






这篇文章聚焦于使用深度强化学习(DRL)开发AI代理,以处理多人在线战术竞技场(MOBA)1v1游戏中复杂的动作控制,具体以《王者荣耀》游戏为例。作者提出了一个可扩展的DRL框架,并结合了几种新颖的策略来有效训练AI代理。这些策略包括:
- 控制依赖解耦:将复杂的控制任务分解为更简单、独立的部分,以提高训练效率。
- 动作掩码:基于游戏知识应用约束,引导训练中的高效探索。
- 目标注意机制:实现注意力机制,帮助AI代理更好地进行目标选择决策。
- 双重剪辑PPO:改进版的近端策略优化(PPO)算法,确保在大规模环境中稳定、高效的学习。
作者设计的系统允许可扩展的离线策略训练和高效的探索,最终使AI代理在《王者荣耀》的1v1模式中超越了人类职业玩家。广泛的实验展示了该AI击败顶级人类玩家的能力,体现了所提出的框架和算法的有效性。
Preliminaries
Notation
在文章的 Preliminary 部分的 Notation 里,作者使用了马尔可夫决策过程(Markov Decision Process, MDP)的标准术语来描述MOBA 1v1游戏的环境和强化学习问题。以下是几个主要参数的含义:
-
S (State Space, 状态空间):表示整个游戏中的状态集合。它包含了游戏的所有可能状态,例如英雄的位置、技能冷却时间、生命值等。这是代理在任何时刻可能处于的所有状态的集合。
-
O (Observable State Space, 可观测状态空间):这是代理可以观察到的状态集合。由于MOBA游戏通常是部分可观测的(即,代理不能看到整个游戏的所有信息,例如敌人躲藏在地图的某些地方),所以可观测状态空间是代理在游戏中可以感知到的信息子集。
-
A (Action Space, 动作空间):代理在每个状态下可以采取的动作集合。在MOBA游戏中,动作可以包括移动、攻击、使用技能等。
-
P (State Transition Probability, 状态转移概率):定义了从一个状态转移到另一个状态的概率。形式上是一个函数 ( P : S × A → S (P: S \times A \to S (P:S×A→S),表示在执行了某个动作 ( a ∈ A (a \in A (a∈A) 后,从当前状态 ( s ∈ S (s \in S (s∈S) 转移到下一个状态的概率。
-
r (Reward Function, 奖励函数):定义了每个状态和动作对所获得的即时奖励。形式上是一个函数 ( r : S × A → R (r: S \times A \to R (r:S×A→R),表示在状态 ( s (s (s) 下执行动作 ( a (a (a) 所获得的奖励值 ( r (r (r)。奖励函数用于指导代理学习如何采取能够获得长期收益的策略。
-
ρ₀ (Initial State Distribution, 初始状态分布):表示游戏开始时状态的概率分布。这个函数 ( ρ 0 : S → R (ρ₀: S \to R (ρ0:S→R) 用于描述代理从哪个状态开始游戏。
-
γ (Discount Factor, 折扣因子):介于 0 到 1 之间的一个常数,表示未来奖励的折扣因子。较大的 γ 值表示代理更加关注长期的回报,而较小的 γ 值表示代理更加关注短期的回报。
-
