






一次简单的图片爬取;
1.爬取的网站:4K美女壁纸_高清4K美女图片大全_彼岸图网
2.查看网页源代码:
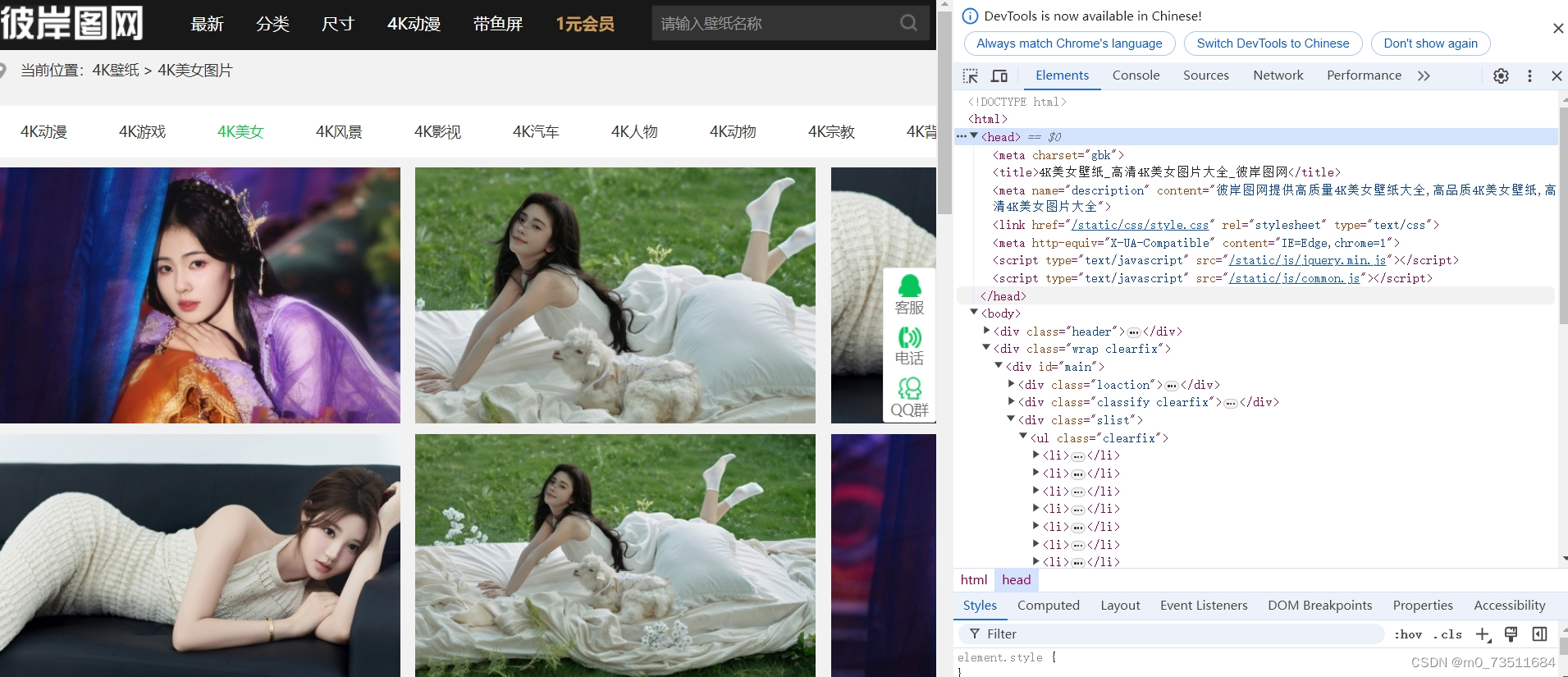
注意查看head里面的信息,这里的编码方式是"gbk",获取网页的html时要设置编码方式来简单尝试请求一下该网站看看是否需要进行伪装:
root_url = "https://pic.netbian.com/4kmeinv/"
response = requests.get(root_url)
print(response.status_code)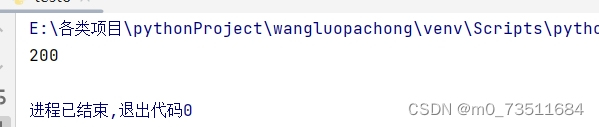
返回值是200表示请求成功我们不需要做伪装,接下来就是拿到并解析html代码,获取图片的下载地址:
