







一、RAG简介
大型语言模型(LLM)已经取得了显著的成功,尽管它们仍然面临重大的限制,特别是在特定领域或知识密集型任务中,尤其是在处理超出其训练数据或需要当前信息的查询时,常会产生“幻觉”现象。为了克服这些挑战,检索增强生成(RAG)通过从外部知识库检索相关文档chunk并进行语义相似度计算,增强了LLM的功能。通过引用外部知识,RAG有效地减少了生成事实不正确内容的问题。RAG目前是基于LLM系统中最受欢迎的架构,有许多产品基于RAG构建,使RAG成为推动聊天机器人发展和增强LLM在现实世界应用适用性的关键技术。
二、RAG架构
2.1 RAG实现过程
RAG在问答系统中的一个典型应用主要包括三个步骤:
- Indexing(索引):将文档分割成chunk,编码成向量,并存储在向量数据库中。
- Retrieval(检索):根据语义相似度检索与问题最相关的前k个chunk。
- Generation(生成):将原始问题和检索到的chunk一起输入到LLM中,生成最终答案。
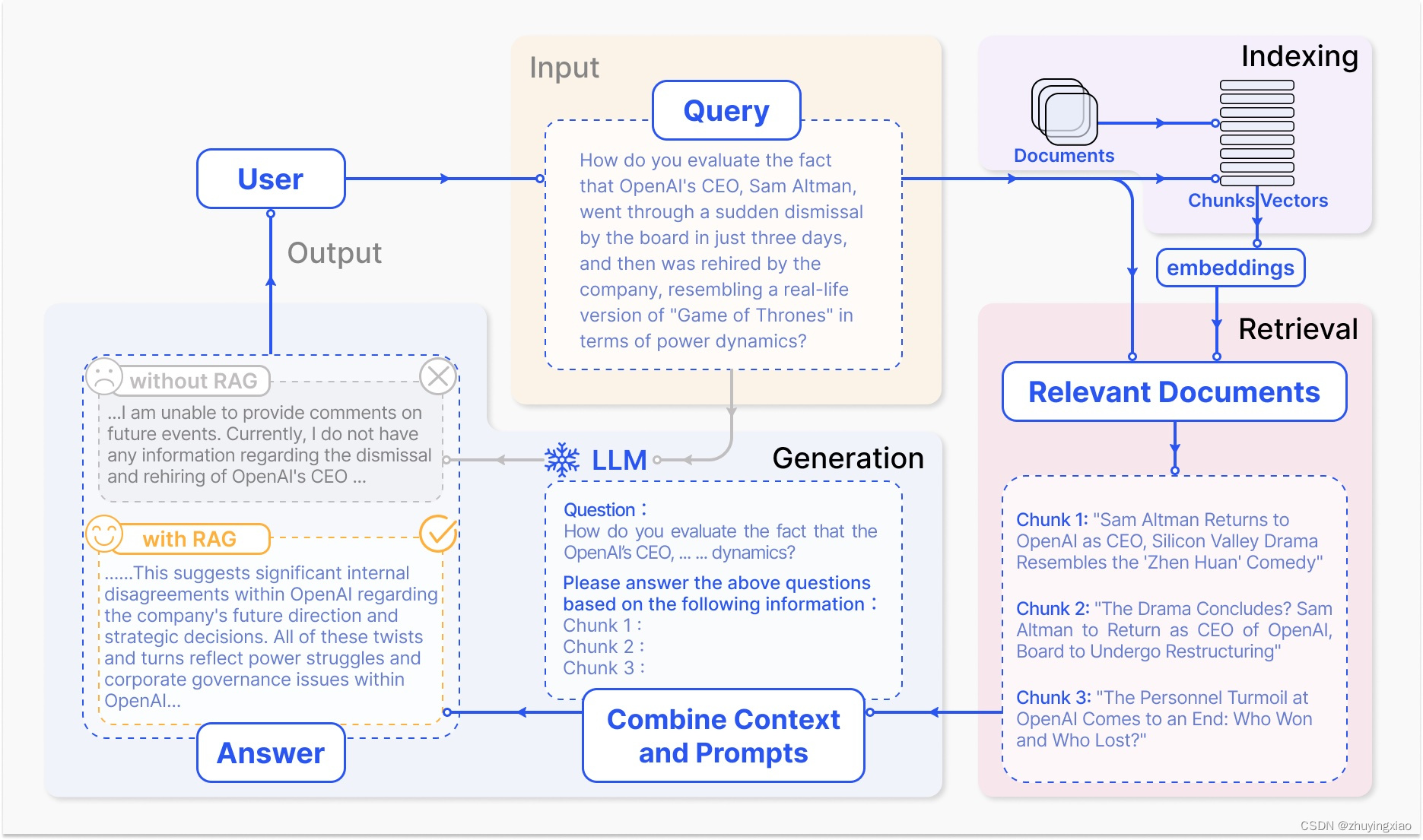
2.2 RAG在线检索架构
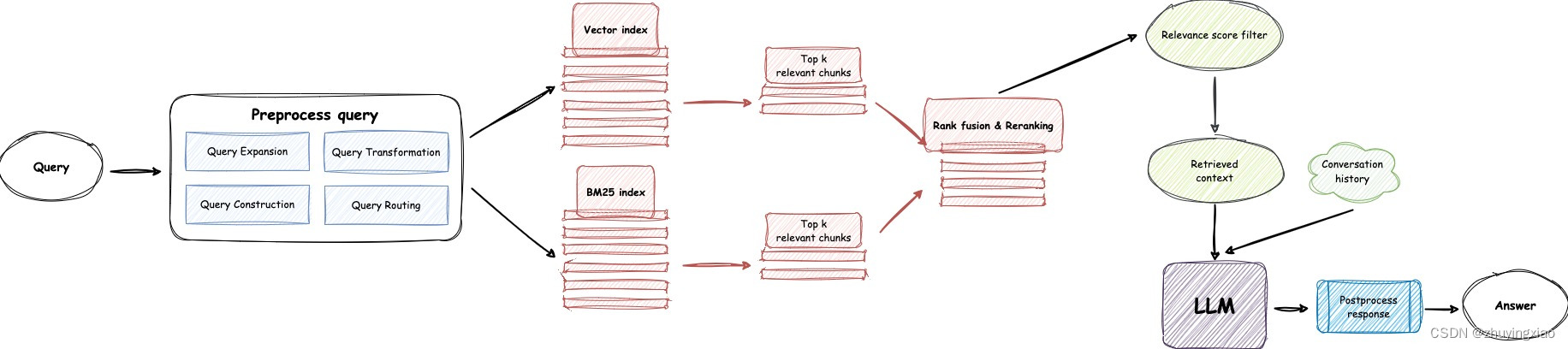
三、RAG流程
接下来,我们将深入探讨RAG各个流程,并为RAG构建技术路线图。
3.1 索引
索引是将文本分解成可管理的chunk的过程,是组织系统的关键步骤,面临三个主要挑战:
- 不完整的内容表示:chunk的语义信息受到分割方法的影响,导致在更长的上下文中重要信息的丢失或隐藏。
