






 刚从R转修python
刚从R转修python
进行数据预处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import OneHotEncoder, LabelEncoder, StandardScaler
from sklearn.model_selection import StratifiedKFold
from bayes_opt import BayesianOptimization
from sklearn.model_selection import cross_val_predict,cross_validate
import xgboost as xgb
import string
import warnings
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score, roc_auc_score, f1_score
from keras import models
from keras import layers
from tensorflow.keras import optimizers
import tensorflow as tf
from keras import losses
from keras import metrics
from sklearn.model_selection import KFold
sns.set(style="darkgrid")
SEED = 42定义两个函数,用于连接和分开训练集和测试集
def concat_df(train_data, test_data):
# Returns a concatenated df of training and test set
return pd.concat([train_data, test_data], sort=True).reset_index(drop=True)
#分离两个数据集
def divide_df(all_data):
# Returns divided dfs of training and test set
return all_data.loc[:890], all_data.loc[891:].drop(['Survived'], axis=1)
df_train = pd.read_csv('换成你自己的路径')
df_test = pd.read_csv('换成你自己的路径')
c = df_test['PassengerId']
df_all = concat_df(df_train, df_test)
y_train = df_train['Survived'].values
df_train.name = 'Training Set'
df_test.name = 'Test Set'
df_all.name = 'All Set'
dfs = [df_train, df_test]
print(df_all.columns)
数据列名如下所示,Survived为目标变量

处理缺失值
查看缺失值
def missing_value(df):
class_types = df.apply(lambda col: col.dtype)
na_counts = df.isnull().sum()
zero_counts = df.apply(lambda col: (col == 0).sum(), axis=0)
m = pd.DataFrame({
'class': class_types,
'na': na_counts,
'zero': zero_counts
})
