






url="斗罗大陆III龙王传说最新章节_斗罗大陆III龙王传说免费全文阅读_89文学"
一样我们还是进入网页之后点击检查来查看一下网页:
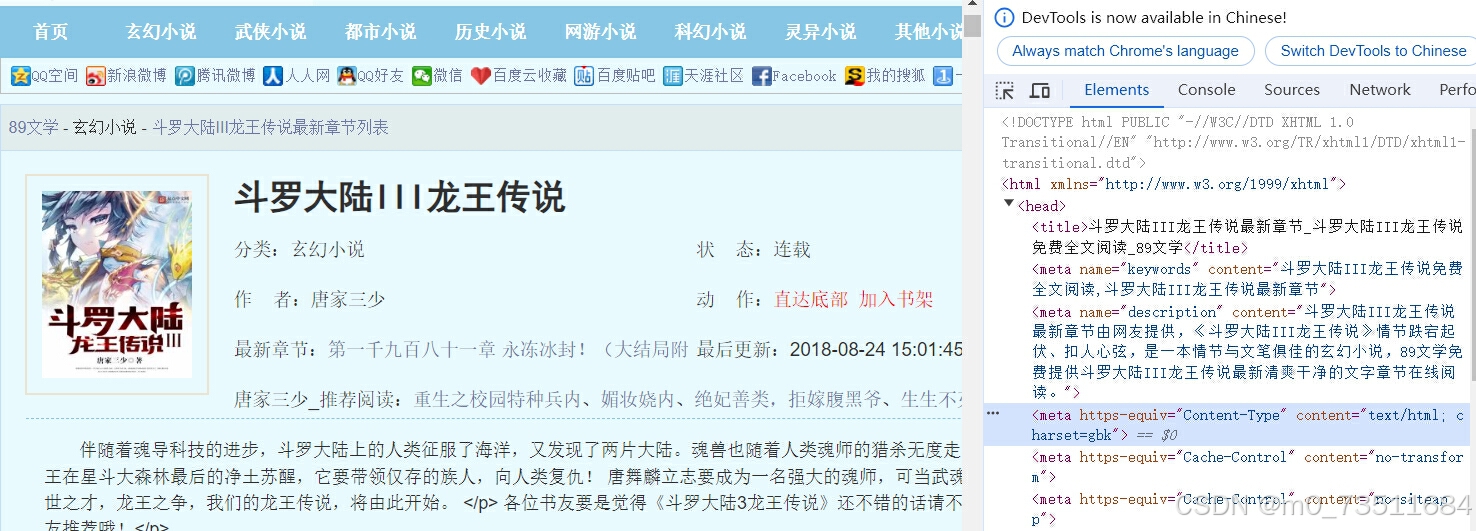
这里我们可以看到网页的编码方式是"gbk" ,所以发送请求之后需要手动设置一下编码方式,先来来尝试向网站发送请求试试:
root_url = "http://www.89wx.cc/9/9881/"
response = requests.get(root_url)
print(response)
返回值是200表示请求成功此时我们就可以拿到网页的html代码了:
接下来我们设计两个函数做两件事情:
1.在这里我们获取所有章节的标题和URL
2.在获取到所有的url之后爬取正文内容
先做第一件事情来分析如何拿到所有章节的url和标题:
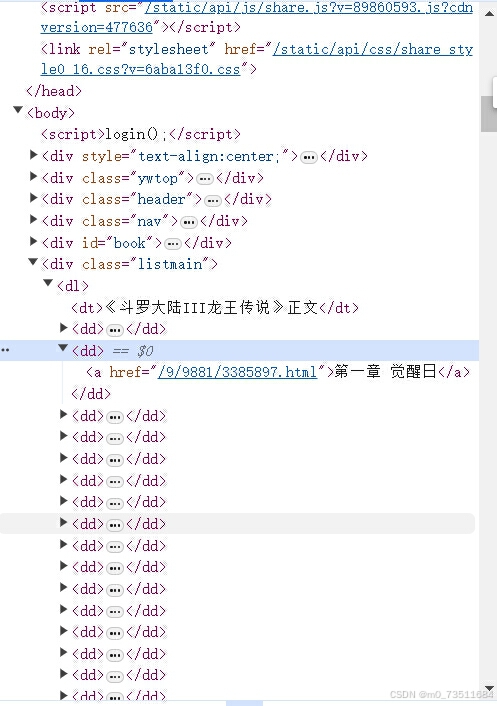
可以看到每个章节的url和标题都是存在<dd>.....<dd>之间的经过测试我们直接找所有的这样格式的数据就可以拿到所有的url和标题:
import requests
from bs4 import BeautifulSoup
root_url = "http://www.89wx.cc/9/9881/"
response = requests.get(root_url)
response.encoding = "gbk"
data = []
soup = BeautifulSoup(response.text, "html.parser")
for dd in soup.find_all("dd"):
link = dd.find("a")
if not link:
continue
href = link.get("href")
title = link.get_text()
data.append(("http://www.89wx.cc%s" % href, title))
print(data)
这里拿到的结果是一个元组列表,列表里的每个元组是拼接好的url以及标题对。
现在我们进行第二步就是从这些章节的url中采集所有的文本内容了:
来看看某个章节的文本内容
这里我们可以看到文本内容所在的位置,先用bs4这个库来试试能不能提取到这些文字:

