







GAN/DCGAN原理、公式推导及实践
GAN学习:GAN/DCGAN原理、公式推导及实践
生成对抗网络(GAN)是深度学习领域一个相当有趣的内容。最近补习了一下相关的论文,也推了下公式、做了一点简单的实践,因此写了这篇文章来对GAN进行介绍。大致分为三个部分
- GAN:介绍GAN的思想、原理,以及公式推导和训练过程
- DCGAN:引入DCGAN,介绍基于深度卷积网络的GAN,并谈一下自己对GAN的理解
- 动漫头像生成:使用Pytorch,实现了一个对DCGAN的简单应用
一、GAN
GAN原理简介
GAN的起源应该是Ian Goodfellow大牛的这篇paper。
GAN的基本原理很简单,以图片生成领域为例,整个网络由两个部分构成:G(Generator),即生成器,以及D(Discriminator),判别器。
借用这篇博客的图片可以很清晰地看到整个过程,G接收按照一定概率分布生成的随机分布作为噪声,生成和真实数据尽可能类似的图片;而D则负责从真实数据集和生成的图片中,区分真假。两者的目的相反,由此构成了一个博弈过程,这就是生成对抗网络名称的由来。

直观上来说,随着训练的过程,D的分辨能力会得到提高,而这又会迫使G生成更加逼真的样本,最后理想情况下,生成的虚假样本和真实样本基本上完全一致,D对任意样本判断其属于真实样本的概率都是0.5,等同于随机猜。GAN的一文中对这一过程给出了示意图:

其中,黑色虚线可以视作真实样本的分布(离散的),而绿色实线则是生成器生成样本的分布。蓝色虚线可以看作是分类器,用于输出给定x的情况下,最后样本属于真实类别的概率。由于一开始蓝色虚线性能不佳,此时即使生成了样本也无从判断样本的逼真程度,因此往往先训练分类器,达到(b)图中比较好的效果。在分类器如图(b)中所示,能够根据给定的x判断属于哪个分布后,再训练生成器就可以让生成器生成的分布去拟合真实样本的分布,最后达到(d)当中的理想效果。
GAN的应用非常广泛,包括但不限于针对监督学习样本稀缺下的数据增广,辅助半监督学习,以及大量涉及到生成和图片翻译的领域。例如影片的修复、上色、辅助拍摄,超分辨率,动漫领域的动画生成和虚拟主播等等。
数学描述
针对GAN的目标,原论文给出了如下数学描述,假定用于生成的噪声分布是
p
z
(
z
)
p_z(z)
pz(z),真实数据分布是
p
x
(
x
)
p_x(x)
px(x),同时生成器和辨别器分别为G和D,则GAN的目标可以通过如下公式描述:
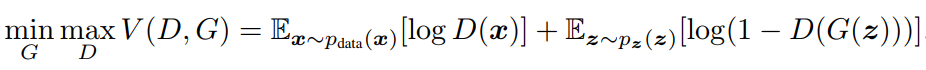
这里的公式形式其实和常见的交叉熵损失函数很像,但要注意没有负号。D(x)表示x来源于真实数据的分布,理想情况下,D(x)=1,logD(x)=0。若是分类器不理想,则D(x)输出越小,logD(x)则会越小。G(z)表示噪声经过生成器后生成的样本,D(G(z))则是分类器认为生成样本属于真实样本的概率,理想情况下这个数值为0,但当性能越不好,D(G(z))越大,log(1-D(G(z)))就会越小。总而言之,后面两项期望的和越大,分类器识别能力越好。
再观察估值函数V(G,D)前面的min/max,就很明显了,最终的目标是求外面的minG,G的目标是让V最小,达到以假乱真的目的;而内部嵌套的maxD,则代表D是在G给定的情况下,最大化V,即给定生成器,得到识别能力最好的分辨器。
公式推导
得到了GAN的数学化建模后,我们需要确定3个问题:
- 假设G和D有足够的容量(没有参数限制),该问题是否真的有解呢?要知道,如果这个问题在数学上就无解,那么我们再怎么训练也是没有意义的。
- 对于DNN这种很难进行数学建模来描述G/D的模型来说,怎么逼近解?
- 解是否可达到的问题。
我们将在这部分讨论第1个问题,并在下一个部分讨论第2个问题。第3个问题论文中有过一定的讨论,由于比较复杂我们在这篇博客里暂时不做总结。
先看论文怎么谈第一个问题的,对于第一个问题,要分两步求解:在G固定的情况下,求出最佳的分类器
D
G
∗
(
x
)
D_G^*(x)
DG∗(x);然后将最佳分类器带回,证明该问题的有解性。
第一步:求最优D
展开V(G,D)并对第二项进行换元
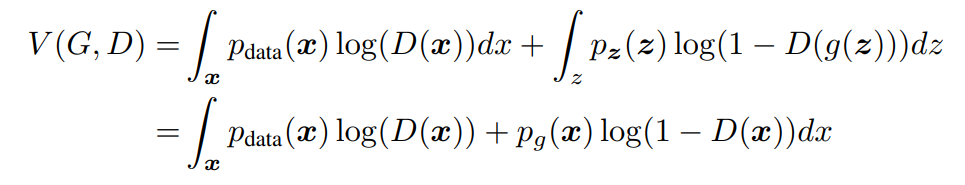
不难看出来,第一行其实就是原有的V(G,D)对期望公式的展开。问题是第二行是怎么得到的?一个直观的思路是令g(z)=x,并进行换元,具体的公式推导参考这篇博客。这里的
p
g
(
x
)
p_g(x)
pg(x)实际上代表了由z生成的x的分布,和二者都有联系。我们之所以在这里不展开说这个换元,是因为这个方式要求生成器必须可逆,而对很多问题,尤其是DNN来说这基本是不可能的。对于这一问题可以参考机器之心里的结论。完整的推导比较复杂,有兴趣的同学可以到这里自行推导。
按照paper中的符号,我们令:
p
d
a
t
a
(
x
)
=
a
,
p
g
(
x
)
=
b
,
D
(
x
)
=
y
p_{data}(x)=a,p_g(x)=b,D(x)=y
pdata(x)=a,pg(x)=b,D(x)=y,那么可以得到积分内的积分函数:
f
(
y
)
=
a
l
o
g
(
y
)
+
b
l
o
g
(
1
−
y
)
f(y)=alog(y)+blog(1-y)
f(y)=alog(y)+blog(1−y)
对f(y)求一阶导和二阶导,并求出极值点:
f
′
(
y
)
=
a
y
−
b
1
−
y
{f}'(y)=\frac{a}{y} - \frac{b}{1-y}
f′(y)=ya−1−yb
f
′
(
y
)
=
0
⇒
y
=
a
a
+
b
{f}'(y)=0\Rightarrow y=\frac{a}{a+b}
f′(y)=0⇒y=a+ba
f
′
′
(
y
)
=
−
a
y
2
−
b
(
1
−
y
)
2
<
0
{f}''(y)=-\frac{a}{y^2} - \frac{b}{(1-y)^2} < 0
f′′(y)=−y2a−(1−y)2b<0
a/(a+b)是极值点,而由于二阶导恒小于0,该极值点是最大值,且f(y)有且仅有这一个最大值。
因此,我们可以得到:
V
(
G
,
D
)
=
∫
x
f
(
y
)
d
x
=
⩽
∫
x
max
y
f
(
y
)
d
x
V(G,D)= \int_{x}f(y)dx=\leqslant \int_{x}\max\limits_yf(y)dx
V(G,D)=∫xf(y)dx=⩽∫xymaxf(y)dx
注意当x变换的时候,对于每个x,y都可以取到相应的唯一最大值,因此等号可以取到,当且仅当y=a/(a+b)得到的,即:
