






 本文介绍了KNN(K-NearestNeighbor)机器学习算法的基本概念,包括其工作原理(基于相似度的分类),实现过程(计算距离、排序并计票),以及数据集间的距离计算方法(如欧氏距离)。通过一个简单的例子展示了如何用Python实现KNN算法。
本文介绍了KNN(K-NearestNeighbor)机器学习算法的基本概念,包括其工作原理(基于相似度的分类),实现过程(计算距离、排序并计票),以及数据集间的距离计算方法(如欧氏距离)。通过一个简单的例子展示了如何用Python实现KNN算法。
KNN算法简介
KNN(K-NearestNeighbor)是机器学习入门级的分类算法,非常简单。它实现将距离近的样本点划为同一类别;KNN中的K指的是近邻个数,也就是最近的K个点 ;根据它距离最近的K个点是什么类别来判断属于哪个类别。近朱者赤,近墨者黑,物以类聚,人以群分。KNN算法就是这样。它使相同类别的样本在特征空间中聚集在一起。
KNN算法实现过程
(1)计算已知类别数据集中的点与当前点之间的距离;
(2)按照距离递增次序排序;
(3)选取与当前点距离最小的k个点;
(4)确定前k个点所在类别的出现频率;
(5)返回前k个点出现频率最高的类别作为当前点的预测分类.
数据集间距离计算
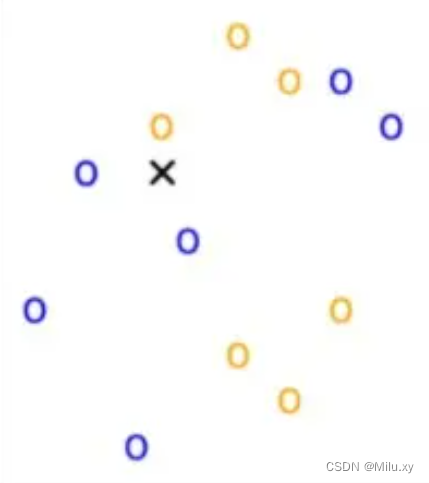
KNN做的就是选出距离目标点黑叉叉距离最近的k个点,看这k个点的大多数颜色是什么颜色。这里的距离用欧氏距离来度量。
给定两个样本 和
,其中n表示特征数 ,X和Y两个向量间的欧氏距离(Euclidean Distance)表示为:

 ||||
|||| 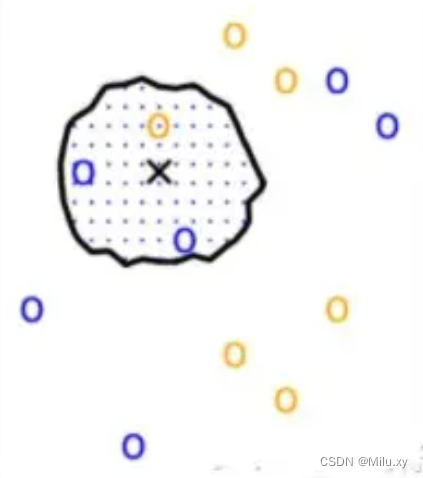
当我们设定k=1时,距离目标点最近的点是黄色,就认为目标点属于黄色那类。当k设为3时,我们可以看到距离最近的三个点,有两个是蓝色,一个是黄色,因此认为目标点属于蓝色的一类。
所以,K的选择不同,得到的结果也会不同。
KNN算法python代码实现
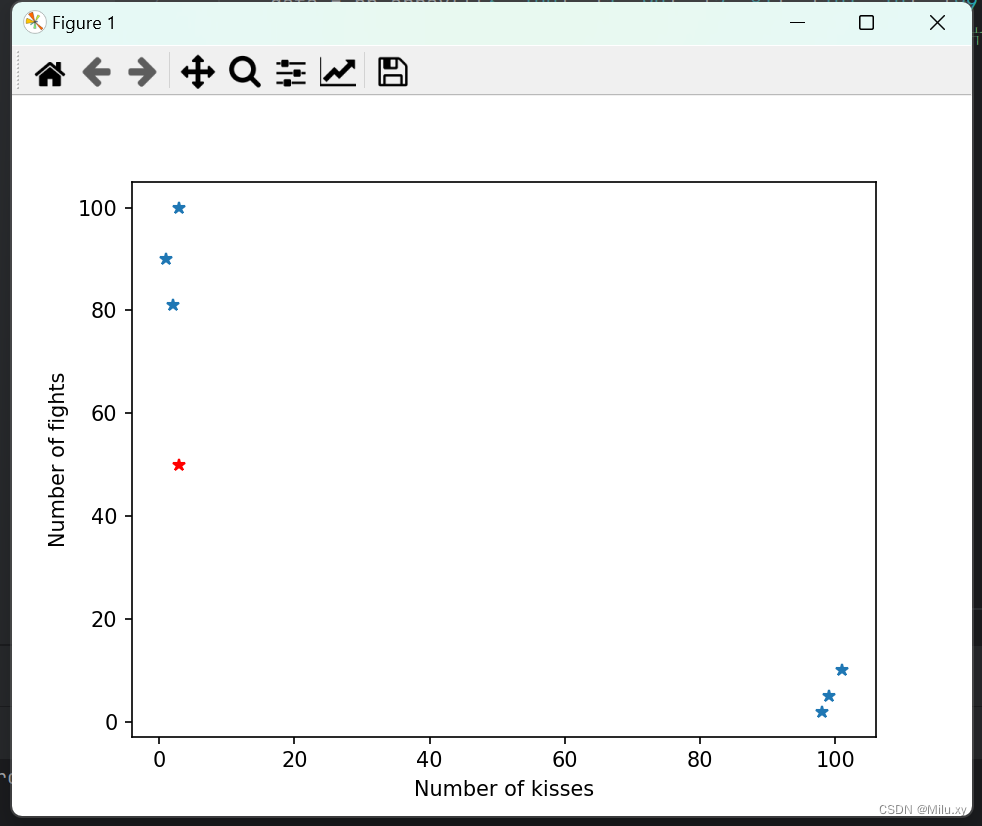
1、给定一定的训练数据集数据集,前一个数据是亲吻次数,后一个数据是打斗次数。
def Dataset():
data = np.array([[3, 100], [1, 90], [2, 81], [101, 10], [99, 5], [98, 2]])
labels = ['动作片', '动作片', '动作片', '爱情片', '爱情片', '爱情片']
return data, labels2 、data_show函数创建了两个空列表x和y,用于存储训练数据的横坐标和纵坐标。然后,通过遍历train_data的每一行,将每一行的前两个元素分别添加到x和y列表中。
接下来,使用plt.plot(x, y, "*")绘制训练数据的散点图,其中"*"表示用星号标记每个数据点。然后,使用plt.xlabel("Number of kisses")和plt.ylabel("Number of fights")设置横轴和纵轴的标签。
最后,使用plt.plot(in_data[0], in_data[1], "r*")在图中以红色星号标记输入数据点。最后一行代码plt.show()用于显示图形。
def data_show(in_data, train_data):
# 显示训练数据
x = []
y = []
for i in range(train_data.shape[0]):
x.append(train_data[i][0])
y.append(train_data[i][1])
plt.plot(x, y, "*")
plt.xlabel("Number of kisses")
plt.ylabel("Number of fights")
plt.plot(in_data[0], in_data[1], "r*")
plt.show()3、
KNN函数的工作原理是找到训练集中与新数据点最接近的k个邻居,然后根据这些邻居的标签来预测新数据点的标签。
这个函数的输入参数包括:
- in_data:需要分类的数据点
- train_data:训练数据集
- train_labels:训练数据集对应的标签
- k:选择的最近邻居的数量
函数的主要步骤如下:
- 计算输入数据点与训练数据集中每个点的距离。这里使用的是欧氏距离。
- 对计算出的距离进行排序,得到距离最小的k个点的索引。
