






简介
·GAN(Generative Adversarial
Networks),中文翻译为“生成式对抗网络”,是lan Goodfellow等在2014年提出的一种生成式模型。
GAN的基本思想源自博弈论的二人零和博弈,由一个生成器和一个判别器构成,通过对抗学习的方式来训练.目的是估测数据样本的潜在分布并生成新的数据样本。生成对抗网络其实有两个网络组合:生成网络和判别网络。
生成网络即生成器(Generator):负责生成模拟数据;
判别网络即判别器(Discriminator):负责判断输入的数据是真实的还是生成的。
生成网络要不断的优化自己生成的数据让判别网络判断不出来,判别网络也要优化自己让自己判断更准确。二者关系形成对抗,因此叫做对抗网络。
GAN结构图
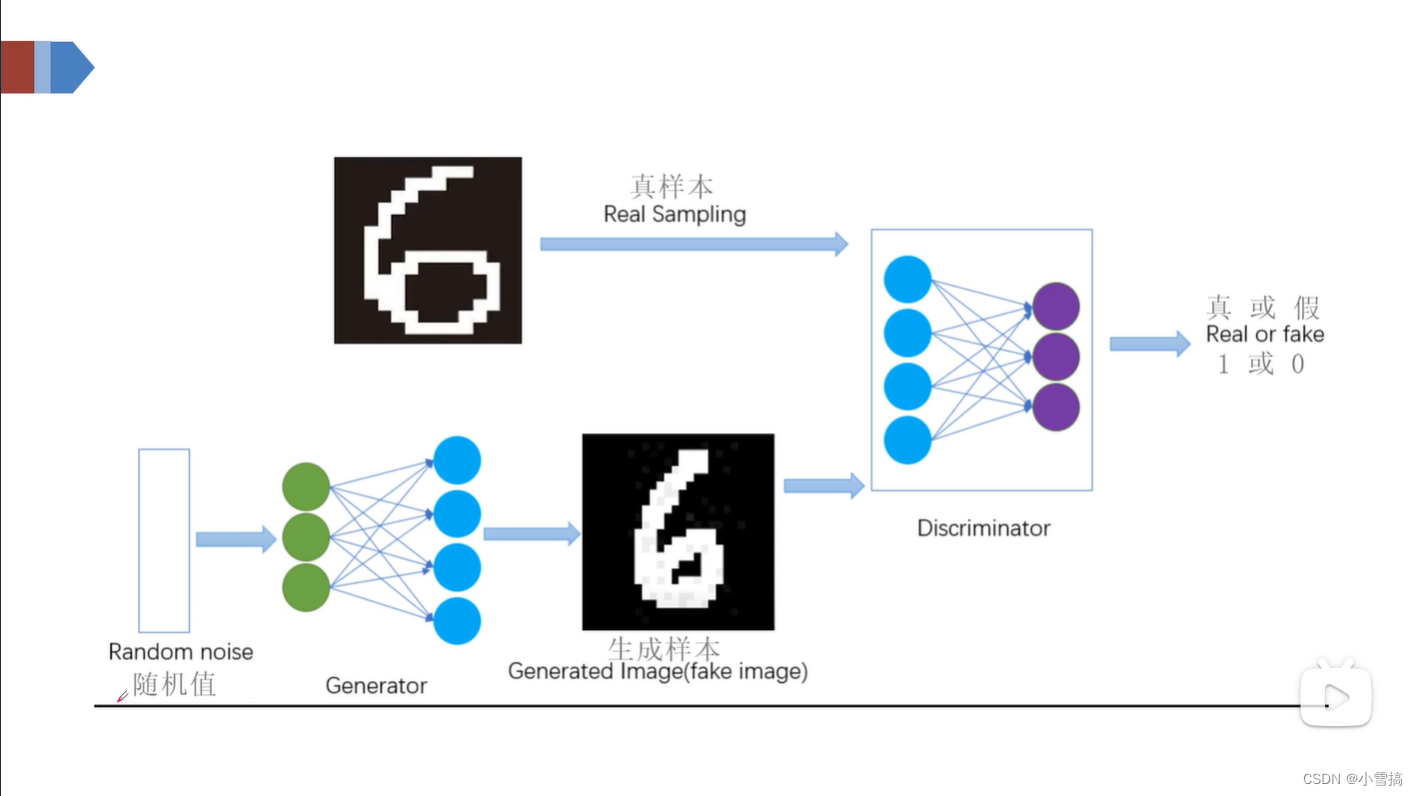
原理
先编写生成器(根据随机值(噪音)生成样本)和判断器;然后固定生成器,优化判别器,致使生成器生成的图片判断为0,真实图片判断为1;再固定判别器,优化生成器致使生成器根据随机值生成的图偏被判别器判断为1(真实图片)。
在训练过程中,生成器努力让生成的数据更加真实,而判别器努力的去判别数据的真假,二者相互对抗,互相提升自己。最终两个网络形成了动态平衡,生成样本接近真实样本,而判别器也分辨不出来样本的真假,此时分类错误率约为0.5。
目标函数

函数中中a>0,函数取值:0~1
Ex~p部分
x:真实的图片。
D(x):判别网络,判断图片真实性。这时候E应该大越好,越接近1说明越能够判断出来是真实值。
E:期望.
