






文章目录
前言
该博文为笔者学习《计算机网络》的记录,主要参考中科大郑烇老师发布在 B 站的课程,不完全涵盖所有内容(像 历史 这样的内容并没有分享)。相信总有一些片段能够解答你的疑惑~
郑烇老师 B 站课程在这里:https://www.bilibili.com/video/BV1JV411t7ow?vd_source=0b09067c2866c4e9422cb38d8613e75c
期末复习
Chap 1 Computer Networks and the Internet

1.1 什么是 Internet
- 协议
- 协议定义了两个或多个通信实体之间交换的
报文格式和次序,以及在报文传输和/或接收或其他事件方面所采取的动作
- 协议定义了两个或多个通信实体之间交换的
1.2 网络边缘
-
包含的实体:
- 主机/端系统
- **注意:**服务器本质上也是主机,所以它也在
网络边缘,而不是网络核心
- **注意:**服务器本质上也是主机,所以它也在
- 应用程序
- 主机/端系统
-
TCP - 传输控制协议(Transmission Control Protocol)
-
特点:
-
提供面向连接的服务
-
确认和重传
- 能够可靠、安全地传送数据
-
流量控制
- 发送方不会淹没接收方
-
拥塞控制
- 当网络拥塞时,发送方降低发送速率
-
-
使用 TCP 的应用:
- HTTP(Web)
- FTP(文件传送)
- Telnet(远程登录)
- SMTP(邮件)
-
-
UDP - 用户数据报协议(User Datagram Protocol)
- 特点:
- 提供无连接的服务
- 不可靠的数据传输
- 无流量控制
- 无拥塞控制
- 使用 UDP 的应用:
- 流媒体
- 远程会议
- DNS(域名系统)
- 网络电话(VoIP,基于 IP 的语音传输)
- 特点:
1.3 网络核心
- 包含的实体:
- 路由器
- 交换机
- 网络核心的关键功能:
- 路由
- 决定分组采用的从源到目标的路径
- 转发
- 将分组从路由器的输入链路转移到输出链路
- 路由
- 两种数据传输方式
- 电路交换
- 定义:为每个呼叫预留一条专有电路,如电话线
- 特点:不共享
- 每个呼叫一旦建立起来就只为这一个通信服务,虽然能够保证性能,但是更多时候是会造成资源的浪费
- 需要花费时间来建立连接,连接一旦建成,后续直接发送数据即可
- 不适合计算机之间的通信的原因:
- 建立连接时间长
- 对线路资源的利用率低
- 不能很好地应对计算机通信中的突发情况
- 分组交换
- 定义:将要传送的数据分成一组一组,然后将分组从一个路由器传到相邻路由器(hop),一段段最终从源端传到目标端
- 特点:资源共享,按需使用
- 存储-转发:分组每次移动一跳(hop)
- 转发之前,节点必须收到整个分组
- 延迟比线路交换大
- 存在排队延迟
- 当 分组到达速率 > 链路输出速率 时,后来的分组需要等待前面的分组发送完才能发送
- 数据存在丢失风险(丢包)
- 如果路由器的缓存用完了,分组将会被抛弃
- 电路交换
1.6 分组延时、丢失和吞吐量
-
四种分组延时
注意:做题的时候通常只需要考虑 传输延时 和 传播延时,后面两种延时不考虑在内
-
传输延时
- 为什么会有传输延时?
- 因为前面我们说过,在分组交换中,转发之前,节点必须要收到整个分组。这就导致 B 收到 A 发送来的第一个 bit 后并不能开始向 C 转发,而是要等到成功接收到从 A 传来的所有 bit 后再开始向 C 转发。
站在 B 的角度来看,从接收到来自 A 的第一个 bit 到接收到来自 A 的最后一个 bit 的时间就是传输延时,数值上等价于:从 A 发出第一个 bit 到 A 发出最后一个 bit 的时间。
- 因为前面我们说过,在分组交换中,转发之前,节点必须要收到整个分组。这就导致 B 收到 A 发送来的第一个 bit 后并不能开始向 C 转发,而是要等到成功接收到从 A 传来的所有 bit 后再开始向 C 转发。
- 如何计算?
- 传输延时 = 分组长度(bits) / 链路带宽(bps)
- 为什么会有传输延时?
-
传播延时
- 为什么会有传播延时?
- 当发送方和接收方距离很远时,我们就需要考虑 bit 在物理空间上的传播速率。
继续使用上面 传输延时 中的那个例子:从 A 向 B 发出第一个 bit 到 B 接收到 A 发出的所有 bit 这一整个过程的 总时间 = T1 + T2 。
其中,T1 为传输延时,即 T1 = A 发出最后一个 bit 的时间 - A 发出第一个 bit 的时间 = B 收到来自 A 的最后一个 bit 的时间 - B 收到来自 A 的第一个 bit 的时间
T2 为传播延时,即 T2 = B 收到来自 A 的第一个 bit 的时间 - A 发出第一个 bit 的时间 = B 收到来自 A 的最后一个 bit 的时间 - A 发出最后一个 bit 的时间
- 当发送方和接收方距离很远时,我们就需要考虑 bit 在物理空间上的传播速率。
- 如何计算?
- 传播延时 = 物理链路的长度/在媒体上传播的速率
- 为什么会有传播延时?
