






损失函数
每一个样本数据经过模型后会得到一个预测值,然后得到的预测值和真实值的差值就成为损失,得到这个损失的值的函数称为损失函数(目标函数)。许多不同种类的损失函数,这些函数本质上就是计算预测值和真实值的差距的一类型函数,然后经过库的封装形成了有具体名字的函数。
import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32) #预测值
targets = torch.tensor([1, 2, 5], dtype=torch.float32) #目标值
inputs = torch.reshape(inputs,(1, 1, 1, 3))
targets = torch.reshape(targets,(1, 1, 1, 3))
loss = L1Loss(reduction='sum') #求和,默认求平均
result = loss(inputs, targets)
loss_mse = nn.MSELoss() #实例化对象
result_mse = loss_mse(inputs, targets) #对象调用默认函数
print(result)
print(result_mse)
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3)) #有3类
loss_cross = nn.CrossEntropyLoss() #对于分类的函数
result_cross = loss_cross(x,y)
print(result_cross)
梯度下降法
梯度下降法求函数的最小值,梯度即函数的导数。

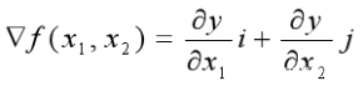
反向传播
是一种逆向计算的方法,具体理解可以参考:“反向传播算法”过程及公式推导(超直观好懂的Backpropagation)_aift的博客-CSDN博客
三者联系
在初次接触看到这些名词时,只单独进行了学习了它们的原理算法,但还不理解其在神经网络模型中所发挥的作用以及它们之间的联系。在经过对一些模型的训练后,我总结出了更加适合小白理解的大白话思路。
首先在模型中有计算公式,其中计算公式中的参数(权重,偏置)决定了这个计算公式是否准确。在导入训练集训练时,会得到实际值。通过损失函数可以计算出实际值和预测值的误差值。利用梯度下降法求得损失函数的最小值。此时损失函数得到一个数据可以使误差值最低,再利用反向传播法计算出对应的计算公式中的参数,从而使计算公式中的参数更加优化,训练出更加优化的模型。















 2138
2138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









