






目录
小车可以运行成功,但是如果标志距离摄像头远了或者偏移距离大就会出现识别不到的情况。我认为可以再训练一个识别模型,先识别出图像中的标志,再对标志进行分类,指导小车行驶。本文只训练了分类模型。
一、模型训练
1、下载数据集
这里使用的是Chinese Traffic Sign Database中的数据集
下载
https://nlpr.ia.ac.cn/pal/trafficdata/tsrd-train.zip
https://nlpr.ia.ac.cn/pal/trafficdata/TSRD-Train%20Annotation.zip
2、训练分类模型
这里使用pytouch框架进行训练,预训练模型使用的是ResNet18,在此基础上进行微调
训练代码
#train.py
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models
from PIL import Image
from tqdm import tqdm # 导入 tqdm 库
# 数据集类
class TrafficSignDataset(Dataset):
def __init__(self, annotation_file, image_dir, transform=None):
self.image_paths = []
self.labels = []
# 读取注释文件
with open(annotation_file, 'r') as f:
for line in f:
parts = line.strip().split(';')
# 检查行内的字段数目是否正确
if len(parts) < 8: # 必须包含至少 8 个字段
print(f"Warning: Skipping invalid line (incorrect number of fields): {line}")
continue
image_path = parts[0] # 图片路径
try:
label = int(parts[-2]) # 标签位于倒数第二位
except ValueError:
print(f"Warning: Invalid label value (skipping): {line}")
continue
# 收集图片路径和标签
self.image_paths.append(image_path)
self.labels.append(label)
# 打印出一些调试信息
print(f"Loaded {len(self.image_paths)} samples.")
if len(self.image_paths) > 0:
print(f"Example image path: {self.image_paths[0]}")
print(f"Example label: {self.labels[0]}")
self.image_dir = image_dir
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image_path = os.path.join(self.image_dir, self.image_paths[idx])
# 检查图像是否存在
if not os.path.exists(image_path):
print(f"Warning: Image {image_path} not found!")
return None, None
image = Image.open(image_path)
label = self.labels[idx]
if self.transform:
image = self.transform(image)
return image, label
# 数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 创建数据集和数据加载器
annotation_file = 'C:/Users/user/Desktop/vs.code/python/chinese_traffic/TsignRecgTrain4170Annotation.txt'
image_dir = 'C:/Users/user/Desktop/vs.code/python/chinese_traffic/tsrd-train'
train_dataset = TrafficSignDataset(
annotation_file=annotation_file,
image_dir=image_dir,
transform=transform
)
# 确保数据集加载成功
print(f"Train dataset size: {len(train_dataset)}")
# 如果数据集为空,终止训练
if len(train_dataset) == 0:
raise ValueError("No data found. Please check the dataset paths and labels.")
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 模型构建(使用预训练的ResNet18模型)
model = models.resnet18(pretrained=True)
model.fc = nn.Linear(model.fc.in_features, 58) # 修改输出类别为58,全连接层58类
# 损失函数和优化器
criterion = nn.CrossEntropyLoss() #损失函数CrossEntropyLoss(),适合多分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001) #优化器Adam,学习率0.001