Ez~p部分
Z:随机值(噪音)。 G(z):已经根据随机值(噪音)得到的假图片。
D(G(z)):判断生成图片的真实值。这时候E应该越小越好,越接近0,说明越能够判断出来是生成的图片。
DCGAN
DCGAN就是在GAN的基础上加了卷积网络结构,把生成器G换成转置卷积,辨别器D换成卷积。目的是利用卷积提升图像的强大处理能力。让生成的图片更加。
先了解一下转置卷积
转置卷积nn.ConvTranspose2d
学习转置卷积要先了解卷积,可以看我前面写的卷积http://t.csdnimg.cn/TDUiQ
转置卷积可以看这位博主写的,写的很清晰明了。http://t.csdnimg.cn/rCUla![]() http://t.csdnimg.cn/rCUla
http://t.csdnimg.cn/rCUla
普通卷积

像这个图就是普通卷积,输出是由卷积核和输入的左上角3*3位置相乘,然后按照步长移动在与卷积核相乘得到的。可以看到是下采样(就是降维了)。实际上,在计算机中不会根据图示移动计算,计算机中计算的时候是会把卷积核转化为等效的矩阵,将输入转化为向量,通过输入向量和卷积核的矩阵的相乘得到输出向量 。输出的向量在经过变形就可以得到二维输出特征(如图中输出)。
实际计算机中的操作:
首先把卷积核补零分成四个4*4的矩阵
上图的卷积核会与输入的不同位置进行四次卷积。所以可以通过补零的方法将卷积核分成四个4*4的矩阵,让这4个矩阵分别与输入进行卷积操作得到输出。省略移动操作。
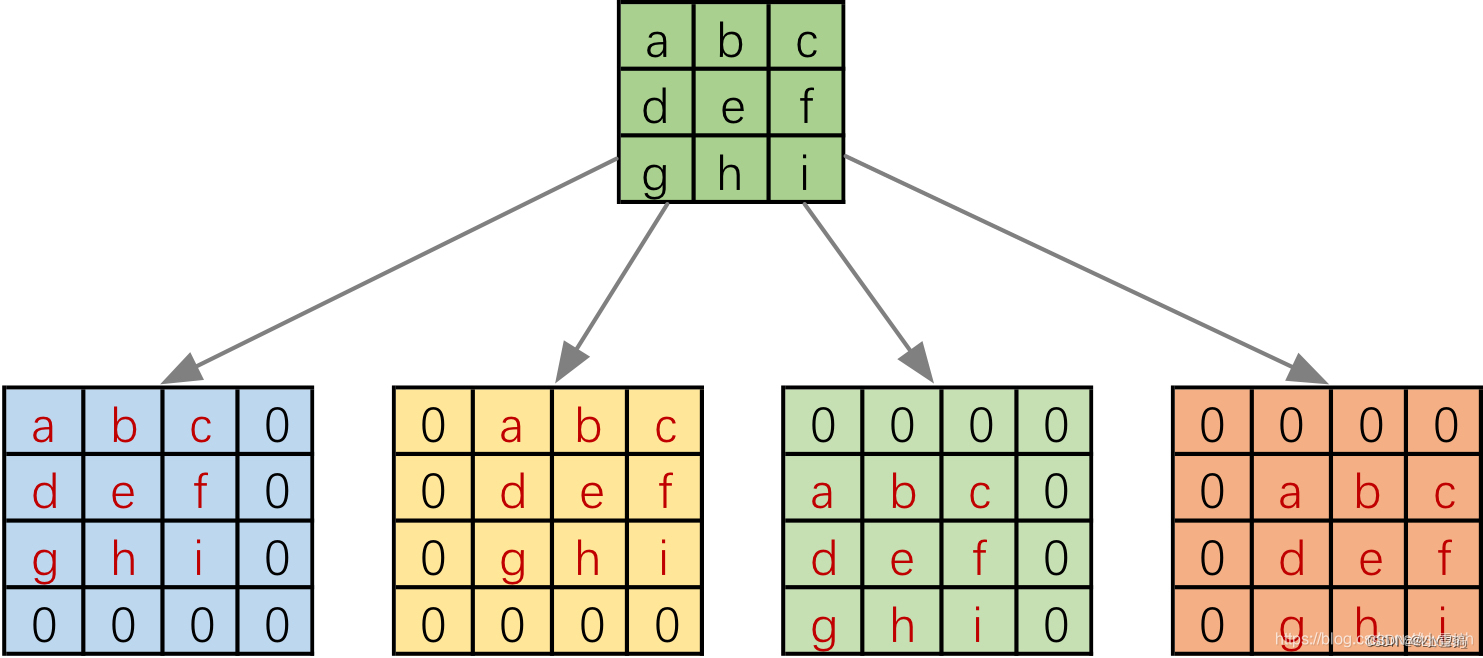
然后把输入拉成向量,卷积核4*4的矩阵也拉成向量
然后可以进一步的把我们把输入拉成长向量,卷积核 四个4*4的矩阵也拉成向量拼接在一起。
 最后把输入向量和卷积核矩阵相乘得到输出向量
最后把输入向量和卷积核矩阵相乘得到输出向量
然后把输出向量变形成二维输出特征。
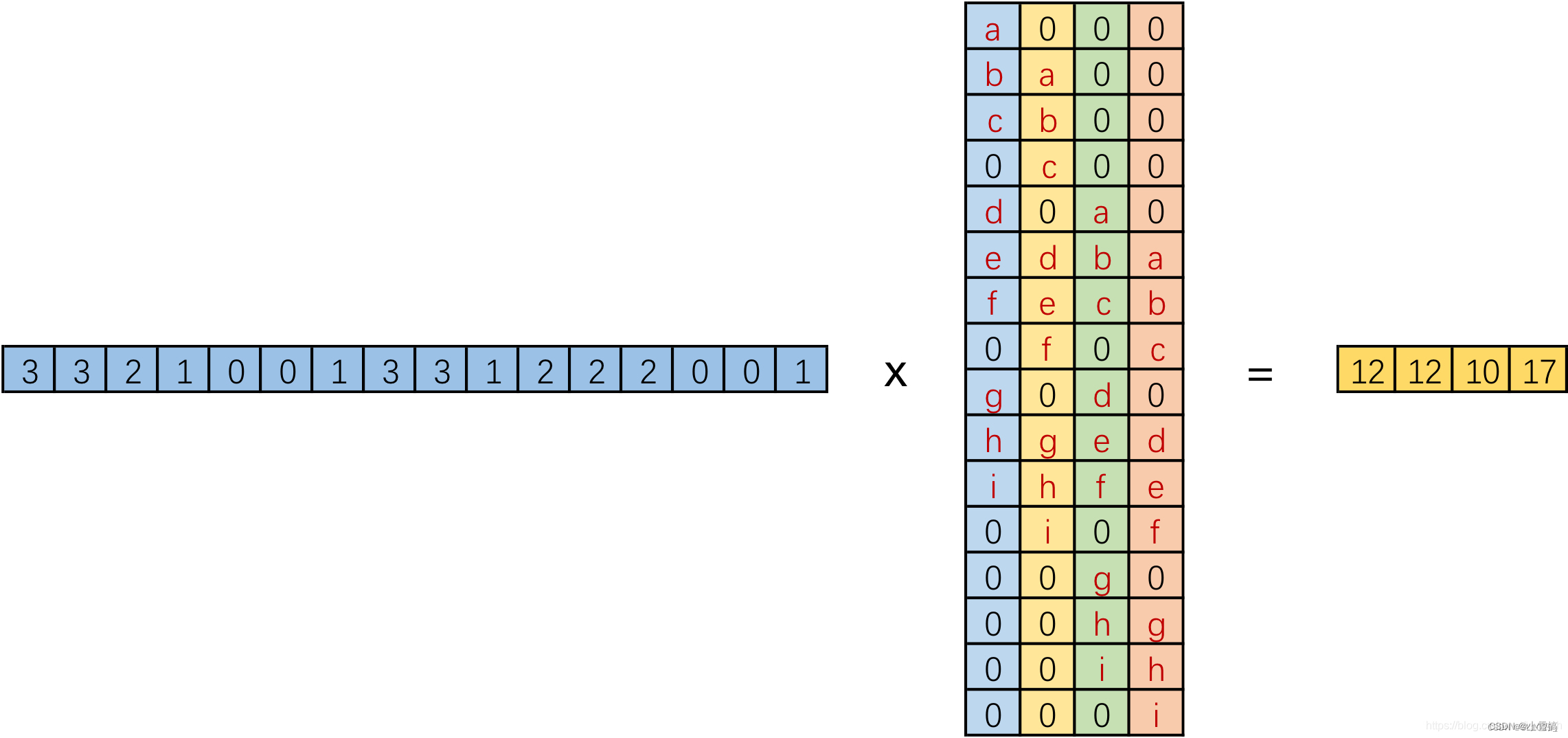
转置卷积
上图是由一个1*16的向量乘以一个4*16的矩阵得到的1*4的向量。那么反过来,把1*4的向量乘以4*16的矩阵得到一个1*16的向量,在把这个向量变形成4*4的二维输出特征。就是转置卷积的思想。(注:卷积和转置卷积的操作不可逆)
如图:由2*2——>4*4上采样(升维了)
计算转置卷积输出特征的长和宽
卷积操作中计算输出特征的长和宽。
 i:输入的尺寸;k:输出的尺寸;p:padding(填充) ;s:步长;
i:输入的尺寸;k:输出的尺寸;p:padding(填充) ;s:步长;
转置卷积中计算输出特征的尺寸
转置卷积中可以看成是把卷积操作的输入变成输出,输出变成输入。所以求转置卷积输出特征尺寸就是求上述关系的 i 。我们对上述关系进行变形可以得到 i 的求解公式。

转置卷积代码
import torch
import torch.nn as nn
input1 = torch.tensor([[2.0,1.0],[4.0,4.0]])
input1 = input1.view(-1,1,2,2)
print("输入尺寸L:",input1.shape)
upsample = nn.ConvTranspose2d(1,1,3,stride=1,padding=0)
o1 = upsample(input1)
print("输出值:",o1)
print("输出尺寸:",o1.shape) 
DCGAN
