






目录
一、支持向量机
1.1定义
支持向量机(support vector machines,SVM)是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化。SVM的目标就是要找到这个超平面。
支持向量机思想直观,但细节复杂,涵盖凸优化,核函数,拉格朗日算子等理论。
1.2支持向量机类分类
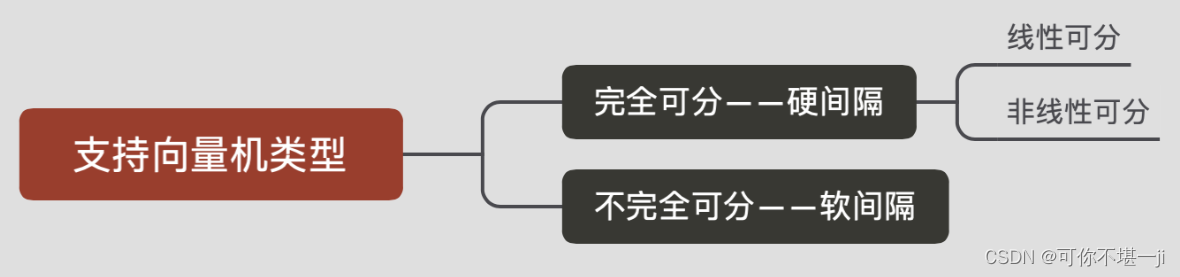
二、基本概念
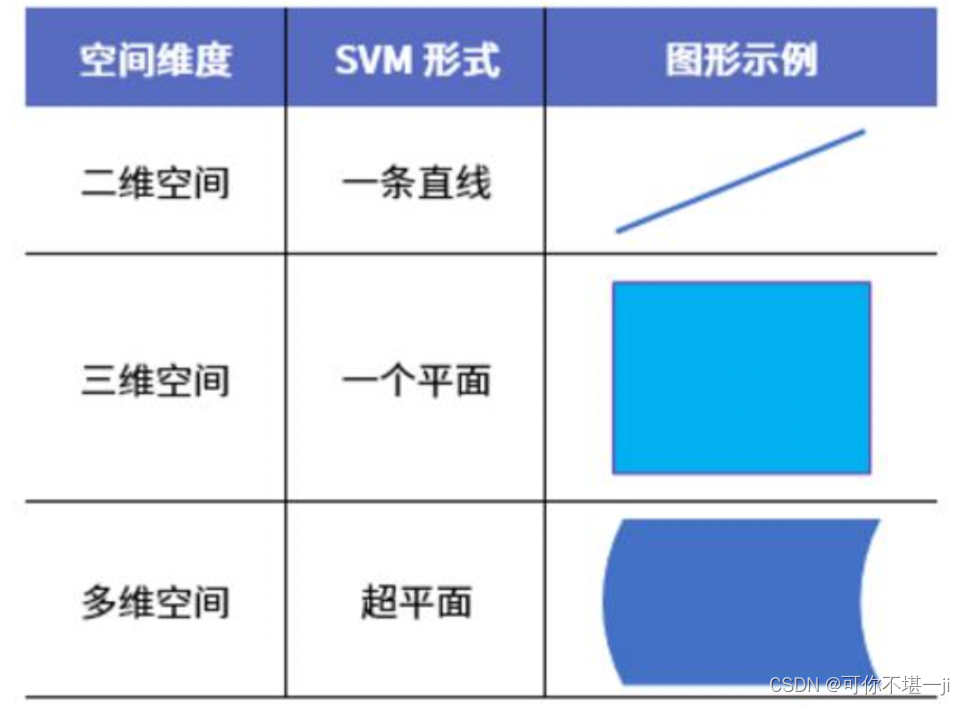
2.1线性可分
对于一个数据集合可以画一条直线将两组数据点分开,这样的数据称为线性可分(linearly separable)。如下图所示:
2.2分割超平面
将上述数据集分隔开来的直线成为分隔超平面。对于二维平面来说,分隔超平面就是一条直线。
2.3超平面
对于三维及三维以上的数据来说,分隔数据的是个平面,称为超平面,也就是分类的决策边界。
2.4点相对于分割面的间隔
点到分割面的距离,称为点相对于分割面的间隔。
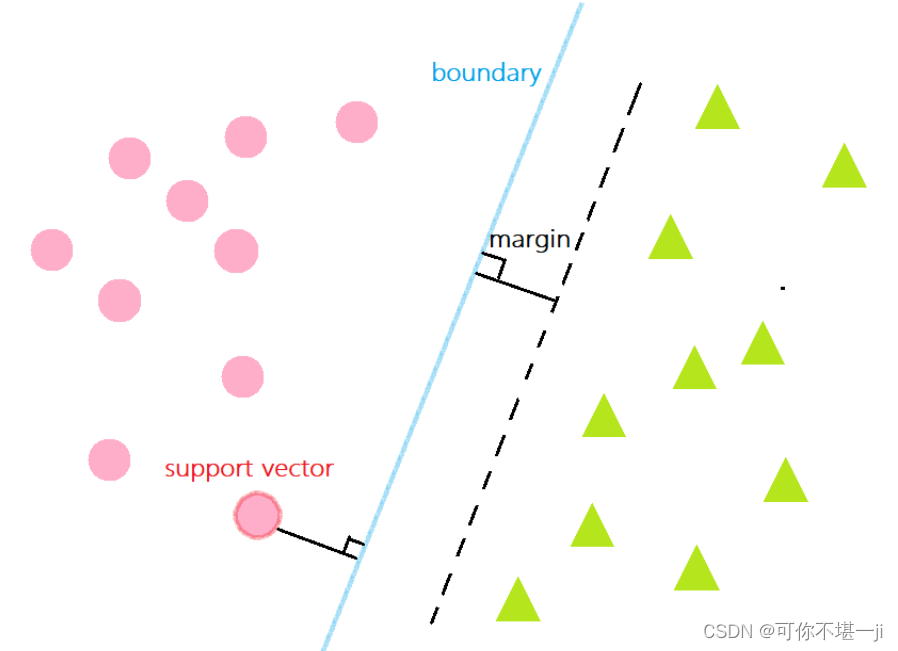
2.5间隔
数据集所有点到分隔面的最小间隔的2倍,称为分类器或数据集的间隔。论文中提到的间隔多指这个间隔。SVM分类器就是要找最大的数据集间隔。
2.6支持向量
离分隔超平面最近的那些点。
三、最大间隔
支持向量机的核心思想: 最大间隔化, 最不受到噪声的干扰。
3.1 分隔超平面
二维空间一条直线的方程为,y=ax+b,推广到n维空间,就变成了超平面方程,即,其中w是权重,b是截距,训练数据就是训练得到权重和截距。
3.2 如何决定最好的参数
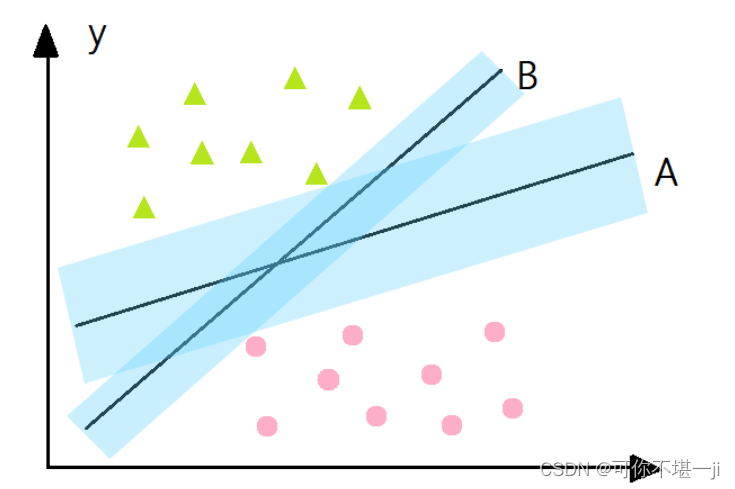
如下图所示,分类器A比分类器B的间隔(蓝色阴影)大。
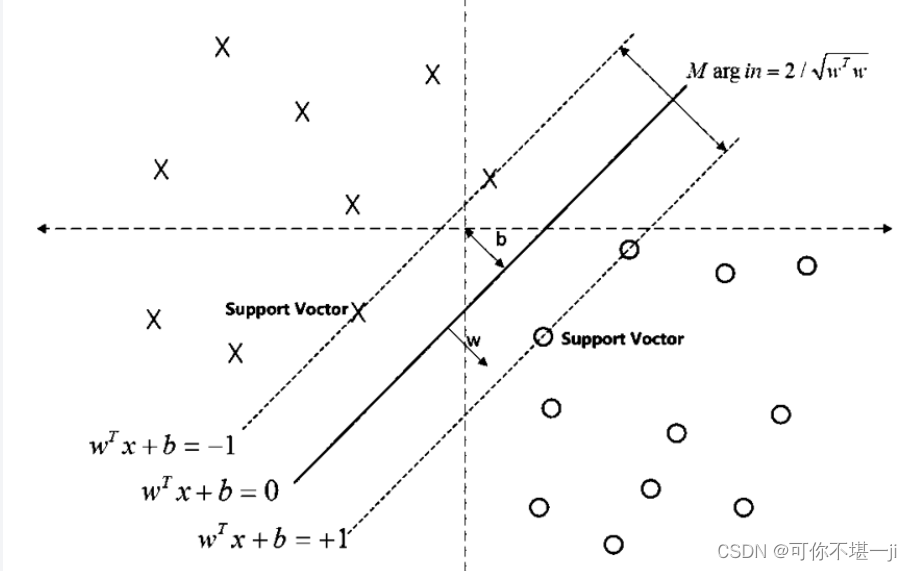
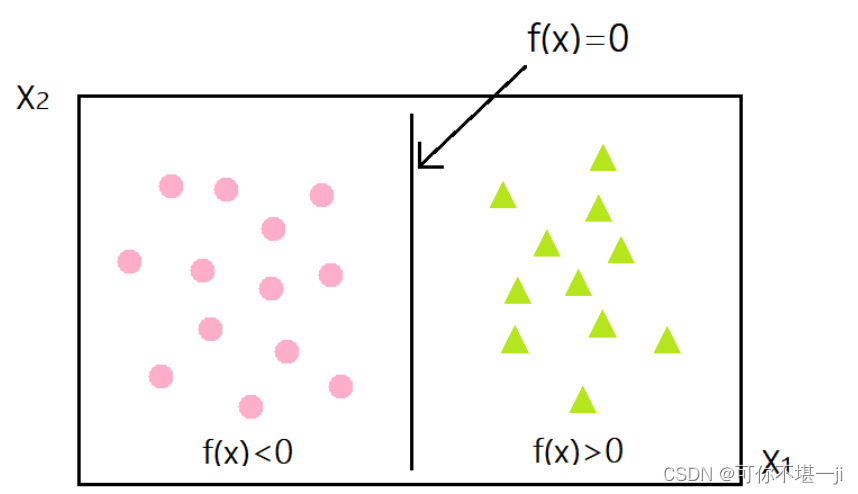
SVM划分的超平面:f(x) = 0,w为法向量,决定超平面方向,
假设超平面将样本正确划分