此时可以看到我们只提取到了文本最后一句话的内容,我们暂时认为是bs4这个库的问题,因为我们多个人都尝试的这种方法去取但是返回的结果都是最后一句话,所以我换了一种方式来获取文本,采用的是正则匹配的方式来获取文本内容(有个比正则更好用的方式就是使用X_path来取文本呢内容),注意这个小说的每一章节只有一页所以我可以很快的拿到每一章节的内容,有多页的目前还没有解决这个问题,后续有待开发:
y

采用正则之后也是成功拿下来了所有的文本,这里做一个小处理用字符串分割将其处理成一个列表在输入的时候我们就能使其更美观一些:
import re
import requests
root_url = "http://www.89wx.cc/9/9881/3385897.html"
response = requests.get(root_url)
response.encoding = "gbk"
content = re.findall('<div id="content" class="showtxt">(.*?)</div>', response.text, re.S)
content = str(content)
content = content.replace(" ", "").replace("<br />", "").replace("['",
"").replace(
"']", "")
old_content = content.split(r"\r")
new_content = []
for content in old_content:
if content == "":
continue
new_content.append(content)到这里我们两个函数就已经做好了,接下来封装调用就完事了:
import re
import requests
from bs4 import BeautifulSoup
from lxml import etree
def get_novel_url():
root_url = "http://www.89wx.cc/9/9881/"
response = requests.get(root_url)
response.encoding = "gbk"
data = []
soup = BeautifulSoup(response.text, "html.parser")
for dd in soup.find_all("dd"):
link = dd.find("a")
if not link:
continue
href = link.get("href")
title = link.get_text()
data.append(("http://www.89wx.cc%s" % href, title))
return data
def get_chapter_content(url):
response = requests.get(url)
# 正则实现
# response.encoding = "gbk"
# content = re.findall('<div id="content" class="showtxt">(.*?)</div>', response.text, re.S)
# content = str(content)
# content = content.replace(" ", "").replace("<br />", "").replace("['",
# "").replace(
# "']", "")
# old_content = content.split(r"\r")
# new_content = []
# for content in old_content:
# if content == "":
# continue
# new_content.append(content)
# return new_content
# X_path实现:
html = response.content.decode("gbk")
tree = etree.HTML(html)
contents = tree.xpath('//*[@id="content"]//text()')
return contents
novel_chapters = get_novel_url()
total_cnt = len(novel_chapters)
idx = 0
for chapter in novel_chapters:
print(idx,total_cnt)
url, title = chapter
with open("output/%s%s.txt" % (idx,title), "w", encoding="utf-8") as fout:
# 正则实现的输入
# for content in get_chapter_content(url):
# fout.write(content + "\n")
# X_path实现的输入
for content in get_chapter_content(url):
content = str(content).replace(r" ", "") # 这里有一段比较特殊的字符串并不是多个空格
fout.write(content)
idx += 1total_cnt = len(novel_chapters)这里计算了一下这本书有多少个章节,然后设置一个参数用来标记爬取到第几章了:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