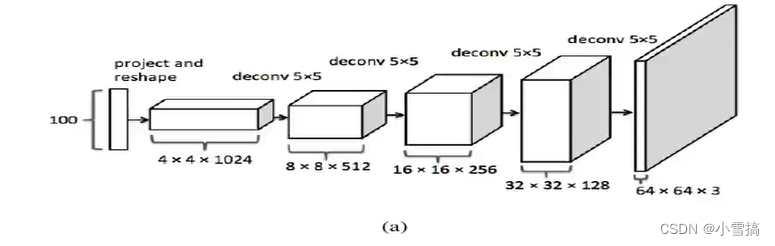
深度卷积生成对抗网络(Deep Convolutional GAN,DCGAN),是在生成模型和判别模型中添加了卷积神经网络,使得生成性能有了很大的提高。 DCGAN是继GAN之后比较好的改进,其主要的改进主要是在网络结构上,到目前为止,DCGAN的网络结构还是被广泛的使用,DCGAN极大的提升了 GAN训练的稳定性以及生成结果质量。下图是DCGAN中的生成器G结构图。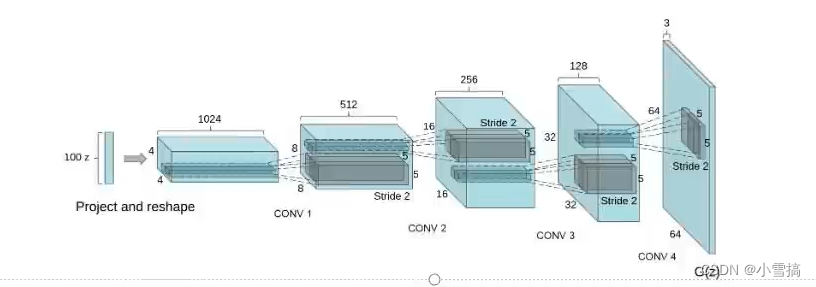
DCGAN能改进GAN训练稳定的原因主要有:
·生成器G网络中使用转置卷积进行上采样,判别器D网络中使用卷积。
·生成器G和判别器D中几乎每一层都使用batchnorm层,将特征层的输出归一化到一起,加速了训练,提升了训练的稳定性。(生成器的最后一层和判别器的第一层不加batchnorm)。
·在判别器D中使用leakyrelu激活函数,而不是relu,防止梯度稀疏,生成器G中仍然采用relu,但是输出层采用tanh。
·使用adam优化器训练,并且学习率最好是0.0002。
生成器
输入是随机值(噪音)输出是图片,利用转置卷积进行上采样
不断升维,提高分辨率减少通道数。
class Generator(torch.nn.Module):
def __init__(self):
super(Generator,self).__init__()
self.linear1=torch.nn.Linear(100,7*7*256) #升维
self.bn1=torch.nn.BatchNorm1d(7*7*256)
self.deconv1=torch.nn.ConvTranspose2d(256,128,kernel_size=(3,3),padding=1) #转置卷积
self.bn2=torch.nn.BatchNorm2d(128)
self.deconv2 = torch.nn.ConvTranspose2d(128, 64, kernel_size=(4, 4),stride=2, padding=1) #转置升维
self.bn3 = torch.nn.BatchNorm2d(64)
self.deconv3 = torch.nn.ConvTranspose2d(64, 1, kernel_size=(4, 4), stride=2, padding=1) #转置升维
def forward(self,x):
#print('--------------------------------------')
#print('x.shape:',x.shape)
x=F.relu(self.linear1(x)) #torchsize([,])#升维
# print('x.shape:',x.shape)
x=self.bn1(x) #归一化
x=x.view(-1,256,7,7)#将7*7*256的一维向量拉成7*7的通道数为256的图像 [64,256,7,7]
# print('x.shape:',x.shape)
x=F.relu(self.deconv1(x)) #转置卷积 变成[64,128,7,7]
#print('x.shape:',x.shape)
x = self.bn2(x)
#print('x.shape:', x.shape)
x = F.relu(self.deconv2(x)) #转置升维 [64,64,14,14]