m['na_prop'] = (m['na'] / len(df) * 100).round(2).astype(str) + '%'
m['zero_prop'] = (m['zero'] / len(df) * 100).round(2).astype(str) + '%'
m2 = m[m[['na', 'zero']].sum(axis=1) != 0]
m2 = m2.sort_values(by=['na', 'zero'], ascending=[False, False])
return m2
missing_value(df_all)定义一个函数用于查看缺失值,数据集缺失值如下所示:
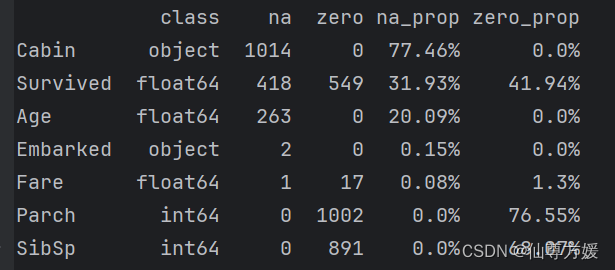
对缺失值进行插补
对于Age采用基于区域特征进行插补的策略
df_num=df_all[['PassengerId', 'Survived', 'Pclass','Age', 'SibSp','Parch', 'Fare']]
df_all_corr = df_num.corr().abs().unstack().sort_values(kind="quicksort", ascending=False).reset_index()
df_all_corr.rename(columns={"level_0": "Feature 1", "level_1": "Feature 2", 0: 'Correlation Coefficient'}, inplace=True)
df_all_corr[df_all_corr['Feature 1'] == 'Age']查看与Age的相关关系,如下所示
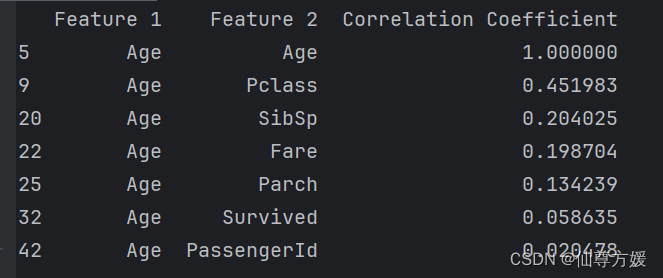
由图可知Age与Pclass相关性较强,可使用Pclass进行分组
age_by_pclass_sex = df_all.groupby(['Sex', 'Pclass'])['Age'].median()
for pclass in range(1, 4):
for sex in ['female', 'male']:
print('Median age of Pclass {} {}s: {}'.format(pclass, sex, age_by_pclass_sex[sex][pclass]))
print('Median age of all passengers: {}'.format(df_all['Age'].median()))为了是结果更为准确,使用Sex进行再次分组

由图可知,性别对Age也有一定影响,最终使用基于Age和Pclass的二级分组对数据进行插补
df_all['Age'] = df_all.groupby(['Sex', 'Pclass'])['Age'].transform(lambda x: x.fillna(x.median()))对Embarked进行插补
只有一个缺失值,从谷歌上搜到这个缺失值为S,这些数据是当时乘客的真实数据,可以搜
df_all[df_all['Embarked'].isnull()]
df_all['Embarked'] = df_all['Embarked'].fillna('S')对Fare进行插补
df_all[df_all['Fare'].isnull()]
med_fare = df_all.groupby(['Pclass', 'Parch', 'SibSp']).Fare.median()[3][0][0]
# Filling the missing value in Fare with the median Fare of 3rd class alone passenger
df_all['Fare'] = df_all['Fare'].fillna(med_fare)运行代码可以看到是单身,我们根据跟她相同情况的人的数据进行插补
