







1.研究内容:
基于车辆行驶异常事件检测研究主要包括检测检测车辆的行驶速度异常、检测到流量异常行为的处理两个部分。
2.研究目标:
检测车辆违规变道:熟练运用图像处理的相关工具,可对车辆的异常变道行为进行检测。检测车辆的行驶速度异常:了解模式识别的相关工具,并对车辆的行驶速度进行分类从而识别相应的异常行为。检测到异常行为的处理:对于车辆异常行为的检测,及时记录异常行为并发出警报。
3.解决的关键问题:
1.理解熟悉车辆行驶异常事件检测的流程与方法;
2.建立车辆行驶异常的模型;
3.根据实际问题优化模型。
4.图片展示
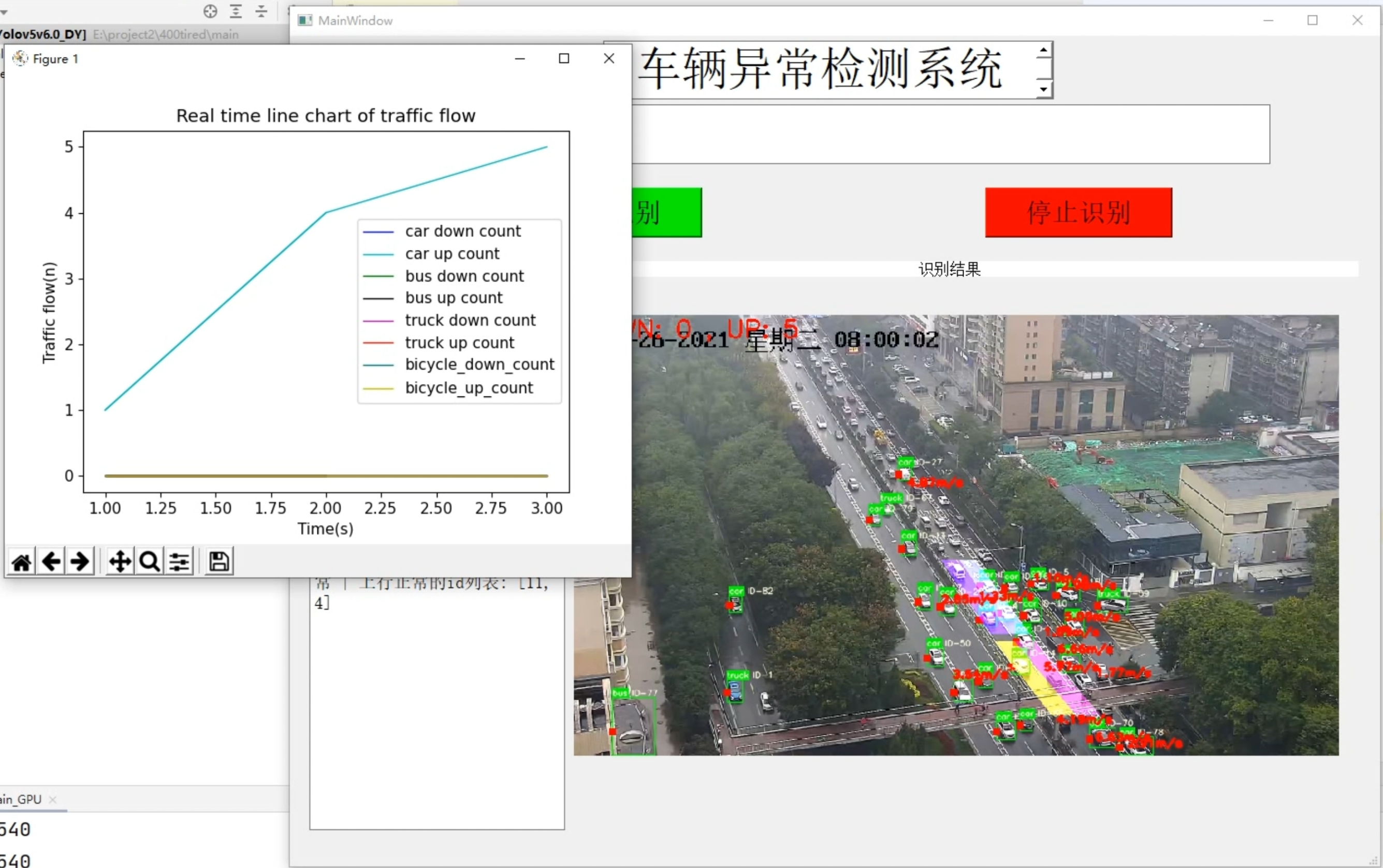
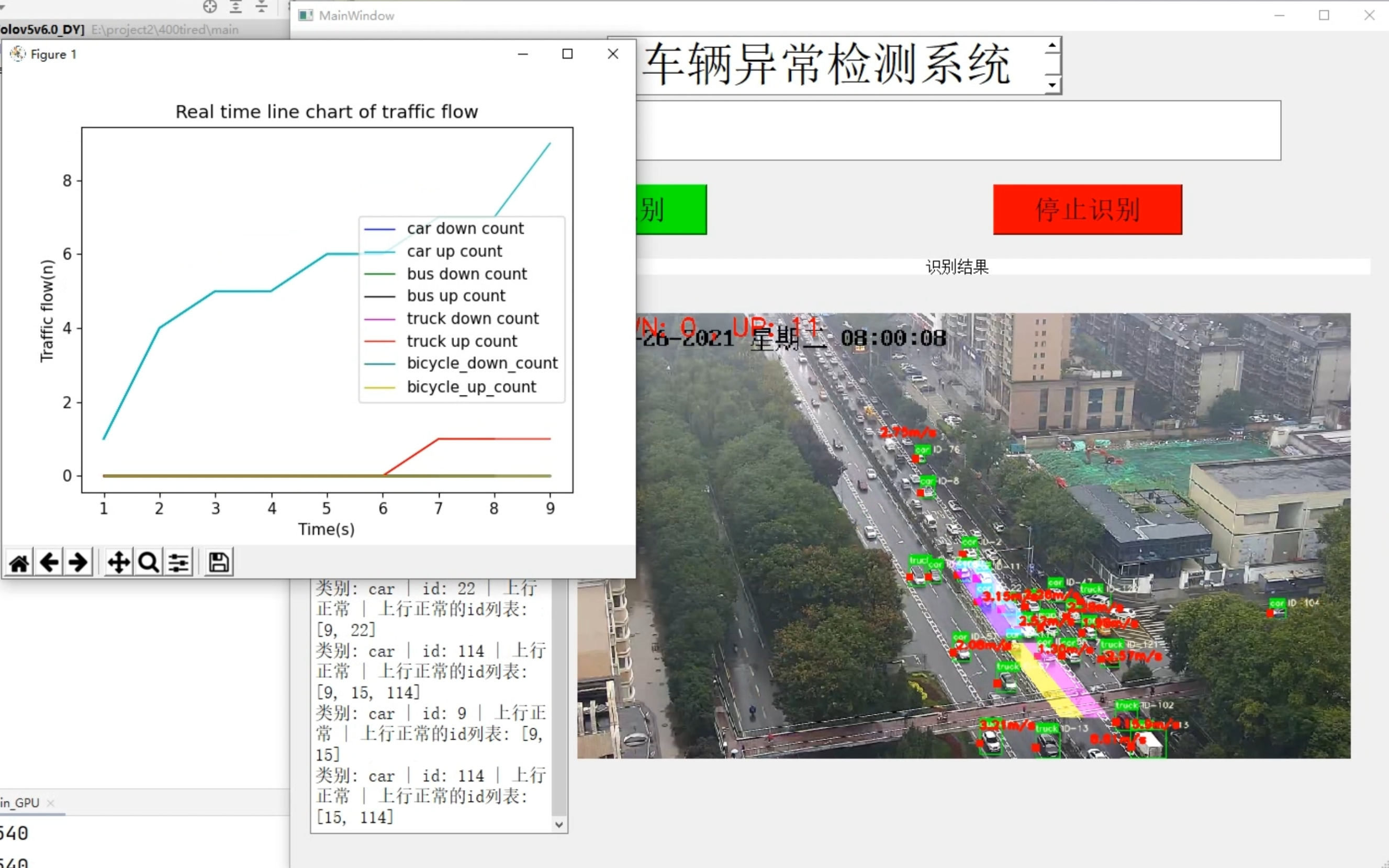
5.视频展示
[YOLOv7]基于YOLO&Deepsort的车速&车流量检测系统(源码&部署教程)_哔哩哔哩_bilibili
6.Deepsort目标追踪
(1)获取原始视频帧
(2)利用目标检测器对视频帧中的目标进行检测