π (Policy, 策略):这是一个概率分布,表示在某个可观测状态下,代理采取某个动作的概率。形式上是一个函数 ( π : O × A → [ 0 , 1 ] (π: O \times A \to [0, 1] (π:O×A→[0,1]),用来决定在给定状态下采取不同动作的概率。
代理的目标是通过不断地在游戏中行动,最大化累积的折扣奖励 ( E [ ∑ t = 0 T γ t r ( s t , a t ) ] (E[\sum_{t=0}^{T} \gamma^t r(s_t, a_t)] (E[∑t=0Tγtr(st,at)]),其中 ( T (T (T) 表示时间步长。
Related Work
在文章的 Related Work(相关工作) 部分,作者回顾了多智能体控制和强化学习领域的相关研究,主要分为合作环境和竞争环境两大类。文章的研究属于竞争环境的多智能体控制。以下是该部分的主要内容:
1. 合作环境中的多智能体控制
在合作环境中,多智能体系统的目标是合作完成某项任务。文章提到了一些相关研究:
- 合作的强化学习综述:Panait 和 Luke (2005) 提出了一篇关于合作多智能体学习的综述。
- 解决谜题的多智能体合作:Foerster 等人 (2016) 研究了使用循环 Q 网络来解决谜题的多智能体合作问题。
- 3D 第一人称射击游戏的多智能体合作:Jaderberg 等人 (2019) 和 Lample 与 Chaplot (2017) 研究了多智能体合作在三维射击游戏中的应用。
- MOBA 5v5 游戏中的宏观策略模型:Wu 等人 (2018) 开发了一个用于 MOBA 5v5 游戏的多智能体宏观策略模型,这些模型通常基于监督学习。
2. 竞争环境中的多智能体控制
在竞争环境中,多智能体系统的目标是相互竞争。1v1 对战游戏是这类研究的典型测试平台。以下是几个主要的研究成果:
- AlphaGo 和强化学习:Silver 等人 (2016) 结合了监督学习和强化学习,构建了一个可以在围棋比赛中击败人类顶尖棋手的 AI 系统。之后,这种方法也被用于国际象棋和将棋等游戏的 1v1 对战中。
- Atari 游戏中的强化学习:Mnih 等人 (2015) 成功地将深度 Q 网络应用于 Atari 系列游戏,其中包含了单人游戏和 1v1 对战的 Pong 游戏。
- 对手建模:He 等人 (2016) 使用深度 Q 学习进行了对手建模,测试平台包括模拟足球游戏和问答游戏。
- Pong 1v1 游戏中的深度 Q 学习:Tampuu 等人 (2017) 使用深度 Q 学习训练 Pong 1v1 游戏中的智能体。
- MuJoCo 环境中的 1v1 对战:Bansal 等人 (2017) 创建了四个基于 MuJoCo 环境的 1v1 游戏,以分析多智能体竞争中涌现的复杂性。
3. MOBA 1v1 游戏中的强化学习
文章重点讨论了 MOBA 1v1 游戏中的复杂竞争控制问题,并指出相较于之前的 1v1 游戏,MOBA 1v1 游戏的动作和状态空间都要复杂得多。例如,Jiang 等人 (2018) 提出了基于蒙特卡洛树搜索 (MCTS) 的强化学习方法,用于玩《王者荣耀》中的 1v1 游戏。另外,OpenAI 公布了可以在 Dota 2(另一款流行的 MOBA 游戏)中击败职业玩家的 AI 系统,但该技术细节尚未公开。