#print('x.shape:', x.shape)
x = self.bn3(x)
#print('x.shape:', x.shape)
x = torch.tanh(self.deconv3(x)) #转置升维 [64,1,28,28]
#print('x.shape:', x.shape)#torch.Size([64, 1, 28, 28])
return x判别器
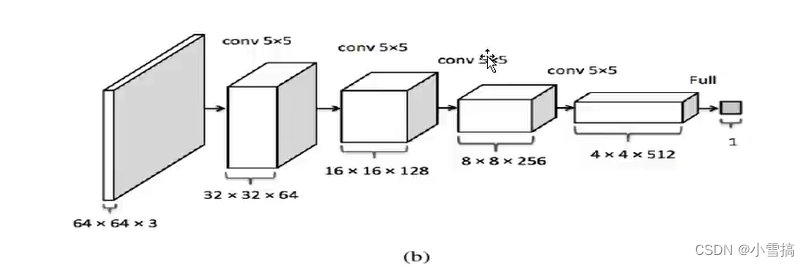
利用卷积进行下采样输出图片真假值判断。
不断降维,减少分辨率提高通道数,便于输出真假值。
#判别器,最后判断0,1,这意味着最后可以是一个神经元或者两个神经元
class Discraiminator(torch.nn.Module):
def __init__(self):
super(Discraiminator,self).__init__()
self.conv1=torch.nn.Conv2d(1,64,3,2)
self.conv2=torch.nn.Conv2d(64,128,3,2)
self.bn=torch.nn.BatchNorm2d(128)
self.fc=torch.nn.Linear(128*6*6,1)
def forward(self,x):
# print('--------------------')
#print('x.shape:', x.shape)#x.shape: torch.Size([64, 1, 28, 28])
x=F.dropout2d(F.leaky_relu(self.conv1(x)),p=0.3)
# print('x.shape:', x.shape)#x.shape: torch.Size([64, 128, 6, 6])
x = F.dropout2d(F.leaky_relu(self.conv2(x)),p=0.3)
#print('x.shape:', x.shape)#x.shape: torch.Size([64, 128, 6, 6])
x=self.bn(x) #归一化操作
x=x.view(-1,128*6*6)
#print('x.shape:', x.shape)#x.shape: torch.Size([64, 4608])
x=torch.sigmoid(self.fc(x))
#print('x.shape:', x.shape)#torch.size([64,1])
return xtorch.nn.BatchNorm1d
nn.BatchNorm1d 是 PyTorch 中的一个用于一维数据(例如序列或时间序列)的批标准化(Batch Normalization)层。
批标准化是一种常用的神经网络正则化技术,旨在加速训练过程并提高模型的收敛性和稳定性。它通过对每个输入小批次的特征进行归一化处理来规范化输入数据的分布。
在一维数据上使用 nn.BatchNorm1d 层时,它会对每个特征维度上的数据进行标准化处理。具体而言,它会计算每个特征维度的均值和方差,并将输入数据进行中心化和缩放,以使其分布接近均值为0、方差为1的标准正态分布。
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
num_features – 特征维度
eps – 为数值稳定性而加到分母上的值。