# 确定设备(使用 GPU 如果可用,否则使用 CPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device) # 将模型移到设备上
# 训练模型
num_epochs = 10 #训练10轮
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
# 使用 tqdm 显示进度条
with tqdm(train_loader, unit='batch', desc=f"Epoch {epoch+1}/{num_epochs}") as tepoch:
for images, labels in tepoch:
# 跳过无效的数据(如果读取时失败)
if images is None or labels is None:
continue
images = images.to(device) # 将数据移到设备上
labels = labels.to(device) # 将标签移到设备上
optimizer.zero_grad() #清除之前计算的梯度
outputs = model(images) #前向传播,通过模型得到预测结果
loss = criterion(outputs, labels) #计算损失
loss.backward() #反向传播,计算梯度
optimizer.step() #更新模型参数
# 累积损失和正确预测的样本数
running_loss += loss.item()
_, predicted = torch.max(outputs, 1) # 获取预测的类别标签
total += labels.size(0) #总样本数
correct += (predicted == labels).sum().item() # 统计正确预测的数量
# 更新进度条描述信息
tepoch.set_postfix(loss=running_loss / (total / 32), accuracy=100 * correct / total)
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}, Accuracy: {100 * correct / total:.2f}%')
# 保存模型
torch.save(model.state_dict(), 'traffic_sign_model.pth')
训练结束以后会生成traffic_sign_model.pth,这就是我们的训练结果。
3、检验模型效果
检验我们的模型效果,代码如下:
#test.py
import torch
import cv2
from torchvision import models, transforms
from PIL import Image
import torch.nn.functional as F
# 定义标签(需要和训练时的标签一致)
labels = [
"限速5公里每时","限速15公里每时","限速30公里每时","限速40公里每时","限速50公里每时",
"限速60公里每时","限速70公里每时","限速80公里每时","禁止直行和左转","禁止直行和右转",
"禁止直行","禁止左转","禁止左转和右转","禁止右转","禁止超车",
"禁止掉头","禁止机动车行驶","禁止鸣笛","解除40公里每小时限速","解除50公里每小时限速",
"允许直行和左转","允许直行","允许左转","允许左转和右转","允许右转",
"靠左行驶","靠右行驶","环岛","机动车道","允许鸣笛",
"非机动车道","允许掉头","左右绕行","注意信号灯","注意危险",
"注意行人","注意非机动车","前方学校","向右急转弯","向左急转弯",
"下陡坡","上陡坡","减速慢行","T字路口","T字路口",
"村庄","反向弯路","无人看守铁道路口","前方施工","连续弯路",
"有人看守铁道路口","注意安全","停车让行","禁止通行","禁止停车",
"禁止驶入","减速让行","停车检查"
]
# 图像预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整图像大小为 224x224(ResNet 输入大小)
transforms.ToTensor(), # 转换为 Tensor 格式
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
# 加载训练好的模型
model = models.resnet18(pretrained=True)
model.fc = torch.nn.Linear(model.fc.in_features, 58) # 修改输出类别为58(你的标签数量)
# 加载保存的模型权重
model.load_state_dict(torch.load('C:/Users/user/Desktop/vs.code/python/chinese_traffic/traffic_sign_model.pth'))
model.eval() # 设置为评估模式
# 打开摄像头
cap = cv2.VideoCapture(0)
while True:
# 捕获每一帧图像
ret, frame = cap.read()
if not ret:
print("无法读取摄像头图像")
break
# 将图像从 BGR 转换为 RGB(OpenCV 读取图像为 BGR 格式)
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
pil_image = Image.fromarray(rgb_frame)
