






Python爬虫项目:纯原创!!!数据库,可视化等如图
小众好用,源码+项目报告~
详细介绍:
从中国水稻数据网(https://www.ricedata.cn/variety/index.htm)爬取各省份的水稻品种信息,并进行数据清洗、集成、保存到数据库以及数据分析和可视化。具体功能包括:
1. 获取省份名称和链接:从网站的品种索引页面提取各省份的名称和对应的链接,排除特定省份(如青海、西藏、钓鱼岛、台湾、香港、澳门)。
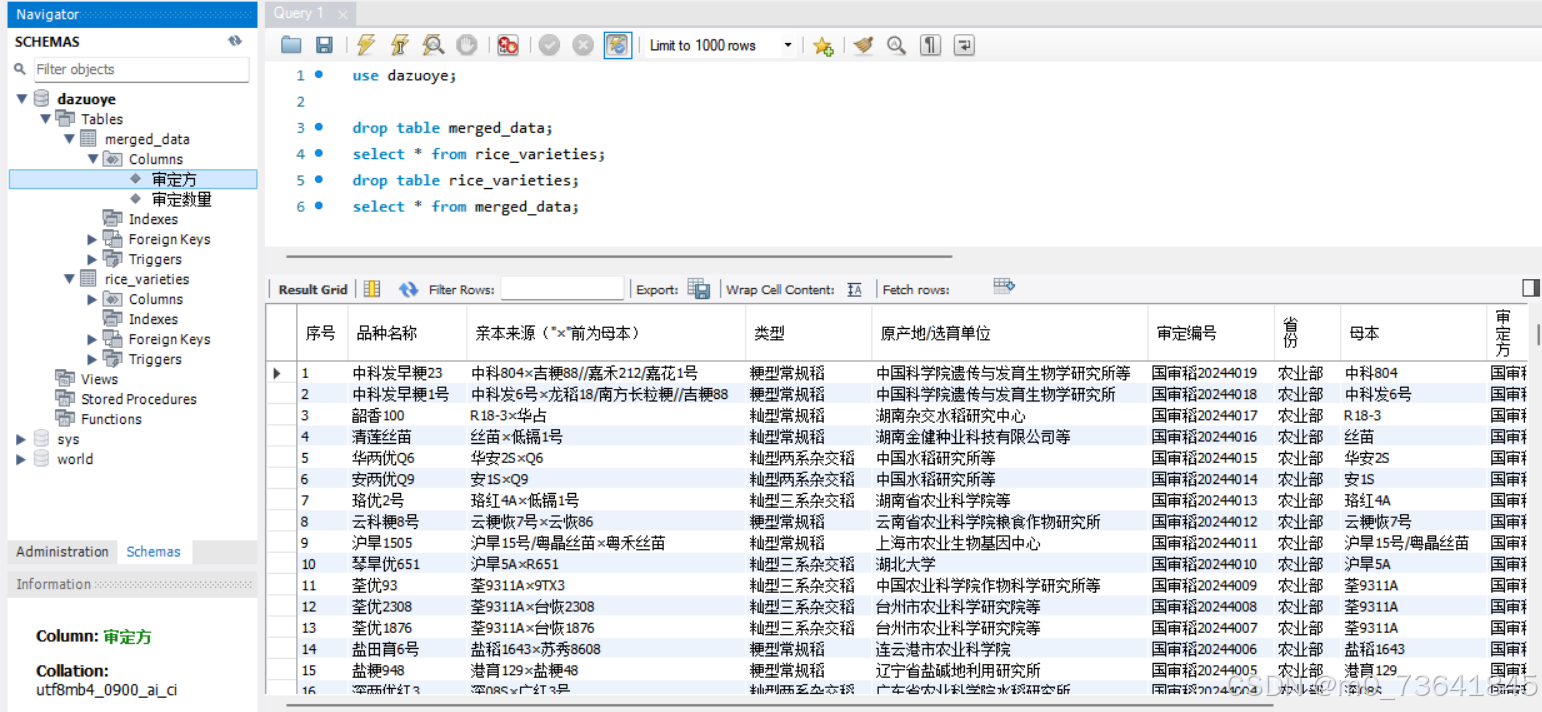
