






1
项目背景
flink读取数据库表的内容,将其同步到项目的数仓中或者做流式处理,这是一个常见的需求。本期就同步sql库表内容到kafka及同步sqlserver配置信息进行流式处理两个需求展开进行讲解.
2
案例一分析
案例:我们的sqlserver表中存储有我们业务系统数据,该表在设计时会设置过期时间,每隔一段时间会删除历史数据,现在我们需要把该表实时同步到kafka中,方便管理,并且要保存历史数据,那该怎么实现呢?

3
解决思路
实时同步库表数据,需要选择合适的CDC工具,本次使用flinkCDC.一般的,使用cdc首先要对数据库进行配置,比如mysql需要开启binlog日志,同样的,sqlserver要开启cdc及配置代理.这里不再进行赘述了.
来到flinkCDC官网,它对sqlserver版本有一定限制.

4
具体实现
导入依赖
<dependency>
<groupId>com.ververica</groupId><artifactId>flink-connector-sqlserver-cdc</artifactId><!-- The dependency is available only for stable releases, SNAPSHOT dependencies need to be built based on master or release- branches by yourself. --><version>3.0-SNAPSHOT</version></dependency>
导入模版代码
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.functions.source.SourceFunction;import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;import com.ververica.cdc.connectors.sqlserver.SqlServerSource;public class SqlServerSourceExample {public static void main(String[] args) throws Exception {SourceFunction<String> sourceFunction = SqlServerSource.<String>builder().hostname("localhost").port(1433).database("sqlserver") // monitor sqlserver database.tableList("dbo.products") // monitor products table.username("sa").password("Password!").deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String.build();StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.addSource(sourceFunction).print().setParallelism(1); // use parallelism 1 for sink to keep message orderingenv.execute();}}
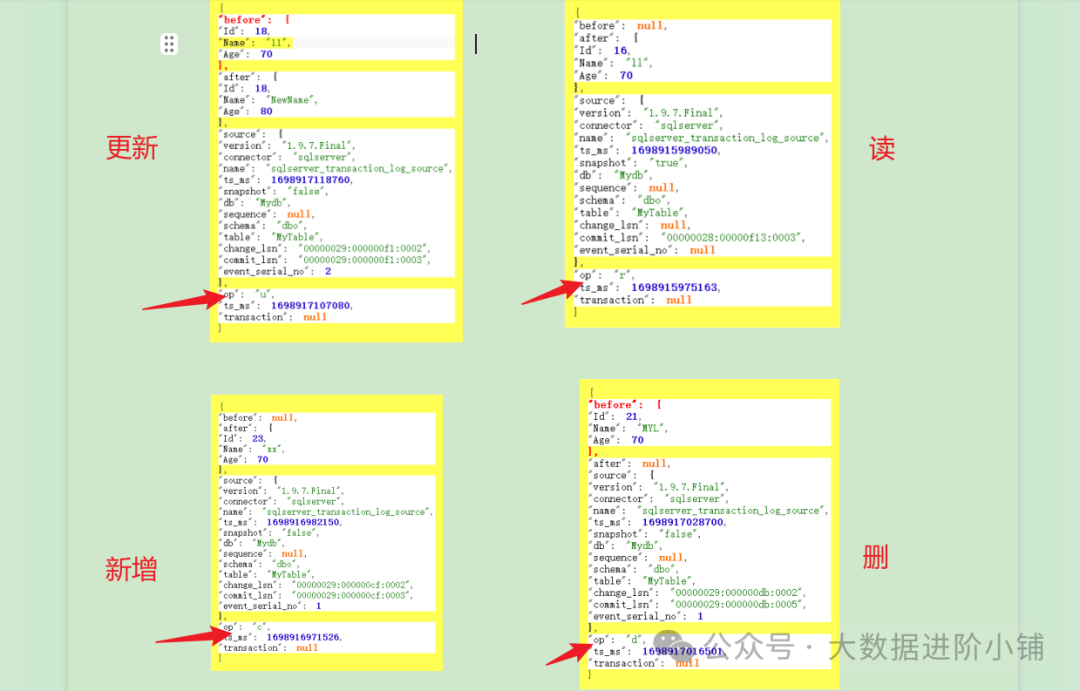
这是flinkcdc读取到数据结构.before为操作之前的数据,after为操作之后的数据.
op=u:更新操作
op=r:首次启动时全量的读取的数据均为r
op=c:新增操作
op=d:删除操作
好,弄明白了数据表达的意思就好操作了,咱们最终需要的保存全量历史数据,所以用一个filter算子排除op=d的数据就可以了.
SingleOutputStreamOperator<String> result = source.map(line -> JSON.parseObject(line, SqlServerEventData.class)).returns(Types.POJO(SqlServerEventData.class)).filter(bean -> {String op = bean.getOp();return "c".equals(op) || "r".equals(op); // c:代表新增 r:代表全量读取的数据}).map(bean -> JSON.toJSONString(bean.getAfter()));
5
案例二分析
案例:需要将sqlserver的配置信息同步到kafka中,那这需要怎么实现呢?比如查询sqlserver最大会话数,SELECT @@MAX_CONNECTIONS.
6
解决思路
这个需求的难点在于如何流式的读取配置数据,即采用什么工具每隔一段时间去执行这句sql语句,将结果转化为流,有java经验的伙伴就会想到用线程去执行,然后设置睡眠时间.没错,flink中就有类似的工具.RichSourceFunction.是富函数类型,它有很多的工具,比如open()方法,用于初始化的,比如run()方法,用于执行具体的业务逻辑,run方法可以调动线程去执行任务,显然还可以设置睡眠时间,TimeUnit.SECONDS.sleep(intervalSecond),
7
笔记扩展
常见的CDC工具有哪些?
以下是Maxwell、Canal与Flink CDC之间的一个简单对比表格:
| 指标 | Maxwell | Canal | Flink CDC |
|---|---|---|---|
| 设计目标 | MySQL CDC | MySQL CDC,后扩展至其他数据库 | 全面的数据流处理及多数据库CDC |
| 数据库支持 | MySQL | MySQL, PostgreSQL等 | MySQL, PostgreSQL, SQL Server等多种数据库 |
| 轻量级 | 是 | 较重,但支持集群部署 | 作为流处理框架相对较重 |
| 易用性 | 高,部署简单 | 中等,部署和配置较Maxwell复杂 | 中到高,取决于具体应用场景 |
| 功能特性 | 基础CDC,JSON输出 | 高度可定制化,支持过滤和转换规则 | 全增量一体化,Exactly-Once语义,丰富的流处理能力 |
| 扩展性 | 单机部署,扩展性有限 | 支持分布式集群部署 | 集成了Flink的分布式能力,扩展性好 |
| 社区支持与活跃度 | 社区活跃度适中 | 相对活跃,有阿里巴巴背书 | Apache顶级项目,社区活跃度高 |
| 应用场景 | 小型到中型企业,简单CDC需求 | 大型企业,需要复杂定制和扩展的场景 | 需要实时流处理、复杂数据管道构建的场景 |

坚持分享,感谢关注,大家共同进步!

微信公众号|大数据进阶小铺
















 592
592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