# 对图像进行预处理
img_tensor = transform(pil_image)
img_tensor = img_tensor.unsqueeze(0) # 增加批次维度
# 使用模型进行预测
with torch.no_grad():
outputs = model(img_tensor)
# 使用 softmax 转换为概率
probabilities = F.softmax(outputs, dim=1)
# 获取最大概率的类别
max_prob, predicted = torch.max(probabilities, 1)
predicted_label = labels[predicted[0]] # 映射到标签名称
# 检查最大置信度是否低于 0.6
if max_prob.item() < 0.6:
print("未检测到交通标志")
else:
# 输出最大置信度的标签
print(f"Predicted label: {predicted_label} - Confidence: {max_prob.item():.4f}")
cv2.imshow('window_name', frame)
# 输出每个标签的置信度(可选)
# for i, prob in enumerate(probabilities[0]):
# print(f"Label: {labels[i]} - Confidence: {prob.item():.4f}")
# 按 'q' 键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放摄像头资源并关闭所有窗口
cap.release()
cv2.destroyAllWindows()
因为数据集中包含了这58种交通标志,所以我们的标签也要按照索引的顺序进行排列;
在检测代码中,我将阈值置为0.6,如果置信度低于0.6,则输出“未检测到交通标志”。
根据我的测试,模型的分类效果还是不错的,但是不能离镜头太远或者偏离角度过大。
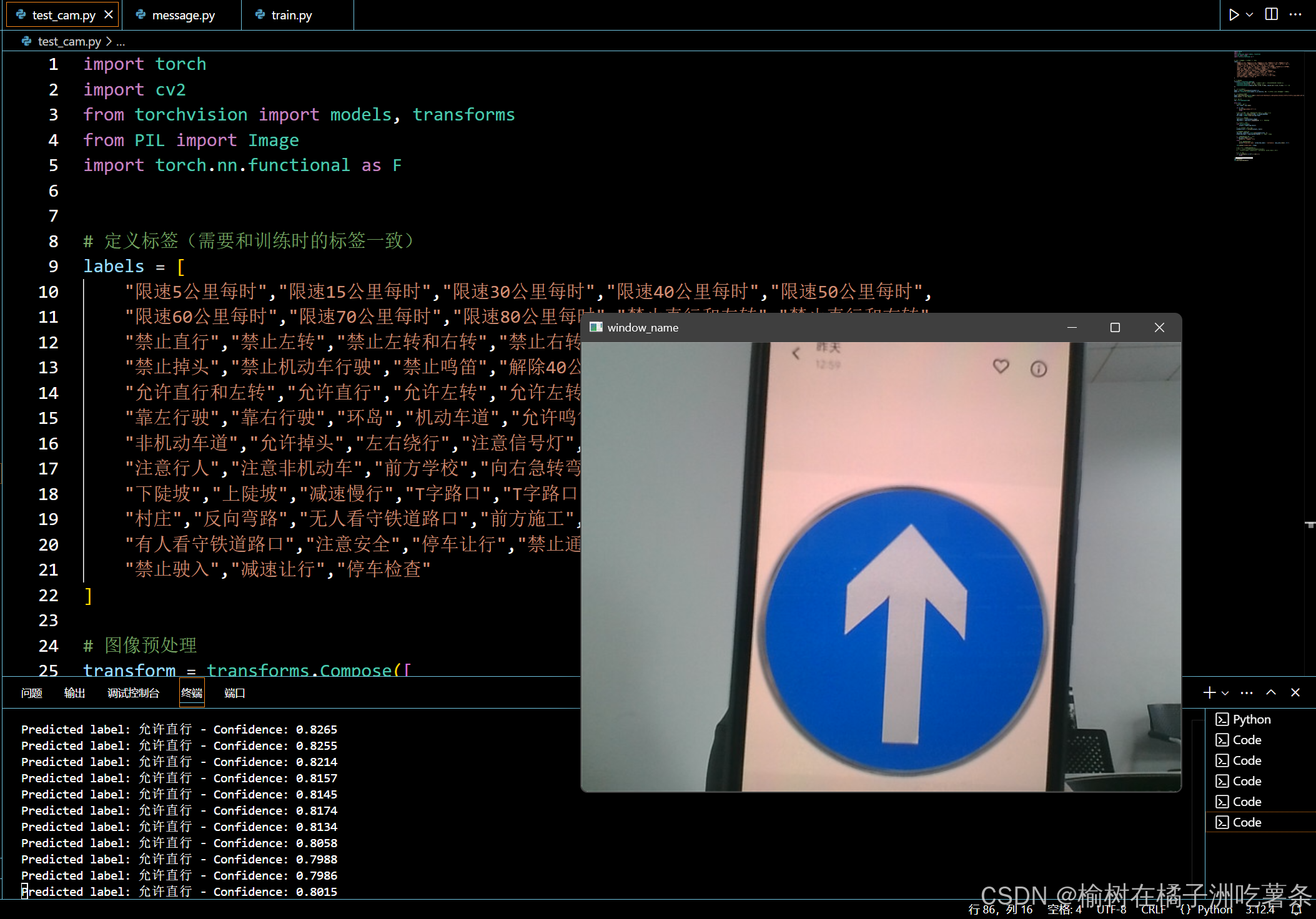
二、尝试虚拟机与主机通信
因为我的ros系统部署在ubuntu虚拟机上,我通过串口使小车与ubuntu虚拟机通信;又由于ubuntu版本过老,如果将训练好的模型布置在ubuntu上,还需要配环境,升级各种依赖,亲测十分不方便,并且虚拟机总崩。对比几种通信思路以后,最终我选择使用socket编程实现主机与虚拟机的通信,通过虚拟机调用图像,将图像传递回主机,主机接收图像后使用模型进行预测,再将预测结果返回到虚拟机的方式来完成。
1、主机代码:
#message.py
import socket
import torch
from torchvision import models, transforms
import torch.nn.functional as F
from PIL import Image
import io
# 定义标签(与训练时的标签一致)
labels = [
"限速5公里每时","限速15公里每时","限速30公里每时","限速40公里每时","限速50公里每时",
"限速60公里每时","限速70公里每时","限速80公里每时","禁止直行和左转","禁止直行和右转",
"禁止直行","禁止左转","禁止左转和右转","禁止右转","禁止超车",
"禁止掉头","禁止机动车行驶","禁止鸣笛","解除40公里每小时限速","解除50公里每小时限速",
"允许直行和左转","straight","left","允许左转和右转","right",
"靠左行驶","靠右行驶","环岛","机动车道","允许鸣笛",
"非机动车道","允许掉头","左右绕行","注意信号灯","注意危险",
"注意行人","注意非机动车","前方学校","向右急转弯","向左急转弯",
"下陡坡","上陡坡","减速慢行","T字路口","T字路口",
"村庄","反向弯路","无人看守铁道路口","前方施工","连续弯路",
"有人看守铁道路口","注意安全","停车让行","禁止通行","禁止停车",
"禁止驶入","减速让行","停车检查"
]
# 图像预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整图像大小为 224x224(ResNet 输入大小)
transforms.ToTensor(), # 转换为 Tensor 格式
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
# 加载训练好的模型
model = models.resnet18(pretrained=True)
model.fc = torch.nn.Linear(model.fc.in_features, 58) # 修改输出类别为58(你的标签数量)
model.load_state_dict(torch.load('C:/Users/user/Desktop/vs.code/python/chinese_traffic/traffic_sign_model.pth'))
model.eval() # 设置为评估模式
# 设置主机 IP 和端口(需与客户端匹配)
HOST = '0.0.0.0' # 监听所有接口
PORT = 12345 # 与客户端一致的端口号
# 创建服务器套接字
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind((HOST, PORT))
server_socket.listen(5)
print(f"Server is listening on {HOST}:{PORT}...")