- 不准确的chunk相似性搜索:随着数据量的增加,检索中的噪声增多,导致频繁与错误数据匹配,使检索系统变得脆弱和不可靠。
- 不明确的引用轨迹:检索到的chunk可能来源于任何文档,缺乏引用路径,可能导致存在来自多个不同文档的chunk,尽管这些chunk在语义上相似,但包含的内容完全不同的主题。
3.1.1 Chunking
Transformer模型有固定的输入序列长度,即使输入上下文窗口很大,一个句子或几个句子的向量也比几页文本的平均向量更能代表它们的语义意义。所以我们需要对数据进行分块,将初始文档分割成一定大小的chunk,同时不丢失它们的意义(将文本分割成句子或段落,而不是将一个句子分成两部分)。
有多种文本切分策略能够完成这项任务,我们在实践中采用了以下3种策略:
- 直接分段:将文本按照一定的规则进行分段处理后,转成可以进行语义搜索的格式。这里不需要调用模型进行额外处理,成本低,适合绝大多数应用场景。
- 生成问答对:根据一定的规则,将文本拆成一段主题文本,调用LLM为该段主题文本生成问答对。这种处理方式有非常高的检索精度,但是会丢失部分文本细节,需要特别留意。
- 增强信息:通过子索引以及调用LLM生成相关问题和摘要,来增加chunk的语义丰富度,更加有利于后面的检索。不过需要消耗更多的存储空间和增加LLM调用开销。