f(x) ≥ 1,y = +1
f(x) ≤ −1,y = −1
间隔:d=2/|w|


上式就是求解最大间隔超平面的表达式。
3.3 正则化与软间隔
针对样本不是完全能够划分开的情况,可以允许支持向量机在一些样本上出错,为此要引入“软间隔”的概念。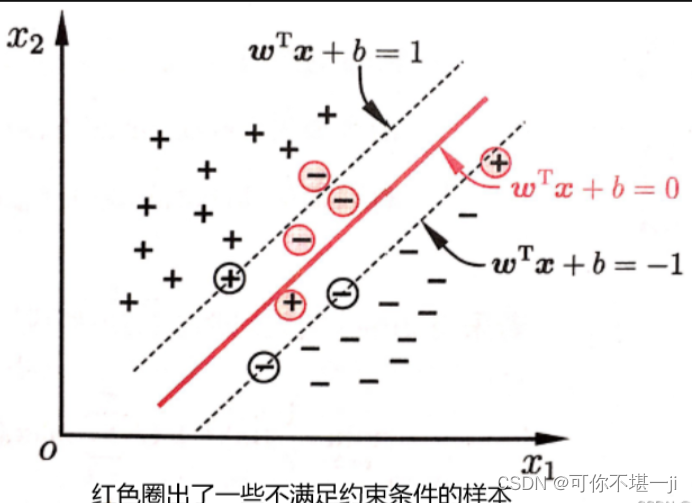
引入正则化强度参数C(正则化:在一定程度上抑制过拟合,使模型获得抗噪声能力,提升模型对未知样本的预测性能的手段),损失函数重新定义为:
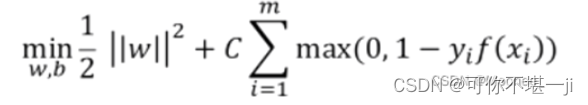
上式为采用hinge损失的形式,再引入松弛变量ξi≥0,重写为:
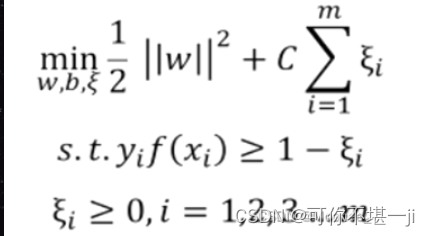
支持向量:
由此可以看出,软间隔支持向量机的最终模型仅与支持向量有关,即通过采用hinge损失函数仍保持了稀疏特性。
四、SVM算法实现
4.1分类器实现
定义一个名为LinearSVM的类,用于实现线性支持向量机算法。其中包含类的初始化方法、fit方法和predict方法。
class LinearSVM:
def __init__(self,learning_rate=0.0001,lambda_param=0.1,n_iters=1000):
self.learning_rate=learning_rate#学习率
self.lambda_param=lambda_param#正则化参数
self.n_iters=n_iters#迭代次数
self.w=None
self.b=None
def fit(self,X,y):#fit方法用于模型训练
n_samples,n_features=X.shape
y_ =np.where(y<=0,-1,1)
#初始化权重和偏置为0
self.w=np.zeros(n_features)
self.b=0
for _ in range(self.n_iters):
for idx,x_i in enumerate(X):
condition = y_[idx]*(np.dot(x_i,self.w)-self.b)>=1 #遍历每个样本,检查分类条件