momentum – 移动平均的动量值。
affine – 一个布尔值,当设置为真时,此模块具有可学习的仿射参数。
这里其他几个参数都不重要,只需要看num_features就可以了。num_features就是你需要归一化的那一维的维度。
nn.BatchNorm1d本身不是给定输入矩阵,输出归一化结果的函数,而是定义了一个方法,再用这个方法去做归一化。
torch.nn.Dropout2d
dropout是一类用于神经网络训练或推理的随机化技术。
torch.nn.Dropout2d有多个channel的二维输出。赋值对象是彩色的图像数据(batch N,通道 C,高度 H,宽 W)的一个通道里的每一个数据。即输入为 Input: (N, C, H, W) 时,对每一个通道维度 C 按概率赋值为 0。
适用性:nn.Dropout2d用于将 dropout 正则化应用于卷积层,要求输入和输出数据为4维(N,C,H,W)。卷积层用于处理空间数据,例如图像,它们具有二维结构。
维度:它在二维张量上运行。如果您有一个 shape 的输入张量(batch_size, channels, height, width),nn.Dropout2d则会独立地将 dropout 应用于每个通道的空间维度,使每个通道独立清零。
有利于促进独立性特征图。来自http://t.csdnimg.cn/l1YfW。
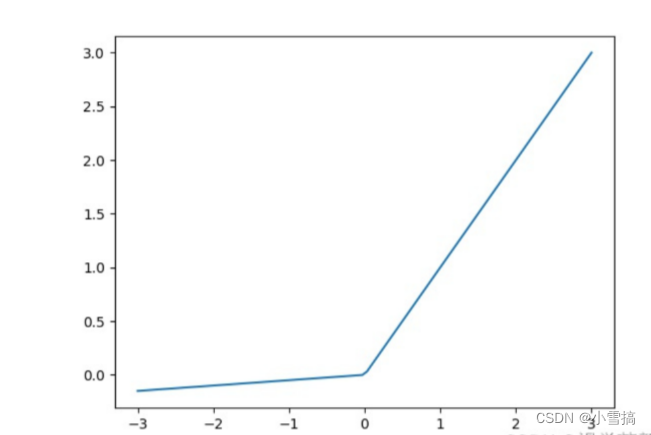
torch.nn.functional.leaky_relu
leaky_relu是一种激活函数,它在神经网络中常用于引入非线性性质。与传统的relu函数不同,leaky_relu允许负数输入有一个小的斜率,而不是完全截断为0。
在PyTorch中,可以使用torch.nn.functional.leaky_relu函数来应用leaky_relu激活函数。该函数的语法如下:
output = torch.nn.functional.leaky_relu(input, negative_slope=0.01, inplace=False)其中:
- input是输入张量。
- negative_slope是负数输入的斜率,默认为0.01。
- inplace是一个布尔值,表示是否原地操作(即是否覆盖输入张量),默认为False。

代码实现
import matplotlib.pyplot as plt
from matplotlib import font_manager
import torch
from torch.utils.data import DataLoader
import torchvision
from torchvision import transforms
import numpy as np
import torch.nn.functional as F
# 导入数据集并且进行数据处理
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(0.5, 0.5)])
traindata = torchvision.datasets.MNIST(root='./data/MINIST', train=True, download=True,transform=transform) # 训练集60,000张用于训练
# 利用DataLoader加载数据集
trainload = DataLoader(dataset=traindata, shuffle=True, batch_size=64)
