






目录
一、简介
1.1 PCA算法简介
PCA 是 (Principal Component Analysis )的缩写,中文称为主成分分析法。它是一种维数约减(Dimensionality Reduction)算法,即把高维度数据在损失最小的情况下转换为低维度数据的算法。 显然,PCA 可以用来对数据进行压缩,可以在可控的失真范围内提高运算速度,提高机器学习的效率,使较为复杂的数据简单化。
所谓损失最小就是从高维向低维映射的时候误差最小,低维空间的描述是向量组,k维空间就用k个向量来描述这个空间。
1.2 PCA算法流程

流程解释:
一个协方差矩阵有着不同的特征值与特征向量,最高特征值的对应的特征向量就是这个数据集的主成分。通常来说,一旦协方差矩阵的特征值和特征向量被计算出来了之后,就是按照特征值的大小从高到低依次排列。特征值的大小确定了主成分的重要性。
主成分分析的基本原理就是:选择特征值较大的作为主成分,从而进行降维。
比如:一开始数据集是N维的,在进行了协方差矩阵的特征值计算后,得到了N个特征值和与这些特征值相对应的特征向量。然后在主成分分析时,选取了前P个较大的特征值,如此一来,就将原来N维的数据降维到只有P维。这样就起到了降维的效果了。
1.3 PCA算法功能
PCA算法在机器学习中有许多用途,如:
1. 降维
PCA可以将高维数据集降到更低的维度,减少数据存储和处理的开销。
2. 压缩
PCA可以将数据集表示为比原始数据集更紧凑的形式,可以用于数据压缩。
3. 特征提取
PCA可以从原始数据集中提取最重要的特征,这些特征可以用于构建更好的模型。
4. 去噪
PCA可以帮助我们去除噪声,并且使数据集更具可分性。
二、算法实现
2.1 准备数据集
准备数据集:导入Scikit-learn库中的鸢尾花数据集
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import PCA
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 鸢尾花的数据集
iris = datasets.load_iris()
print(iris)输出鸢尾花的数据集的(部分)结果图如下:
2.2 利用PCA进行降维
fit_transform 方法:
fit_transform 是 PCA(主成分分析)类中的一个非常实用的方法,它结合了 fit 和 transform 两个步骤。当你使用 fit_transform 方法时,PCA 首先会拟合数据(通过 fit 方法)来计算数据的主成分(或称为特征向量),这些主成分代表了数据中的主要变化方向。然后,它会对原始数据进行线性变换(通过 transform 方法),将数据投影到这些主成分上,从而实现数据的降维。这个过程在一步内完成,使得使用 PCA 进行降维更加简便。
explained_variance_ratio_ 属性:
explained_variance_ratio_ 是 PCA 类的一个属性,它返回一个数组,数组中的每个元素表示对应主成分所解释的方差占总方差的百分比。这个百分比反映了每个主成分在描述原始数据变异时的贡献程度。通过查看 explained_variance_ratio_,我们可以了解各个主成分的重要性,并据此决定保留多少个主成分来平衡信息保留和降维效果。
explained_variance_ratio_.sum() 方法:
explained_variance_ratio_.sum() 并不是一个独立的方法,而是一个对 explained_variance_ratio_ 属性数组求和的操作。这个操作的结果是计算当前保留的主成分所解释的总方差百分比。这个百分比越高,意味着我们保留的主成分越多,降维后的数据保留了原始数据中的更多信息。因此,这个值可以帮助我们评估降维的效果,判断我们是否保留了足够多的信息。
components_ 属性:
components_ 是 PCA 类的一个属性,它返回了一个数组,数组中的每一行是一个特征向量,这些特征向量对应于 PCA 计算出的主成分。这些特征向量描述了数据的主要变化方向,它们构成了新的特征空间。在 PCA 中,这些特征向量被用来对原始数据进行线性变换,将原始数据投影到新的特征空间上,实现数据的降维。此外,components_ 也可以用来分析每个原始特征在构建新特征时的权重,从而了解哪些原始特征对降维后的数据影响更大。