对Cabin进行插补
这个变量缺失很多,但保留下来对后面预测有点用,正常来说应该直接删掉,但我看其他人都保留下来了
#对Cabin进行插补
df_all['Cabin']=df_all['Cabin'].fillna('Missing')
df_all['Cabin']=df_all['Cabin'].map(lambda c: c[0])
missing_value(df_all)开始绘图查看数据间的关系,并进行硬编码
查看船舱等级,甲板和生存率之间的关系
#绘图
#查看船舱与甲板的关系
total_per_deck = df_all.groupby(['Cabin']).size()
pclass1=df_all.Cabin[df_all.Pclass == 1].value_counts()/total_per_deck
pclass2=df_all.Cabin[df_all.Pclass == 2].value_counts()/total_per_deck
pclass3=df_all.Cabin[df_all.Pclass == 3].value_counts()/total_per_deck
df=pd.DataFrame({'pclass1': pclass1, 'pclass2': pclass2,'pclass3': pclass3})
ax = df.plot(kind='bar', stacked=True, title='Pclass and Deck')
ax.axhline(y=0.5, color='black', linestyle='--', linewidth=1)
idx = df_all[df_all['Cabin'] == 'T'].index
df_all.loc[idx, 'Cabin'] = 'A'
#查看甲板和生存率的关系
total_per_deck = df_all.loc[0:891].groupby(['Cabin']).size()
survived=df_all.loc[0:891].Cabin[df_all.loc[0:891].Survived == 1].value_counts()/total_per_deck
unsurvived=df_all.loc[0:891].Cabin[df_all.loc[0:891].Survived == 0].value_counts()/total_per_deck
df=pd.DataFrame({'survived': survived, 'unsurvived': unsurvived})
ax = df.plot(kind='bar', stacked=True, title='survived and Deck')
ax.axhline(y=0.5, color='black', linestyle='--', linewidth=1)
#Pclass
df_all.Pclass.value_counts()
df_all['Pclass'] = df_all['Pclass'].replace([1], 'First')
df_all['Pclass'] = df_all['Pclass'].replace([2], 'Second')
df_all['Pclass'] = df_all['Pclass'].replace([3], 'Third')
#对甲板进行硬编码
df_all['Cabin'] = df_all['Cabin'].replace(['D', 'B', 'E'], 3)
df_all['Cabin'] = df_all['Cabin'].replace(['C', 'F'], 2)