-
节点处理延时
-
排队延时
-
这里引出一个新的概念叫做:
流量强度,计算如下图所示。值得注意的是,随着流量强度的增加,排队延时呈指数型增长,因此我们我们通常不可以设计出 流量强度 = 1 的网络,乍一看似乎感觉利用率刚刚好,实际上网络已经瘫痪了,因为排队延时无穷大,数据根本传不动。
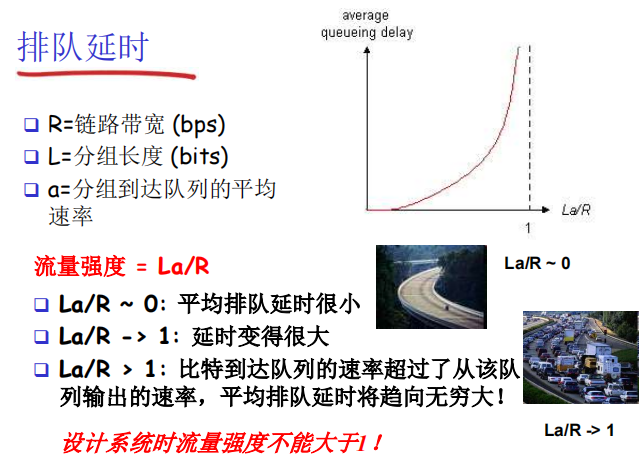
-
-
-
分组丢失
- 链路的队列缓冲区有限,当分组到达一个满的队列时,该分组将被抛弃,从而造成分组丢失
-
吞吐量
- 在源端和目标端之间的传输速率,使衡量网络性能的一个常用指标。
- 这里存在一个短板效应:我们知道,分组传输,相当于是由许多小路段拼接成一条大路段,那么其中吞吐量最小的那个小路段,将会决定总链路的吞吐量,这个链路称为
瓶颈链路
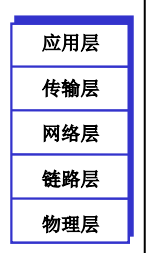
1.7 协议层次及服务模型
-
Internet 协议栈
- 应用层
- 为人类用户或其他应用进程提供网络应用服务
- FTP SMTP HTTP DNS
- 传输层
- 在网络层提供的端到端的通信基础上细分为进程到进程
- 进程到进程的通信
- TCP: 可靠通信
- UDP: 不可靠通信
- 网络层
- 实现了主机到主机之间的通信,不可靠,提供的是
尽力而为的服务 - 端到端的通信
- 网络层用的最多的是
IP和路由协议,但并不是只有这两种协议
- 实现了主机到主机之间的通信,不可靠,提供的是
- 链路层
- 实现了相邻网络节点间的数据传输
- 点到点的通信
- 物理层
- 在线路上传送 bit
- 应用层
-
ISO/OSI 参考模型
现在比较通用的是上面那个 五层 的模型架构,不过也有 七层 架构的说法,即在 应用层 和 网络层 之间加了 表示层 和 会话层
-
五层模型与七层模型

- 表示层:允许应用解释传输的数据,如:加密、压缩、机器相关的表示转换
- 会话层:数据交换的同步,检查点,恢复
-
-
各层次的 PDU(协议数据单元)的名称
- 应用层:报文(message)
- 传输层:报文段(segment)
- 网络层:分组(packet),如果是无连接(UDP)的情况下,也叫做数据报(datagram)
- 链路层:帧(frame)
- 物理层:位(bit)
Chap 2 Application Layer

2.1 应用层协议原理
- 网络应用的体系结构
- CS 模式(客户端-服务器模式)
- 服务器一直运行,客户端主动与服务器通信
- P2P 模型
- 各点既充当客户端,也可发挥服务器功能,最典型的是迅雷、百度网盘这种工具。你要下载一个东西不一定非要去官网,如果其他主机上有,便可以通过这些工具发送给你,通常情况下(不限速),这比直接去官网下载来得快,因为官网要处理的是来自全球各地的很多各请求,而对方主机只处理你这一个请求。
- CS 模式(客户端-服务器模式)
- socket
- 定义:标示通信双方或者单方的具有
本地意义的标识 - 分类:
- TCP socket:
- 包含 4 个元素:(源 IP,源 port,目标 IP,目标 port)
- 作用:唯一指定了一个会话,应用该标识与远程的应用进程通信
- UDP socket:
- 包含 2 个元素:(本 IP,本 port)
- TCP socket:
- 定义:标示通信双方或者单方的具有
2.2 Web and HTTP
-
HTTP(超文本传输协议)
-
特点:HTTP 是无状态的
- 虽然 HTTP 本身是无状态的,但是通过使用 cookies 和 session 可以让它“有状态”
-
分类:
- 非持久 HTTP:
- 最多只有一个对象在 TCP 连接上发送,下载多个对象需要多个 TCP 连接
- 假如现在需要请求一个包含 5 个 object 的网页,那么共需要进行 6 次建立 TCP 连接和传输数据的过程**(做题的时候注意这一点)**
- 持久 HTTP:
- 多个对象可以在一个 TCP 连接上发送
- 假如现在需要请求一个包含 5 个 object 的网页,那么只需要建立 1 次 TCP 连接即可。那么建立连接之后,根据数据的发送方式又可以分为两类:
- 非流水方式的持久 HTTP:
- 客户端只有收到前一个响应后才能发出新的请求
- 流水方式的持久 HTTP:
- 客户端遇到一个引用对象就立刻产生一个请求
- 非流水方式的持久 HTTP:
- 非持久 HTTP:
-
响应时间模型:
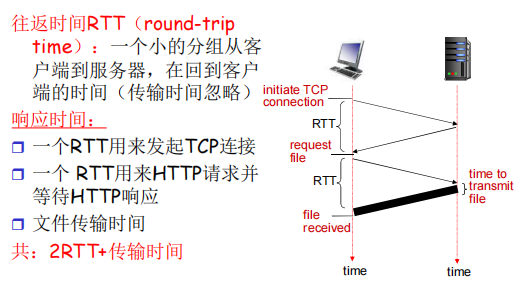
