






目录
1 生成对抗网络(GAN) 2
1.1 概念 2
1.2 结构分析 2
1.2.1 基本结构 2
1.2.2 生成网络 2
1.2.3 判别网络 3
1.3 意义与应用场景 3
1.4 基于mnist数据集的PyTorch实现 3
1.4.1 源代码 3
1.4.2 运行结果 7
1.4.3 报错与解决 9
2 GAN的变体-DCGAN 10
2.1 概念 10
2.2 结构分析 10
2.2.1 与GAN的区别 10
2.2.2 生成网络 10
2.2.3 判别网络 11
2.3 基于mnist数据集的Pytorch实现 12
2.3.1 源代码 12
2.3.2 运行结果 14
3 GAN与DCGAN 16
3.1 DCGAN的改进 16
3.2 在本文实验中效果对比 16
3.3 在资料中效果对比 17
1 生成对抗网络(GAN)
1.1 概念
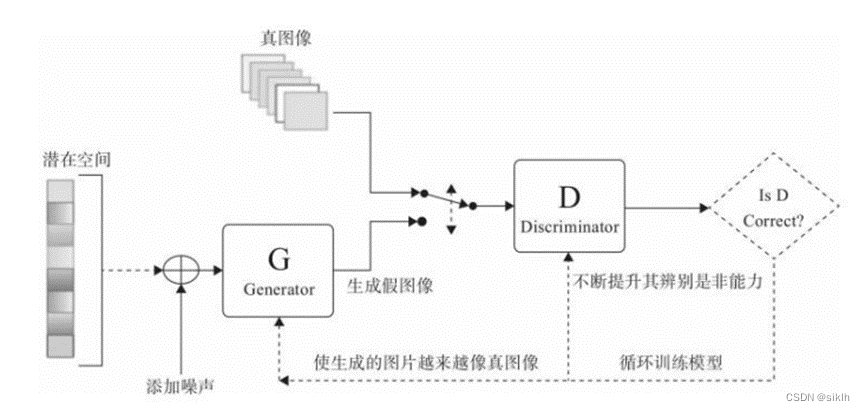
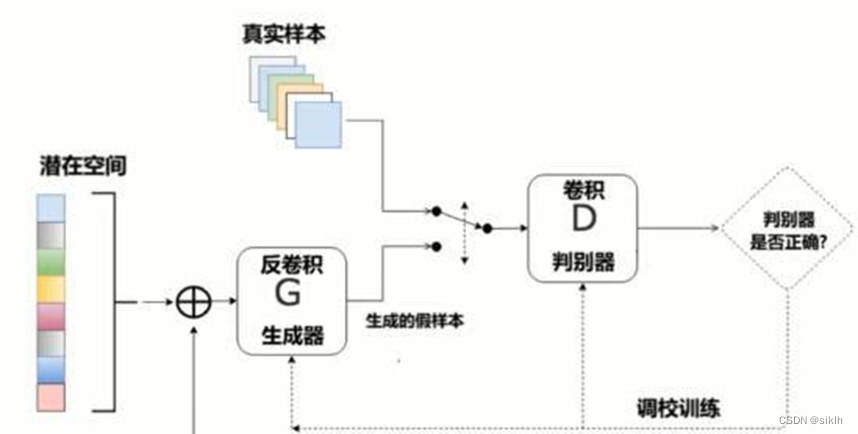
GAN(Generative adversarial network)全称对抗生成网络,属于“无监督学习”的一种,可以用来生成不同类型的数据。对抗神经网络其实是两个网络的组合,一个网络用于生成模拟数据,又叫生成网络;另一个网络判断生成的数据是真实的还是模拟的,这个网络又叫判别网络。生成网络要不断优化自己生成的数据让判别网络判断不出来,判别网络也要优化自己让自己判断得更准确。二者关系形成对抗,因此叫对抗神经网络。
实际上,GAN可以使用任何形式的生成器与判别器,包括但不限于神经网络、机器学习等等。而神经网络被广泛应用在GAN的原因是因为它是一种通用函数逼近算法。也就是说我们可以使用大量节点的神经网络来模拟任何非线性的输入与输出之间的函数,相对于其他方法具有更高的自由度,不会因为算法本身的能力而受限。
1.2 结构分析
1.2.1 基本结构
GAN的主要结构包括两部分,一个是生成器,姑且称为G,另一个是判别器,称为D。
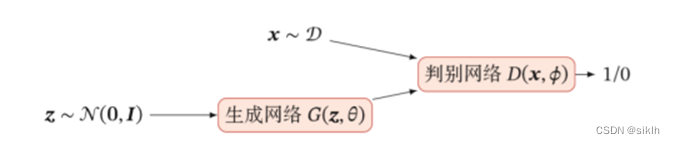
生成器接受任意的噪声数据,我们往往使用均值为0的正态分布。生成网络将之转换为模拟数据,判别网络对模拟数据与真实数据进行判别,尽可能的使得生成网络的模拟数据贴近真实数据。
1.2.2 生成网络
生成网络的目标是让判别网络将自己生成的样本判别为真实样本。
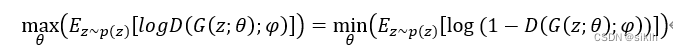
其中D(G(z;θ);φ)为判别器对生成样本的“打分”。
1.2.3 判别网络
判别网络的目标是区分出一个样本是来自于真实分布还是生成样本的分布。
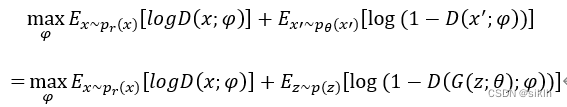
其中θ和φ分别是生成网络和判别网络的参数;D(x;φ)为判别器对真实样本的打分;D(x^';φ),D(G(z;θ);φ)为判别器对生成样本的打分。
1.3 意义与应用场景
生成式对抗网络的优点是采用博弈论中的二人博弈框架训练,理论优雅;生成的图片质量高;
生成式对抗网络的缺点是训练网络的技巧多,训练过程不稳定;训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到,还没有找到很好的达到纳什均衡的方法;GAN不适合处理离散形式的数据,比如文本等。
传统的机器学习方法,一般都会定义一个什么模型让数据去学习。GAN网络最强大的地方就是可以帮助我们建立模型,而不像传统的网络那样是在已有模型上帮我们更新参数而已。同时,GAN网络是一种无监督的学习方式,它的泛化性非常好。
GAN是一个生成模型,可以用来生成图像、音频等等;可以进行图像转换,将图像转换为另一种形式的图像;可以用于场景合成,根据分割图像还原出原始场景信息等等。
1.4 基于mnist数据集的PyTorch实现
简单了解了GAN的原理,下面我们将借助Pytorch来基于MNIST数据集实现手写字符集的生成。
1.4.1 源代码
(1)库的声明与数据的加载
# 声明一些必要的库
from ast import increment_lineno
import itertools
import math
import time
import matplotlib
from random import shuffle