df_all['Cabin'] = df_all['Cabin'].replace(['A','G'], 1)
df_all['Cabin'] = df_all['Cabin'].replace(['M'], 0)
df_all['Cabin'].value_counts()
df_train, df_test = divide_df(df_all)
dfs = [df_train, df_test]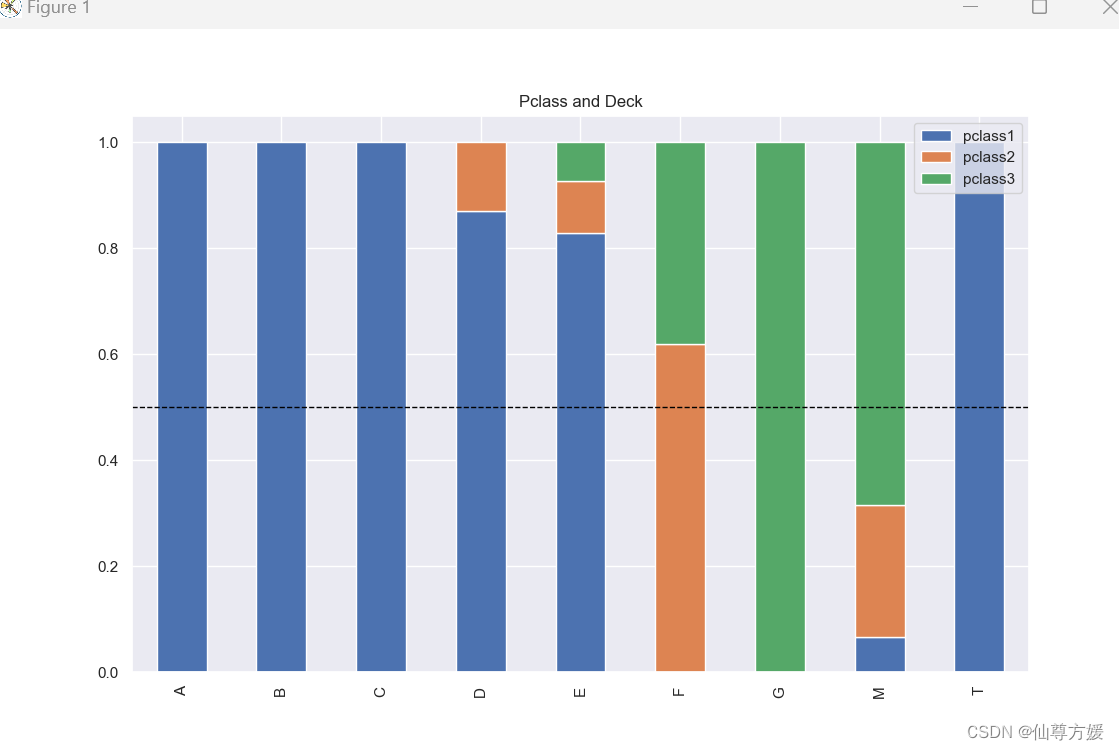
 可以看到不同的甲板上住着不同等级的乘客,甲板对Survived有一定影响,同时Pclass是一个分类变量,需要转化一下,不能直接用数字表示,按生存率高低进行硬编码
可以看到不同的甲板上住着不同等级的乘客,甲板对Survived有一定影响,同时Pclass是一个分类变量,需要转化一下,不能直接用数字表示,按生存率高低进行硬编码
查看Survived的情况
#绘图
survived = df_train['Survived'].value_counts()[1]
not_survived = df_train['Survived'].value_counts()[0]
survived_per = survived / df_train.shape[0] * 100
not_survived_per = not_survived / df_train.shape[0] * 100
plt.figure(figsize=(5, 4))
plt.hist(df_train['Survived'],bins=3,color='red',alpha=0.6)
plt.xlabel('Survival', size=15, labelpad=15)
plt.ylabel('Passenger Count', size=15, labelpad=15)
plt.xticks((0, 1), ['Not Survived ({0:.2f}%)'.format(not_survived_per), 'Survived ({0:.2f}%)'.format(survived_per)])
plt.title('Training Set Survival Distribution', size=15, y=1.05)
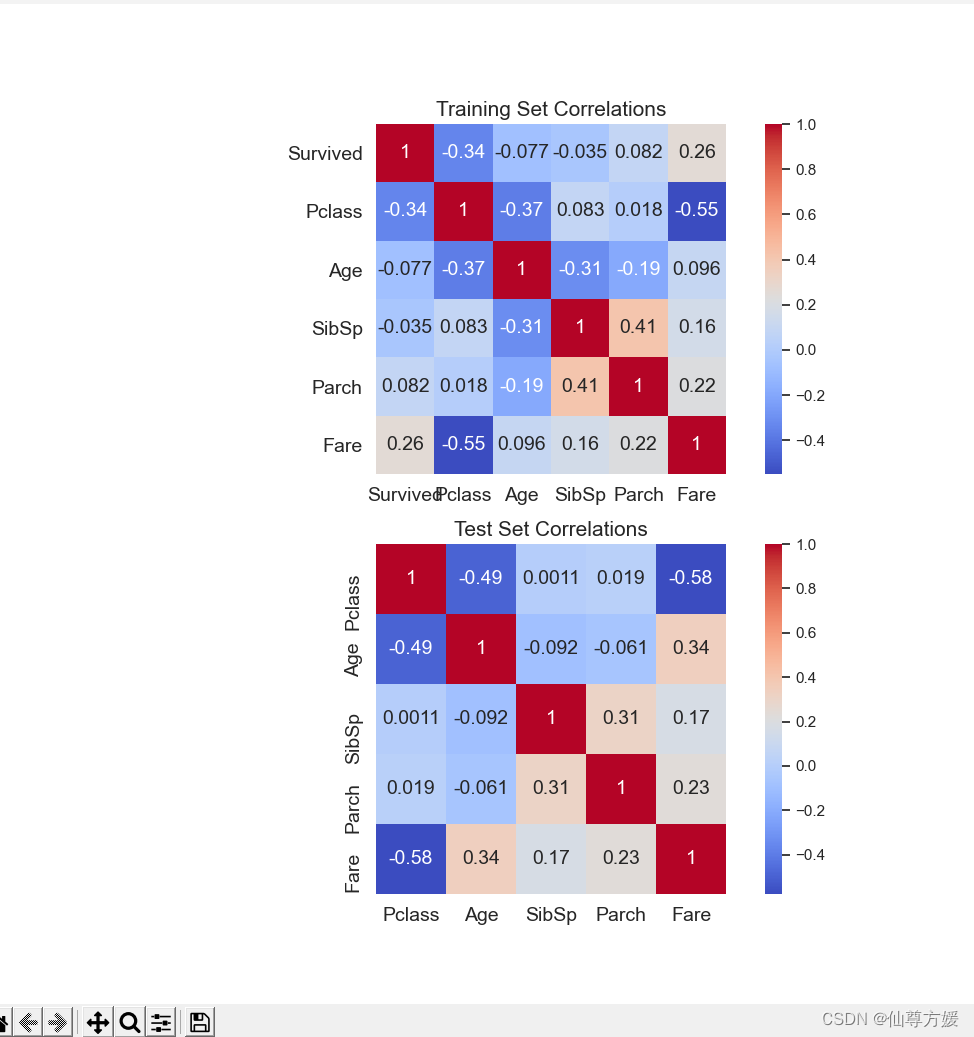
#相关系数图
fig, axs = plt.subplots(nrows=2, figsize=(10,10))
sns.heatmap(df_train.drop(['PassengerId'], axis=1).corr(), ax=axs[0], annot=True, square=True, cmap='coolwarm',
annot_kws={'size': 14})
sns.heatmap(df_test.drop(['PassengerId'], axis=1).corr(), ax=axs[1], annot=True, square=True, cmap='coolwarm',
annot_kws={'size': 14})
for i in range(2):
axs[i].tick_params(axis='x', labelsize=14)
axs[i].tick_params(axis='y', labelsize=14)
axs[0].set_title('Training Set Correlations', size=15)
axs[1].set_title('Test Set Correlations', size=15)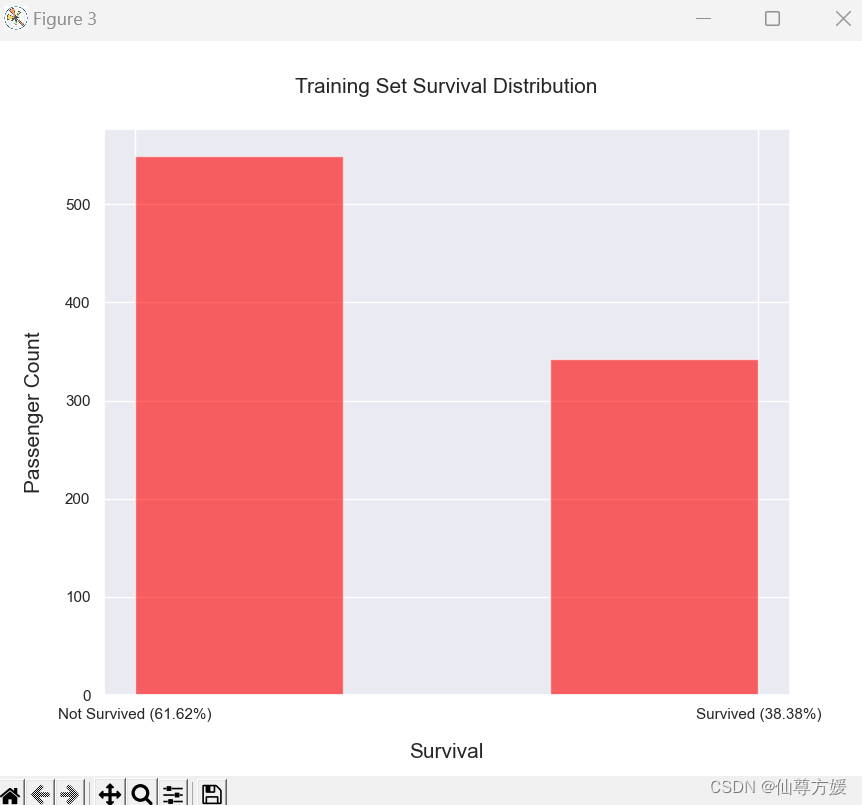 可以看到,大部分人都没能存活下来
