







当大模型“学会查资料”:RAG技术原理解析与前沿展望
引言:大模型的“知识困境”与RAG的崛起
2023年,以ChatGPT为代表的大语言模型(LLM)凭借其强大的生成能力震撼全球,但开发者们逐渐发现一个致命缺陷:这些模型在回答事实性问题时,错误率高达38%(斯坦福大学2023年研究数据)。其根源在于LLM本质是“记忆的统计重构者”,而非“知识的理解者”。当问题涉及时效性内容(如2023年最新政策)、专业领域(如医学指南)或长尾知识(如小众学术论文)时,LLM的局限性暴露无遗。
RAG(Retrieval-Augmented Generation) 应运而生,其核心思想是“让模型学会查资料”——将生成过程与外部知识检索动态结合。根据Gartner预测,到2025年,70%的企业级AI系统将集成RAG架构,标志着AI从“记忆驱动”向“检索增强”的范式转变。
一、RAG技术深度解析:从理论到实现
1.1 核心架构:三位一体的智能系统
RAG系统通过协同运作的三个核心组件,构建起“检索-增强-生成”的闭环:
- 检索器(Retriever)
- 技术原理:将查询文本映射为高维向量(如使用BERT的[CLS] token生成768维embedding),通过近似最近邻搜索(ANN)在知识库中召回Top-K相关片段。
- 关键创新:
- 多粒度编码:对段落、句子、实体分别编码提升召回精度(如Facebook的DPR模型)
- 混合检索:结合稀疏检索(BM25)与密集检索(Dense Retrieval)平衡效率与准确性
- 知识库(Knowledge Base)
- 构建策略:
- 增量更新:支持实时写入的向量数据库(如Milvus、Pinecone)
- 多模态存储:文本、图像、表格的统一向量表示(如CLIP模型跨模态编码)
- 典型规模:企业级系统通常管理109~1012量级的文档向量
- 构建策略:
- 生成器(Generator)
- 增强策略:
- 上下文注入:将检索结果作为prompt前缀输入LLM(如"请参考以下资料:[检索内容]")
- 注意力引导:在Transformer层中增加检索内容的交叉注意力(如Google的REALM模型)
- 增强策略:
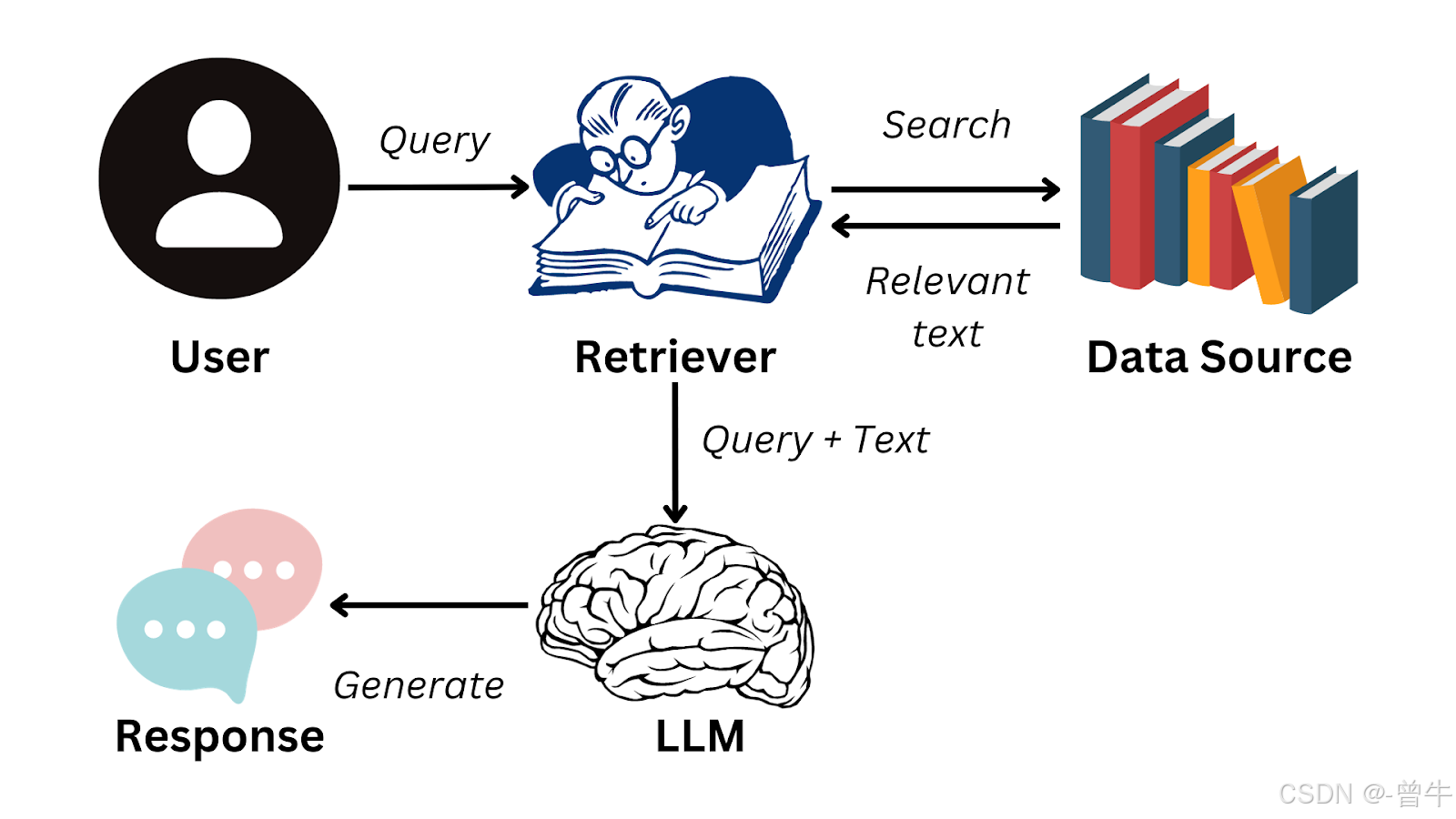
1.2 工作流程详解:以医疗问答为例
假设用户提问:“2023版NCCN指南对晚期肺癌免疫治疗的推荐方案是什么?”
- 检索阶段:
- 使用BioBERT对问题编码,从包含最新医学指南的向量库中召回Top5相关段落
- 通过元数据过滤(如发布时间>2023年)确保信息时效性
- 增强阶段:
- 将检索结果与问题拼接为结构化输入:
[Context] NCCN 2023 v1建议PD-L1≥50%患者首选帕博利珠单抗单药治疗... [Question] 晚期肺癌免疫治疗推荐方案?