-
2.3 FTP(文件传输协议)
- 特点:
- control connection 与 data connection 相互之间是分开的
- 由于控制信息的传输和数据的传输是分开进行的,我们一般称 control connection 为
带外传送(out of band),data connection 为带内传送
- 由于控制信息的传输和数据的传输是分开进行的,我们一般称 control connection 为
- 是一个有状态协议
- control connection 与 data connection 相互之间是分开的
- 工作流程:
- 服务器守候在 21 号端口,客户端通过访问该端口与服务器取得联系,并使用 TCP 作为传输协议。
- 在 control connection 上,服务器完成对客户端的身份认证工作,之后客户端便可以通过 control connection 发送一系列操作文件的命令。
- 每当服务器从 control connection 上收到来自客户端的一个命令,便会主动用自己的 20 号端口访问客户端,建立起一个新的连接,即 data connection,在该连接上传输数据
(注意:这里有一个比较反常的举动:data connection 是由服务器主动访问客户端而建立起来的) - 文件传输完成后,服务器关闭连接
2.4 EMail
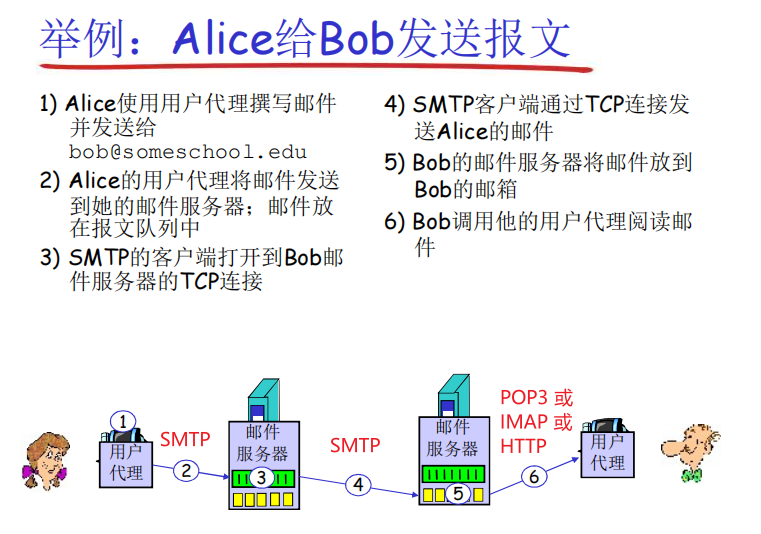
- **Email 是如何被发送的?**查看下图,红色字体 为这一步中使用的协议
- 可以看到,邮件的发送通常使用 SMTP,从邮件服务器拉取邮件到用户代理则可以使用 POP3、IMAP、HTTP
2.5 DNS(域名系统)
- 特点:承担核心的 Internet 功能,但是是以应用层协议来实现的
- 主要目的:实现 主机名 - IP 地址 的转换
- 资源记录(resource records)
- 作用:维护 域名-IP地址 的映射关系
- 位置:Name Server 的分布式数据库中
Chap 3 Transport Layer
3.3 无连接传输:UDP
-
特点
- 提供“尽力而为”的服务,报文段可能:
- 丢失
- 乱序
- 无连接
- UDP 发送端和接收端之间没有握手
- 每个 UDP 报文段都被独立处理
- 提供“尽力而为”的服务,报文段可能:
-
UDP 存在的必要性
- 能够区分不同的进程,而 IP 服务不行
- 在 IP 提供的端到端服务的基础之上,细分为进程到进程
- 无需建立连接
- 省去了建立连接的时间,适合事务性应用
- 不做可靠性工作
- 不花时间在检错重发上,适合那些对实时性要求比较高且对正确性要求不高的应用
- 应用能够按照设定的速度发送数据
- 没有拥塞控制和流量控制
- 报文段头部很小
- 造成的 overhead 开销少
- 能够区分不同的进程,而 IP 服务不行
3.4 可靠数据传输原理
- GBN(Go-back-N)
- 发送端最多在流水线中有 N 个未确认的分组
- 接收方发送的确认类型为
累计确认- 因为是 累计确认,所以只能 顺序接收
- 发送端拥有对最老的未确认分组的定时器
- 只需设置一个定时器
- 当定时器到时时,重传所有未确认分组
- SR(Selective Repeat)
- 发送端最多在流水线中有 N 个未确认的分组
- 接收方对每个到来的分组单独确认,而不是累计确认
- 因为是单独确认,所以可以乱序接收
- 发送方为每个未确认的分组保持一个定时器
- 当超时定时器到时时,只需重发到时的未确认分组
3.5 面向连接的传输:TCP
-
概述
- 点对点
- 一个发送方,一个接收方
- 可靠的、按顺序的字节流
- 没有报文边界
- 管道化(流水线)
- TCP 拥塞控制和流量控制设置窗口大小
- 发送和接收缓存
- 全双工数据
- 在同一连接中数据双向流动
- MSS:最大报文段大小
- 面向连接
- 在数据交换之前,通过握手初始化发送方、接收方的状态变量
- 有流量控制
- 发送方不会淹没接收方
- 点对点
-
TCP 序号、确认号
- 序号:
- 报文段首字节在字节流中的编号
- 确认号:
- 期望从另一方收到的下一个字节的序号
- 累计确认
- 序号:
-
TCP 对 可靠数据传输的实现综合了 GBN 和 SR 各自的特性
- 累计确认(像 GBN)
- 只设置一个重传定时器(像 GBN)
- 可以缓存接收到的乱序数据,timeout 时只重发最早的未确认段(像 SR)