可以看到,大部分人都没能存活下来
查看Age和Survived的关系,同时对Age进行转化
fig, axs = plt.subplots(nrows=1, figsize=(10,10))
plt.hist(df_train[df_train['Survived'] == 1]['Age'],alpha=0.7,label='survived',color='g')
plt.hist(df_train[df_train['Survived'] == 0]['Age'],alpha=0.5,label='unsurvived',color='b')
plt.title('Distribution of Survival in Age')
plt.xlabel("Distribution of Age Feature")
plt.legend()
conditions = [
df_all['Age'] <= 12.0,
(df_all['Age'] > 12.0) & (df_all['Age'] <= 18.0),
(df_all['Age'] > 18.0) & (df_all['Age'] <= 60.0),
df_all['Age'] > 60.0
]
choices = ['Child', 'teenage', 'Adult', 'Old']
df_all['Age'] = np.select(conditions, choices, default=np.nan)
查看Fare和Survived的关系,同时修正Fare
因为Fare里是有团体票的,要转化一下,换成每个人的票价
#计算人均票价
df_all['Ticket_Frequency'] = df_all.groupby('Ticket')['Ticket'].transform('count')
df_all['nfare']=df_all['Fare']/df_all['Ticket_Frequency']
df_train, df_test = divide_df(df_all)
fig, axs = plt.subplots(nrows=1, figsize=(5,5))
plt.hist(df_train[df_train['Survived'] == 1]['nfare'],alpha=0.5,label='survived',color='g')
plt.hist(df_train[df_train['Survived'] == 0]['nfare'],alpha=0.3,label='unsurvived',color='b')
plt.title('Distribution of Survival in Fare')
plt.xlabel("Distribution of Fare Feature")
plt.legend()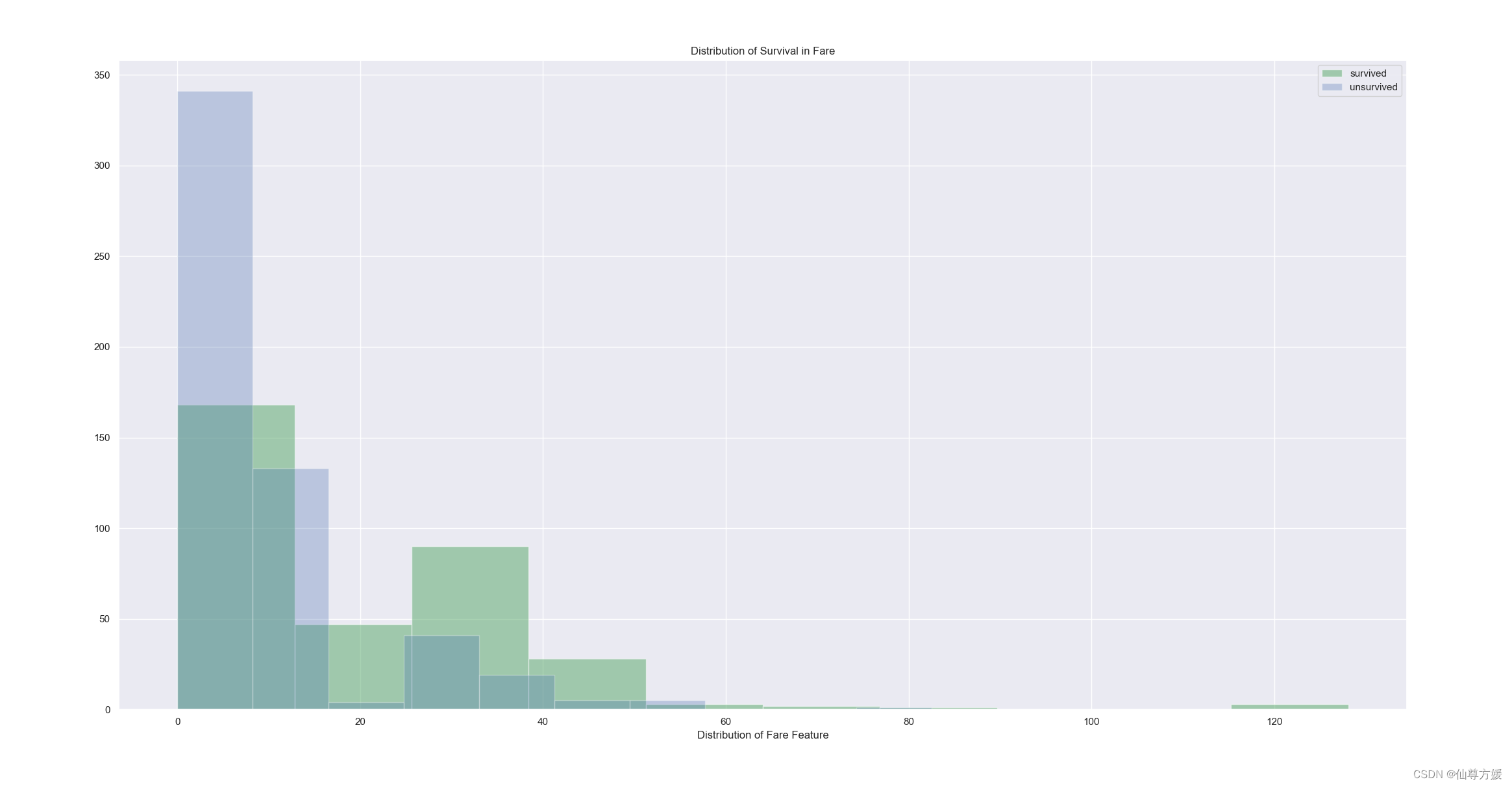
一次性画多个图
#画多个关系图
cat_features = ['Embarked', 'Parch', 'Pclass', 'Sex', 'SibSp', 'Cabin']
for i in cat_features:
total = df_all.loc[0:891].groupby([i]).size()
survived = df_all.loc[0:891][i][df_all.loc[0:891].Survived == 1].value_counts() / total
unsurvived = df_all.loc[0:891][i][df_all.loc[0:891].Survived == 0].value_counts() / total