# GAN生成对抗网络,步骤:
# 首先编写生成器和判别器
# 然后固定生成器,优化判别器,致使生成器生成的图片判断为0,真实图片判断为1;
# 再固定判别器,优化生成器致使生成器根据随机值生成的图偏被判别器判断为1(真实图片)。
# 生成器的代码(针对手写字体识别)
class Generator(torch.nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.linear1 = torch.nn.Linear(100, 7 * 7 * 256) # 升维
self.bn1 = torch.nn.BatchNorm1d(7 * 7 * 256)
self.deconv1 = torch.nn.ConvTranspose2d(256, 128, kernel_size=(3, 3), padding=1) # 转置卷积
self.bn2 = torch.nn.BatchNorm2d(128)
self.deconv2 = torch.nn.ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=2, padding=1) # 转置升维
self.bn3 = torch.nn.BatchNorm2d(64)
self.deconv3 = torch.nn.ConvTranspose2d(64, 1, kernel_size=(4, 4), stride=2, padding=1) # 转置升维
def forward(self, x):
# print('--------------------------------------')
# print('x.shape:',x.shape)
x = F.relu(self.linear1(x)) # torchsize([,])#升维
# print('x.shape:',x.shape)
x = self.bn1(x) # 归一化
x = x.view(-1, 256, 7, 7) # 将7*7*256的一维向量拉成7*7的通道数为256的图像 [64,256,7,7]
# print('x.shape:',x.shape)
x = F.relu(self.deconv1(x)) # 转置卷积 变成[64,128,7,7]
# print('x.shape:',x.shape)
x = self.bn2(x)
# print('x.shape:', x.shape)
x = F.relu(self.deconv2(x)) # 转置升维 [64,64,14,14]
# print('x.shape:', x.shape)
x = self.bn3(x)
# print('x.shape:', x.shape)
x = torch.tanh(self.deconv3(x)) # 转置升维 [64,1,28,28]
# print('x.shape:', x.shape)#torch.Size([64, 1, 28, 28])
return x
# 判别器,最后判断0,1,这意味着最后可以是一个神经元或者两个神经元
class Discraiminator(torch.nn.Module):
def __init__(self):
