






 本文介绍了分类模型评估的关键指标,如准确率、精确率、召回率和F1分数,以及ROC曲线和PR曲线的概念及其在不平衡数据集中的应用。通过实例演示如何在VScode中使用k-近邻分类器绘制不同k值下的ROC曲线,并探讨了k值对模型性能的影响。
本文介绍了分类模型评估的关键指标,如准确率、精确率、召回率和F1分数,以及ROC曲线和PR曲线的概念及其在不平衡数据集中的应用。通过实例演示如何在VScode中使用k-近邻分类器绘制不同k值下的ROC曲线,并探讨了k值对模型性能的影响。
一、掌握常见的分类模型评估指标
常见的分类模型评估指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 分数(F1 Score)、AUC(Area Under the Curve)等。
- 准确率(Accuracy):正确分类的样本数占总样本数的比例。
- 精确率(Precision):真正例(TP)占预测为正例(TP+FP)的比例。
- 召回率(Recall):真正例(TP)占实际为正例(TP+FN)的比例。
- F1 分数(F1 Score):精确率和召回率的调和平均值,用于综合考虑精确率和召回率。
这些指标可以通过混淆矩阵来计算。混淆矩阵是一个表格,展示了模型预测结果与实际结果的对比。
二、掌握ROC曲线和PR曲线
2.1ROC和PR概念
- ROC曲线(Receiver Operating Characteristic Curve):以假正例率(FPR)为横轴,真正例率(TPR)为纵轴绘制的曲线。ROC曲线下的面积(AUC)用于评估模型的性能。
- PR曲线(Precision-Recall Curve):以召回率为横轴,精确率为纵轴绘制的曲线。PR曲线常用于评估不平衡数据集上的模型性能。
2.2差异
- ROC曲线对正负样本的平衡性不敏感,而PR曲线对正负样本的平衡性很敏感。
- 当正负样本不平衡时,PR曲线更能反映模型的性能。
三、画出不同k值下的ROC曲线
3.1步骤
- 准备数据集:确保你有一个带有标签的二分类数据集。
- 训练模型:使用不同的k值训练多个模型,例如k-近邻(k-NN)分类器。
- 计算预测概率或得分:对每个模型,计算每个样本属于正类的预测概率或得分。
- 绘制ROC曲线:使用计算出的预测概率或得分,计算不同阈值下的真正例率(TPR)和假正例率(FPR),并绘制ROC曲线。
- 计算AUC:计算每个ROC曲线下的面积(AUC),以量化模型性能。
- 分析:比较不同k值下的ROC曲线和AUC值,分析k值对模型性能的影响。观察哪个k值下的模型表现最好,以及在不同k值下模型的稳定性和鲁棒性。
四、通过实验实现模型评估与性能度量(VS code编辑器)
4.1代码实现
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import roc_curve, auc, roc_auc_score
import matplotlib.pyplot as plt
# 加载数据集,这里以乳腺癌数据集为例
data = datasets.load_breast_cancer()
X = data.data
y = label_binarize(data.target, classes=[0, 1]) # 将标签二值化