df = pd.DataFrame({'survived': survived, 'unsurvived': unsurvived})
ax = df.plot(kind='bar', stacked=True, title='survived and {}'.format(i))
ax.axhline(y=0.5, color='black', linestyle='--', linewidth=1)
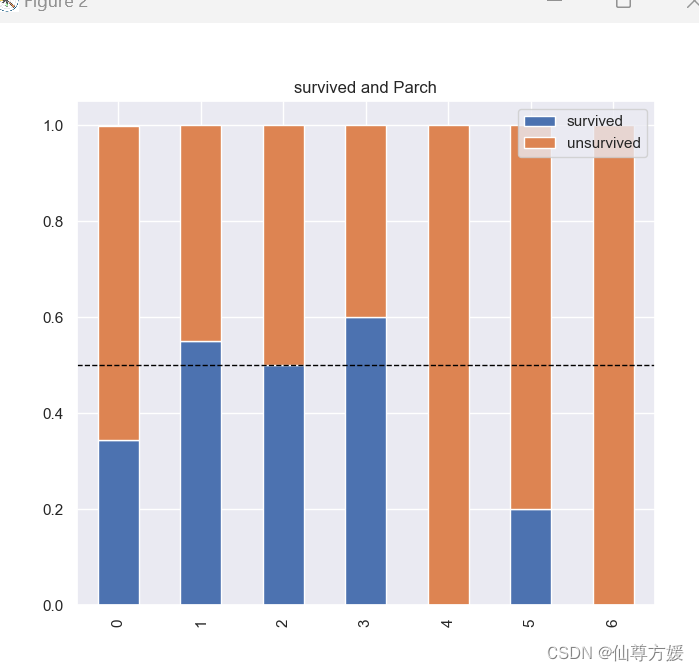
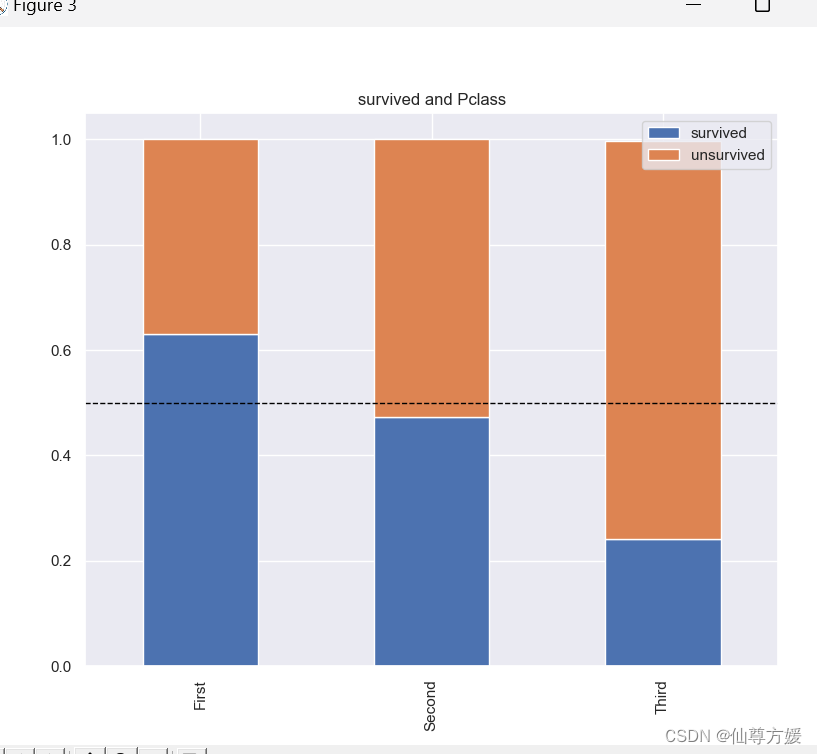
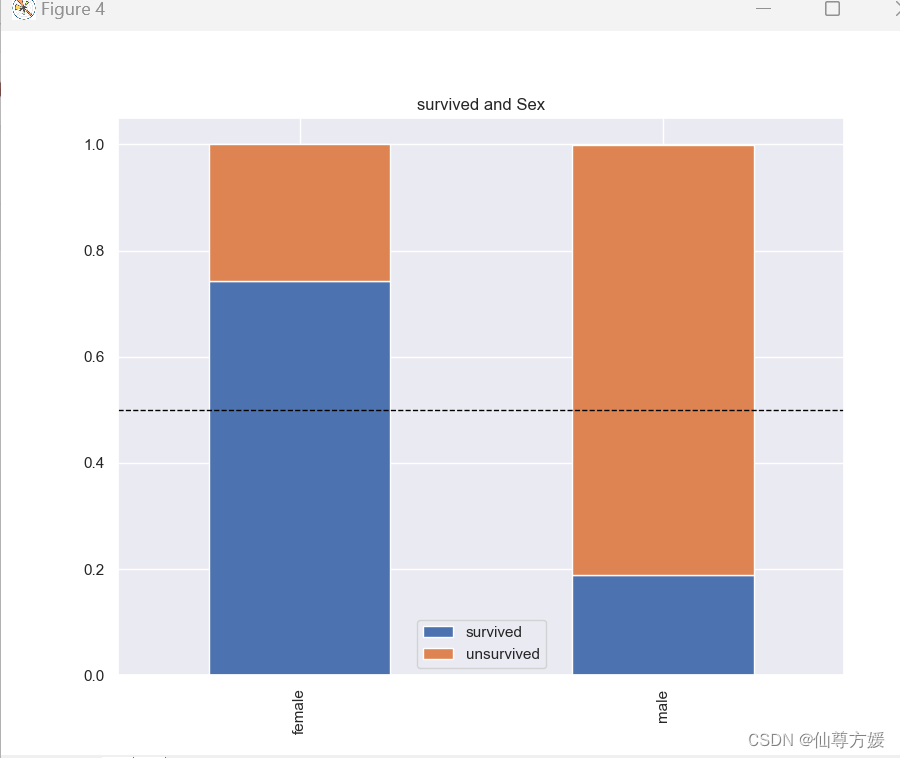
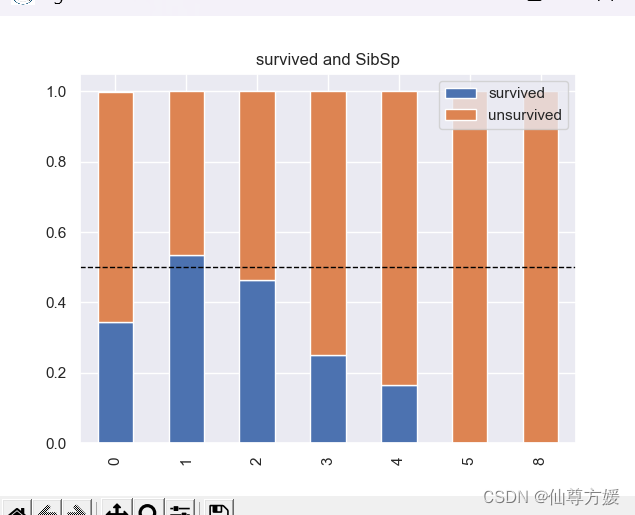
生成新变量
#生成新变量
df_all = concat_df(df_train, df_test)
df_all['Family_Size'] = df_all['SibSp'] + df_all['Parch'] + 1
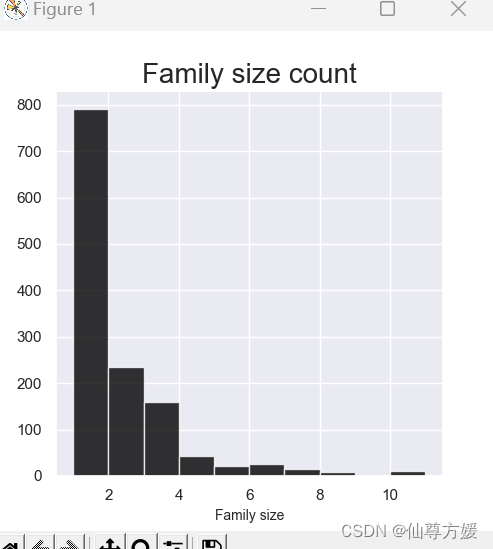
#画家庭数量的图
fig,axs=plt.subplots(1,1,figsize=(5,5))
plt.hist(df_all['Family_Size'],color='black',alpha=0.8)
plt.xlabel('Family size',size=10)
plt.title('Family size count',size=20)
family_map = {1: 'Alone', 2: 'Small', 3: 'Small', 4: 'Small', 5: 'Medium', 6: 'Medium', 7: 'Large', 8: 'Large', 11: 'Large'}
df_all['Family_Size_Grouped'] = df_all['Family_Size'].map(family_map)
#画家庭大小生存率图
total_per_level = df_all.loc[0:891].groupby(['Family_Size_Grouped']).size()
survived=df_all.loc[0:891].Family_Size_Grouped[df_all.loc[0:891].Survived == 1].value_counts()/total_per_level
unsurvived=df_all.loc[0:891].Family_Size_Grouped[df_all.loc[0:891].Survived == 0].value_counts()/total_per_level
df=pd.DataFrame({'survived': survived, 'unsurvived': unsurvived})
ax = df.plot(kind='bar', stacked=True, title='survived and family size')
ax.axhline(y=0.5, color='white', linestyle='--', linewidth=1)将父母兄弟姐妹这些加起来,计算家庭规模,和Survived的关系如下
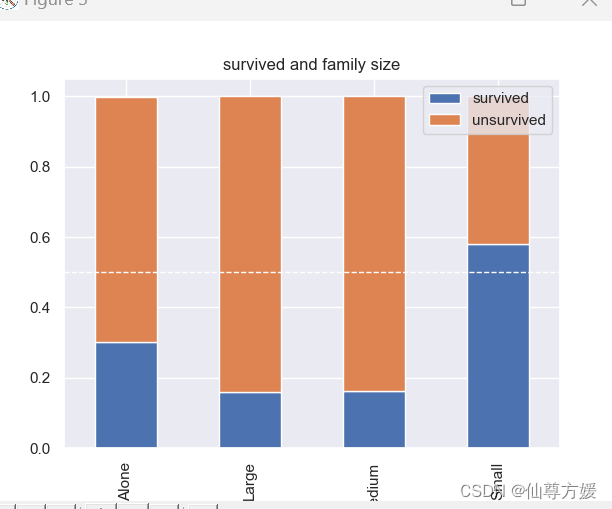
查看Title的影响,同时进行硬编码
#title影响
df_all['Title']=df_all['Name'].str.extract('([A-Za-z]+)\.',expand=False)
#查看称呼和生存率的关系
total_per_title = df_all.loc[0:891].groupby(['Title']).size()