chunk的大小是一个需要重点考虑的参数,它取决于我们使用的Embedding模型及其token的容量。标准的Transformer编码器模型,如基于BERT的Sentence Transformer最多处理512个token,而OpenAI的text-embedding-3-small能够处理更长的序列(8191个token)。
为了给LLM提供足够的上下文以进行推理,同时给搜索提供足够具体的文本嵌入,我们需要一些折衷策略。较大的chunk可以捕获更多的上下文,但它们也会产生更多的噪音,需要更长的处理时间和更高的成本。而较小的chunk可能无法完全传达必要的上下文,但它们的噪音较少。
以网页https://www.openim.io/en的文本内容为输入,按照上面3种策略进行文本分割。
-
直接分段:
切分后的chunk信息,总共
10个chunk:
def split_long_section(section, max_length=1300): lines = section.split('\n') current_section = "" result = [] for line in lines: # Add 1 for newline character when checking the length if len(current_section) + len(line) + 1 > max_length: if current_section: result.append(current_section) current_section = line # Start a new paragraph else: # If a single line exceeds max length, treat it as its own paragraph result.append(line) else: if current_section: current_section += '\n' + line else: current_section = line -
生成问答对:
切分后的chunk信息,总共
28个chunk,每个chunk包含一对问答: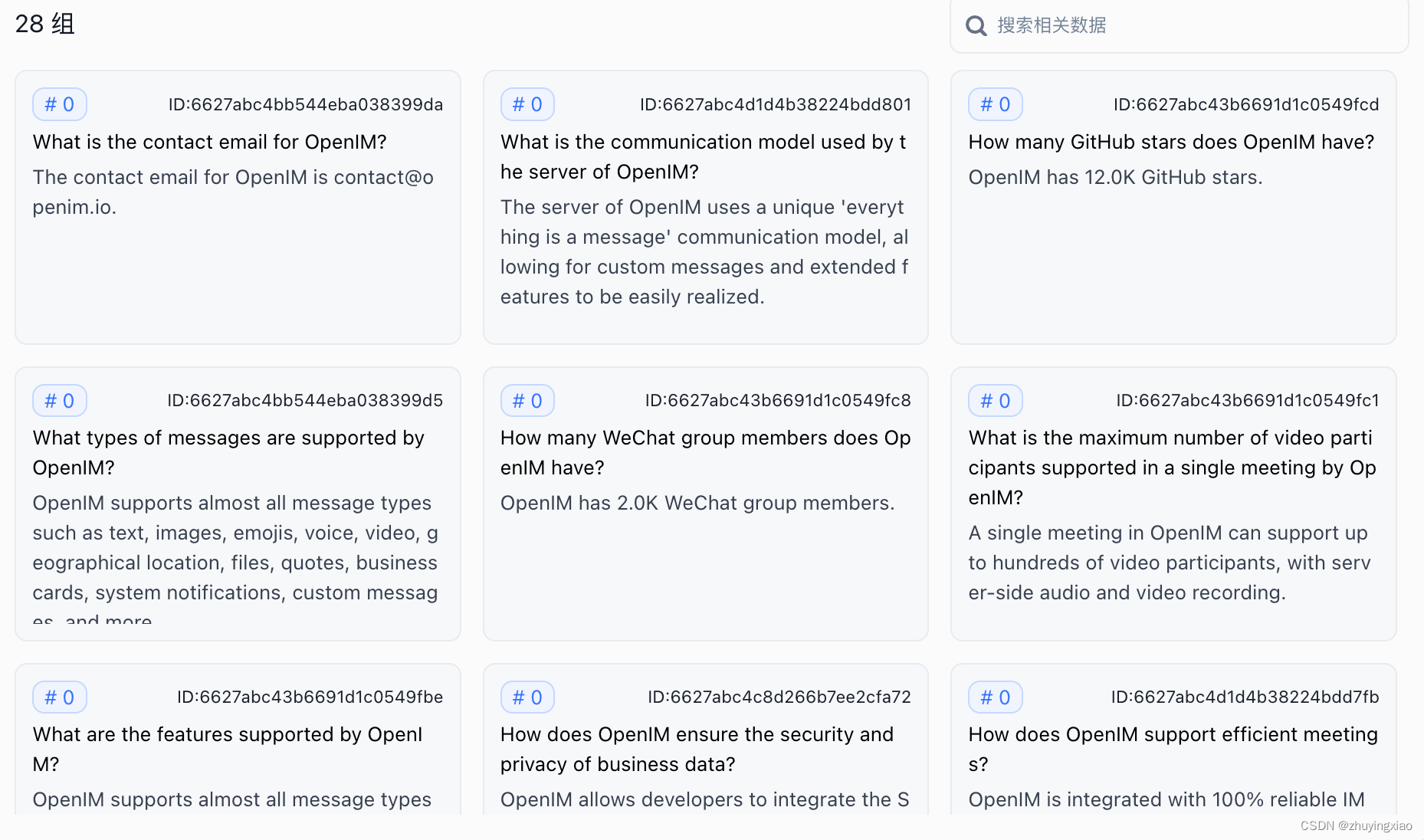
切分后的某个chunk的问答对信息: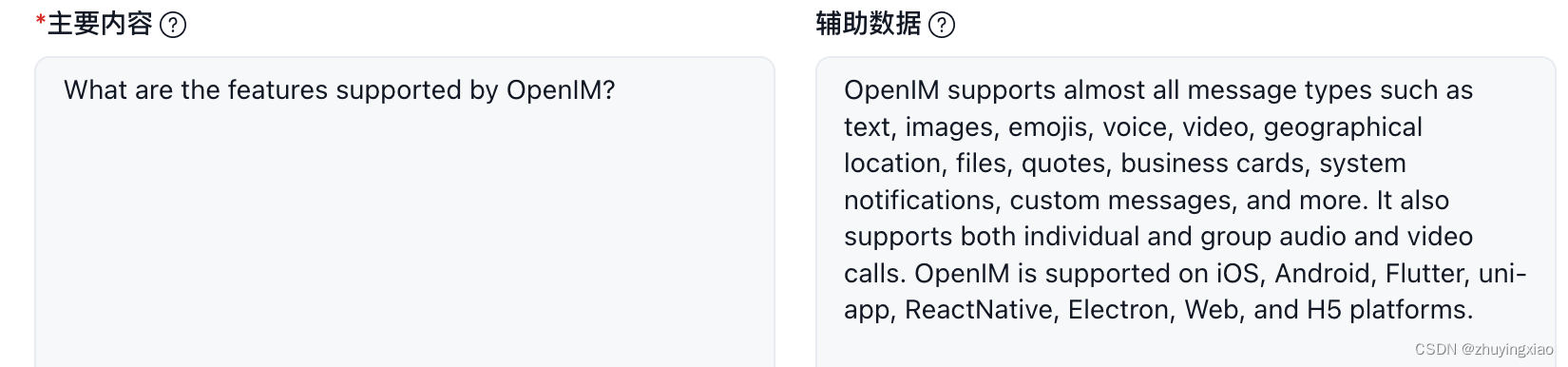
-
增强信息:
切分后的chunk信息,总共
6个chunk,每个chunk都包含一批数据索引信息: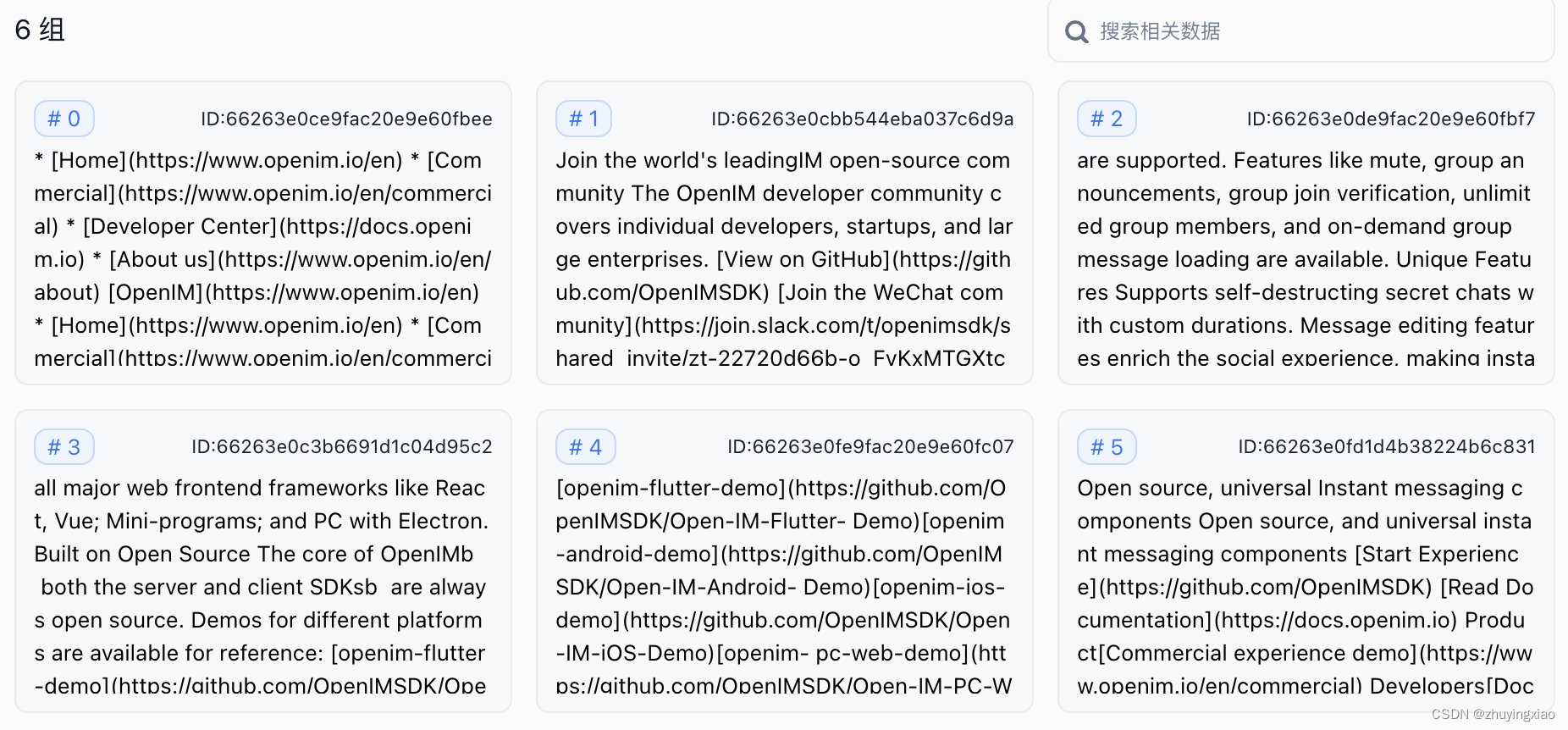
切分后的某个chunk的数据索引信息: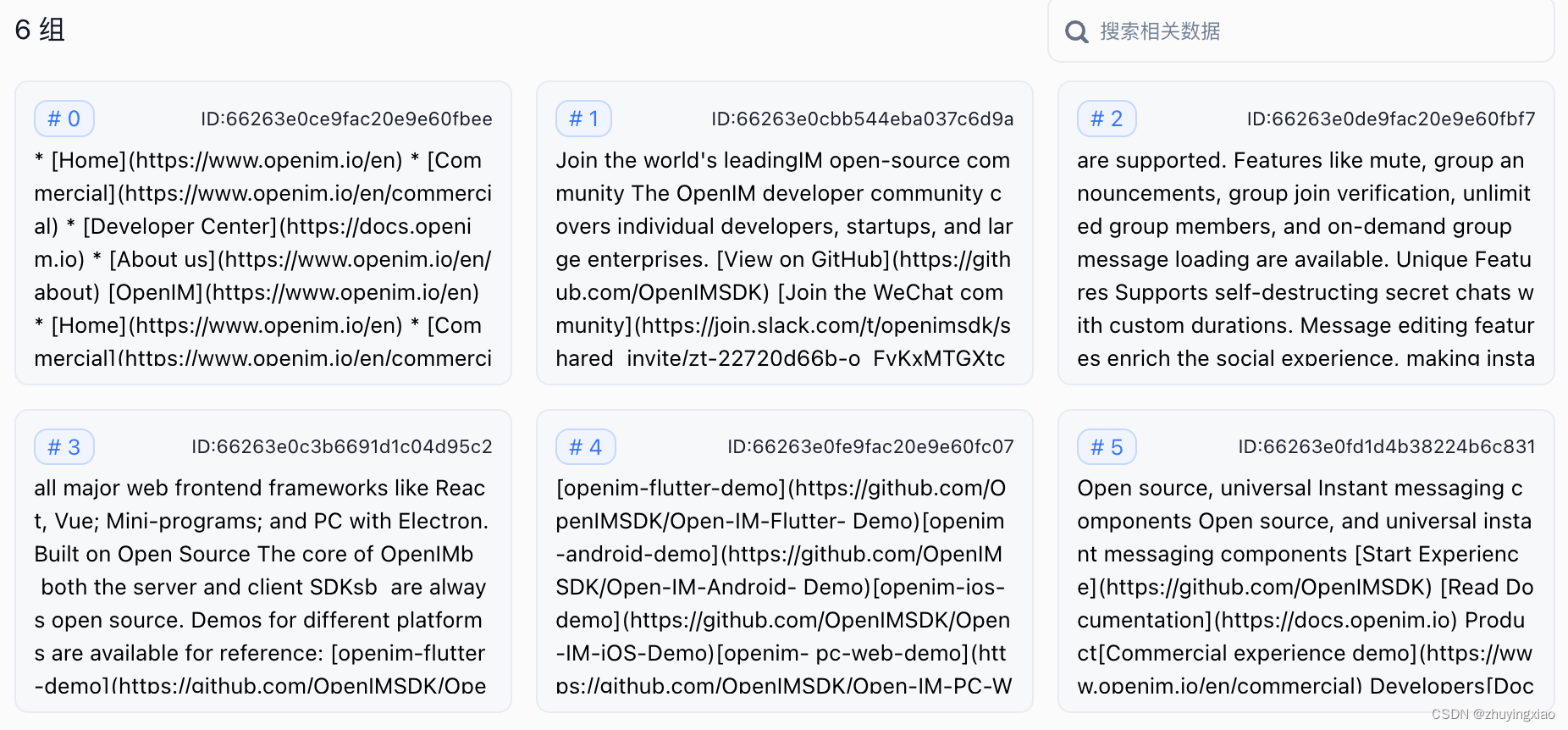
3.1.1.1 滑动窗口
平衡这些需求的一种简单方法是使用重叠的chunk。通过使用滑动窗口,可以增强语义过渡。然而,也存在一些限制,包括对上下文大小的控制不精确、有截断单词或句子的风险,以及缺乏语义考虑。
final_result = []
ast_lines = ""
for section in result:
lines = section.split('\n')
last_two_lines = "\n".join(lines[-2:]) # Extract the last two lines