2. 并行爬取数据:使用 Ray 并行框架,同时爬取多个省份的水稻品种数据。每个省份的数据包括品种名称、母本来源、审定编号、审定方、原产地/选育单位等信息。
3. 数据清洗:去除无效或重复的数据,提取和清理关键字段,如母本来源、审定方、审定公司等。
4. 数据集成:将清洗后的数据进行整合,生成审定方审定数量统计和水稻类型数量统计等汇总数据。
5. 数据保存:将爬取和清洗后的数据保存到 MySQL 数据库中,方便后续查询和使用。
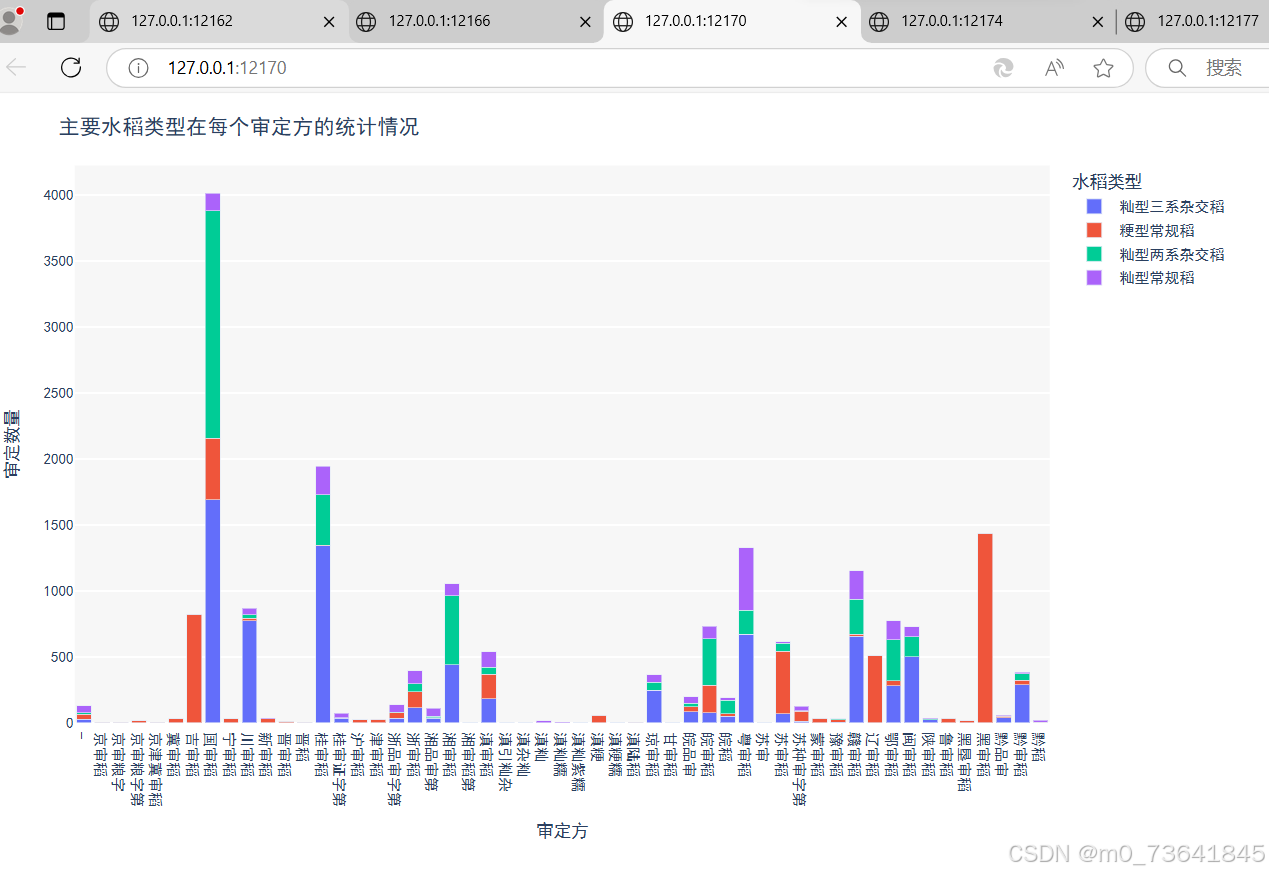