相较于上述工作,本文的研究重点在于 MOBA 1v1 游戏中的动作控制问题(电子竞技中称为“微操”)。文中介绍的 AI 系统不仅能够在《王者荣耀》1v1 模式下进行完整的游戏(直到摧毁基地),而且其方法的鲁棒性和可扩展性经过了多种英雄类型的测试。
4. 与《星际争霸》1v1 游戏的对比
作者提到,《星际争霸》1v1 游戏已经被大量研究,特别是多智能体战略控制问题(Ontañón et al., 2013)。相比之下,MOBA 1v1 游戏的复杂性主要体现在英雄的动作控制上,而《星际争霸》1v1 更多关注的是同时控制多个游戏单位的战略。
通过这部分的讨论,文章表明,尽管多智能体竞争的研究已经取得了显著进展,尤其是在传统的1v1游戏和RTS游戏中,MOBA 1v1 游戏由于其复杂的动作控制需求,依然是一个非常具有挑战性的研究领域。
System Design
文章中的 System Design(系统设计) 部分详细描述了为MOBA 1v1游戏设计的深度强化学习框架,用于解决复杂的动作控制问题。这个系统设计是高度可扩展的,并且能够支持大规模的训练。以下是该部分的核心内容和模块解释:
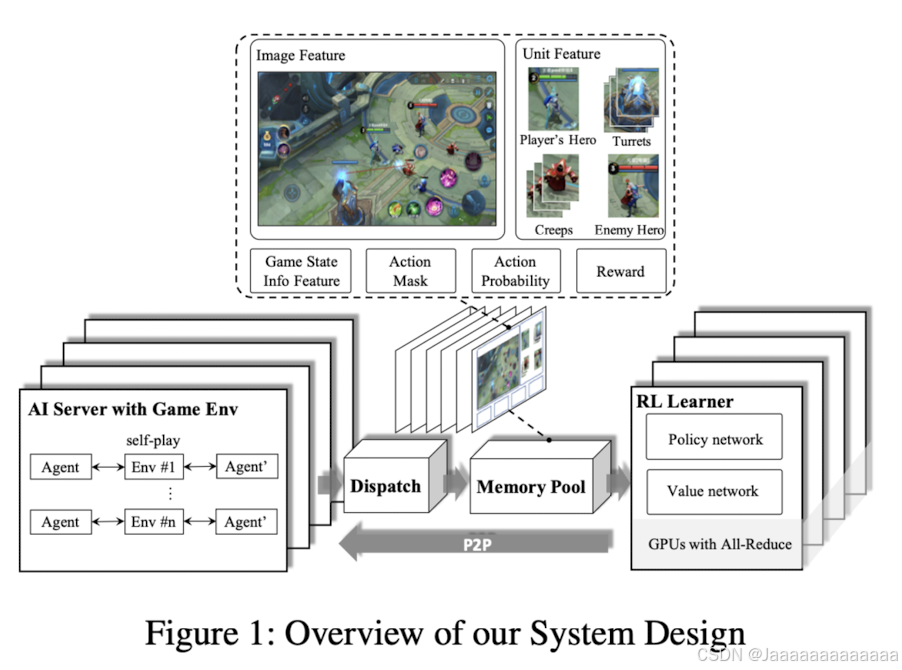
1. 系统的总体结构
系统设计由四个主要模块组成:
- Reinforcement Learning (RL) Learner,强化学习学习器
- AI Server,AI服务器
- Dispatch Module,调度模块
- Memory Pool,内存池
这些模块相互解耦,形成了一个可扩展的架构,可以灵活配置,从而允许研究人员专注于算法的开发和环境的逻辑设计。该设计适用于多智能体竞争问题。
2. AI Server(AI服务器)
AI服务器的主要功能是管理AI模型与游戏环境的交互:
- 自我对弈:AI服务器生成游戏回合,通过自我对弈的方式生成训练数据,使用“镜像策略”来进行对弈(参考 Silver 等人,2017)。游戏中的对手策略也是通过类似的机制生成的(参考 Bansal 等人,2017)。
- 动作采样:AI模型基于从游戏状态提取的特征,通过 softmax 采样动作概率进行探索,采样的动作随后被发送到游戏核心进行执行。执行完后,游戏核心返回奖励值和下一个状态。
- 绑定CPU核心:每个AI服务器会绑定一个CPU核心,游戏逻辑的推导在CPU上运行,同时模型的推理也在CPU上运行,以降低IO成本。为了生成高效的回合,作者开发了一个CPU版本的快速推理库——FeatherCNN,这可以将训练模型转化为用于推理的自定义格式。
3. Dispatch Module(调度模块)
调度模块的主要功能是数据的收集和传输。具体来说,它执行以下任务:
- 收集数据:从AI服务器收集数据样本(包括奖励、特征、动作概率等)。
- 压缩和打包:将这些样本首先进行压缩和打包,然后发送到内存池中进行存储。
4. Memory Pool(内存池)
内存池是数据存储模块,采用内存高效的环形队列实现,支持多样长度的数据存储和基于生成时间的采样。
5. RL Learner(强化学习学习器)
RL学习器是一个分布式训练环境,其主要任务是通过大批量的数据加速策略的更新:
- 数据并行化:多个RL学习器可以并行获取内存池中的数据,并通过环形 allreduce 算法来平均化梯度(参考 Sergeev 和 Balso,2018)。