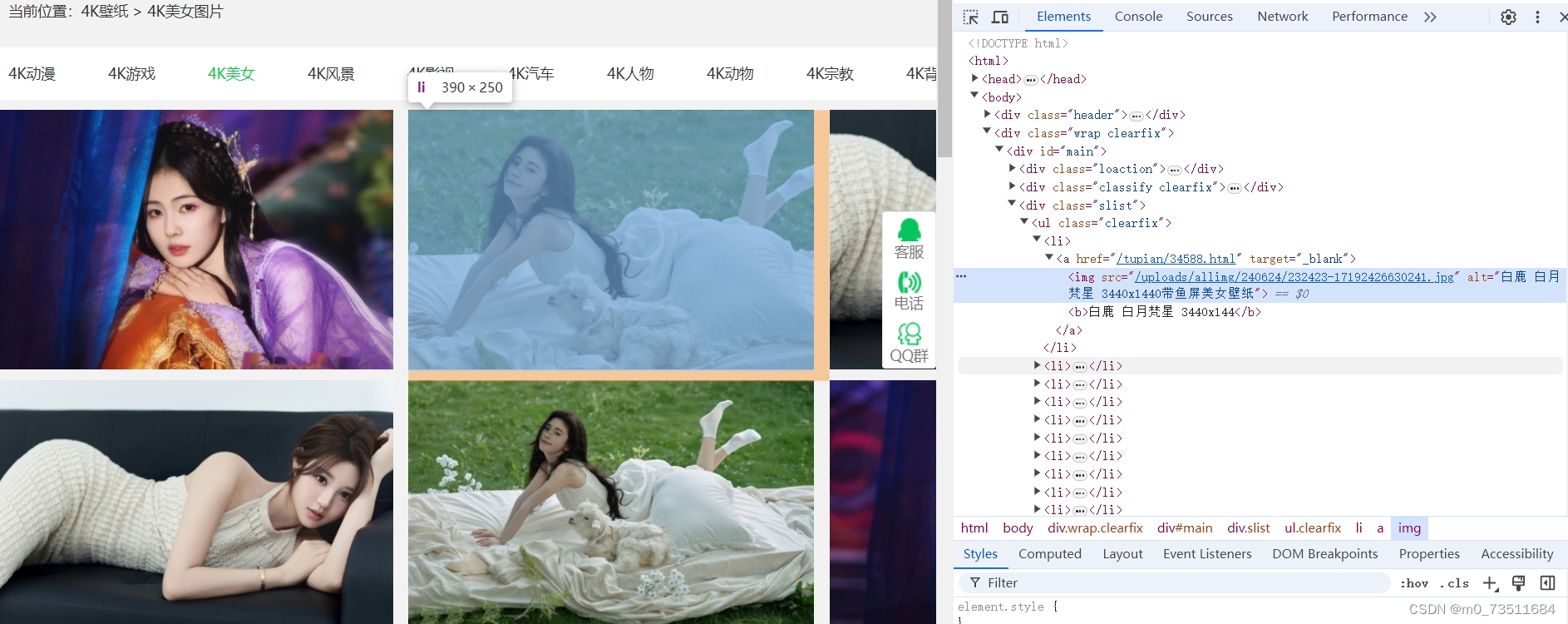
此时我们可以看到图片的下载地址都在<li><li>之间这次使用一个更简单的方法来获取目标数据:
html = response.content.decode("gbk")
tree = etree.HTML(html)
imgs = tree.xpath('//*[@id="main"]/div[3]/ul/li/a/img/@src')
for img in imgs:
print(img) 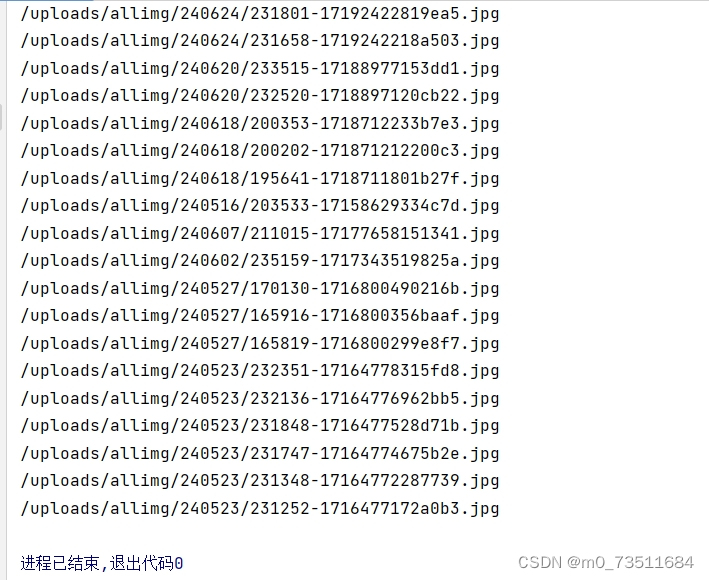
可以看到我们已经成功 拿到下载地址了,之后请求下载的时候讲域名拼接上就好.
