







1.损失函数
-
衡量模型性能: 损失函数能够量化模型的预测结果与实际标签之间的误差。通过最小化损失函数,我们可以使得模型的预测结果尽可能接近实际标签,从而提高模型的性能。
-
指导模型学习: 在训练过程中,优化算法(比如梯度下降)使用损失函数的梯度信息来更新模型参数。通过最小化损失函数,模型可以根据训练数据不断调整自身的参数,使得预测结果更加准确。
2.L1loss函数
该函数在Pytorch官网解释如下:

计算示例如下:
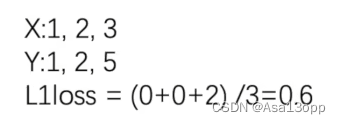
代码示例:
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss = L1Loss() # 默认为 maen
result = loss(inputs,targets)
print(result)result: tensor(0.6667)
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss = L1Loss(reduction='sum') # 修改为sum,三个值的差值,然后取和
result = loss(inputs,targets)
print(result)RESULT: tensor(2.)
2.MSE损失函数
该函数在Pytorch官网解释如下:

import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs,targets)
print(result_mse)result:tensor(1.3333)
4.交叉熵损失函数
交叉熵损失函数数学公式如下图所示:
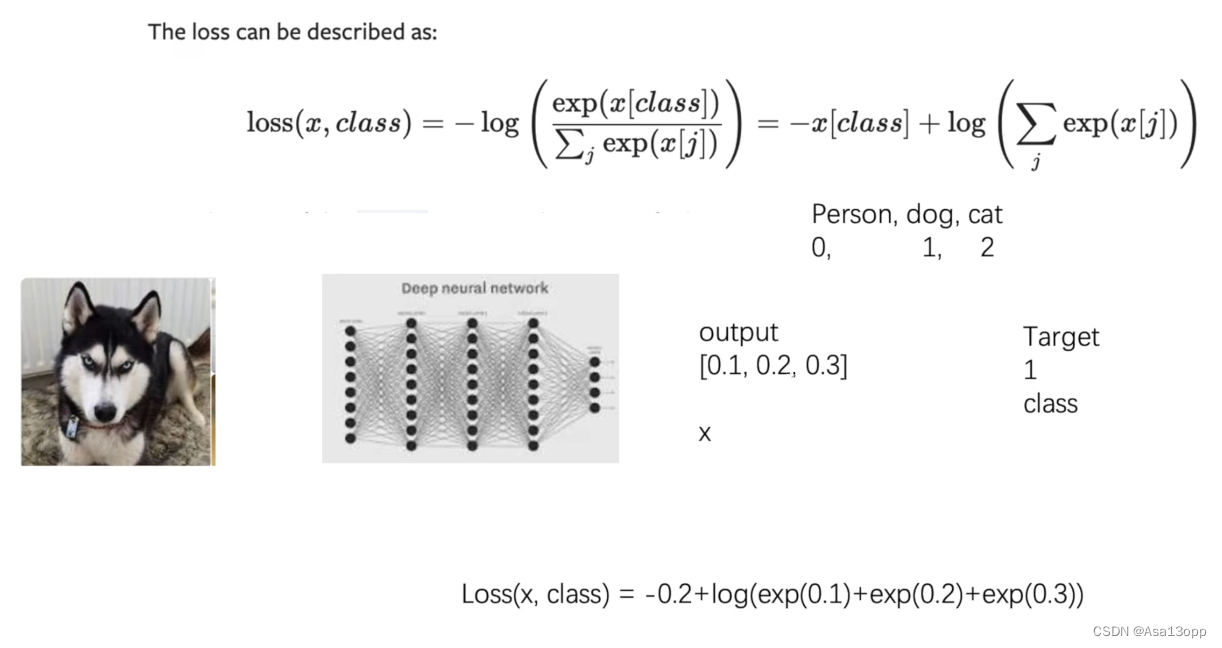
import torch
from torch.nn import L1Loss
from torch import nn
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3)) # 1的 batch_size,有三类
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x,y)
print(result_cross)result:tensor(1.1019)
5.数据集计算损失函数
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss() # 交叉熵
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets) # 计算实际输出与目标输出的差距
print(result_loss)Files already downloaded and verified tensor(2.2994, grad_fn=<NllLossBackward0>) tensor(2.2952, grad_fn=<NllLossBackward0>) tensor(2.3162, grad_fn=<NllLossBackward0>) tensor(2.3234, grad_fn=<NllLossBackward0>) tensor(2.2983, grad_fn=<NllLossBackward0>) tensor(2.3051, grad_fn=<NllLossBackward0>)……
6.损失函数反向传播
损失函数的反向传播(Backpropagation)是深度学习中用于训练神经网络的关键算法。在训练过程中,我们的目标是最小化损失函数,使得模型的预测结果尽可能接近实际标签。反向传播算法是一种计算梯度的方法,它允许我们根据损失函数的梯度信息来更新神经网络的参数,使得损失函数逐渐减小,从而提高模型的性能。
以下是损失函数反向传播的基本步骤:
前向传播(Forward Propagation): 首先,通过神经网络的前向传播过程,将输入数据送入网络,逐层计算神经网络的输出值(预测值)。
计算损失(Compute Loss): 使用损失函数计算预测值与真实标签之间的差距(损失值)。损失函数的选择通常依赖于具体的问题类型。
反向传播(Backward Propagation): 反向传播是指从损失函数开始,沿着神经网络的反方向计算损失函数对每个参数的梯度。这是通过链式法则实现的,将梯度从输出层传递回输入层。
计算输出层的梯度: 首先,计算损失函数对输出层的输出的梯度。
计算隐藏层的梯度: 然后,使用链式法则,将输出层的梯度向前传递到隐藏层,并计算隐藏层的梯度。
更新参数: 最后,使用计算得到的梯度信息,通过梯度下降或其它优化算法,更新神经网络的参数,减小损失函数的值。
迭代优化: 重复进行前向传播、损失计算和反向传播的过程,直到损失函数收敛到一个满意的值或达到预定的训练次数。
通过反向传播,神经网络能够根据损失函数的梯度信息,调整网络中的权重和偏置,从而使得网络的预测结果逐渐接近实际标签,实现模型的训练和优化。
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss() # 交叉熵
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets) # 计算实际输出与目标输出的差距
result_loss.backward()
# 计算出来的 loss 值有 backward 方法属性,反向传播来计算每个节点的更新的参数。
#这里查看网络的属性 grad 梯度属性刚开始没有,反向传播计算出来后才有,
#后面优化器会利用梯度优化网络参数。 7.优化器
在深度学习中,优化器(Optimizer)是一种用于最小化(或最大化)损失函数的算法。它的主要作用是根据损失函数的梯度信息,调整模型的参数,使得损失函数逐渐减小,从而提高模型的性能。不同的优化器采用不同的策略来更新模型的参数。
以下是一些常用的优化器:
梯度下降法(Gradient Descent): 是最基本的优化算法之一。它根据损失函数的梯度信息,以学习率为参数,沿着梯度的反方向更新模型的参数,使得损失函数逐渐减小。
随机梯度下降法(Stochastic Gradient Descent,SGD): 是梯度下降法的变种,每次迭代中只随机选择一个样本来计算梯度并更新参数。SGD的优势在于对大规模数据集的训练速度较快。
批量梯度下降法(Batch Gradient Descent): 在每次迭代中,使用整个训练数据集计算梯度。这种方法通常能够更准确地估计梯度,但计算开销较大。
小批量梯度下降法(Mini-batch Gradient Descent): 是SGD和批量梯度下降法的折中方案。每次迭代中,随机选择一小部分样本(mini-batch)来计算梯度并更新参数。这种方法通常被广泛使用,因为它兼具计算效率和梯度估计的准确性。
自适应学习率优化器: 这类优化器根据参数的历史梯度信息自适应地调整学习率。常见的自适应学习率优化器包括Adagrad、RMSprop和Adam。它们分别考虑了参数的历史梯度平方和、指数加权移动平均以及梯度的一阶和二阶矩估计,以动态地调整学习率,提高了训练的效率和稳定性。
学习率衰减(Learning Rate Decay): 在训练过程中逐渐降低学习率,使得模型在接近最优解时更加稳定。学习率衰减可以与上述任何一种优化器结合使用。
优化器使用步骤:(以SGD为例)
#构造一个优化器对象
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
for input, target in dataset:
optimizer.zero_grad() #梯度要清零,如果梯度不清零会导致梯度累加。
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step() #所有优化器都实现了一个step()方法,用于更新参数。3.神经网络优化多轮
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss() # 交叉熵
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(),lr=0.01) # 随机梯度下降优化器
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets) # 计算实际输出与目标输出的差距
optim.zero_grad() # 梯度清零
result_loss.backward() # 反向传播,计算损失函数的梯度
optim.step() # 根据梯度,对网络的参数进行调优
running_loss = running_loss + result_loss
print(running_loss) # 对这一轮所有误差的总和4.神经网络学习率优化
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss() # 交叉熵
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(),lr=0.01) # 随机梯度下降优化器
scheduler = torch.optim.lr_scheduler.StepLR(optim, step_size=5, gamma=0.1)
# 每过 step_size 更新一次优化器,更新是学习率为原来的学习率的的 0.1 倍
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets) # 计算实际输出与目标输出的差距
optim.zero_grad() # 梯度清零
result_loss.backward() # 反向传播,计算损失函数的梯度
optim.step() # 根据梯度,对网络的参数进行调优
scheduler.step() # 学习率太小了,所以20个轮次后,相当于没走多少
running_loss = running_loss + result_loss
print(running_loss) # 对这一轮所有误差的总和优化结果:
tensor(357.9097, grad_fn=<AddBackward0>)
tensor(351.5848, grad_fn=<AddBackward0>)
tensor(329.7575, grad_fn=<AddBackward0>)
tensor(315.6645, grad_fn=<AddBackward0>)
tensor(307.6896, grad_fn=<AddBackward0>)
tensor(299.2968, grad_fn=<AddBackward0>)
tensor(290.0585, grad_fn=<AddBackward0>)
tensor(282.6966, grad_fn=<AddBackward0>)
tensor(275.7931, grad_fn=<AddBackward0>)
tensor(269.5059, grad_fn=<AddBackward0>)
tensor(263.6960, grad_fn=<AddBackward0>)
tensor(258.2791, grad_fn=<AddBackward0>)
tensor(253.1974, grad_fn=<AddBackward0>)
tensor(248.5044, grad_fn=<AddBackward0>)
tensor(244.2687, grad_fn=<AddBackward0>)
tensor(240.4644, grad_fn=<AddBackward0>)
tensor(236.9770, grad_fn=<AddBackward0>)
tensor(233.7112, grad_fn=<AddBackward0>)















 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