D
(
x
)
=
p
d
a
t
a
(
x
)
p
d
a
t
a
(
x
)
+
p
g
(
x
)
D(x)=\frac{p_{data}(x)}{p_{data}(x)+p_g(x)}
D(x)=pdata(x)+pg(x)pdata(x)
第二步:求最优G
我们令最优生成器为
D
G
∗
D_G^*
DG∗,此时,V(G,D)由于D已经固定,转化为根据G求最小值位置。我们令
C
(
G
)
=
∫
x
p
d
a
t
a
(
x
)
l
o
g
D
G
∗
(
G
)
+
p
g
(
x
)
l
o
g
(
1
−
D
G
∗
(
x
)
)
=
∫
x
p
d
a
t
a
(
x
)
l
o
g
p
d
a
t
a
(
x
)
p
d
a
t
a
(
x
)
+
p
g
(
x
)
+
p
g
(
x
)
l
o
g
(
1
−
p
d
a
t
a
(
x
)
p
d
a
t
a
(
x
)
+
p
g
(
x
)
)
=
−
l
o
g
4
+
∫
x
p
d
a
t
a
(
x
)
l
o
g
p
d
a
t
a
(
x
)
p
d
a
t
a
(
x
)
+
p
g
(
x
)
2
+
p
g
(
x
)
l
o
g
(
1
−
p
d
a
t
a
(
x
)
p
d
a
t
a
(
x
)
+
p
g
(
x
)
2
)
C(G)=\int_xp_{data}(x)logD^*_G(G)+p_g(x)log(1-D^*_G(x)) \\ =\int_xp_{data}(x)log\frac{p_{data}(x)}{p_{data}(x)+p_g(x)}+p_g(x)log(1-\frac{p_{data}(x)}{p_{data}(x)+p_g(x)}) \\ =-log4 + \int_xp_{data}(x)log\frac{p_{data}(x)}{\frac{p_{data}(x)+p_g(x)}{2}}+p_g(x)log(1-\frac{p_{data}(x)}{\frac{p_{data}(x)+p_g(x)}{2}})
C(G)=∫xpdata(x)logDG∗(G)+pg(x)log(1−DG∗(x))=∫xpdata(x)logpdata(x)+pg(x)pdata(x)+pg(x)log(1−pdata(x)+pg(x)pdata(x))=−log4+∫xpdata(x)log2pdata(x)+pg(x)pdata(x)+pg(x)log(1−2pdata(x)+pg(x)pdata(x))
在这里,我们通过添加分子2,构造了两个KL散度,而KL散度是大于等于0的。并且,假设存在两个分布A和B,且这两个分布的平均分布C=(A+B)/2,则它们之间的JS散度是A与C的KL散度和B与C的KL散度的二分之一,即:
J
S
D
(
A
∣
∣
B
)
=
1
2
K
L
(
A
∣
∣
C
)
+
1
2
K
L
(
B
∣
∣
C
)
JSD(A || B)=\frac{1}{2}KL(A||C)+\frac{1}{2}KL(B||C)
JSD(A∣∣B)=21KL(A∣∣C)+21KL(B∣∣C)
因此有:
C
(
G
)
=
−
l
o
g
4
+
K
L
[
p
d
a
t
a
(
x
)
∣
∣
p
d
a
t
a
(
x
)
+
p
g
(
x
)
2
]
+
K
L
[
p
d
a
t
a
(
x
)
∣
∣
p
g
(
x
)
+
p
g
(
x
)
2
]
=
−
l
o
g
4
+
2
J
S
D
(
p
d
a
t
a
(
x
)
∣
∣
p
g
(
x
)
)
C(G)=-log4 + KL\left [ p_{data}(x)|| \frac{p_{data}(x)+p_g(x)}{2} \right ] + KL\left [ p_{data}(x)|| \frac{p_{g}(x)+p_g(x)}{2} \right ] \\ = -log4+2JSD(p_{data}(x)||p_g(x))
C(G)=−log4+KL[pdata(x)∣∣2pdata(x)+pg(x)]+KL[pdata(x)∣∣2pg(x)+pg(x)]=−log4+2JSD(pdata(x)∣∣pg(x))
由JS散度的性质, 当且仅当
p
d
a
t
a
(
x
)
=
p
g
(
x
)
p_{data}(x)=p_g(x)
pdata(x)=pg(x)的时候,C(G)取到最小值-log4。 可以发现,此时最优生成器恰好恒为1/2,这和我们最开始的猜想一致。
总结:
通过上面的步骤,我们证明了这一优化问题是有解的以及最优分类器的解最终收敛到1/2。在实际应用中,尤其是DNN中,G和D都是没办法用数学描述的,这就决定了我们没办法直接使用。但是解的存在告诉我们可以在训练当中不断逼近最优解。
训练过程
我们的训练采用的是梯度下降法,求最小值的参数优化过程和传统的梯度下降法相同,而求最大值则需要符号反过来。因为GAN问题是一个博弈问题,因此不能简单地用常见的梯度下降法。而且虽然生成器可以生成连续分布,但真实数据集的分布必然是离散的。考虑到这些,论文给出的方法如下:

总结来说,先训练k次分类器,再训练一次生成器。训练分类器的时候会在生成器和数据集中采样,而训练生成器仅在生成器部分采样。这个过程不断重复,对抗过程从直观描述就是固定生成器,优化分类器使分类性能最好;固定分类器,优化生成器使结果更具有欺骗性这一博弈过程的重复。
注意这里用的是Minibatch,也就是说,在训练生成器之前,只需要判断数据集中的部分样本即可。因为判别所有样本非常耗时,而且容易引起过拟合。而之所以先训练分类器,是因为在分类器性能不佳的情况下,优化生成器没有意义。最后借用这篇文章里看到的一幅图来简单地可视化对抗过程:


二、DCGAN
在GAN当中使用DNN
DCGAN是将DNN应用在GAN上比较成功的一篇文章,作者将其称为DCGAN。主体思想和GAN基本相同,重点是如何利用卷积神经网络来构造生成器和分类器。
这里可以贴一下作者最终设计出来的生成器:

要注意,尽管这里图中的标注是CONV X,但是根据注释我们知道,这里的CONV实际上是deconv,也就是Pytorch当中的Convtranspose。我们都知道,deconv的前向和conv的后向传播非常相像。如果我们从后往前地看待这个生成器,就会发现,这是一个非常典型的卷积神经网络,使用conv卷积,feature map逐渐减小而且通道数逐渐增加。实际上,分类器的构造和这个过程非常相似。
当然,你可以设计更多的层,或者更多的通道数,总的来说,DCGANs的作者认为使用DNN的GANs应该遵循如下原则:
- 使用stride来替代pooling(和ResNet类似),同时,不要有全连接层
- G和D中都要使用BN
- G中所有的层的激活函数都使用ReLU,但是最后一层使用Tanh约束生成图像的范围
- D中所有的层的激活函数都使用LeakyReLU,但是最后一层使用Sigmoid输出概率
对GAN的一点思考
GAN到底学习到了什么呢?在对分类器的可视化中,作者发现不同的filters可能对应不同的部件:

个人认为,神经网络前向传播的过程某种程度上可以看作,特征图对某种特定部件的响应的结果,每一层是对某种部件的检测,而层数的加深是部件的组合更复杂、语义性更高;而生成器实质上是判别器的逆过程,可以视作生成器将原有的输入看作最终的响应,由响应生成各个部件,并在后续的逐层完成复杂部件到简单部件的拆解。当然,这只是一种猜想。
另一个很有趣的实验是,作者发现,GAN某种程度上也符合叠加原理,这是否也说明了,看似不同的输入和输出之间有特定的语义关系?还有其它一些实验,比如,去掉含有窗户的样本,最后生成的样本有什么影响?在GAN训练的过程中,生成图像是怎样变化的。大家也可以去看看论文看作者怎么考虑这个问题。本身个人觉得这一问题是开放性的,因此这里不下结论。