# 声明pytorch下的必要库
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torchvision.utils as vutils
import torchvision.datasets as dsets
import torchvision.transforms as trans
# 一个魔法函数,用于在jupyter下将plot实时显示出来
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
# 选择训练设备,在gpu可用情况下进行调用,否则调用cpu
device = torch.device('cuda' if torch.cuda.is_available else 'cpu')
# 设定每次训练的图片数量
BATCH_SIZE = 100
# 将每个像素值scale 到[-1,-1]
transform=trans.Compose([
trans.ToTensor(),
trans.Normalize(mean=0.5,std=0.5)
])#单通道不需要在3个channel中进行scale
# 加载MNIST数据集
train_set = dsets.MNIST(root='data/minist',
train=True,
download=True,
transform=transform)
dataloader = torch.utils.data.DataLoader(
train_set,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=True,
num_workers=6
)
(2)定义判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.net = nn.Sequential(
nn.Linear(784,256),
nn.LeakyReLU(0.2),
nn.Linear(256,256),
nn.LeakyReLU(0.2),
nn.Linear(256,1),
nn.Sigmoid()
)
def forward(self,x):
o=x.view(x.size(0),-1)
o=self.net(o)
return(o)
(3)定义生成器
class Generator(nn.Module):
def __init__(self,z_dim=64):
super(Generator, self).__init__()
self.net=nn.Sequential(
nn.Linear(z_dim,256),
nn.ReLU(),
nn.Linear(256,256),
nn.ReLU(),
nn.Linear(256,784),
nn.Tanh()
)
def forward(self,x):
o=self.net(x)
return o
(4)定义相关变量
# 潜在空间
Z_DIM=64
# 将网络实例化并送入训练设备
netG=Generator(Z_DIM).to(device)
netD=Discriminator().to(device)
# 定义训练的损失函数
criterion=nn.BCELoss()
# 定义生成的噪声
z=torch.randn(BATCH_SIZE,Z_DIM).to(device)
# 定义学习率
lr=0.0001
# 定义训练批次
nepochs = 200
# 定义生成器和判别器的优化函数
optimizerD=torch.optim.Adam(netD.parameters(),lr=lr)
optimizerG=torch.optim.Adam(netG.parameters(),lr=lr)
(5)训练模型
# 用于承接两者的准确率
accR_L=[]
accF_L=[]
# 开始训练
for epoch in range(nepochs):
since = time.time() # 用于获取训练开始时间
# 训练
for batch_x,_ in dataloader:
# 更新判别器
netD.zero_grad() # 清除梯度
real_x=batch_x.to(device) # 真实数据
real_labels=torch.ones(BATCH_SIZE,1).to(device) # 真实数据的标签
real_y=netD(real_x) # 真实数据在判别器里的输出
