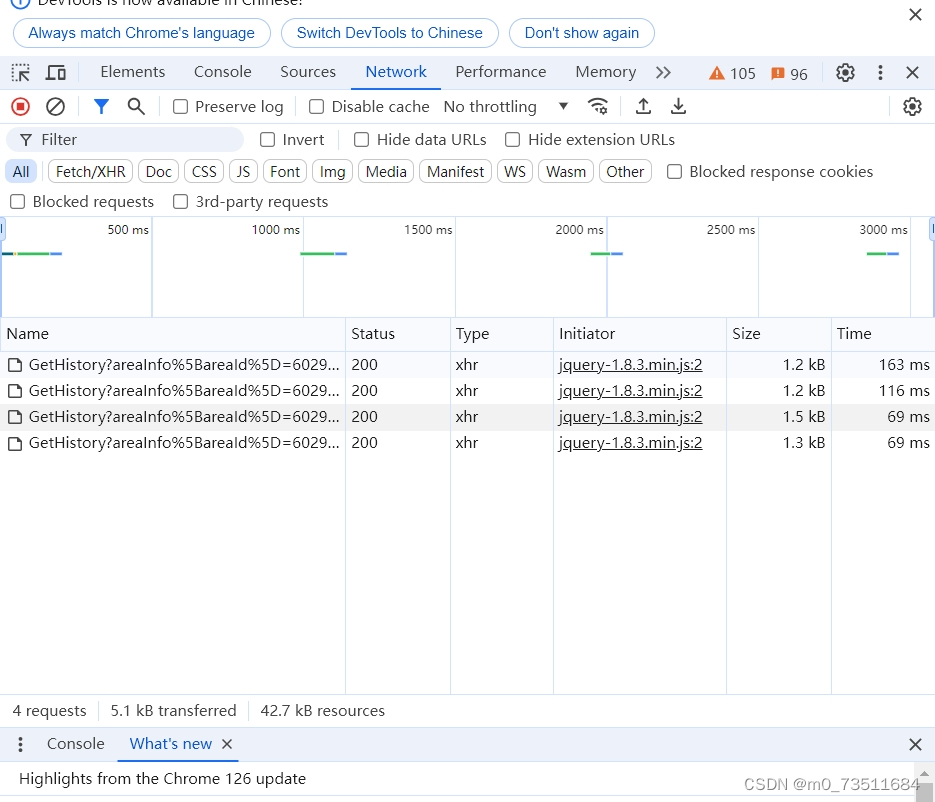
此时可以看到 多了几行,随便点开一个查看即可:
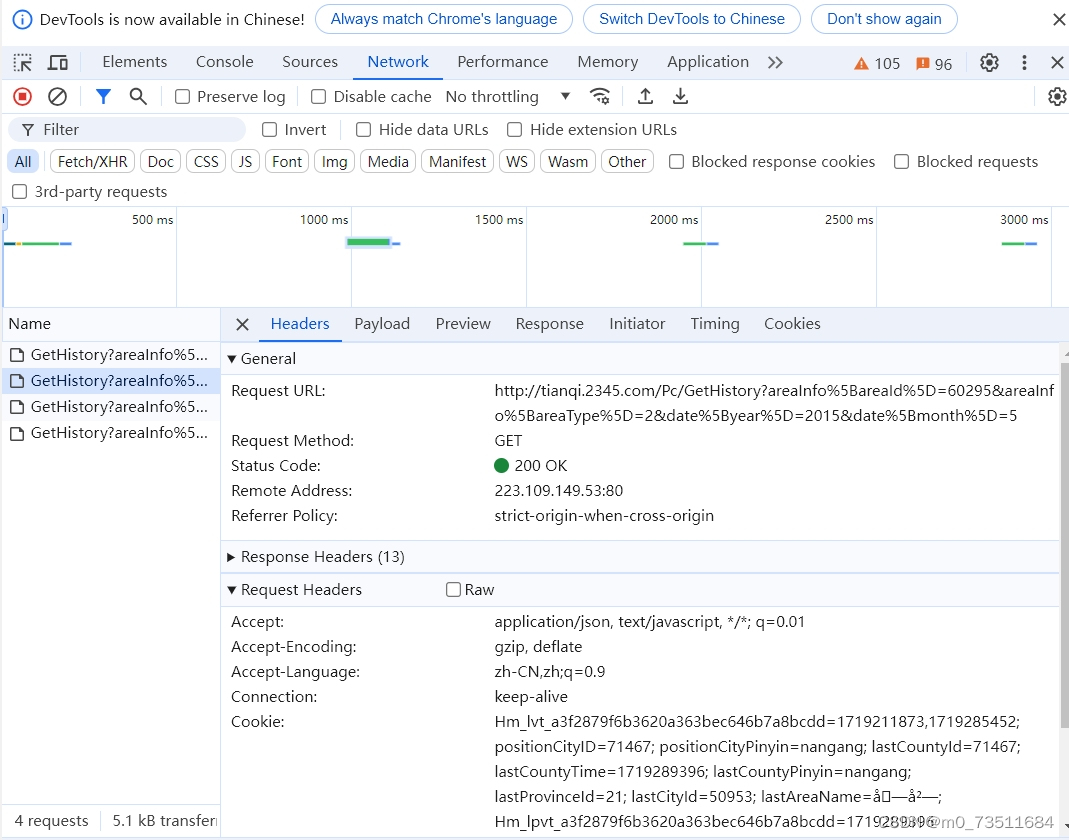
由于是非静态网页,爬取的时候需要设置
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1403
1403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