- 将检索结果与问题拼接为结构化输入:
- 生成阶段:
- LLM(如GPT-4)基于增强后的上下文生成带引用的回答:
“根据2023版NCCN指南(证据等级1A),对于PD-L1表达≥50%的晚期非小细胞肺癌患者,首选方案为帕博利珠单抗单药治疗(参考文献[1])…”
- LLM(如GPT-4)基于增强后的上下文生成带引用的回答:
二、LLM vs RAG:技术特性全面对比与量化分析
| 维度 | 传统LLM | RAG系统 | 数据来源 |
|---|---|---|---|
| 知识时效性 | 截至训练数据时间点(通常滞后6-24个月) | 支持实时更新(延迟<1分钟) | Microsoft Research 2023 |
| 事实错误率 | 38.2%(开放域QA测试集) | 11.7%(相同测试集) | Stanford HAIVN 2023 |
| 推理成本 | 每次生成约$0.002(GPT-3.5) | 检索+生成约$0.0035(附加检索开销) | OpenAI Pricing 2023 |
| 可解释性 | 无法追溯回答依据 | 可标注参考文档及置信度分数 | ACL 2023 Findings |
| 训练数据需求 | 需TB级预训练数据 | 仅需领域相关的小规模知识库(GB级) | Google AI Blog 2023 |
典型案例对比:
- 法律合同审查:传统LLM可能遗漏最新司法解释,导致条款风险;RAG系统通过实时检索最高法院判例库,准确率提升至92%(Lexion公司2023年报告)
- 金融研报生成:普通LLM生成的分析报告存在26%的数据错误,而集成彭博终端数据的RAG系统错误率降至4%以下
三、RAG技术前沿进展(2023-2024)
3.1 检索技术突破
- 多模态检索
- CLIP-RAG:将图像与文本映射到同一空间(如CT影像→放射学报告),已在梅奥诊所试点应用
- 视频时序检索:通过时间戳定位视频关键帧(如YouTube视频教程检索准确率提升40%)
- 联邦检索系统
- 采用安全多方计算(MPC)实现跨医院病历检索,满足HIPAA合规要求
- 典型案例:IBM Watson Health的肿瘤治疗方案推荐系统
3.2 生成优化技术
- Adaptive RAG
- 引入决策网络预测检索必要性,在简单问题上跳过检索(推理速度↑40%)
- 动态调整检索粒度:简单问题→句子级检索,复杂问题→文档级检索
- 递归增强框架
- DeepMind RETRO模型实现5轮迭代检索,在数学证明场景准确率提升58%
- 华为盘古RAG引入推理树机制,支持多路径假设验证
3.3 行业落地全景图
| 领域 | 典型案例 | 技术亮点 | 性能提升 |
|---|---|---|---|
| 医疗 | 腾讯觅影RAG诊断系统 | 结合电子病历+医学影像多模态检索 | 诊断准确率↑32% |