z=torch.randn(BATCH_SIZE,Z_DIM).to(device) # 产生随机噪声信号
fake_labels = torch.zeros(BATCH_SIZE,1).to(device) # 生成标签
fake_x = netG(z) # 生成器产生生成数据
fake_y = netD(fake_x) # 生成数据在判别器里的输出
# 行梯度上升(Gradient Ascent)算法
errD = criterion(real_y, real_labels)+ criterion(fake_y, fake_labels)
errD.backward()
optimizerD.step()
accR_L.append(real_y.data.mean())
accF_L.append(fake_y.data.mean())
# 更新生成器
netG.zero_grad() # 清除梯度
z = torch.randn(BATCH_SIZE, Z_DIM).to(device) # 产生随机噪声信号
fake_x = netG(z) # 生成器产生生成数据
fake_y = netD(fake_x) # 生成数据在判别器里的输出
# 梯度下降(Gradient Descent)算法
errG = criterion(fake_y, real_labels)
errG.backward()
optimizerG.step()
now=time.time() # 记录训练结束时间
# 打印训练数据
print('[%d/%d,%.0f seconds]|\t err_D: %.4f \t err_G:%.4f'%(epoch,nepochs,now-since,errD,errG))
# 查看训练的生成器的生成图片情况
img = vutils.make_grid(fake_x.cpu().view(-1,1,28,28), nrow = 10, normalize = True) #将若干幅图像整合成一幅图像
img = img.numpy().transpose([1,2,0]) #图片数据格式转换
plt.imshow(img)
plt.show()
# 保存训练的生成器的生成图片情况
vutils.save_image(fake_x.data.cpu().view(-1,1,28,28),
'gan_save/fake%d.png'%(epoch+1),
normalize=True,nrow=10)
(6)检查生成图片
noise = torch.randn(25, Z_DIM)
fake_x = netG(noise.to(device)).data.cpu().view(25,1,28,28)
img = vutils.make_grid(fake_x, nrow = 5, normalize = True) #将若干幅图像整合成一幅图像
img = img.numpy().transpose([1,2,0]) #图片数据格式转换
plt.imshow(img)
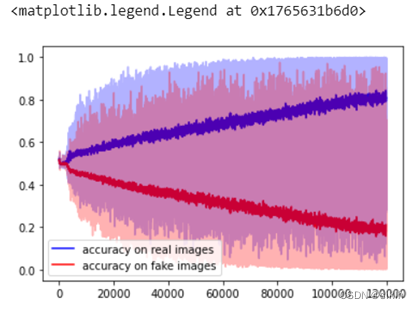
(7)模型效果
# Smooth curve
def smooth_data(x, ksize = 5):
x=list(map(lambda i:i.cpu(),x))
kernel = np.ones(ksize)/ksize
x_smooth = np.convolve(x, kernel, mode = 'valid') #返回两个一维序列的离散型卷积
return x_smooth
accR_L_smooth = smooth_data(accR_L, 120)
accF_L_smooth = smooth_data(accF_L, 120)
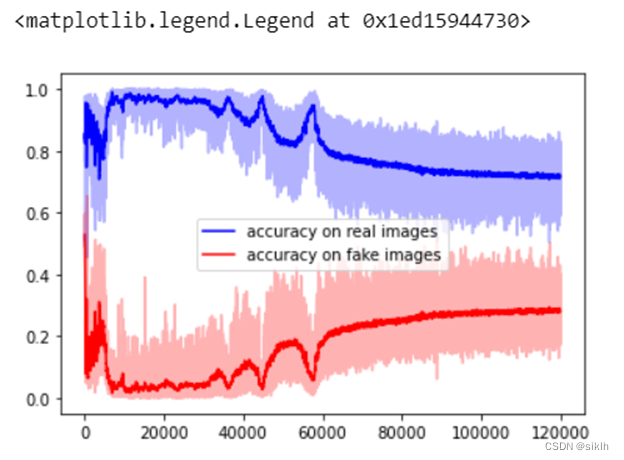
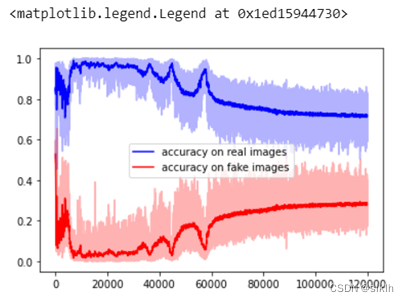
plt.plot(accR_L_smooth,'-b', label = 'accuracy on real images')
plt.plot(accF_L_smooth,'-r', label = 'accuracy on fake images')
plt.plot(list(map(lambda i:i.cpu(),accR_L)),'-b', alpha = 0.3)