-
触发重传的两种事件:
- timeout(超时)
- 定时器到时时,只重发最早的未确认段
- 收到重复确认
- 假如收到了 ACK50,之后又收到了 3 个 ACK50,此时即便定时器尚未到时,发送方仍会选择重传,这种重传叫做快速重传。因为重复 ACK 通常表征数据段丢失。
- timeout(超时)
-
TCP 流量控制
- 接收方在其向发送方发送的 TCP 段头部会显示自己的空闲 buffer 的大小,从而限制发送方发来的字节的个数,保证接收方不被淹没
-
TCP 的连接管理
- 关于这一块的详细解释在目录中的P【TCP的三次握手和四次挥手】这部分
-
TCP 拥塞控制
-
2 种拥塞控制方法:
- 端到端的拥塞控制**(TCP 采用的方法)**
- 没有来自网络的显式反馈
- 端系统根据延迟和丢失事件推断是否有拥塞
- 优点:
- 路由器不需要向主机提供有关拥塞的反馈信息,使得路由器的负担较轻,且符合网络核心简单的 TCP/IP 架构原则
- 网络辅助的拥塞控制
- 单个 bit 置位,显示有拥塞
- 显式提供发送端可以采用的速率
- 端到端的拥塞控制**(TCP 采用的方法)**
-
如何检测拥塞?(判断拥塞的标准)
- timeout -> 拥塞
- 超时时间到,某个段的确认依然没有来
- 接收到关于某个段的 3 个重复 ACK -> 轻微拥塞
- 网络这时候还能够进行一定程度的传输,拥塞但是情况比第一种轻微
- timeout -> 拥塞
-
TCP 拥塞控制的速率控制方法

- CongWin: 发送方的发送窗口大小,单位为 MSS(最大报文段大小)
- Threshold: 慢启动阈值
- 慢启动阶段:在达到 Threshold 之前,CongWin 以 2 为底呈指数型增长
- 拥塞避免阶段:在达到 Threshold 之后,CongWin 随时间 +1,呈线性增长
- 收到 3 个重复 ACK(轻微拥塞)时:
- Threshold = CongWin / 2
- CongWin = Threshold + 3
- 发生 timeout (拥塞)时:
- Threshold = CongWin / 2
- CongWin = 1MSS,重新进入慢启动阶段
-
值得注意的是,对 TCP 拥塞控制的理解,我们需要分别从宏观和微观两个角度去看。宏观帮助我们理解,但是具体面对题目的时候,需要从微观角度去逐层剖析。
慢启动阶段:
- 宏观上:
- 拥塞窗口大小呈指数增长,每收到一个 ACK,窗口大小就翻倍,这意味着每个 RTT 结束时,窗口大小理论上应该加倍。
- 微观上:
- 每收到一个 ACK,拥塞窗口大小增加一个 MSS
拥塞避免阶段:
- 宏观上:
- 窗口大小线性增长,每个 RTT 窗口大小增加一个 MSS
- 微观上:
- 每收到一个 ACK,拥塞窗口只增加 cwnd/MSS 个 MSS
总之,从微观上看,无论是慢启动还是拥塞避免,拥塞窗口的增长都是对每个 ACK 的单独响应。
Chap 4 Network Layer: Data Plane

4.1 导论
- 网络层的功能:
- 路由:使用路由算法来决定分组从发送主机到目标接受主机的路径
- 由控制平面实现
- 运行路由选择算法/协议(RIP、OSPF、BGP),生成路由表
- 转发:将分组从路由器的输入接口转发到合适的输出接口
- 由数据平面实现
- 路由:使用路由算法来决定分组从发送主机到目标接受主机的路径
4.2 路由器的组成
- 最长前缀匹配
- 当给定目标地址查找转发表时,采用最长地址前缀匹配的目标地址表项
4.3 IP: Internet Protocol
-
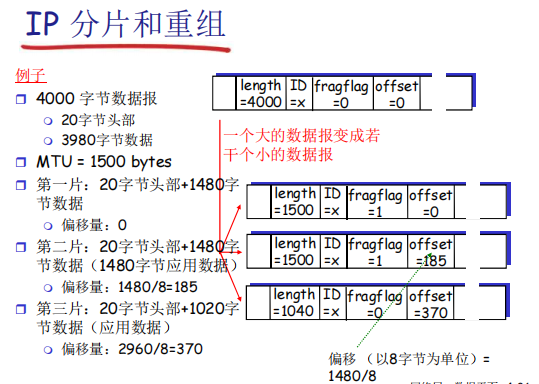
网络链路有MTU(最大数据单元),其为链路层的 帧(Frame)所能携带的最大数据长度。当数据长度超过 帧 的大小时,会被分片(fragmented),一个数据报被分割成若干小的数据报,这些数据报具有:
- 相同的 ID
- 不同的偏移量
- 偏移量的单位为:8字节,所以注意,计量单位为 byte 时需要用 总长度/8
- 最后一个分片标记为 0
-
IP 分片和重组 的例子:
-
IPv4 地址
-
一个路由器通常有多个接口,主机也可能有多个接口,一个 IP 地址和一个接口相关联
-
IP 地址分为两部分:
- 子网部分(高位 bits):代表主机接入的是哪一个网络
- 主机部分(低位 bits):该网络中对该主机的唯一标识
-
-
子网(Subnets)