combined_section = last_lines + "\n" + section if last_lines else section
final_result.append(combined_section)
last_lines = last_two_lines3.1.1.2 上下文丰富化
这里的概念是为了获得更好的搜索质量而检索较小的chunk,并添加周围的上下文供LLM进行推理。
有两个选项:通过在较小的检索chunk周围添加句子来扩展上下文,或者将文档递归地分成多个较大的父chunk,其中包含较小的子chunk。
句子窗口检索
在这个方案中,文档中的每个句子都被单独嵌入,这提供了查询与上下文余弦距离搜索的高准确性。
为了在获取到最相关的单个句子后更好地推理出找到的上下文,我们通过在检索到的句子之前和之后添加k个句子来扩展上下文窗口,然后将这个扩展后的上下文发送给LLM。
from llama_index import ServiceContext, VectorStoreIndex, StorageContext
from llama_index.node_parser import SentenceWindowNodeParser
def build_sentence_window_index(
document, llm, vector_store, embed_model="local:BAAI/bge-small-en-v1.5"
):
# create the sentence window node parser w/ default settings
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
sentence_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
node_parser=node_parser
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
sentence_index = VectorStoreIndex.from_documents(
[document], service_context=sentence_context, storage_context=storage_context
)
return sentence_index父文档检索器
文档被分割成一个层次结构的chunk,然后最小的叶子chunk被发送到索引中。在检索时,我们检索k个叶子chunk,如果有n个chunk引用同一个父chunk,我们将它们替换为该父chunk并将其发送给LLM进行答案生成。
关键思想是将用于检索的chunk与用于合成的chunk分开。使用较小的chunk
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 641
641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