plt.plot(list(map(lambda i:i.cpu(),accF_L)),'-r', alpha = 0.3)
plt.legend()
1.4.2 运行结果
(1)训练过程

… …

… …

(2)检查生成图片

(3)模型效果
1.4.3 报错与解决
1.output with shape [1, 28, 28] doesn’t match the broadcast shape [3, 28, 28]
原因:输出通道图片是灰度图片,即单通道的。与transform=trans.Compose([trans.ToTensor(),trans.Normalize(mean=(0.5,0.5,0.5),std=(0.5,0.5,0.5))])中的三通道的标准化是不匹配的,即单通道不需要在3个channel中进行scale。
解决方法:更改为transform=trans.Compose([trans.ToTensor(),trans.Normalize(mean=0.5,std=0.5)])。
2.TypeError: can’t convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
原因:在神经网络中输出的accR_L.append(real_y.data.mean())可见,为tensor格式,无法与array的格式进行计算,故需要先转到cpu()上在进行计算。
解决方法:更改为list(map(lambda i:i.cpu(),accR_L))。
2 GAN的变体-DCGAN
2.1 概念
DCGAN即使用卷积网络的对抗网络,其原理和GAN一样,只是把CNN卷积技术用于GAN模式的网络里。
生成网络在生成数据时,使用反卷积的重构技术来重构原始图片;判别网络用卷积技术来识别图片特征,进而作出判别。
2.2 结构分析
DCGAN与GAN的实现没有太过大刀阔斧的修改,仅仅是对生成网络与判别网络的构建进行了修改。
2.2.1 与GAN的区别
生成网络G中,去掉了FC层,使网络变成全卷积网络;取消所有池化层,使用转置卷积并且步长>=2进行上采样;使用批量归一化(BN),为了保证模型能够学习到数据的正确均值和方差而在最后一层通常不会使用BN;使用ReLU作激活函数,最后一层使用Tanh作为激活函数。
判别网络D中,用加入stride的卷积代替pooling;使用批量归一化(BN),为了保证模型能够学习到数据的正确均值和方差而在最后一层通常不会使用BN;使用LeakyReLU作为激活函数。
换成了两个卷积神经网络的G和D,可以更好地学到对输入图像层次化的表示,尤其是在生成器部分会有更好的模拟效果。
2.2.2 生成网络
Generator(
(l1): Sequential(
(0): Linear(in_features=64, out_features=8192, bias=True)
)
(conv_blocks): Sequential(
(0): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): Upsample(scale_factor=2.0, mode=nearest)
(2): ConvTranspose2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): BatchNorm2d(128, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Upsample(scale_factor=2.0, mode=nearest)
(6): ConvTranspose2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): BatchNorm2d(64, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(8): LeakyReLU(negative_slope=0.2, inplace=True)
(9): ConvTranspose2d(64, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): Tanh()
)
中间使用Leaky作为激活函数,防止梯度稀疏;
最后一层使用Tanh作为激活函数,因为Tanh()返回的值在-1到1之间,采用+1后×127.5,即可完美映射到图像域中;