if condition:
self.w-=self.learning_rate*(2*self.lambda_param*self.w)#如果样本被正确分类且在正确的间隔外,仅通过正则项更行权重(防止过拟合)
else:
self.w-=self.learning_rate*(2*self.lambda_param*self.w-np.dot(x_i,y_[idx]))#样本被错误分类或者在间隔内,则权重更新包括误差项,同时更新偏置,使样本在未来被正确分类
self.b-=self.learning_rate*y_[idx]
def predict(self,X):
Linear_output=np.dot(X,self.w)-self.b
return np.sign(Linear_output)4.2结果可视化
定义一个名为plot_hyperplane的函数,用于绘制数据集和分类超平面。首先绘制散点图,然后获取坐标轴的范围,生成网格点,计算网格点的Z值,最后绘制等高线。
#结果可视化
def plot_hyperplane(X,y,w,b):
plt.scatter(X[:,0],X[:,1],marker='o',c=y,s=100,edgecolors='k',cmap='winter')
ax=plt.gca()
xlim=ax.get_xlim()
ylim=ax.get_ylim()
xx=np.linspace(xlim[0],xlim[1],30)
yy=np.linspace(ylim[0],ylim[1],30)
YY,XX=np.meshgrid(yy,xx)
xy=np.vstack([XX.ravel(),YY.ravel()]).T
Z=(np.dot(xy,w)-b).reshape(XX.shape)
ax.contour(XX,YY,Z,colors='k',levels=[-1,0,1],alpha=0.5,linestyles=['--','-','--'])
plt.show()4.3 数据准备和模型训练
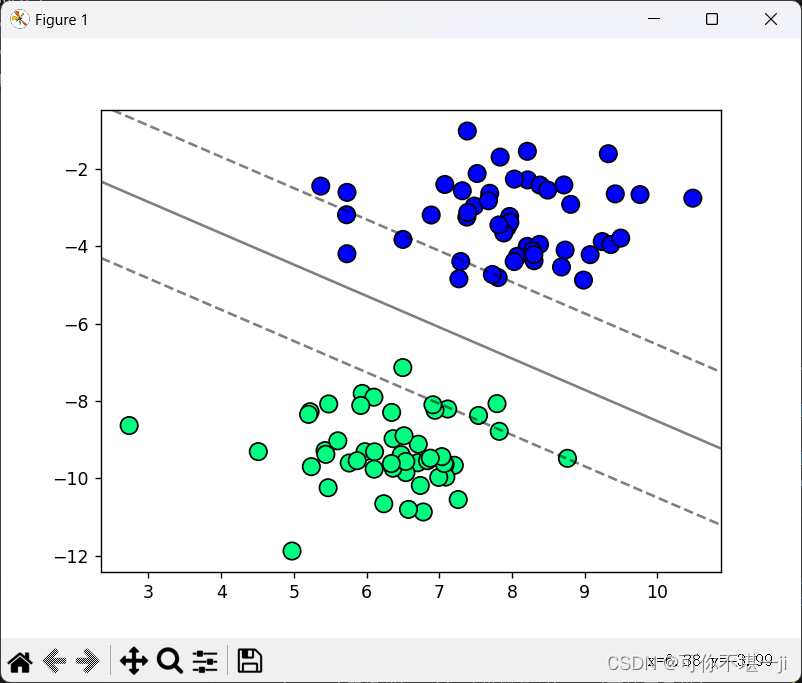
