






年味祝福转化词云图【文字识别+词云图制作】
简介:春节是每一年难忘的回忆,其中不乏一些祝福,一些关键词能让我们久久回味,制作词云图正是将这份回忆保存起来的绝佳方案,下面是利用pycharm制作词云图的方案。
实现效果


环境配置
电脑需有pytorch,没有可前往pytorch官网根据语言版本、操作系统等信息找到安装方法。
用到的库:cv2(图像处理),easyocr(文字识别),wordcloud(词云图关键库),jieba(分词模块),numpy(数据处理库)
安装方法:直接从pycharm中下载,搜索安装最新版本

另外这里还要下载模型👇
进入esayocr官网选择需要的模型下载(https://www.jaided.ai/easyocr/modelhub/)。
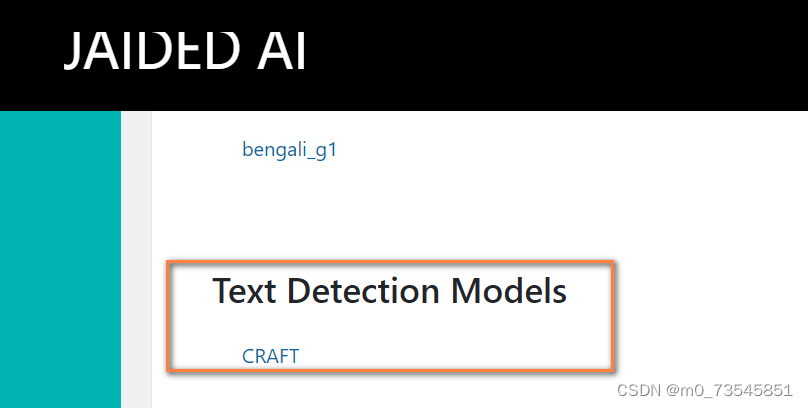
(如果pycharm下载失败,这里可以ye下载)
下载语言模型,这里是英语和中文

将下载的模型文件解压后拷贝到当前登录的用户目录的.EasyOCR\model文件夹下,Windows系统为:C:\Users\yourname.EasyOCR\model,其中yourname是登录用户名。
导入制作词语图的字体
1、打开自己电脑C:\Windows\Fonts
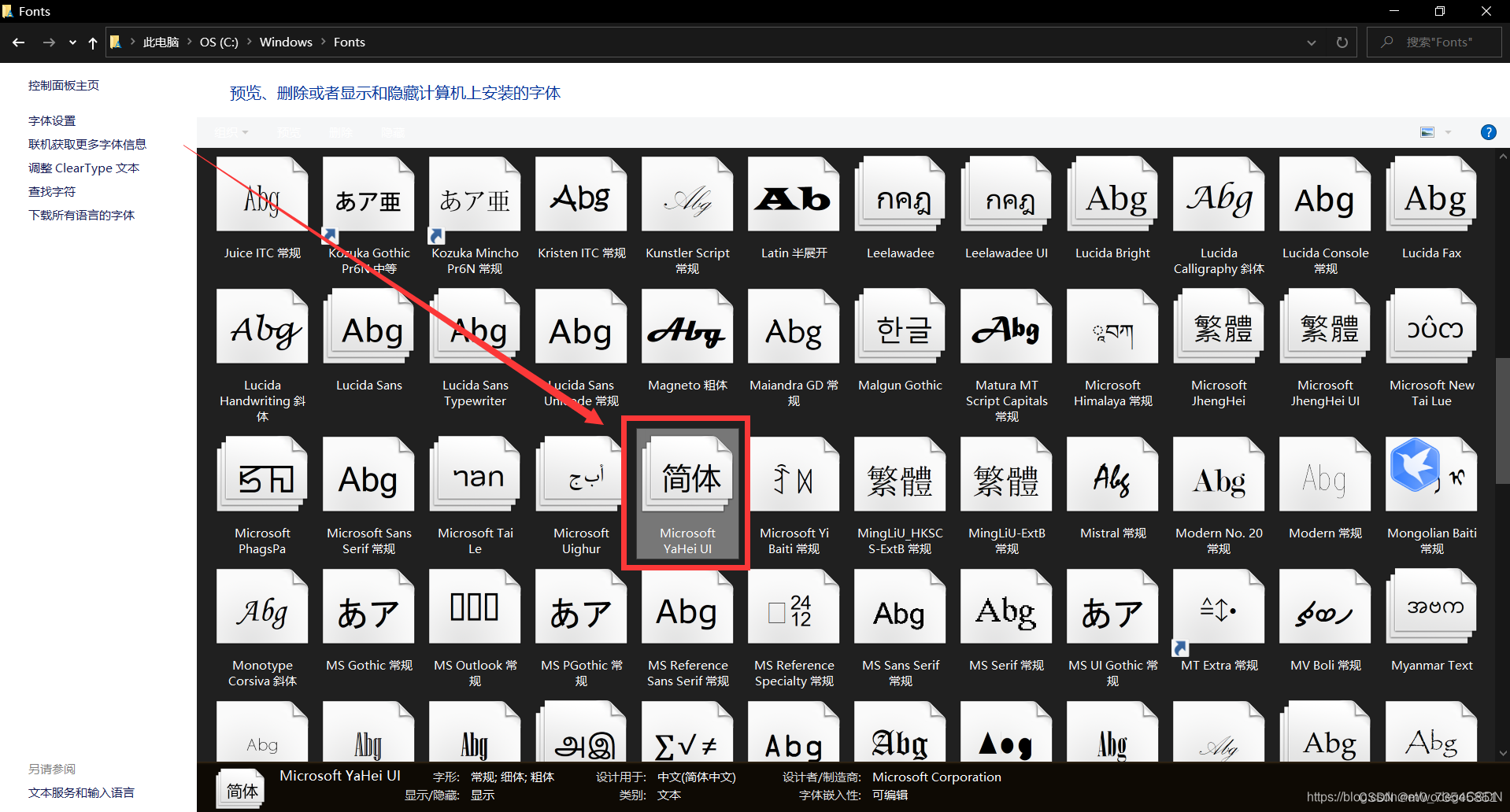
作为显示效果(当然也可以选择自己喜欢的字体样式)
右键复制,并将该字体文件与代码存放在同一目录下(或在字体文件名前增加完整路径),
将此文字文件命名为"msyh.ttf"

代码编写
import easyocr
import cv2
import jieba
import wordcloud
import imageio
reader = easyocr.Reader(['ch_sim', 'en'])#这里表示识别的语言中文和英文
img = cv2.imread('')#输入需要进行文字识别的图片
result = reader.readtext(img)
f=open('output.txt',"w")
for i in result:
word=i[1]
f.write(word)
f.close()#这几行表示将识别的结果保存到output文件
jieba.setLogLevel(jieba.logging.INFO)
with open('output.txt',encoding='gbk') as f:
txt = f.read()#打开文件
ls=jieba.lcut(txt)
text="".join(ls)
w = wordcloud.WordCloud(width=2000,height=1400,font_path="msyh.ttc")
w.generate(text)
w.to_file(r'C:\Users\...\PycharmProjects\python_OCR\pic6.png')
运行代码前需在项目里新建一个文本用于储存识别结果,如这里的output.txt
可能的问题

这里计算机提示库被循环引用,而且找不到相应的函数,说明改文件名与库名重了(这里右上角看出来我用了wordcloud.py这是库的名字😭)
以上就是全部的教程了,当然词云图可以再做相应的美化,这就要再研究库里的其他函数,再后面的文章会继续更新。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