使用BatchNormalization(BN)层,这里有助于处理初始化不良导致的训练问题,防止把所有的样本都收敛到同一点,加速模型训练提升训练的稳定性,但是在输出层不使用,防止失去图像的本来特征;
由于需要从输入图像到生成图像,自然需要将提取的特征和图还原到和原图同样尺度,因此使用转置卷积(反卷积)transposed convolutional来进行处理。
2.2.3 判别网络
Discriminator(
(model): Sequential(
(0): Conv2d(1, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Dropout2d(p=0.25, inplace=False)
(3): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Dropout2d(p=0.25, inplace=False)
(6): BatchNorm2d(32, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(7): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(8): LeakyReLU(negative_slope=0.2, inplace=True)
(9): Dropout2d(p=0.25, inplace=False)
(10): BatchNorm2d(64, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(11): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(12): LeakyReLU(negative_slope=0.2, inplace=True)
(13): Dropout2d(p=0.25, inplace=False)
(14): BatchNorm2d(128, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
)
(adv_layer): Sequential(
(0): Linear(in_features=512, out_features=1, bias=True)
(1): Sigmoid()
)
)
使用Leaky作为激活函数,防止梯度稀疏;
使用BatchNormalization(BN)层,这里有助于处理初始化不良导致的训练问题,加速模型训练提升训练的稳定性,但是在输入层不使用,防止失去图像的本来特征;
使用Dropout来提高模型的泛化能力。
2.3 基于mnist数据集的Pytorch实现
简单了解了DCGAN的原理,下面我们将借助Pytorch来基于MNIST数据集实现手写字符集的生成。
2.3.1 源代码
(1)生成网络
class Generator(nn.Module):
def __init__(self,img_size=32,latent_dim=64,channels=1):
super(Generator, self).__init__()
self.init_size = img_size // 4
self.l1 = nn.Sequential(nn.Linear(latent_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.ConvTranspose2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.ConvTranspose2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose2d(64, channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, z):
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
(2)判别网络
class Discriminator(nn.Module):
def __init__(self,channels=1,img_size=32):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters,