使用sklearn.datasets模块中的make_blobs函数,生成一个数据集,该数据集包含100个样本且围绕2个中心点聚集。接着,将数据集的标签y修改为-1和1,以符合我们的分类需求。之后,我们创建一个LinearSVM分类器的实例,调用fit方法,并使用生成的数据集对其进行训练。训练完成后,我们将调用plot_hyperplane函数,以便直观地展示训练后的分类器如何将数据空间划分为不同的类别。
#数据准备和模型训练
X,y=datasets.make_blobs(n_samples=100,centers=2,random_state=6)
y=np.where(y==0,-1,1)#调整标签为-1和1
svm0=LinearSVM()
svm0.fit(X,y)
plot_hyperplane(X,y,svm0.w,svm0.b) # type: ignore4.4 运行结果图
4.5 调整参数C优化分类结果
当C比较小时,模型对错误分类的惩罚较小,比较松弛,样本点之间的间隔就比较大,可能产生欠拟合的情况。
当C比较大时,模型对错误分类的惩罚较大,两组数据之间的间隔就小,容易产生过拟合的情况。
总之,C值越大,越不容易放弃那些离群点;C值越小,越不重视那些离群点。
#调整C参数看不同的效果
class LinearSVM1:
def __init__(self,C=1.0,learning_rate=0.0001,n_iters=1000):
self.C=C
self.learning_rate=learning_rate
self.n_iters=n_iters
self.w=None
self.b=None
def fit(self,X,y):
n_samples,n_features=X.shape
y_ =np.where(y<=0,-1,1)
#初始化权重和偏置为0
self.w=np.zeros(n_features)
self.b=0
for _ in range(self.n_iters):
for idx,x_i in enumerate(X):