- 定义:一个子网内的节点(主机或路由器)它们的 IP 地址高位部分相同,这些节点构成的网络的一部分叫做子网
- 无需路由器介入,同一子网内的个主机可以在物理上相互直接到达
-
常见的私有 IP(内网/专用 IP 地址)
- 10.0.0.0~10.255.255.255
- 172.16.0.0~172.31.255.255
- 192.168.0.0~192.168.255.255
-
IP 编址:CIDR(Classless InterDomain Routing)无类域间路由
- 地址格式:a.b.c.d/x,其中 x 是地址中网络位的长度
-
子网掩码:
- 1:bit 位置表示网络部分
- 0:bit 位置表示主机部分
值得注意的是,子网掩码中,1 和 0 在区域上一定是具有明显界限的,判断题中通常让你找出不是子网掩码的那一个,那就是 1 和 0 存在交叉分布的那一个
-
DHCP(Dynamic Host Configuration Protocol)
-
作用:允许主机在加入网络时,动态地从服务器那里获得 IP 地址
-
DHCP 返回如下内容:
注意:DHCP 不只是返回 IP 地址,小心判断题
- IP 地址
- 第一跳路由器的 IP 地址(默认网关)
- DNS 服务器的域名和 IP 地址
- 子网掩码(指示地址部分的网络号和主机号)
-
-
NAT 地址转换
- 所有离开本地网络的数据报具有一个相同的源地址 NAT IP address,但是具有不同的端口号,用这个不同的端口号来区分子网内的各主机
Chap 5 Network Layer: Control Plane

5.1 导论
网络层功能
- 转发:将分组从路由器的一个输入端口移动到合适的输出端口
- 执行者:数据平面
- 路由:确定分组从源到目标的路径
- 执行者:控制平面
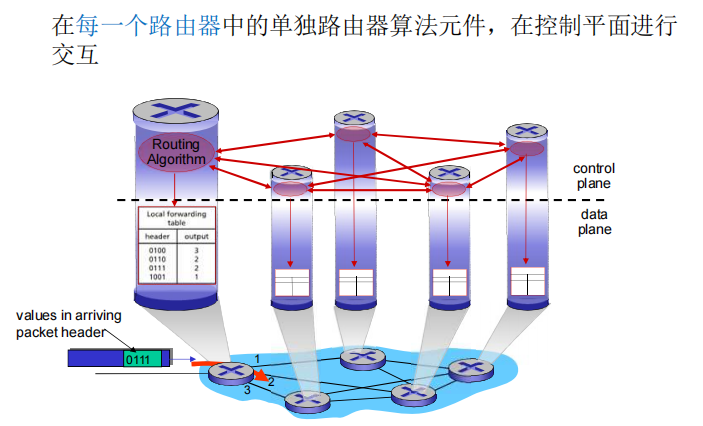
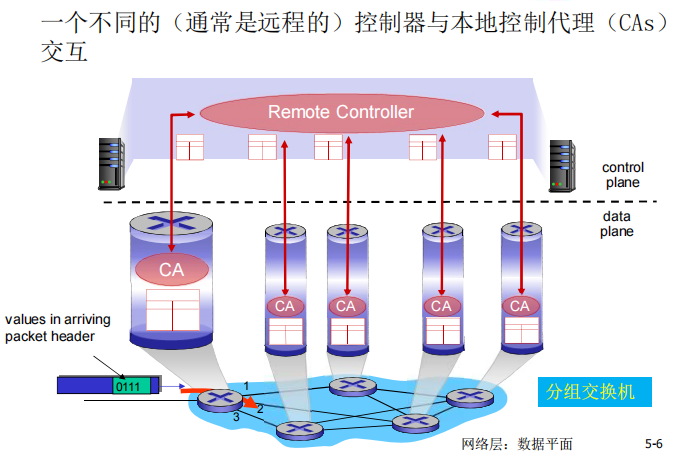
2种构建网络控制平面功能的方法:
当前有两种构建控制平面的方式,第一种是传统的1)每个路由器都单独集成控制平面,如左图所示,每个路由器既有控制平面又有数据平面;第二种是2)逻辑上集中的控制功能实现(software defined networking),如右图所示,控制平面的功能将由远端控制器上的软件实现,每个路由器内部除了数据平面外,还有一个负责与远端控制器交互的本地代理。如此一来,便将控制平面功能的实现从路由器本身移交至远端。
5.2 路由选择算法
Link State
-
特点:所有的路由器拥有完整的拓扑和边的代价信息**(全局路由信息)**
-
工作过程:
- 通过协议获得网络拓扑和链路代价信息
- 使用 Dijkstra 路由算法找出最短路径
- 使用路由表
这部分涉及的考题通常聚集在对 Dijkstra 算法的考察。即:使用 Dijkstra 算法计算出路由表,下面展示一个例题。
- Dijkstra 算法例题:
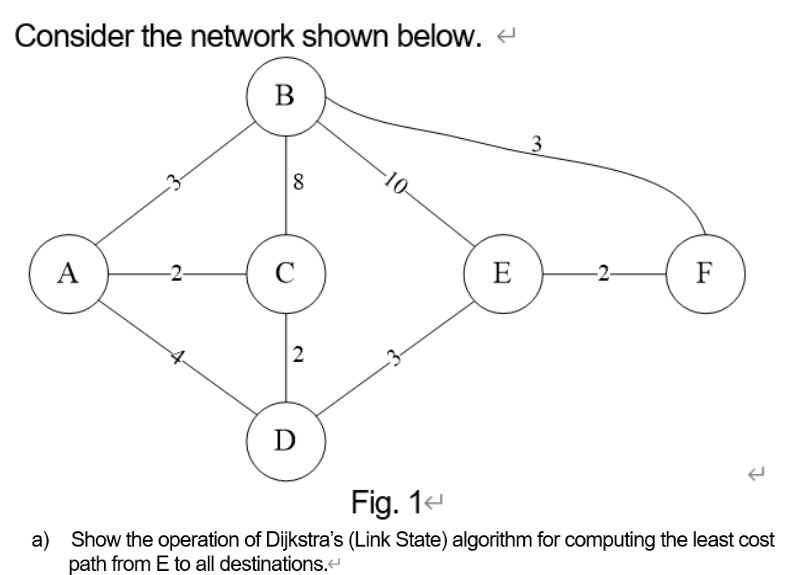
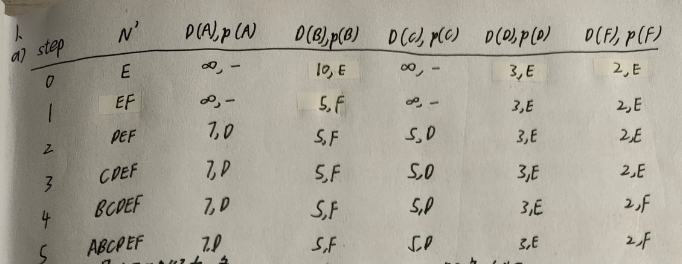
Dijkstra 算法题目通常都以上述表格所展示的形式回答。各符号的含义如下图所示。

Distance Vector
- 特点:
- 分布式存储路由信息,所有路由器只知道与它有物理连接关系的邻居路由器,和到相应邻居路由器的代价值**(部分路由信息)**
- 迭代地与邻居交换路由信息、计算路由信息
- 工作过程
- 通过实测获得相邻节点间的代价
- 对于节点 A,它会定期与相邻节点交换路由表(DV),获得各相邻节点到目标站点 B 的代价
- 计算出 A 经过各相邻站点到目标节点 B 的代价,即 c(A, x) + dx(B),x 为 A 的邻居
- 找到一个最小的代价以及相应的邻居节点 x,所有由 A 发送给 B 的数据将会首先由 A 路由给 x
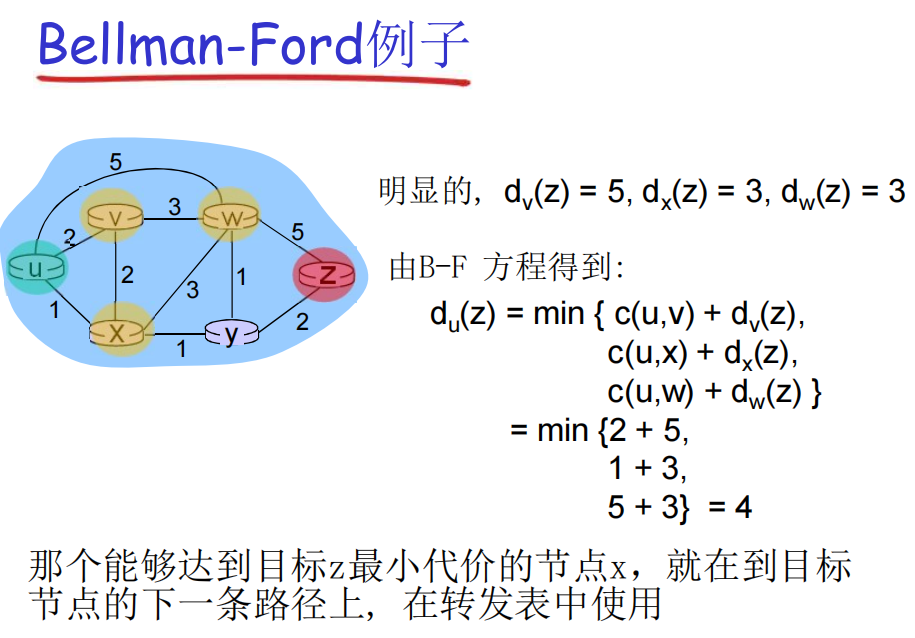
下面几张 ppt 是对距离矢量算法的细节补充。


5.3 因特网中自治系统内部的路由选择
5.2 中介绍了两种路由选择算法,5.3 将分别介绍基于两个算法实现的协议:
- RIP: 基于 距离矢量算法 实现的内部路由协议
- OSPF: 基于 链路状态算法 实现的内部路由协议
RIP( Routing Information Protocol )
RIP 原理
前面说过,距离矢量算法中,每个节点都会将自己的距离矢量估计值传送给邻居,定时或者 DV 有变化时都会触发这个传送过程。
