






 文章探讨了LLM发展中decoder-only架构的主导地位,通过对比encoder-only和encoder-decoder模型,解释了decoder-only在few-shot和zero-shot任务中的优势,重点提及了GPT-3和Transformer的影响。
文章探讨了LLM发展中decoder-only架构的主导地位,通过对比encoder-only和encoder-decoder模型,解释了decoder-only在few-shot和zero-shot任务中的优势,重点提及了GPT-3和Transformer的影响。
一、写作动机
关注这个问题呢,主要是源于这篇论文Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond对我的启发,这篇文章也许你没有听说过,但我想下面这个LLM进化树,你大概是见过的。
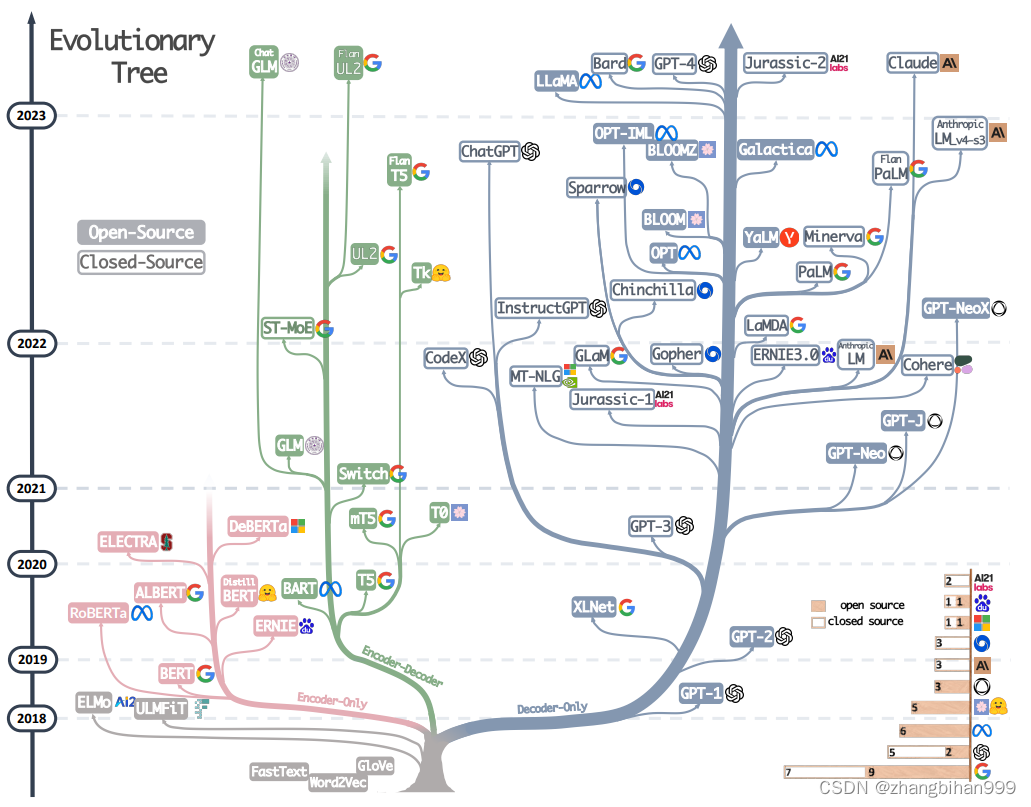
在此,我想先参考原作,对这张图作简要介绍,有兴趣想要了解更多的小伙伴可以移步至上方标题处链接,阅读原论文。
图例说明:
-
粉色枝为encoder-only派系;绿色枝为encoder-decoder派系;灰色枝为decoder-only派系
-
模型在时间轴上的垂直位置表示它们的发布日期
-
开源模型用实心方框表示,闭源模型用空心方框表示
-
右下角的堆叠条形图显示了来自不同公司和机构的模型数量。
原作中对LLM进化树的分析:
-
decoder-only模型已经逐渐统治了LLM的发展。在2021年之前,decoder-only模型的受欢迎程度还不及encoder-only和encoder-decoder模型,直到2021年GPT-3的出现,让decoder-only模型的发展迎来了大爆发。
-
OpenAI仍在LLM领域保持着领导力
-
Meta在开源大模型和促进大模型发展方面有着杰出贡献。它在LLM的开源社区发挥了重要作用,而且他家的所有LLM都是开源的,很慷慨的一家公司
-
大模型整体呈现出闭源趋势。这给学术研究人员在LLM训练上开展实验造成了困难,所以现在的很多研究就都成了基于API的研究
-
encoder-decoder模型仍然很有前途,因为这种架构的模型还在积极探索之中,并且其中大多数都是开源的。谷歌在这方面做了很多工作,但是decoder-only模型的灵活性和多功能性让谷歌在这个方向上的希望略显渺茫
可以看到,基于LLM进化树的第一条分析就是:decoder-only模型已经逐渐统治了LLM的发展,这也不由得让人思考,为什么现在的LLM都是decoder-only架构,它相比encoder-only和encoder-decoder架构有怎样的优势呢?个人感觉某乎上这位大佬对本问题的分析已经很透彻了,有需要的朋友可以移步链接为什么现在的LLM都是Decoder only的架构?。
那么这篇文章呢,也是站在大佬的肩膀上,记录我对这个问题的一些思考。
二、问题解答
ok,我们不妨也采用模拟面试的方法来解答这个问题。
现在,假如面试官向你发问:“为什么现在的LLM都是decoder-only架构?”