condition = y_[idx]*(np.dot(x_i,self.w)-self.b)>=1 #遍历每个样本,检查分类条件
if condition:
self.w-=self.learning_rate*(2*self.w)#如果样本被正确分类且在正确的间隔外,仅通过正则项更行权重(防止过拟合)
else:
self.w-=self.learning_rate*((2*self.w)-self.C*np.dot(x_i,y_[idx]))#样本被错误分类或者在间隔内,则权重更新包括误差项,同时更新偏置,使样本在未来被正确分类
self.b-=self.learning_rate*self.C*y_[idx]
def predict(self,X):
Linear_output=np.dot(X,self.w)-self.b
return np.sign(Linear_output)
#数据准备和模型训练
X,y=datasets.make_blobs(n_samples=100,centers=2,random_state=6)
y=np.where(y==0,-1,1)#调整标签为-1和1
svm1=LinearSVM1(C=20)#C=20,100,200
svm1.fit(X,y)
plot_hyperplane(X,y,svm1.w,svm1.b) # type: ignore4.6 调整C值的实验结果图
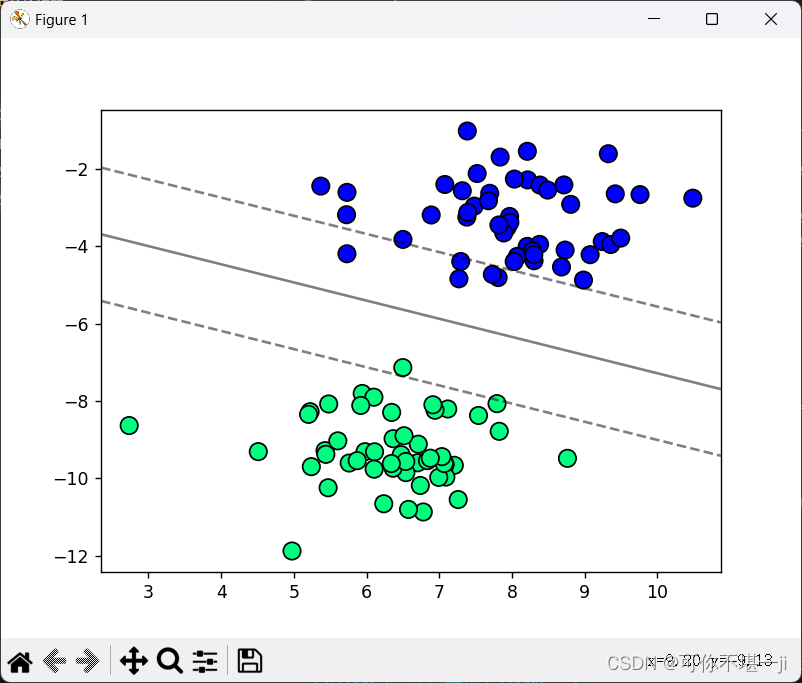
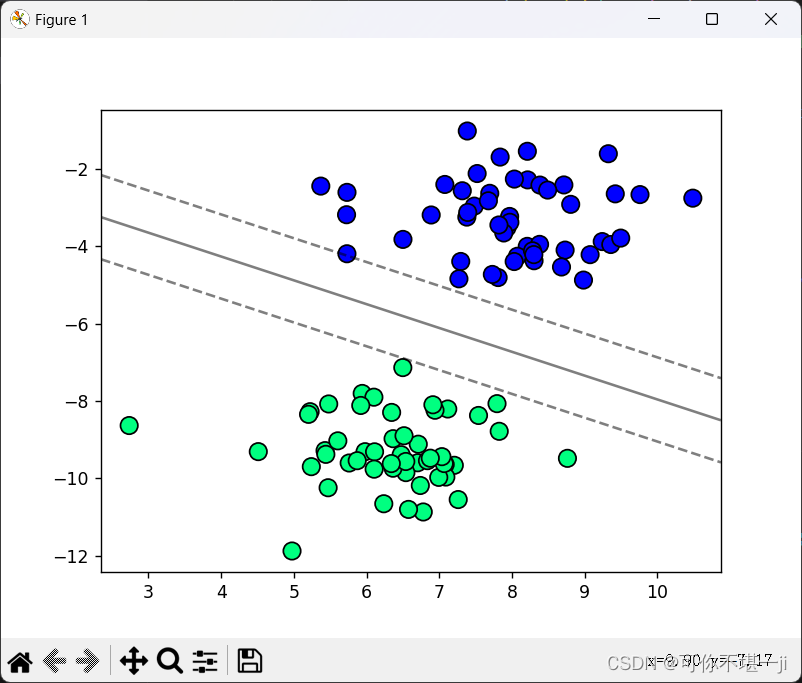
当C=20时,SVM分类结果如下图所示
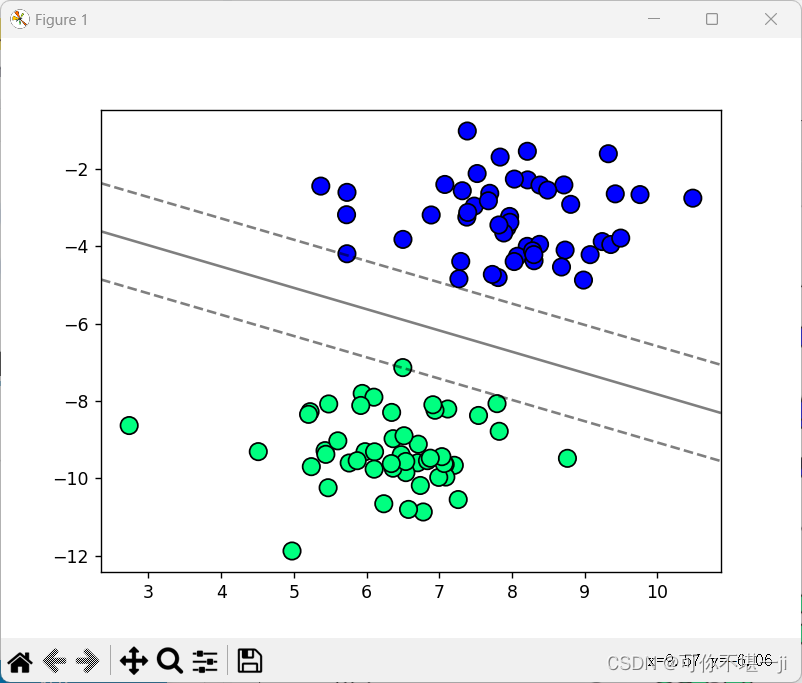
当C=100时,SVM分类结果如下图所示
当C=200时,SVM分类结果如下图所示
4.7 实验整体代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
class LinearSVM:
def __init__(self,learning_rate=0.0001,lambda_param=0.1,n_iters=1000):