然而,作为对算法的具体实现,RIP 相较于算法本身存在一些局限性(这可能就是理想向现实的妥协吧…),如下所述:
-
默认每一跳都具有相同的成本,只使用跳数作为路径选择的度量单位。
- 在 距离矢量算法中,我们知道,节点 A 的邻居 C 向 A 传递的是 C 到其他节点的代价信息,在这里,我们考虑的并不是有多少跳,而是它的实际代价,这显然是选择最优路径的正确做法。可是在 RIP 中,默认每一跳的成本相同,只使用跳数作为路径选择度量单位,这样就容易引发这样一个问题:跳数少的路径的实际代价反而更大,如此一来,RIP 得到的就是次优路径。
-
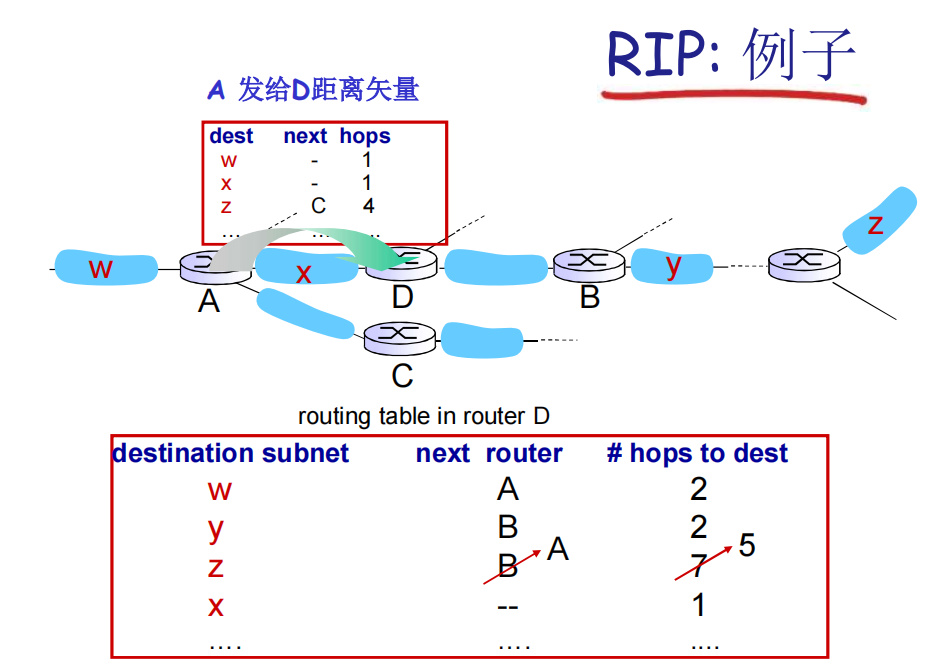
节点间交换的距离矢量通告(DV),至多只能包含 25 个网络,最远距离为 15 跳。
-
参考图片中的例子,A 向 D 发送的距离矢量中,最多只能有 25 个 destination subnet,hops to dest 最多只能是 15。于是,总跳数超过 15 的网络将无法被访问到。
-
这一点限制了 RIP 只能用在小型网络中
-
RIP 进程处理
比较有趣的是,RIP 作为网络层的协议,它的实现却用到了应用层和传输层的东西,具体如下:
- RIP 以应用进程的方式实现
- 通告报文遵循 UDP 协议进行传送,周期性重复
- RIP 协议使用了传输层的服务,以应用层实体的方式实现
OSPF( Open Shortest Path First )
OSPF 原理
OSPF 协议是对 链路状态算法 的实现,因此,它使用的路由算法就是 Dijstra 算法。每个节点中都会保存一个全局的网络拓扑,就像有一张世界地图,清楚的知道有哪些路径可以让我通向目标节点,这条路径的代价又是多少,这点相比 RIP 无疑是巨大的改进。除此之外,相比 RIP,**OSPF 还允许有多个代价相同的路径存在。**在 RIP 中,通往每个子网的最短路径只会保留一条(且不说这个由跳数得来的路径是不是最优)。
层次性的 OSPF 路由
大型网络中支持层次性的OSPF,通常有两个级别的层次:本地和骨干。链路状态的通告只在本地范围内进行,每一个节点只拥有本地区域的拓扑信息。
重要概念:
- 区域边界路由器(Area Border Router,ABR)
- (地方选派到政府的“通讯委员”)
- 负责汇总自己到本区域内其他网络的距离,经由骨干区域向其他区域边界路由器通告
- 骨干路由器(Backbone Router,BBR)
- (政府大楼里的工作人员)
- 只负责在骨干区域内运行 OSPF 路由,处理从各 ABR 间传递上来的通告
5.4 ISP 之间的路由选择
层次路由
- 含义:将互联网分成一个个 AS(路由器区域)
- 某个区域内的路由器集合叫做“自治系统”(Autonomous Systems, AS)
- 每个 AS 用 AS Number(ASN)唯一标识
- 一个 ISP 可能包含一个或多个 AS
在这种划分下,路由变成了2个层次:
- AS 内部路由
- 同一个 AS 内路由器运行相同的路由协议,称为
intra-AS routing protocol,内部网关协议 - 不同的 AS 可能运行着不同的内部网关协议
- 连接其他 AS 的路由器叫做
网关路由器
- 同一个 AS 内路由器运行相同的路由协议,称为
- AS 外部路由
- 运行
inter-AS routing protocol,外部网关协议 - 解决 AS 之间的路由问题,完成 AS 之间的互联互通
- 运行
互联网 AS 间路由:BGP
BGP 基础
上面讲述过的两种路由协议:RIP 和 OSPF,都是用于在 AS 内部间交换路由信息的,那么不同 AS 的网关路由器是如何交换路由信息的呢?这里就需要用到 BGP(Border Gateway Protocol)。
-
BGP 提供给每个 AS 以下方法/协议:
-
eBGP(external BGP)
- 从相邻的 AS 那里获得子网可达信息
-
iBGP(internal BGP)
- 将获得的子网可达信息扩散到 AS 内部的所有路由器
-
-
BGP 基于 距离矢量算法 实现。
- 然而不仅仅是距离矢量,它还会传递到达各个目标的详细路径,即由 ASN 构成的列表
-
网关路由器同时运行 eBGP 和 iBGP 协议。
BGP 路径通告
两个 BGP 路由器之间在一个半永久的 TCP 连接上交换 BGP 报文,从而告诉对方通往不同目标子网前缀的路径。