survived=df_all.loc[0:891].Title[df_all.loc[0:891].Survived == 1].value_counts()/total_per_title
unsurvived=df_all.loc[0:891].Title[df_all.loc[0:891].Survived == 0].value_counts()/total_per_title
df=pd.DataFrame({'survived': survived, 'unsurvived': unsurvived})
ax = df.plot(kind='bar', stacked=True, title='survived and Title')
ax.axhline(y=0.5, color='white', linestyle='--', linewidth=1)
df_all['Title'] = df_all['Title'].replace(['Countess','Lady', 'Mlle','Mme','Ms','Sir'], 3)
df_all['Title'] = df_all['Title'].replace(['Miss', 'Master','Mrs'], 2)
df_all['Title'] = df_all['Title'].replace(['Col', 'Dr', 'Major' ], 1)
df_all['Title'] = df_all['Title'].replace(['Col', 'Capt','Don','Jonkheer','Mr','Rev', 'Dona'], 0)
df_all['Title'].value_counts()
y_train=df_train.Survived.values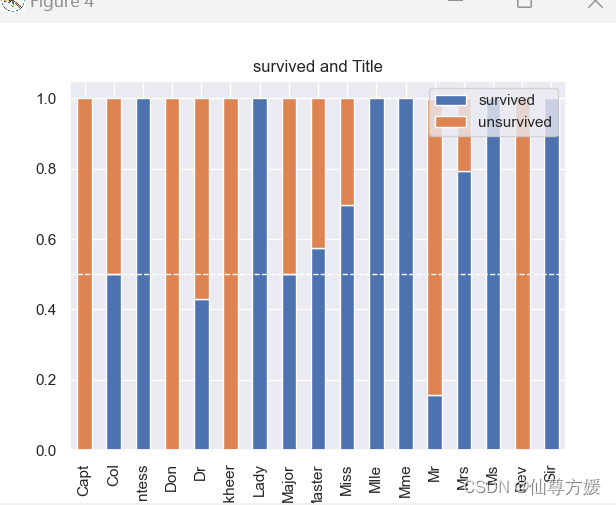
按生存率高低进行硬编码
对分类变量进行独热编码
df_all.columns
drop_cols = ['Fare','Name','PassengerId','Survived','Ticket','Family_Size']
df_all.drop(columns=drop_cols, inplace=True)
#独热编码
features = ['Sex', 'Age', 'Family_Size_Grouped','Embarked','Pclass',]
for i in features:
one_hot_encoded=pd.get_dummies(df_all[i])
df_all = pd.concat([df_all, one_hot_encoded], axis=1)
df_all.drop(i, axis=1, inplace=True)
df_train=df_all.loc[0:890]
df_test=df_all.loc[891:]对数值变量进行标准化
columns=['Parch','SibSp','Cabin','Title','Ticket_Frequency', 'nfare']
for i in columns:
a=df_train[i].mean()
df_train[i]-=a
df_test[i]-=a
b=df_train[i].std()
df_train[i] /= b
df_test[i] /= b进行建模
贝叶斯调优
网格调参太慢了,直接放弃
def create_model(learning_rate):
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(22,)))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