self.learning_rate=learning_rate#学习率
self.lambda_param=lambda_param#正则化参数
self.n_iters=n_iters#迭代次数
self.w=None
self.b=None
def fit(self,X,y):#fit方法用于模型训练
n_samples,n_features=X.shape
y_ =np.where(y<=0,-1,1)
#初始化权重和偏置为0
self.w=np.zeros(n_features)
self.b=0
for _ in range(self.n_iters):
for idx,x_i in enumerate(X):
condition = y_[idx]*(np.dot(x_i,self.w)-self.b)>=1 #遍历每个样本,检查分类条件
if condition:
self.w-=self.learning_rate*(2*self.lambda_param*self.w)#如果样本被正确分类且在正确的间隔外,仅通过正则项更行权重(防止过拟合)
else:
self.w-=self.learning_rate*(2*self.lambda_param*self.w-np.dot(x_i,y_[idx]))#样本被错误分类或者在间隔内,则权重更新包括误差项,同时更新偏置,使样本在未来被正确分类
self.b-=self.learning_rate*y_[idx]
def predict(self,X):
Linear_output=np.dot(X,self.w)-self.b
return np.sign(Linear_output)
#结果可视化
def plot_hyperplane(X,y,w,b):
plt.scatter(X[:,0],X[:,1],marker='o',c=y,s=100,edgecolors='k',cmap='winter')
ax=plt.gca()
xlim=ax.get_xlim()
ylim=ax.get_ylim()
xx=np.linspace(xlim[0],xlim[1],30)