其它一些可能的问题:
- DCGAN的输入为什么是随机噪声?不可以有更丰富的输入,比如,我输入类别信息,指定生成的输出是某个类?回答: 可以,实质上已经有人做过了。关于对GAN的更复杂的应用,可以看这篇博客综述
- 使用GAN生成数据再去训练是不是不靠谱?因为不管怎么操作,信息量是无法增加的。回答: 根据信息论,确实如此,但是实质上,数据增广也没有增加信息量,一样提高了模型效果的效果。GAN从这个意义上可以视作更复杂的,需要从训练集当中总结数据的数据增广方式。至于数据增广为什么可以提升效果,个人观点里,DNN在学习数据集的分布,而真实数据集是离散的不是连续的曲线,或者说,曲线有很多漏洞是一段一段的。而数据增广实际上是在添补曲线让曲线更完整。
- GAN在CV当中有什么应用吗?回答: 超分辨率和图像翻译某种程度上都可以看作CV问题,如果是比较直观的话,有人用GAN来做目标检测,主要是对小目标做增广和超分辨率。
三、实践
笔者参考Pytorch的tutorials和github上的一个实现进行了DCGAN的简单实践。这里吐槽下GAN的参数真的挺难调的,笔者之前尝试了另一个动漫的数据集和其它实验参数结果一直没办法收敛,后来参考了DCGAN的参数才成功。
最终的代码在这里,欢迎围观拍砖,后面应该会增加一些更复杂的GAN。我们在这篇博客中简单看一下。
生成器:
import torch.nn as nn
class DCGenerator(nn.Module):
def __init__(self, input_dim, num_filters, output_dim):
super(DCGenerator, self).__init__()
self.hidden_layer = nn.Sequential()
for i in range(len(num_filters)):
# Deconv layer
if i == 0:
deconv = nn.ConvTranspose2d(input_dim, num_filters[i], kernel_size=4, stride=1, padding=0, bias=False)
else:
deconv = nn.ConvTranspose2d(num_filters[i-1], num_filters[i], kernel_size=4, stride=2, padding=1, bias=False)
deconv_name = 'deconv' + str(i + 1)
self.hidden_layer.add_module(deconv_name, deconv)
# BN layer
bn_name = 'bn' + str(i + 1)
self.hidden_layer.add_module(bn_name, nn.BatchNorm2d(num_filters[i]))
# Activation
act_name = 'act' + str(i + 1)
self.hidden_layer.add_module(act_name, nn.ReLU(inplace=True))
self.output_layer = nn.Sequential(
nn.ConvTranspose2d(num_filters[i], output_dim, kernel_size=4, stride=2, padding=1, bias=False),
nn.Tanh()
)
def forward(self, x):
h = self.hidden_layer(x)
out = self.output_layer(h)
return out
可以看到,生成器主要使用ConvTranspose2d。在隐层部分,由多个连续的ConvTranspose2d-BN-ReLU形式的连续模块构成。而输出层则则是ConvTranspose2d-Tanh,input_dim是随机噪声z的维度,output_dim在彩色和RGB图像时候分别为3/1。num_filters默认使用[512, 256, 128, 64],代表隐层里有4个结构,通道数最开始映射到512,然后逐渐减小。
分类器,基本上可以视作生成器的逆过程,卷积换成了Conv2d,输出用Sigmoid表示概率:
import torch.nn as nn
class DCDiscriminator(nn.Module):
def __init__(self, input_dim, num_filters, output_dim):
super(DCDiscriminator, self).__init__()
self.hidden_layer = nn.Sequential()
for i in range(len(num_filters)):
if i == 0:
conv = nn.Conv2d(input_dim, num_filters[i], kernel_size=4, stride=2, padding=1, bias=False)
else:
conv = nn.Conv2d(num_filters[i-1], num_filters[i], kernel_size=4, stride=2, padding=1, bias=False)
conv_name = 'conv' + str(i + 1)
self.hidden_layer.add_module(conv_name, conv)
# Batch normalization
if i != 0:
bn_name = 'bn' + str(i + 1)
self.hidden_layer.add_module(bn_name, nn.BatchNorm2d(num_filters[i]))
# Activation
act_name = 'act' + str(i + 1)
self.hidden_layer.add_module(act_name, nn.LeakyReLU(0.2, inplace=True))
self.output_layer = nn.Sequential(
nn.Conv2d(num_filters[i], output_dim, kernel_size=4, stride=1, padding=0, bias=False),
nn.Sigmoid()
)
def forward(self, x):
h = self.hidden_layer(x)
out = self.output_layer(h)
return out
再看一下训练部分的核心代码:
real_label = 1
fake_label = 0
# loss and optimizer
criterion = nn.BCELoss()
optimizerG = optim.Adam(G.parameters(), lr=cfg.lr, betas=cfg.betas)
optimizerD = optim.Adam(D.parameters(), lr=cfg.lr, betas=cfg.betas)
for epoch in range(num_epochs):
for i, data in enumerate(dataloader, 0):
D.zero_grad()
real = data[0].to(device)
bs = real.size(0)
# train D
# Compute loss of true images, label is 1
label = torch.full((bs,), real_label, device=device)
output = D(real).view(-1)
errD_real = criterion(output, label)
errD_real.backward()
D_x = output.mean().item()
# Compute loss of fake images, label is 0
noise = torch.randn(bs, cfg.G['input_dim'], 1, 1, device=device)
fake = G(noise)
label.fill_(fake_label)
output = D(fake.detach()).view(-1)
errD_fake = criterion(output, label)
errD_fake.backward()
D_G_z1 = output.mean().item()
errD = errD_fake + errD_real
optimizerD.step()
# train G
# The purpose of the generator is to make the generated picture more realistic
# label is 1
G.zero_grad()
label.fill_(real_label)
output = D(fake).view(-1)
errG = criterion(output, label)
errG.backward()
D_G_z2 = output.mean().item()
optimizerG.step()
代码本身并不复杂。在这里说下两个要注意的地方:
- 训练分类器的时候,不需要对G的参数进行优化,因此,生成的图片要加detach,避免梯度回传
- 训练生成器Pytorch的tutorials方法比较巧妙。不需要梯度反方向,因为我生成器的目标就是希望生成的图片尽可能真,所以我把目标的label设置成1就是正确的优化方向了,当然,最后也可以正确训练
最后,是训练的损失函数,以及最后真假图片的对比,可以看到,部分图片效果还是很不错的:

















 2740
2740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