optimizer = optimizers.RMSprop(learning_rate=learning_rate)
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['acc'])
return model
def optimize_model(learning_rate):
kf = KFold(n_splits=5) # Number of folds for cross-validation
accuracies = []
for train_idx, val_idx in kf.split(df_train.values):
X_train, X_val = df_train.values[train_idx], df_train.values[val_idx]
Y_train, y_val = y_train[train_idx], y_train[val_idx]
model = create_model(learning_rate)
model.fit(X_train, Y_train, epochs=40, batch_size=64, verbose=0)
_, accuracy = model.evaluate(X_val, y_val)
accuracies.append(accuracy)
return np.mean(accuracies)
optimizer = BayesianOptimization(optimize_model, pbounds={'learning_rate': (0.001, 0.1)})
optimizer.maximize(n_iter=10)建模
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(22, )))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(learning_rate=0.025049251923234424),
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(df_train.values, y_train,epochs=30, batch_size=64, verbose=0)
result=model.predict(df_test.values)
result=pd.DataFrame(result,columns=['Survived'])
conditions = [
result['Survived'] < 0.5,
result['Survived'] > 0.5
]
choices = [0,1]
result['Survived'].unique()
result['Survived'] = np.select(conditions, choices, default=np.nan)
result =result['Survived'].astype(int)
submission_df = pd.DataFrame(columns=['PassengerId', 'Survived'])
submission_df['PassengerId'] = c
submission_df['Survived'] = result
submission_df.to_csv('shenjing3.csv', header=True, index=False)种子数会有影响,所以你可能跑出来结果跟我不一样,我看见有人用了100个种子建模,最后对结果进行平均,可以试试















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