yy=np.linspace(ylim[0],ylim[1],30)
YY,XX=np.meshgrid(yy,xx)
xy=np.vstack([XX.ravel(),YY.ravel()]).T
Z=(np.dot(xy,w)-b).reshape(XX.shape)
ax.contour(XX,YY,Z,colors='k',levels=[-1,0,1],alpha=0.5,linestyles=['--','-','--'])
plt.show()
#数据准备和模型训练
#X,y=datasets.make_blobs(n_samples=100,centers=2,random_state=6)
#y=np.where(y==0,-1,1)#调整标签为-1和1
#svm0=LinearSVM()
#svm0.fit(X,y)
#plot_hyperplane(X,y,svm0.w,svm0.b) # type: ignore
#调整C参数看不同的效果
class LinearSVM1:
def __init__(self,C=1.0,learning_rate=0.0001,n_iters=1000):
self.C=C
self.learning_rate=learning_rate
self.n_iters=n_iters
self.w=None
self.b=None
def fit(self,X,y):
n_samples,n_features=X.shape
y_ =np.where(y<=0,-1,1)
#初始化权重和偏置为0
self.w=np.zeros(n_features)
self.b=0
for _ in range(self.n_iters):
for idx,x_i in enumerate(X):
condition = y_[idx]*(np.dot(x_i,self.w)-self.b)>=1 #遍历每个样本,检查分类条件
if condition:
self.w-=self.learning_rate*(2*self.w)#如果样本被正确分类且在正确的间隔外,仅通过正则项更行权重(防止过拟合)