out_filters, 3, 2, 1),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.model = nn.Sequential(
*discriminator_block(channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# The height and width of downsampled image
ds_size = img_size // 2 ** 4
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())
def forward(self, img):
out = self.model(img)
# print(out.size())
out = out.view(out.shape[0], -1)
# print(out.size())
validity = self.adv_layer(out)
# print(validity.size())
return validity
(3)其他
其他部分代码几乎与前文1.4.1所示代码一致,但是需要将输入图片进行一下Resize,变换为32*32的大小,这样模型才不会报错。也就是需要更改部分代码为:
transform=trans.Compose([
trans.Resize((32,32)),
trans.ToTensor(),
trans.Normalize(mean=0.5,std=0.5)
])
2.3.2 运行结果
(1)训练过程
… …

… …

(2)检查生成图片

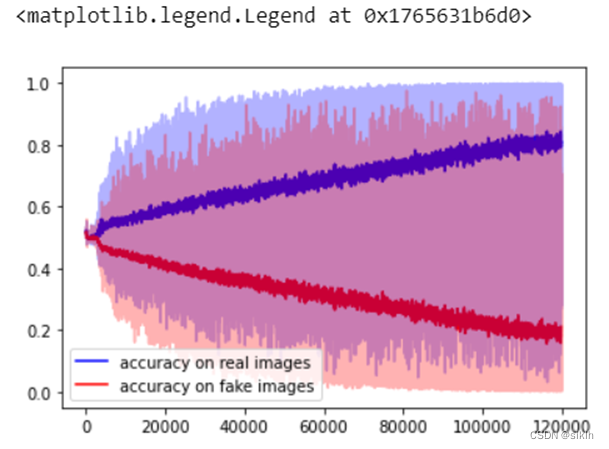
(3)模型效果
3 GAN与DCGAN
3.1 DCGAN的改进
DCGAN主要是在网络架构上改进了原始GAN,DCGAN的生成器和判别器都利用CNN架构替换了原始GAN的全连接网络,主要改进之处有如下几个方面:
DCGAN的生成器和判别器都舍弃了CNN的pooling层(池化层),判别器保留CNN的整体架构,生成器则是将卷积层替换成了反卷积层(ConvTranspose2d);
在判别器和生成器中使用了BN(Batch Normalization)层,加速模型训练,提升了训练的稳定性。但是在生成器的输出层和鉴别器的输入层不使用BN层,因为直接应用batchnorm到所有层会导致样本振荡和模型不稳定;
生成器网络中使用ReLU作为激活函数,最后一层使用Tanh(),因为使用有界激活(a bounded activation)可以让模型更快地学习,以饱和和覆盖训练分布的颜色空间,Tanh()返回的值在-1到1之间,采用+1后×127.5,即可完美映射到图像域中。
鉴别器网络中使用LeakyReLU作为激活函数;
使用Adam优化器,一阶矩估计的指数衰减率的值设置为0.5,也可以不设置。
3.2 在本文实验中效果对比
 |  |
|---|---|
 |  |
 |  |
如上图,左侧为GAN的训练结果,右侧为DCGAN的训练结果。可见,在相同的训练轮次下,DCGAN的训练结果显著优于GAN,即以CNN为主体的生成器与判别器均较好的进行了学习。
 |  |
|---|---|
如上图,左侧为GAN的训练结果,右侧为DCGAN的训练结果。可见,DCGAN的模型效果更加良好。
3.3 在资料中效果对比
评估无监督表示学习算法质量的一种常用技术是将其作为有监督数据集的特征提取器应用,并评估基于这些特征的线性模型的性能。
使用GANS作为特征提取器对CIFAR-10进行分类(DCGAN不是在CIFAR-10上预训练的,而是在Imagenet-1k上训练的,这些特征用于对CIFAR-10图像进行分类 )实验结果如下图所示:

当使用大量特征图(4800)时,K-means可达到80.6%的准确率,DCGAN达到了82.8%的准确率,超过了所有基于K均值的方法。值得注意的是,与基于K-means的技术相比,鉴别器的特征图要少得多(最高层为512),但由于有4×4个空间位置的多个层,鉴别器确实会导致更大的总特征向量大小。DCGANs的性能仍然低于样本CNN。
综上所述,DCGAN的效果还是不错的。














 528
528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