- 根据这k个点的标签进行投票,得到出现次数最多的标签作为预测结果。
def KNN(in_data, train_data, train_labels, k): train_data_size = train_data.shape[0] # 将输入数据平铺为train_data_size行1列,便于与训练数据做差 distance = (np.tile(in_data, (train_data_size, 1)) - train_data) ** 2 add_distance = distance.sum(axis=1) sq_distance = add_distance ** 0.5 # 欧氏距离 # 将欧氏距离排序,返回对应的索引值 index = sq_distance.argsort() classdict = {} # 寻找前k个最小距离对应的标签 for i in range(k): vote_label = train_labels[index[i]] # 第i个距离对应的标签 classdict[vote_label] = classdict.get(vote_label, 0) + 1 #统计某个标签个数 sort_classdict = sorted(classdict.items(), key=operator.itemgetter(1), reverse=True) return sort_classdict[0][0]完整代码
import numpy as np import matplotlib.pyplot as plt import operator def Dataset(): data = np.array([[3, 100], [1, 90], [2, 81], [101, 10], [99, 5], [98, 2]]) labels = ['动作片', '动作片', '动作片', '爱情片', '爱情片', '爱情片'] return data, labels def data_show(in_data, train_data): # 显示训练数据 x = [] y = [] for i in range(train_data.shape[0]): x.append(train_data[i][0]) y.append(train_data[i][1]) plt.plot(x, y, "*") plt.xlabel("Number of kisses") plt.ylabel("Number of fights") plt.plot(in_data[0], in_data[1], "r*") plt.show() def KNN(in_data, train_data, train_labels, k): train_data_size = train_data.shape[0] # 将输入数据平铺为train_data_size行1列,便于与训练数据做差 distance = (np.tile(in_data, (train_data_size, 1)) - train_data) ** 2 add_distance = distance.sum(axis=1) sq_distance = add_distance ** 0.5 # 欧氏距离 # 将欧氏距离排序,返回对应的索引值 index = sq_distance.argsort() classdict = {} # 寻找前k个最小距离对应的标签 for i in range(k): vote_label = train_labels[index[i]] # 第i个距离对应的标签 classdict[vote_label] = classdict.get(vote_label, 0) + 1 #统计某个标签个数 sort_classdict = sorted(classdict.items(), key=operator.itemgetter(1), reverse=True) return sort_classdict[0][0] train_data, labels = Dataset() in_data = np.array([3, 50]) data_show(in_data, train_data) result = KNN(in_data, train_data, labels, 3) print("预测结果:", result)运行结果
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