else:
self.w-=self.learning_rate*((2*self.w)-self.C*np.dot(x_i,y_[idx]))#样本被错误分类或者在间隔内,则权重更新包括误差项,同时更新偏置,使样本在未来被正确分类
self.b-=self.learning_rate*self.C*y_[idx]
def predict(self,X):
Linear_output=np.dot(X,self.w)-self.b
return np.sign(Linear_output)
#数据准备和模型训练
X,y=datasets.make_blobs(n_samples=100,centers=2,random_state=6)
y=np.where(y==0,-1,1)#调整标签为-1和1
svm1=LinearSVM1(C=20)#C=20,100,200
svm1.fit(X,y)
plot_hyperplane(X,y,svm1.w,svm1.b) # type: ignore五、总结
5.1 SVM的优缺点
优点:能够处理高维数据、具有较强的泛化能力、适用于小样本数据、可以处理非线性问题、具有较好的鲁棒性和可解释性等。
缺点:对参数的敏感性、计算复杂度高、对数据的缩放和噪声敏感、仅适用于二分类问题等。
5.2 实验小结
在学习支持向量机(SVM)的理论知识时,抽象的概念和复杂的公式可能让人难以理解。然而,通过实验,我得以直观地观察到SVM是如何在高维数据空间中划分数据的,同时也更深入地理解了支持向量在模型中所扮演的关键角色。在实验过程中,我对参数进行了调整,如改变C值以及选择不同的核函数,这让我更加清晰地认识到这些参数是如何影响模型性能的。此外,我也体会到在运用SVM之前,对数据进行恰当的预处理,包括归一化、标准化以及去除多余特征等步骤,是非常关键的。实验让我深刻感受到,预处理数据的方式对模型性能有着显著的影响。同时,我也发现,合理的特征选择或特征工程可以大幅提升模型的性能,并且有助于降低过拟合的风险。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