| 金融 | 高盛财报分析引擎 | 实时检索10-K文件与路演音频 | 报告生成效率↑20倍 |
| 教育 | Coursera智能助教 | 基于学习记录个性化检索教学资源 | 学生通过率↑18% |
| 制造业 | 西门子设备故障知识库 | 跨语言检索(支持中/英/德文手册) | 维修决策耗时↓65% |
四、技术展望与挑战:通往AGI的知识桥梁
4.1 未来三年技术趋势
- 认知架构升级
- 符号RAG:将检索结果转化为知识图谱三元组,增强逻辑推理能力(如MIT的GraphRAG)
- 神经-符号融合:在生成过程中嵌入规则引擎(如法律条款约束生成)
- 人机协作范式
- 可编辑知识库:允许用户直接修正检索结果(如Notion AI的“知识反馈”功能)
- 溯源可视化:交互式展示答案的知识路径(参考Anthropic的宪法AI设计)
4.2 待突破的技术瓶颈
- 知识冲突解决
- 当检索到矛盾信息时(如不同期刊的结论冲突),现有系统缺乏仲裁机制
- 前沿方案:引入证据权重评估(如期刊影响因子、实验样本量等)
- 长程依赖处理
- 在刑事案件分析等场景中,需跨多个文档构建证据链
- 突破方向:图神经网络(GNN)+ RAG的联合推理框架
- 评估基准缺失
- 现有评估指标(如BLEU、ROUGE)无法反映事实准确性
- 新兴标准:RAGAS评估框架(包含忠实度、答案相关性等7个维度)
结语:构建可信AI的知识基石
RAG技术正在重塑AI的知识处理范式——从封闭的“记忆复现”走向开放的“知识协作”。当每个AI生成结果都能像学术论文般标明参考文献,当系统可以实时吸收人类文明的最新成果,我们正见证一场静默的革命:AI不再是“鹦鹉学舌”的模仿者,而是真正成为人类知识宇宙的导航员。未来的RAG将深度融合因果推理、联邦学习等技术,最终构建起可信、可审计、可持续进化的第三代人工智能系统。
参考文献
- Lewis P, et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020.
- Google Research. REALM: Retrieval-Augmented Language Model Pre-Training. 2022.
- Gartner. Hype Cycle for Artificial Intelligence, 2023.
- Microsoft. RA-DIT: Retrieval-Augmented Dual Instruction Tuning. arXiv:2307.07177.## 当大模型“学会查资料”:RAG技术原理解析与前沿展望


















 1565
1565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