super(Discraiminator, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 64, 3, 2)
self.conv2 = torch.nn.Conv2d(64, 128, 3, 2)
self.bn = torch.nn.BatchNorm2d(128)
self.fc = torch.nn.Linear(128 * 6 * 6, 1)
def forward(self, x):
# print('--------------------')
# print('x.shape:', x.shape)#x.shape: torch.Size([64, 1, 28, 28])
x = F.dropout2d(F.leaky_relu(self.conv1(x)), p=0.3)
# print('x.shape:', x.shape)#x.shape: torch.Size([64, 128, 6, 6])
x = F.dropout2d(F.leaky_relu(self.conv2(x)), p=0.3)
# print('x.shape:', x.shape)#x.shape: torch.Size([64, 128, 6, 6])
x = self.bn(x) # 归一化操作
x = x.view(-1, 128 * 6 * 6)
# print('x.shape:', x.shape)#x.shape: torch.Size([64, 4608])
x = torch.sigmoid(self.fc(x))
# print('x.shape:', x.shape)#torch.size([64,1])
return x
# 定义损失函数和优化函数
device = 'cuda' if torch.cuda.is_available() else 'cpu'
gen = Generator().to(device)
dis = Discraiminator().to(device)
# 定义优化器
gen_opt = torch.optim.Adam(gen.parameters(), lr=0.0001)
dis_opt = torch.optim.Adam(dis.parameters(), lr=0.0001)
loss_fn = torch.nn.BCELoss() # 损失函数
# 图像显示
def gen_img_plot(model, testdata):
pre = np.squeeze(model(testdata).detach().cpu().numpy())
# tensor.detach()
# 返回一个新的tensor,从当前计算图中分离下来的,但是仍指向原变量的存放位置,不同之处只是requires_grad为false,得到的这个tensor永远不需要计算其梯度,不具有grad。
# 即使之后重新将它的requires_grad置为true,它也不会具有梯度grad
# 这样我们就会继续使用这个新的tensor进行计算,后面当我们进行反向传播时,到该调用detach()的tensor就会停止,不能再继续向前进行传播
plt.figure()
for i in range(16):
plt.subplot(4, 4, i + 1)
plt.imshow(pre[i])
plt.show()
# 后向传播
dis_loss = [] # 判别器损失值记录
gen_loss = [] # 生成器损失值记录