短暂的惊愕过后,你脑海中应该呈现出这样的思考路线:
-
首先说明现在有哪些模型架构。
-
简要介绍各种架构的训练方法并作简单的对比分析
-
重申decoder-only架构的优势
基于思考路线,以下是笔者的一个示例回答:
(1.首先说明现在有哪些模型架构)
自Transformer出现以来,业界共发展出三个模型派系。
以BERT为代表的encoder-only架构,以T5为代表的encoder-decoder架构,以及以GPT为代表的decoder-only架构。
(2.简要介绍各种架构的训练方法并作简单的对比分析)
那我们逐个分析各个架构。
首先是BERT派系,这一派模型采用的是MLM的预训练方式,可以理解为它做的是完形填空任务,这种训练方式,让模型有了强劲的理解token间的关系和上下文的能力,这也使得它们在情感分析和命名实体辨别等分类任务上有着出色的表现。
再来看GPT派系,这一派模型采用的预训练方式是自回归,做的任务是predict next token,如果把MLM比作完形填空,那么笔者有一个不成熟的比喻,就是把预测next token比作写作文。这也就能够通俗地理解为什么后者会有更好的泛化性能了(毕竟写作文的可发散性比完形填空强)。
最后来看T5派系,这一类模型采用的是encoder-decoder架构,并在encoder中引入了双向attention,理论上它兼具BERT的理解能力和GPT的生成能力,但依然没能够撼动decoder-only架构的地位。为什么呢?有大佬根据自己的实验为什么现在的LLM都是Decoder only的架构? 提出,双向attention的注意力矩阵存在低秩问题,这会削弱模型的表达能力,就文本生成任务而言,引入双向注意里没有实质性的好处。反观decoder-only架构的attention矩阵,呈下三角架构,因此它必然满秩,理论上有更好的表达能力。
(3.重申decoder-only架构的优势)
那么decoder-only架构究竟优越在哪里呢?
我想最主要的是它在few-shot和zero-shot任务上优越的性能。
首先是在few-shot任务上,有研究表明 Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers ,prompt和in-context learning让decoder-only模型在few-shot任务中有着比encoder-decoder架构更好的表现,也就是说,我们可以通过思维链和提示工程让模型有更好的表现。
其次是在zero-shot任务上,有研究表明 What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization? ,自回归训练的模型在zero-shot任务上的表现是最优秀的。我想这是很关键的一大优势,毕竟在实际应用中,我们无法奢求能够对模型进行全方位的训练哪怕只是few-shot训练,因此zero-shot场景是模型无法避免的,这就对模型的泛化能力和上限提出了很高的要求,而这也正是decoder-only模型最大的优势。
三、参考文献
[1] Yang J, Jin H, Tang R, et al. Harnessing the power of llms in practice: A survey on chatgpt and beyond[J]. arXiv preprint arXiv:2304.13712, 2023.
[2] Dai D, Sun Y, Dong L, et al. Why can gpt learn in-context? language models secretly perform gradient descent as meta optimizers[J]. arXiv preprint arXiv:2212.10559, 2022.
[3] Wang T, Roberts A, Hesslow D, et al. What language model architecture and pretraining objective works best for zero-shot generalization?[C]//International Conference on Machine Learning. PMLR, 2022: 22964-22984.















 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