如上图所示,AS3 的网关路由器 3a 会告诉 AS2 的网关路由器 2c:“你把向 X 发送的数据交给我就好,我帮你转给它。”如此,3a 就会成为 2c 关于 X 的下一跳。AS2 内除 2c 外的其他路由器,都可以通过 iBGP 协议从 2c 那里得知,如果要向 X 发送数据就要首先发给 2c,再由 2c 发给 AS3。
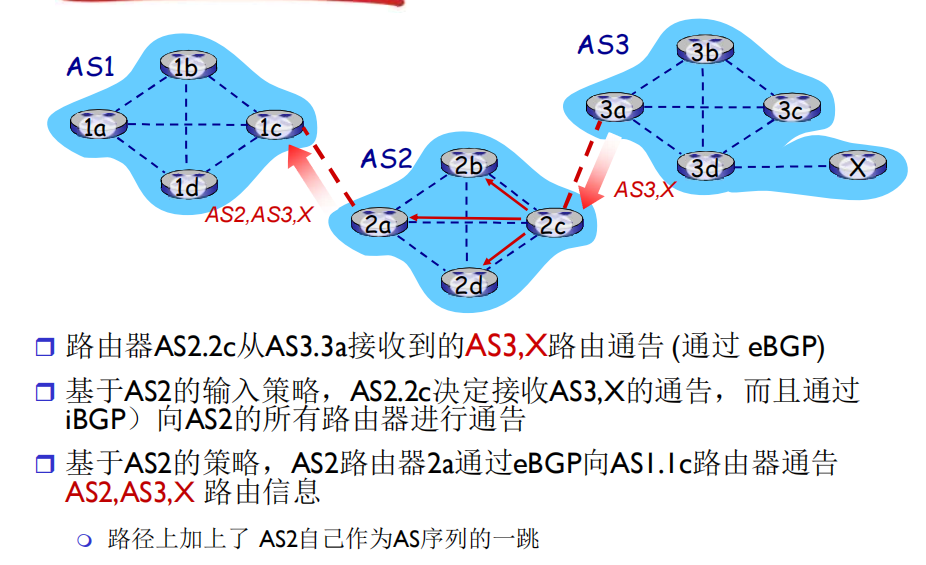
同样地,2a 通过 iBGP 从 2c 那里接收到关于 X 的可达性信息后,会将该信息通过 eBGP 转发给 1c,但是通告中的路径将会把自己加进去,即从AS3,X变成AS2,AS3,X,next-hop 也会从 AS3 变成 AS2。
需要注意的是:
- 由于 BGP 的水平分割,即同一个 AS 中 iBGP 的消息源只能是网关路由器而不能是其他路由器,因此所有路由器都需要与网关路由器直连,这样才能正确接收 iBGP 扩散的通告。
- 网关路由器在向 AS 内的其他路由器通过 iBGP 发送学习来的通告时,并不会改变路由信息中的 NEXT-HOP 这一属性的值,也就是说,2c 从 3a 那里学习到的关于 X 的 next hop 为 3a,那么 2c 告诉给 2d 的也将是:关于 X 的 next hop 为 2c,然而具体传送的时候,由于 iBGP 协议本身的一些功能,2d 会将数据首先发送给 2c(毕竟 2d 本身并没有和 3a 直连,只能通过 2c 转发)
BGP 路径选择
路由器可能获得关于一个网络前缀的多个路径,这时候它必须对路径做出选择,这种选择可以基于如下规则:
- 根据本地偏好策略决定
- 选择 AS 跳数最少的路径
- 热土豆路由
- 选择具备最小内部区域代价的网关作为 X 的出口,不考虑域间代价,类似于贪心算法的思想,只求眼前的最低代价
Chap 6 Link Layer and LANs
这个章节没有重新进行整理,保留了课堂上实时做的笔记,因为原版 ppt 讲的已经很详细了,而我也不想一味地搬运 ppt……
造成的结果就是,重点率提升了,但是重点覆盖率就降低了……
大家按需查看。
课堂笔记
-
包的名称:帧(Frame)
-
在相邻节点之间提供可靠数据传输
- wireless link 往往会有更高的错误发生率
-
link layer 可以看作两部分:
- 更靠近 网络层 的部分:由操作系统 ( cpu ) 实现
- 更靠近 物理层 的部分:由网卡 ( network interface card ) 实现
-
链路层也有 校验和:CRC: cyclic redundancy check 循环冗余校验
- CRC 校验码的生成过程:
- 生成 CRC 校验码:
- 发送方在发送数据之前,会根据特定算法生成一个 CRC 校验码
- 这个校验码根据要发送的数据计算出来
- 附加 CRC 校验码:
- 将生成的 CRC 校验码附加到数据末尾,一起发送给接收方
- 接收方验证 CRC 校验码:
- 接收方接到数据后,使用相同的算法对接收到的数据重新计算一个 CRC 校验码
- 然后,接收方会将计算出来的 CRC 校验码与接收到的 CRC 校验码进行比较
- 若匹配,则数据完整;若不匹配,则数据不完整
- 生成 CRC 校验码:
- 二进制除法:具体操作方法:异或与移位
- 异或:同一 bit 位上,二者相同则结果为 0,否则为 1
- 移位:确保每次异或时,生成多项式的最高位“1”与当前数据的最高位“1”对齐
- CRC 校验码的生成过程:
-
以太网会限制两个节点之间的距离不能超过某个规定值
-
在链路层,IP 地址会被解析成 MAC 地址
- 使用的协议:ARP,地址解析协议
- ARP 工作原理:
- ARP 请求:
- 设备 A 需要发送数据到 IP 地址 X,但它不知道对应的 MAC 地址
- 于是设备 A 会在本地网络广播一个 ARP 请求,该请求的内容为:“谁拥有 IP 地址 X,请告诉我你的 MAC 地址”
- ARP 响应:
- 网络上拥有 IP 地址 X 的设备接收到 ARP 请求后,会回复一个 ARP 响应,该响应包含了 B 的 MAC 地址
- 收到响应后,A 就会将这个 MAC 地址与 IP 地址 X 相关联,并保存在其 ARP 缓存中以供后续使用。
- ARP 请求:
- ARP 工作原理:
- 使用的协议:ARP,地址解析协议
-
同一网段内的两台主机通信是否需要路由器? - 知乎 (zhihu.com)
(ARP 地址解析、HUB 互联、交换机互联的特性看这个博客)
-
E 如何知道 F 与自己在同一网段?