X=iris['data']
y=iris['target']
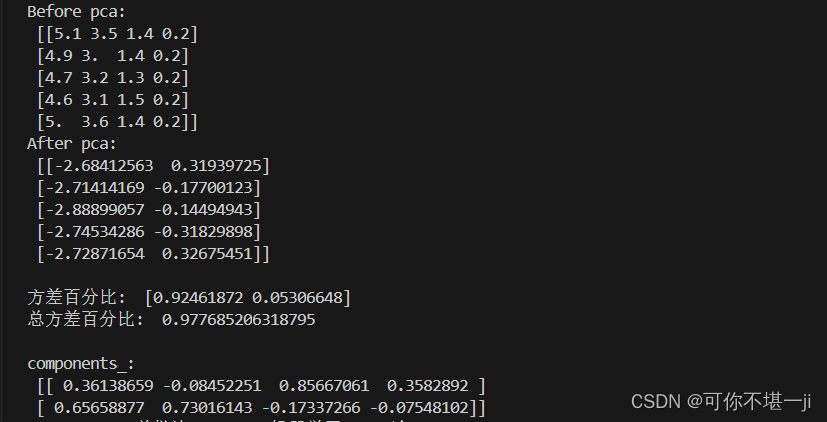
print('Before pca: \n', X[:5,:])# 前五行,所有列
pca_1 = PCA(n_components=2) # 指定主成分数量初始化 将数据降为2维
X_red_1 = pca_1.fit_transform(X) # fit并直接得到降维结果
# 这里只展示前三行的结果以示对比
print('After pca: \n', X_red_1[:5, :],'\n')
# 查看各个特征值所占的百分比,也就是每个主成分保留的方差百分比
print('方差百分比: ', pca_1.explained_variance_ratio_)
# 当前保留总方差百分比;
print('总方差百分比: ',pca_1.explained_variance_ratio_.sum(),'\n')
# 线性变换规则
print('components_: \n', pca_1.components_)经规定主成成分为2,PCA处理过后,数据从四维变成二维,实现降维。结果如下所示:
2.3 分类结果可视化
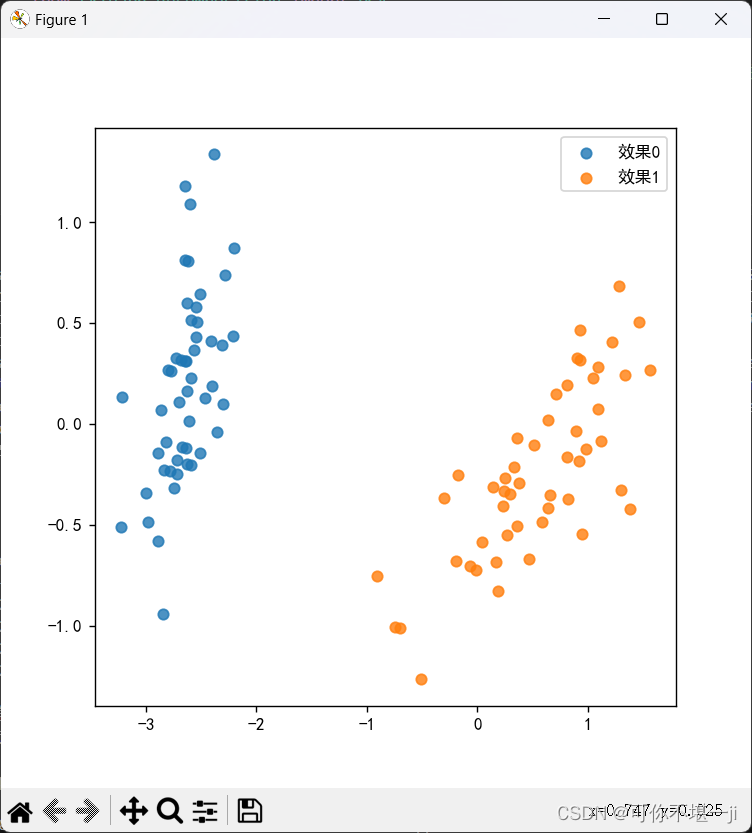
#结果可视化
plt.figure(figsize=(6,6))
for i in range(2):
plt.scatter(x=X_red_1[np.where(y==i),:][0][:,0], y=X_red_1[np.where(y==i),:][0][:,1], alpha=0.8, label='效果%s' % i)
plt.legend()
plt.show()测试结果图:
三、代码整合及小结
3.1 完整代码整合
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import PCA
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 鸢尾花的数据集
iris = datasets.load_iris()
print(iris)
X=iris['data']
y=iris['target']
print('Before pca: \n', X[:5,:])# 前五行,所有列
pca_1 = PCA(n_components=2) # 指定主成分数量初始化 将数据降为2维
X_red_1 = pca_1.fit_transform(X) # fit并直接得到降维结果
# 这里只展示前三行的结果以示对比
print('After pca: \n', X_red_1[:5, :],'\n')
# 查看各个特征值所占的百分比,也就是每个主成分保留的方差百分比
print('方差百分比: ', pca_1.explained_variance_ratio_)
# 当前保留总方差百分比;
print('总方差百分比: ',pca_1.explained_variance_ratio_.sum(),'\n')
# 线性变换规则
print('components_: \n', pca_1.components_)
#结果可视化
plt.figure(figsize=(6,6))
for i in range(2):
plt.scatter(x=X_red_1[np.where(y==i),:][0][:,0], y=X_red_1[np.where(y==i),:][0][:,1], alpha=0.8, label='效果%s' % i)
plt.legend()
plt.show()3.2 小结
PCA的优缺点:
优点:PCA能有效减少数据的维度,同时保留大部分变异性,有助于去除噪声;通过正交转换消除了数据的相关性,有助于后续模型的处理和性
能提升。
缺点:降维过程中可能会丢失一部分信息,特别是当去除的成分含有重要信息时。
总结:
PCA算法是一种广泛使用的算法,用于降维、特征提取和数据压缩等。它可以使数据集更易于处理,并提供更好的可视化效果。但是,PCA也有一些限制,例如不能更好地理解非线性数据集。















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