- 共享内存通信:为了减少IO开销,RL学习器通过共享内存与内存池通信,而不是通过套接字,这样可以提升2到3倍的速度。
- 快速模型同步:训练好的模型会通过点对点方式快速同步到AI服务器中。
6. 系统的松耦合和高并发设计
整个系统设计的核心是经验生成与参数学习的解耦,这种机制使得AI服务器和RL学习器的可扩展性和吞吐量非常高。模型更新是通过从主RL学习器到AI服务器的点对点同步完成的,避免了学习器与演员之间的通信瓶颈。
相比其他系统设计,如IMPALA(Espeholt 等人,2018),该系统的不同之处在于参数分布和通信方式。在IMPALA中,参数是分布在学习器中的,演员从所有学习器中并行检索参数,而本系统使用主学习器的点对点同步方式,使得经验生成与学习过程更加独立。
7. 可扩展性
该系统能够轻松扩展到数百万个CPU核心和数千个GPU,同时提供了高吞吐量和大规模训练的能力。这一设计大大提高了在复杂MOBA游戏中的多智能体竞争问题的训练效率。
系统设计的目标是为MOBA 1v1游戏中的复杂控制任务提供一个高效、可扩展且松耦合的强化学习框架,从而加快训练速度并提高AI模型的性能。
Algorithm Design
在文章的 Algorithm Design(算法设计) 部分,作者提出了一种新颖的深度强化学习(DRL)算法框架,用于处理MOBA 1v1游戏中的复杂动作控制问题。该部分介绍了多种策略和优化方法,下面我将详细解释每一个步骤的内容。
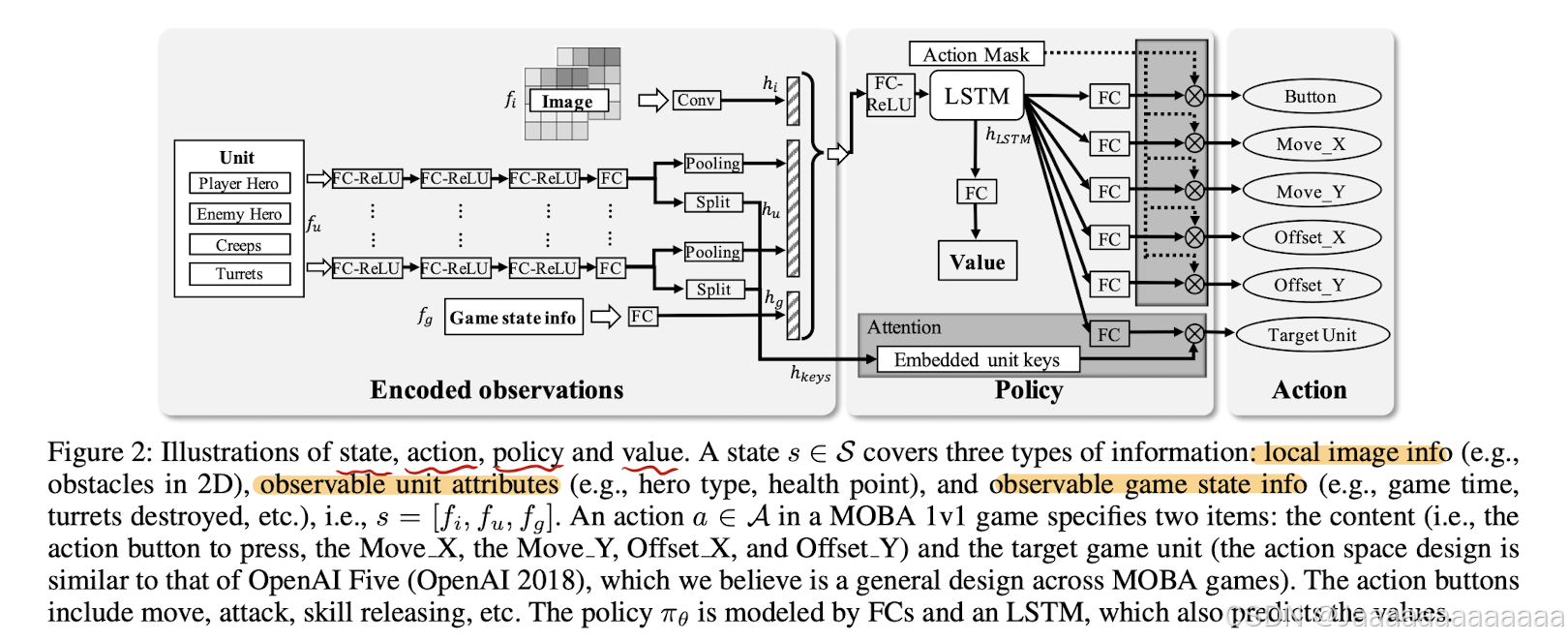
1. 目标注意机制(Target Attention Mechanism)
在MOBA游戏的战斗中,选择正确的攻击目标至关重要,因此作者设计了一种目标注意机制,用于帮助AI代理在战斗中选择目标。
- 注意机制的设计:在神经网络中,目标选择的过程通过注意力机制实现。网络将状态信息编码为特征向量,并通过全连接层输出一个“查询向量”(query),这个查询向量用于与游戏中的多个目标(如敌方英雄、小兵、炮塔等)的编码“键向量”(key vectors)进行点积计算,得出每个目标的注意力权重。最终通过 softmax 操作生成目标选择的概率分布,AI代理根据该概率分布选择攻击目标。
- 作用:这种机制允许AI根据战斗局势的变化,动态调整目标选择策略,从而在游戏中做出更加智能的决策。
公式为:
[
p
(
t
∣
a
)
=
S
o
f
t
m
a
x
(
F
C
(
h
L
S
T
M
)
⋅
h
k
e
y
s
T
)
]
[ p(t|a) = Softmax(FC(h_{LSTM}) \cdot h_{keys}^{T}) ]
[p(t∣a)=Softmax(FC(hLSTM)⋅hkeysT)]
其中
(
p
(
t
∣
a
)
(p(t|a)
(p(t∣a)) 是目标选择的概率分布,
(
F
C
(
h
L
S
T
M
)
(FC(h_{LSTM})
(FC(hLSTM)) 是从状态编码
(
h
L
S
T
M
(h_{LSTM}
(hLSTM) 生成的查询向量,
(
h
k
e
y
s
(h_{keys}
(hkeys) 是所有目标的编码堆栈。
2. 动作依赖解耦(Decoupling of Control Dependencies)