-
判断是否在同一网段:
- E 使用自己的 IP 和 自己的子网掩码做【按位与】得到自己的网段地址;再使用目的地址 (F) 的 IP 和自己 (E) 的子网掩码做【按位与】得到一个网段地址。如果两个网段地址相同,则说明 E 与 F 处于同一网段;如果两个网段地址不同,则说明 E 和 F 不在一个网段
-
查看 ARP cache 中是否存在目标 IP 和目标 MAC 的对应关系并进行相应的处理
这时候 E 会查看自己的 ARP cache 中否存有目标 IP 与 目标 MAC 的对应关系
- 如果有,则直接发数据;
- 如果没有
- 且 E 与 F 在同一网段内,则在所在广播域内广播一个 ARP 请求来获取 F 对应的 MAC 地址。得到回答后,将这组对应关系存在 ARP cache 中并向对应的 MAC 发送数据
- 且 E 与 F 不在同一网段内,则在所在广播域内广播一个 ARP 请求来获取 默认网关 对应的 MAC 地址。得到回答后,将这组对应关系存在 ARP cache 中并向对应的 MAC 发送数据
-
-
-
动态路由
-
私有 ip
-
在与外界互联网通信时,私有IP地址通常会通过==“网络地址转换”(NAT)技术==被转换为公有IP地址
-
常见的私有 IP
- 10.0.0.0~10.255.255.255
- 172.16.0.0~172.31.255.255
- 192.168.0.0~192.168.255.255
-
-
VLAN (虚拟局域网)
- 定义:虚拟局域网,是在一个或多个物理局域网上创建的逻辑上分隔的网络。
- 应用场景:
- 同一栋大楼里,不同的企业之间为了隔离数据
- 同一个企业里,不同部门之间为了隔离数据
易错题
-
**(判断)**链路层中,目的 IP 和 目的 MAC 一定指代同一个节点
- ==错误。==不一定指代同一个节点。
- 目的 IP 恒为目标节点,但是 目的 MAC 有可能是网关端口的 MAC 地址。
-
**(填表格)**ARP 请求 和 ARP 回复 都是数据包,填表的时候,如果题目表明最开始的 ARP cache 为空,那么一定要把 ARP 请求 和 ARP 回复也作为传输的数据对待,来写入表格。
- ARP 请求/回复 中,未知 MAC 用
FF-FF-FF-FF-FF-FF来表示
- ARP 请求/回复 中,未知 MAC 用
-
由同一个交换机连接的两个主机一定可以互相访问到吗?
- 不一定。如果存在 VLAN 配置,那么由同一个交换机连接的两个主机可能无法互相访问。
TCP的三次握手和四次挥手
1. 什么是三次握手?
当一个TCP实体想要与另一个TCP实体建立连接时,它首先会向对方发送一个数据包,名为syn包,然后它将处于syn-send状态;如果对方同意连接,则回复一个syn+ACK包;发送方收到syn+ACK包后,会回复一个ACK包,此时连接建立。
因为这个过程中双方总共发送了三次包,所以称为三次握手
2. 为什么不能是两次握手呢?
为什么不能两次握手,服务端回复syn+ACK之后就建立连接呢?为了防止已经失效的请求报文突然传到服务端而引发错误。
假设现在客户端向服务端发送了一个syn包,但是因为某些原因并没有到达服务器,当客户端的计时器到时间后,就会重新发送一个syn包,这个包安全抵达服务端,服务端向其返回syn+ACK,连接建立,然而,之后的某一时刻,原先没有到达服务端的syn包突然抵达服务端,于是服务端以为是客户端请求向它重新建立一个连接,于是再两次握手之后,建立新的连接,并进入数据等待状态。此时,服务器端认为是两个连接,而客户端认为是一个连接,造成了状态不一致。
如果在三次握手下,服务端收不到最后的ACK包,就不会建立连接。
所以三次握手本质上就是为了解决网络信道不可靠的问题,在不可靠的信道上建立可靠连接。经过三次握手后,客户端和服务端都进入数据传输状态。
3. 什么是四次挥手?
处于连接状态的客户端和服务端,都可以发送关闭连接的请求,此时需要经过四次挥手。
本质上就是为了在不可靠的网络信道中进行可靠的连接断开。
- 假设现在客户端主动发起连接关闭请求,它需要向服务端发送一个
fin包,自己则进入fin-wait-1状态; - 服务端收到包后,向客户端发送一个
ACK包,表示自己进入了close-wait状态,即不再从客户端接收数据,此时客户端进入fin-wait-2状态;但是这时候二者的连接还没有断掉,因为服务端可以还有没发完的数据 - 于是等服务器这边ok之后,它会向客户端发送一个
fin包,自己进入last-ACK状态; - 客户端收到之后,向服务端发送一个
ACK,自己则进入time-wait状态(超时时间),经过超时时间后关闭连接,进入closed状态;
(注:这里客户端为什么设置一个超时时间呢?)
为了保证对方成功收到ACK包。假设客户端在释放ACK后就关闭连接,一旦这个包丢失了,那服务端那边就关不掉了。而如果客户端在发送完最后一个包后等待一段时间,这是服务端因为没有收到ACK包,会重新发送fin包,这时候客户端会对其作出响应,重发ACK包并刷新超时时间 - 服务端收到
ACK后立即关闭连接。
期中考试
- 服务器 (server) 不在网络核心,而在网络边缘
- 用户发送请求获取含子模块的网页时,一次请求对应只能得到一个response
- 无论是两种邮件传输方式中的哪一种,核心步骤(链接发送方与接收方)采用的协议都是SMTP
- 1的补码即取反
- 请求一个包含数个小objects的web page时,不管是否可持续是否pipeline,主文档的获得都是与其他小objects相互独立的。换言之,如果请求一个包含5个小objects的web page,那么实际上是申请了6个objects,且是否pipeline只是针对后面的小组件,主文档与后面的小组件总是独立的。















 3980
3980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