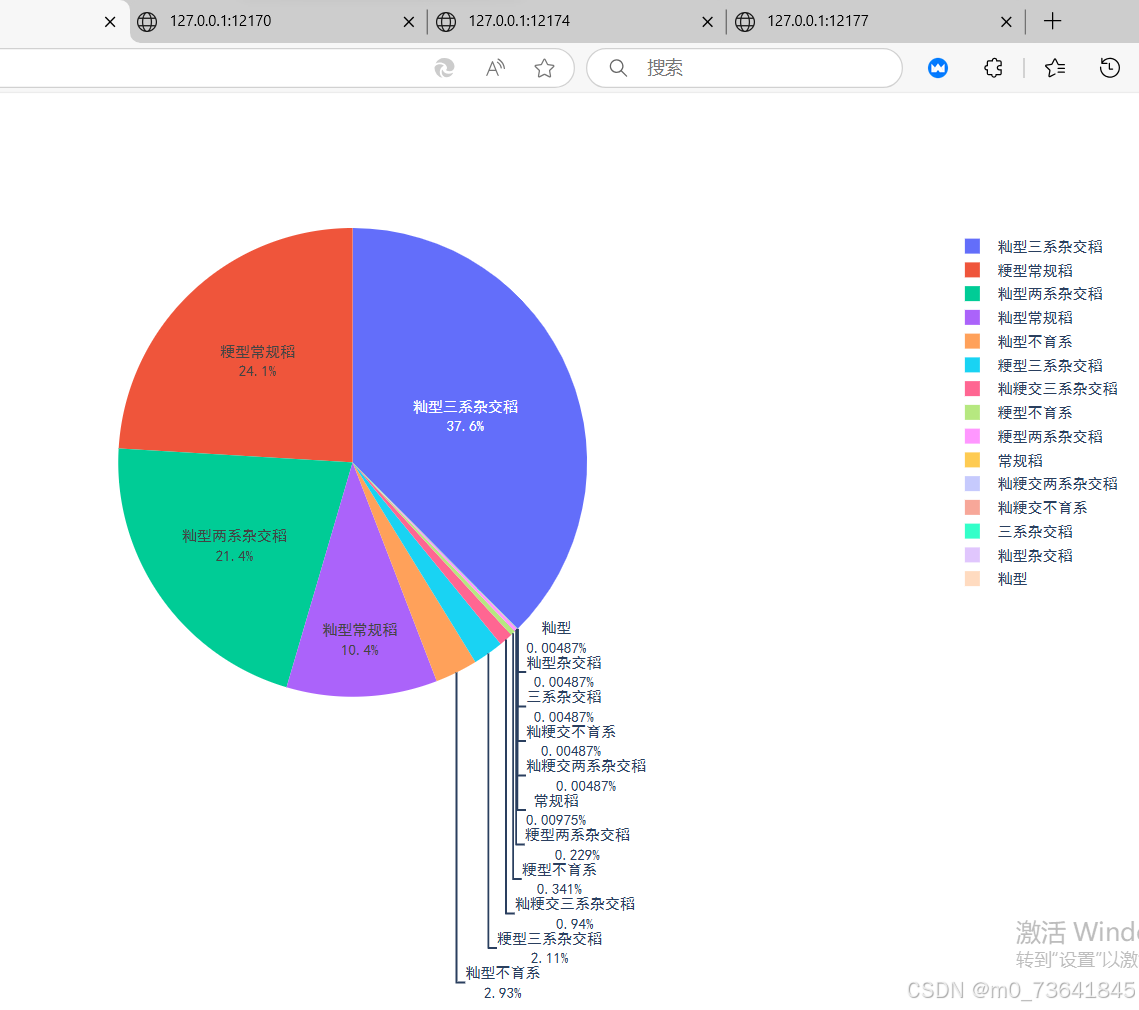
6. 数据分析和可视化:利用 Plotly 库生成各种图表,包括审定方审定数量的条形图、水稻类型的占比饼图、主要水稻类型在每个审定方的堆叠柱状图、TOP 5 审定方的详细审定数量分布图以及审定数量随年份变化的折线图,直观展示数据特点和趋势。





















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