n_classes = y.shape[1]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
# 定义要测试的k值
k_values = [1, 3, 5, 7, 9]
# 存储每个k值的ROC曲线数据
fpr_list = []
tpr_list = []
auc_list = []
# 对每个k值训练模型并计算ROC曲线
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
y_score = knn.predict_proba(X_test)[:, 1] # 获取正类的预测概率
fpr, tpr, thresholds = roc_curve(y_test.ravel(), y_score)
auc_value = auc(fpr, tpr)
fpr_list.append(fpr)
tpr_list.append(tpr)
auc_list.append(auc_value)
print(f'k={k}, AUC={auc_value:.2f}')
# 绘制ROC曲线
plt.figure(figsize=(10, 8))
for i, (fpr, tpr, auc_value) in enumerate(zip(fpr_list, tpr_list, auc_list)):
plt.plot(fpr, tpr, label=f'k={k_values[i]}, AUC={auc_value:.2f}')
# 绘制对角线
plt.plot([0, 1], [0, 1], 'k--')
# 设置标签和图例
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curves for Different k Values in k-NN')
plt.legend(loc='lower right')
# 显示图形
plt.show()
4.2实验结果截图
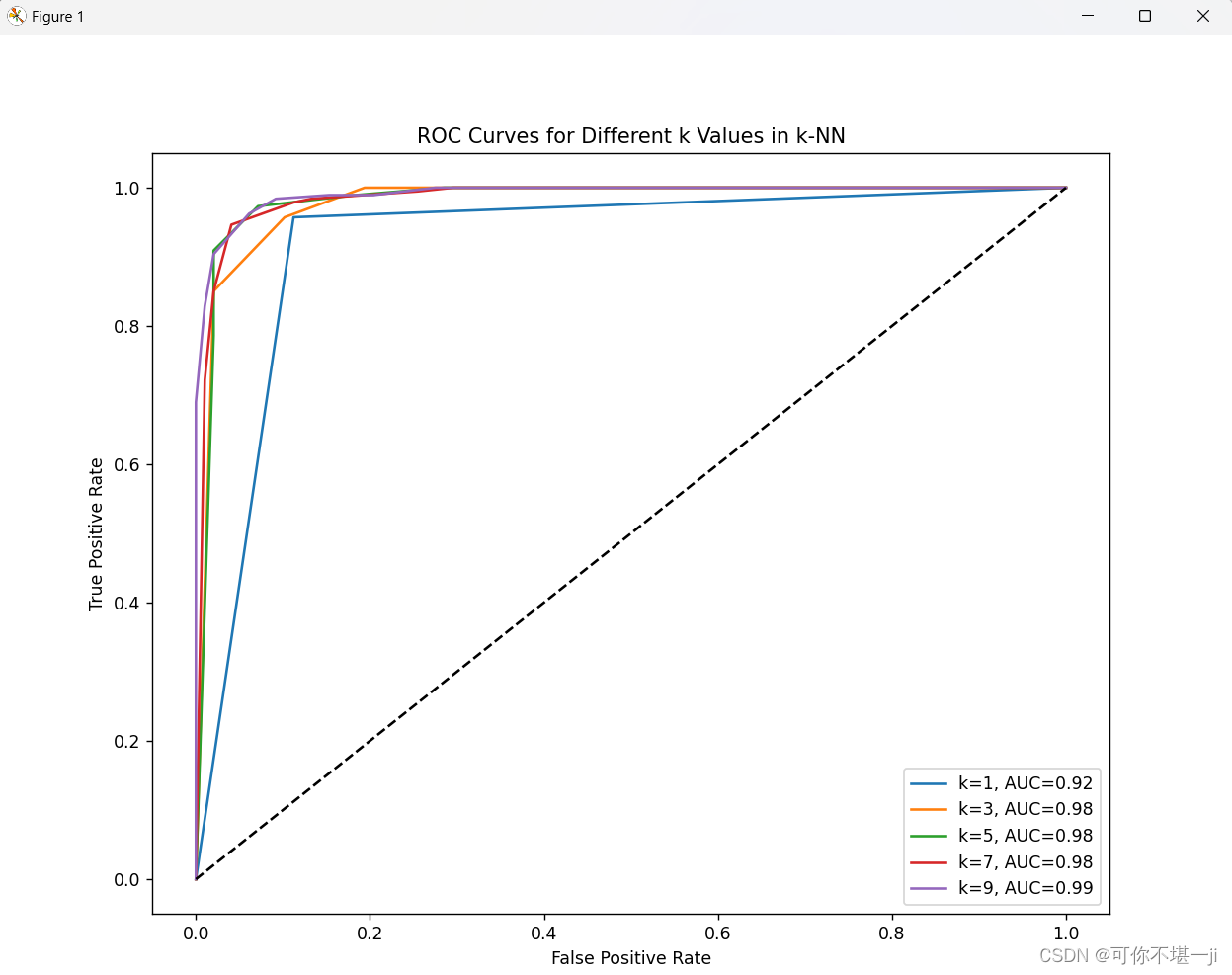
4.3实验小结
本实验的主要目的是掌握常见的分类模型评估指标,特别是ROC曲线和AUC值的应用与理解,并通过实际操作绘制不同k值下的ROC曲线,进而分析k值对k-近邻分类器性能的影响。
首先,通过学习和实践,我掌握了准确率、精确率、召回率以及F1分数等评估指标的计算方法,理解了这些指标在模型性能评估中的作用和限制。同时,我也深入了解了ROC曲线和AUC值的含义,明白了它们是如何通过综合考虑不同阈值下的真正例率和假正例率来评估模型的整体性能的。
其次,通过编写Python代码并使用scikit-learn库,我成功实现了不同k值下的k-近邻分类器的训练和评估。在这个过程中,我计算了每个模型的预测概率,并基于这些概率绘制了ROC曲线。通过观察这些曲线,我能够直观地比较不同k值下模型的性能差异。
最后,通过比较不同k值下的ROC曲线和AUC值,我发现k值的选择对k-近邻分类器的性能有显著影响。较小的k值可能导致模型过拟合,而较大的k值则可能导致模型欠拟合。因此,在实际应用中,需要通过交叉验证等方法选择合适的k值,以平衡模型的复杂度和泛化能力。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