while True:
# 接受客户端连接
client_socket, client_address = server_socket.accept()
print(f"Connected by {client_address}")
while True:
# 接收图像数据大小
img_size = int.from_bytes(client_socket.recv(4), byteorder='big')
img_data = b''
while len(img_data) < img_size:
img_data += client_socket.recv(4096)
# 将图像数据转换为PIL图像
image = Image.open(io.BytesIO(img_data))
# 对图像进行预处理
img_tensor = transform(image)
img_tensor = img_tensor.unsqueeze(0) # 增加批次维度
# 使用模型进行预测
with torch.no_grad():
outputs = model(img_tensor)
# 使用 softmax 转换为概率
probabilities = F.softmax(outputs, dim=1)
# 获取最大概率的类别
max_prob, predicted = torch.max(probabilities, 1)
predicted_label = labels[predicted[0]] # 映射到标签名称
# 检查最大置信度是否低于 0.6
if max_prob.item() < 0.6:
result = "no sign"
else:
result = f"{predicted_label} - Confidence: {max_prob.item():.4f}"
# 发送预测结果回客户端
client_socket.sendall(result.encode('utf-8'))
client_socket.close()
2、虚拟机代码:
#send.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import socket
import cv2
import struct
import rospy
from sensor_msgs.msg import Image
from cv_bridge import CvBridge, CvBridgeError
# 设置默认编码为 UTF-8
reload(sys)
sys.setdefaultencoding('utf-8')
# 设置主机 IP 和端口(需与服务器端匹配)
HOST = '192.168.56.1' # 主机 IP 地址(根据实际情况修改)
PORT = 12345 # 与服务器端一致的端口号
# 初始化 ROS 节点
rospy.init_node('camera_client_node', anonymous=True)
# 创建 CvBridge 对象
bridge = CvBridge()
# 创建图像发布者
image_pub = rospy.Publisher('/camera/image_raw', Image, queue_size=10)
# 创建套接字
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 尝试连接到服务器
try:
client_socket.connect((HOST, PORT))
rospy.loginfo("成功连接到服务器 {}:{}".format(HOST, PORT))
except socket.error as e:
rospy.logerr("连接服务器失败: {}".format(e))
exit()
# 打开摄像头
cap = cv2.VideoCapture(0)
if not cap.isOpened():
rospy.logerr("无法打开摄像头")
client_socket.close()
exit()
while not rospy.is_shutdown():
# 捕获摄像头图像
ret, frame = cap.read()
if not ret:
rospy.logerr("无法读取摄像头图像")
break
# 将图像从 OpenCV 格式转换为 ROS 图像消息
try:
ros_image = bridge.cv2_to_imgmsg(frame, "bgr8")
image_pub.publish(ros_image) # 发布图像消息
except CvBridgeError as e:
rospy.logerr("CvBridge 错误: %s", e)
# 图像编码为 JPEG 格式
_, img_encoded = cv2.imencode('.jpg', frame)
img_data = img_encoded.tobytes()
# 发送图像大小,4字节
client_socket.sendall(struct.pack('!I', len(img_data))) # 发送图像大小
client_socket.sendall(img_data) # 发送图像数据
# 接收服务器返回的预测结果
try:
result = client_socket.recv(1024).decode('utf-8')
rospy.loginfo("result: {}".format(result))
except socket.error as e:
rospy.logerr("fail: %s", e)
# 显示摄像头图像
cv2.imshow("Camera Feed", frame)
# 按 'q' 键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源并关闭连接
cap.release()
client_socket.close()
cv2.destroyAllWindows()
虚拟机端需要将主机ip地址改为自己的地址。
验证一下是否好使,先运行主机的代码,再运行虚拟机的代码,
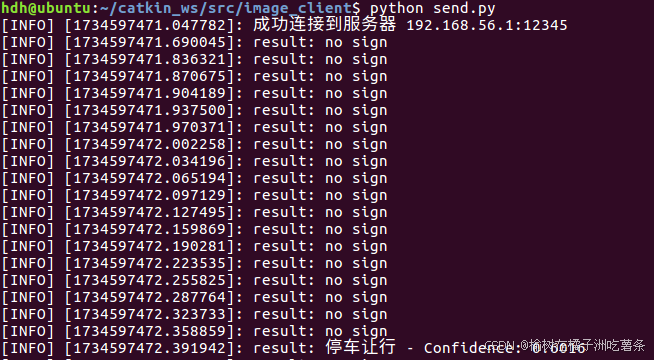
连接成功并可以正常检测。
三、布置ros
cd catkin_ws/src