import requests
from lxml import etree
import os
root_url = "https://pic.netbian.com/4kmeinv/"
url_list = []
# 制作10页的url
for i in range(1, 11):
if i == 1:
url_list.append(root_url)
else:
url = f"https://pic.netbian.com/4kmeinv/index_{i}.html"
url_list.append(url)
i = 0
j = 0
for url in url_list:
j += 1
response = requests.get(url)
html = response.content.decode("gbk")
tree = etree.HTML(html)
imgs = tree.xpath('//*[@id="main"]/div[3]/ul/li/a/img/@src')
for img in imgs:
i += 1
img_url = "https://pic.netbian.com" + img
# 利用图片的下载地址,来设置图片的本地命名
filenmae = os.path.basename(img_url)
with open(f"imgoutput/{filenmae}", "wb") as f:
# 想要下载图片需要再次请求图片的url才可以下载到图片
response_img = requests.get(img_url)
# response_img.content得到的是二进制流
f.write(response_img.content)
print(f"第{j}页,第{i}张图片爬取完成")
i = 0
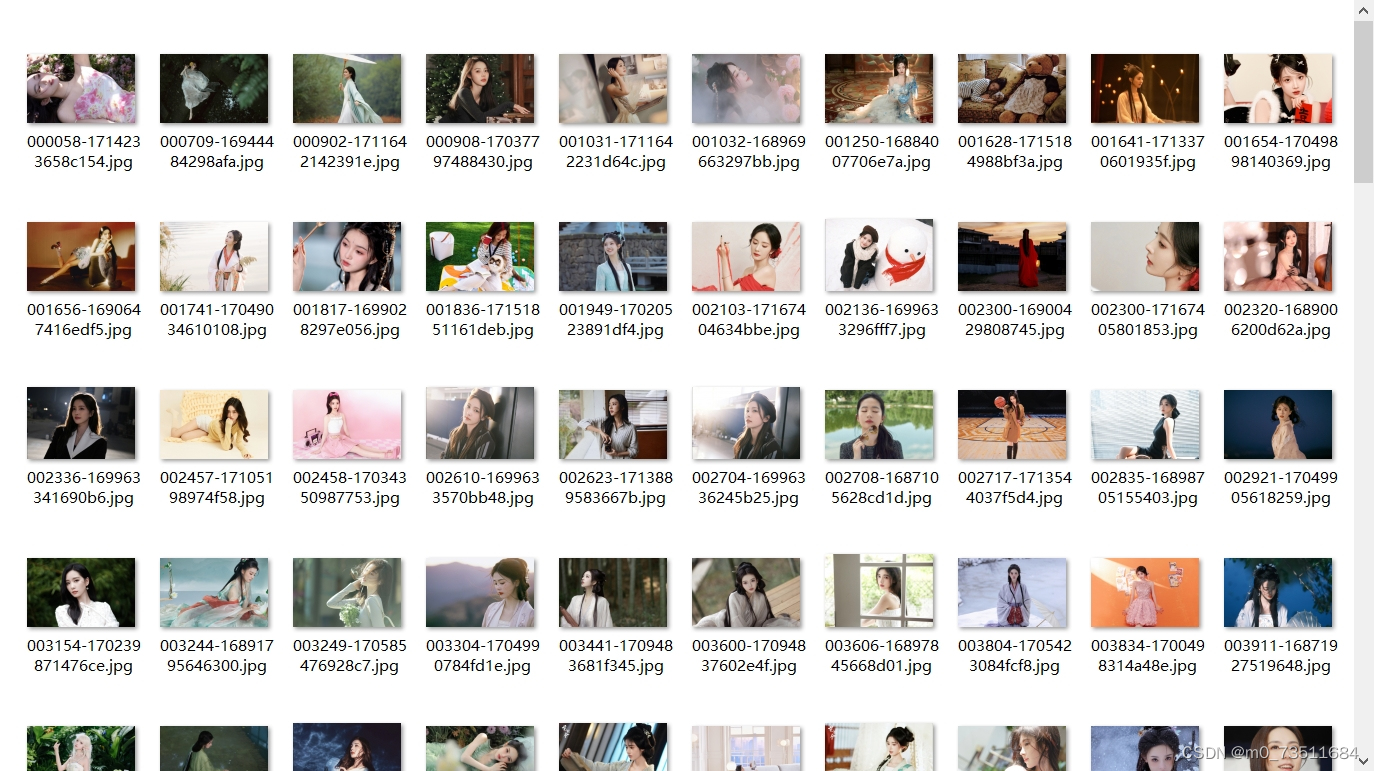
这里是爬取了10页的图片 ,有翻页的url自己制作一下就好,然后通过循环就可以搞定,也可以将其封装成函数调用。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









