







url = "https://maimai.cn/gossip_list"
本次爬取的目的是因为这个网站是需要登录之后才可以获得数据的,同时这个页面也是异步加载的,需要进行抓包分析。进入网站登录后看看:
找到我们要爬取的页面,看看network的情况往下刷几页:
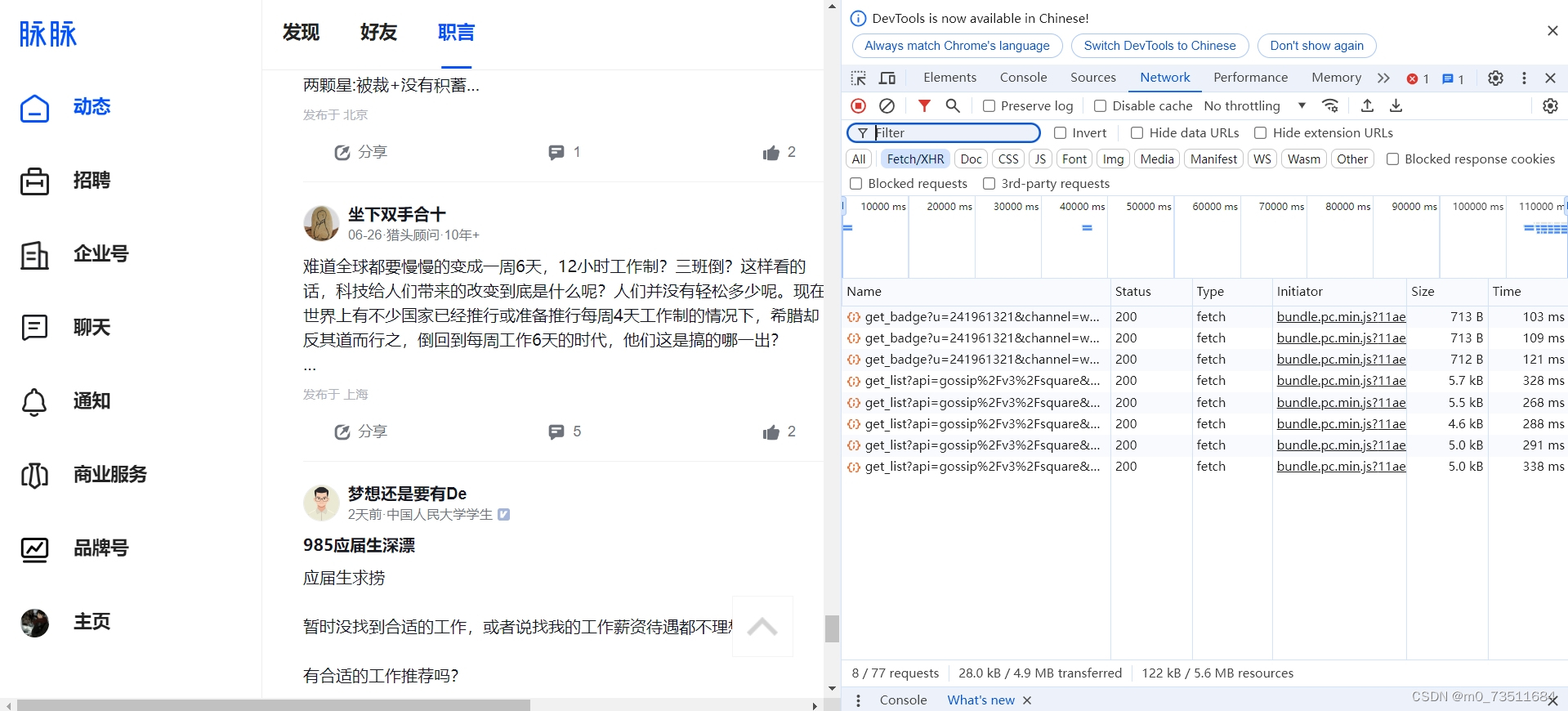
往下刷可以看到get_list会出现很多个
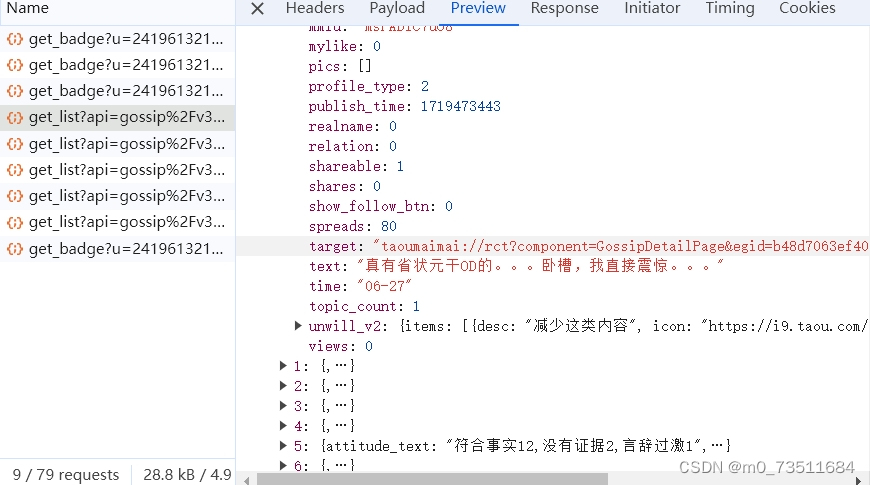
可以看到我们需要的数据放在一个json字典内,"text"内就是这些用户的职言 。这里需要做的伪装要多一些,还要设置params字典,用于爬取这种异步加载的网页。
import requests
def craw_page(page_number):
params = {
"api": "gossip/v3/square",
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