mkdir image_client && cd image_client
vim send.py通信代码send.py
#send.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import socket
import cv2
import struct
import rospy
from sensor_msgs.msg import Image
from cv_bridge import CvBridge, CvBridgeError
from geometry_msgs.msg import Twist # 导入 Twist 消息类型
# 设置默认编码为 UTF-8
reload(sys)
sys.setdefaultencoding('utf-8')
# 设置主机 IP 和端口(需与服务器端匹配)
HOST = '192.168.56.1' # 主机 IP 地址(根据实际情况修改)
PORT = 12345 # 与服务器端一致的端口号
# 初始化 ROS 节点
rospy.init_node('camera_client_node', anonymous=True)
# 创建 CvBridge 对象
bridge = CvBridge()
# 创建图像发布者
image_pub = rospy.Publisher('/camera/image_raw', Image, queue_size=10)
# 创建套接字
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 尝试连接到服务器
try:
client_socket.connect((HOST, PORT))
rospy.loginfo("成功连接到服务器 {}:{}".format(HOST, PORT))
except socket.error as e:
rospy.logerr("连接服务器失败: {}".format(e))
exit()
# 打开摄像头
cap = cv2.VideoCapture(0)
if not cap.isOpened():
rospy.logerr("无法打开摄像头")
client_socket.close()
exit()
# 创建 /cmd_vel 话题的发布者
cmd_vel_pub = rospy.Publisher("/cmd_vel", Twist, queue_size=10)
# 持续识别和控制小车运动
while not rospy.is_shutdown():
# 捕获摄像头图像
ret, frame = cap.read()
if not ret:
rospy.logerr("无法读取摄像头图像")
break
# 将图像从 OpenCV 格式转换为 ROS 图像消息
try:
ros_image = bridge.cv2_to_imgmsg(frame, "bgr8")
image_pub.publish(ros_image) # 发布图像消息
except CvBridgeError as e:
rospy.logerr("CvBridge 错误: %s", e)
# 图像编码为 JPEG 格式
_, img_encoded = cv2.imencode('.jpg', frame)
img_data = img_encoded.tobytes()
# 发送图像大小,4字节
client_socket.sendall(struct.pack('!I', len(img_data))) # 发送图像大小
client_socket.sendall(img_data) # 发送图像数据
# 接收服务器返回的预测结果
try:
result = client_socket.recv(1024).decode('utf-8')
rospy.loginfo("Prediction result: {}".format(result))
# 根据预测结果控制小车
linear_x = 0.0
angular_z = 0.0
if "straight" in result:
linear_x = 0.2
elif "left" in result:
linear_x = 0.1
angular_z = 0.5
elif "right" in result:
linear_x = 0.1
angular_z = -0.5
elif "no sign" in result:
angular_z = 0.1 # 假设没有识别到标识时进行旋转
else:
rospy.logwarn("未知的预测结果: %s", result)
# 发布小车运动命令
twist = Twist() # 创建 Twist 消息
twist.linear.x = linear_x
twist.angular.z = angular_z
# 发布到 /cmd_vel 话题
cmd_vel_pub.publish(twist)
except socket.error as e:
rospy.logerr("接收预测结果失败: %s", e)
# 显示摄像头图像
cv2.imshow("Camera Feed", frame)
# 按 'q' 键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源并关闭连接
cap.release()
client_socket.close()
cv2.destroyAllWindows()
四、运行
#terminal 1
sudo ip link set can0 up type can bitrate 500000
source ./devel/setup.bash
roslaunch scout_bringup scout_robot_base.launch
#terminal 2
source ./devel/setup.bash
rosrun image_client send.py参考资料:
Traffic Sign Recogntion Database
https://zhuanlan.zhihu.com/p/693754050

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