MOBA游戏中的动作往往具有多个维度的依赖关系,例如,英雄的技能释放方向、移动方向、技能类型等,这些维度之间的关联性使得策略学习变得更加复杂。因此,作者提出了“动作依赖解耦”的方法,将复杂的动作表示解耦为多个独立的标签。
- 解耦的做法:将复杂动作的每个维度(如技能方向、技能选择)独立处理。通过这种方式,可以简化策略网络的结构,并通过多个独立的通道输出动作的概率分布。
- 作用:解耦动作后,策略网络不需要显式建模不同标签之间的相关性,训练过程变得更加高效,同时增加了动作的多样性,鼓励更多的探索。
解耦前的PPO目标函数:
[
max
θ
E
^
s
,
a
∼
π
θ
old
[
π
θ
(
a
t
∣
s
t
)
π
θ
old
(
a
t
∣
s
t
)
A
^
t
]
]
[ \max_\theta \hat{E}_{s,a \sim \pi_{\theta_{\text{old}}}} \left[ \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} \hat{A}_t \right] ]
[θmaxE^s,a∼πθold[πθold(at∣st)πθ(at∣st)A^t]]
解耦后的目标函数变为:
[
max
θ
∑
i
=
0
N
a
−
1
E
^
s
,
a
∼
π
θ
old
[
π
θ
(
a
t
(
i
)
∣
s
t
)
π
θ
old
(
a
t
(
i
)
∣
s
t
)
A
^
t
]
]
[ \max_\theta \sum_{i=0}^{N_a - 1} \hat{E}_{s,a \sim \pi_{\theta_{\text{old}}}} \left[ \frac{\pi_\theta(a_t^{(i)}|s_t)}{\pi_{\theta_{\text{old}}}(a_t^{(i)}|s_t)} \hat{A}_t \right] ]
[θmaxi=0∑Na−1E^s,a∼πθold[πθold(at(i)∣st)πθ(at(i)∣st)A^t]]
其中每个
(
a
t
(
i
)
(a_t^{(i)}
(at(i)) 表示解耦后的动作标签。
3. 动作掩码(Action Masking)
由于MOBA游戏的动作空间非常庞大,随机探索可能会导致低效的训练。为此,作者引入了动作掩码,通过提前引入游戏中的一些约束来裁剪动作空间,减少不必要的探索。
- 动作掩码的作用:在动作输出层使用动作掩码,避免探索不合理的动作。例如:
- 地图上物理上不可移动的区域,如障碍物。
- 在冷却时间内不能释放的技能。
- 被敌方英雄控制时不能执行的动作。
- 英雄或物品特定的限制(例如,某些英雄不能使用特定物品)。
- 效果:动作掩码引导AI代理避免无效的探索,加速了训练过程,并提高了AI代理在实际游戏中的表现。
4. 双重剪辑的PPO算法(Dual-clip PPO)
标准的PPO算法通过剪辑比率 ( r t ( θ ) (r_t(\theta) (rt(θ)) 来避免策略发生过大的偏移。然而,在大规模离线策略训练中,采样的数据可能来自各种不同的策略源,而这些策略与当前策略可能有显著差异。为了解决这一问题,作者提出了双重剪辑的PPO算法(Dual-clip PPO)。
- 标准PPO中的剪辑:为了避免策略变化过大,标准PPO在优化目标中引入了比率剪辑:
[ L CLIP ( θ ) = E ^ t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] ] [ L_{\text{CLIP}}(\theta) = \hat{E}_t \left[ \min \left( r_t(\theta) \hat{A}_t, \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A}_t \right) \right] ] [LCLIP(θ)=E^t[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]]
其中 (r_t(\theta)) 表示新旧策略的概率比。 - 双重剪辑的改进:当
(
A
t
<
0
)
(A_t < 0)
(At<0) 时,标准PPO可能无法有效限制过大的偏移。为此,双重剪辑PPO在这种情况下引入了下界剪辑:
[ E ^ t [ max ( min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) , c A ^ t ) ] ] [ \hat{E}_t \left[ \max \left( \min \left( r_t(\theta) \hat{A}_t, \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A}_t \right), c \hat{A}_t \right) \right] ] [E^t[max(min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t),cA^t)]]
其中 ( c (c (c) 是一个常量,用于限制策略的过大偏移。 - 效果:双重剪辑PPO适合大规模的离线训练,能够确保在多样化的数据源下策略的稳定收敛。

5. 长短期记忆网络(LSTM)用于技能连招
MOBA游戏中的技能连招(即一系列技能的顺序释放)是决定战斗胜负的关键因素之一。因此,作者使用长短期记忆网络(LSTM)来学习并执行复杂的技能连招。
- LSTM的作用:LSTM网络可以记忆一段时间内的状态变化,帮助AI在游戏中理解技能的释放时机和组合,以产生连续且高效的伤害输出。
- 效果:LSTM的引入帮助AI在执行复杂的技能连招时表现得更加智能,尤其是在多技能英雄(如法师和战士)中表现尤为突出。
6. 其他优化措施
- 全回合训练(Full Rollouts):MOBA游戏中的训练使用了全回合训练,即一局游戏从开始到结束作为一个完整的训练单元。这有助于AI更好地理解长期目标,如摧毁敌方基地。
- 零起点训练(Zero-start):AI代理从游戏的初始状态开始训练,而不是从游戏的中途或某个固定的状态开始。这种方式可以增强AI对整局游戏的掌控能力。
总结:
- 目标注意机制 提升了AI在战斗中的目标选择能力;
- 动作依赖解耦 和 动作掩码 简化了训练过程,并提升了探索效率;
- 双重剪辑PPO 确保了大规模分布式训练中的策略收敛;
- LSTM 网络提升了技能连招的执行效果。
这些算法设计的结合,使得AI在MOBA 1v1游戏中的复杂控制任务上表现出色,能够击败顶尖的人类玩家。

















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