lun = [] # 轮数
for epoch in range(25):
d_epoch_loss = 0
g_epoch_loss = 0
cout = len(trainload) # 938批次
for step, (img, _) in enumerate(trainload):
img = img.to(device) # 图像数据
# print('img.size:',img.shape)#img.size: torch.Size([64, 1, 28, 28])
size = img.size(0) # 一批次的图片数量64
# 随机生成一批次的100维向量样本,或者说100个像素点
random_noise = torch.randn(size, 100, device=device)
# 先进性判断器的后向传播
dis_opt.zero_grad()
real_output = dis(img)
d_real_loss = loss_fn(real_output, torch.ones_like(real_output)) # 真实数据的损失函数值
d_real_loss.backward()
gen_img = gen(random_noise)
fake_output = dis(gen_img.detach())
d_fake_loss = loss_fn(fake_output, torch.zeros_like(fake_output)) # 人造的数据的损失函数值
d_fake_loss.backward()
d_loss = d_real_loss + d_fake_loss
dis_opt.step()
# 生成器的后向传播
gen_opt.zero_grad()
fake_output = dis(gen_img)
g_loss = loss_fn(fake_output, torch.ones_like(fake_output))
g_loss.backward()
gen_opt.step()
d_epoch_loss += d_loss
g_epoch_loss += g_loss
dis_loss.append(float(d_epoch_loss))
gen_loss.append(float(g_epoch_loss))
print(f'第{epoch + 1}轮的生成器损失值:{g_epoch_loss},判别器损失值{d_epoch_loss}')
lun.append(epoch + 1)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决 “预测值” 这三个中文出现乱码现象
plt.rcParams['axes.unicode_minus'] = False ##解决 “预测值” 这三个中文出现乱码现象 加上这两行就不会乱码
random_noise = torch.randn(16, 100, device=device)
gen_img_plot(gen, random_noise)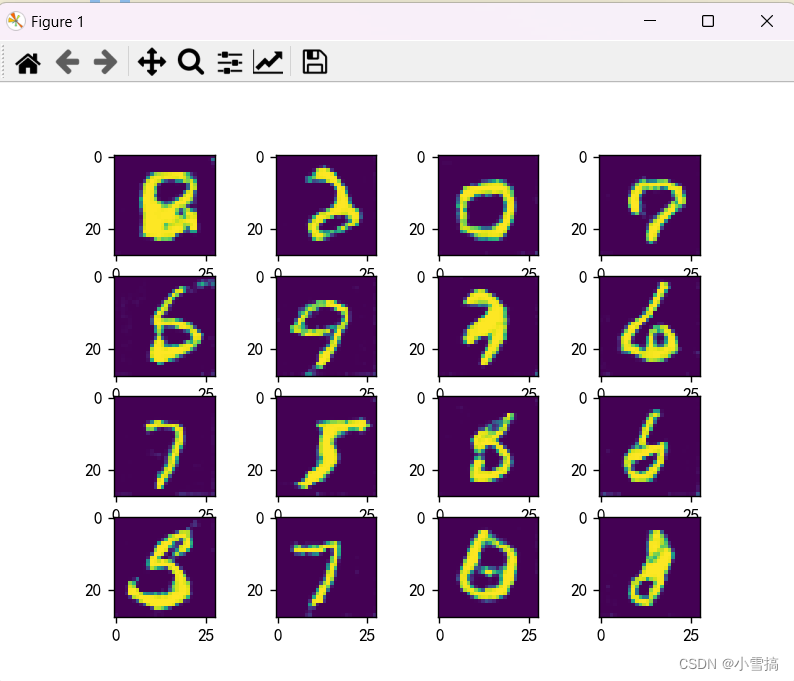
运行了25轮的结果可以看出来还不太清晰的。需要运行更多轮次。















 528
528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