(3)将检测到的目标的框中的特征提取出来,该特征包括表观特征(方便特征对比避免ID switch)和运动特征(运动特征方
便卡尔曼滤波对其进行预测)
(4)计算前后两帧目标之前的匹配程度(利用匈牙利算法和级联匹配),为每个追踪到的目标分配ID。
Deepsort的前身是sort算法,sort算法的核心是卡尔曼滤波算法和匈牙利算法。
卡尔曼滤波算法作用:该算法的主要作用就是当前的一系列运动变量去预测下一时刻的运动变量,但是第一次的检测结果用来初始化卡尔曼滤波的运动变量。
匈牙利算法的作用:简单来讲就是解决分配问题,就是把一群检测框和卡尔曼预测的框做分配,让卡尔曼预测的框找到和自己最匹配的检测框,达到追踪的效果。
sort工作流程如下图所示:
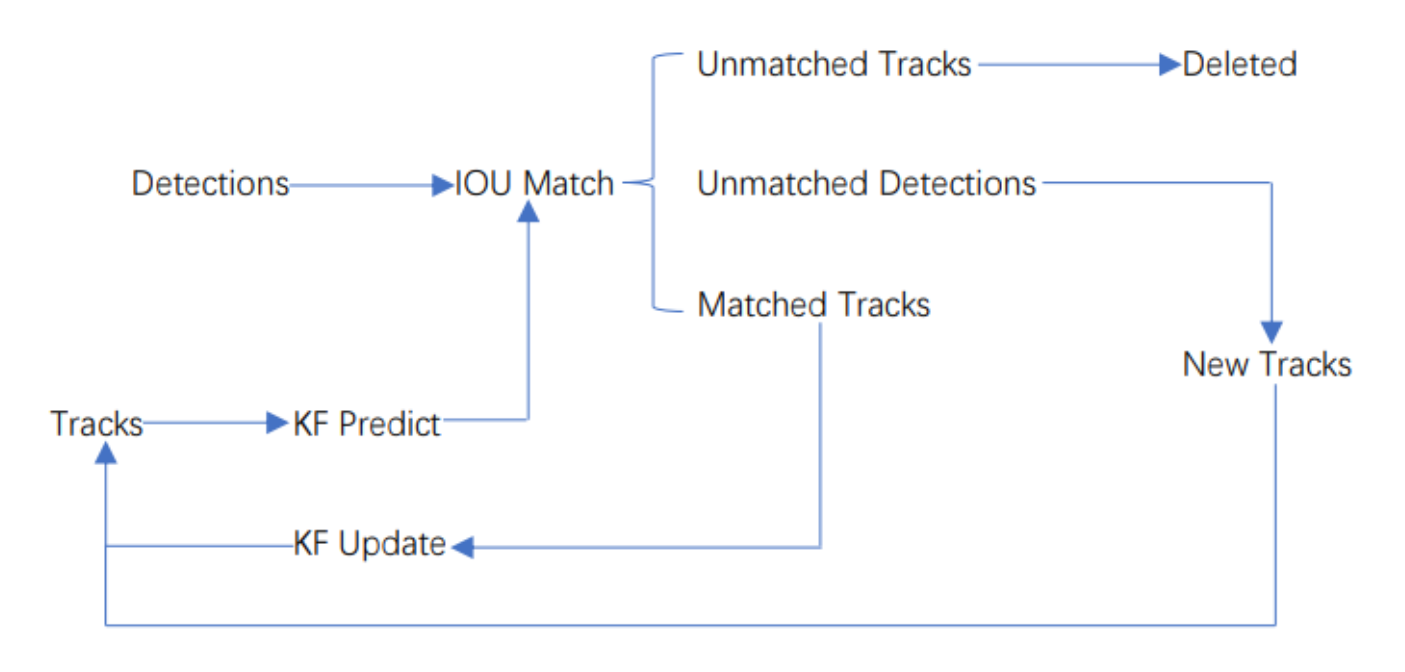
Detections是通过目标检测到的框框。Tracks是轨迹信息。
整个算法的工作流程如下:
(1)将第一帧检测到的结果创建其对应的Tracks。将卡尔曼滤波的运动变量初始化,通过卡尔曼滤波预测其对应的框框。
(2)将该帧目标检测的框框和上一帧通过Tracks预测的框框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(3)将(2)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(4)反复循环(2)-(3)步骤,直到视频帧结束。
Deepsort算法流程
由于sort算法还是比较粗糙的追踪算法,当物体发生遮挡的时候,特别容易丢失自己的ID。而参考该博客改进后的算法在sort算法的基础上增加了级联匹配(Matching Cascade)和新轨迹的确认(confirmed)。Tracks分为确认态(confirmed),和不确认态(unconfirmed),新产生的Tracks是不确认态的;不确认态的Tracks必须要和Detections连续匹配一定的次数(默认是3)才可以转化成确认态。确认态的Tracks必须和Detections连续失配一定次数(默认30次),才会被删除。
Deepsort算法的工作流程如下图所示:
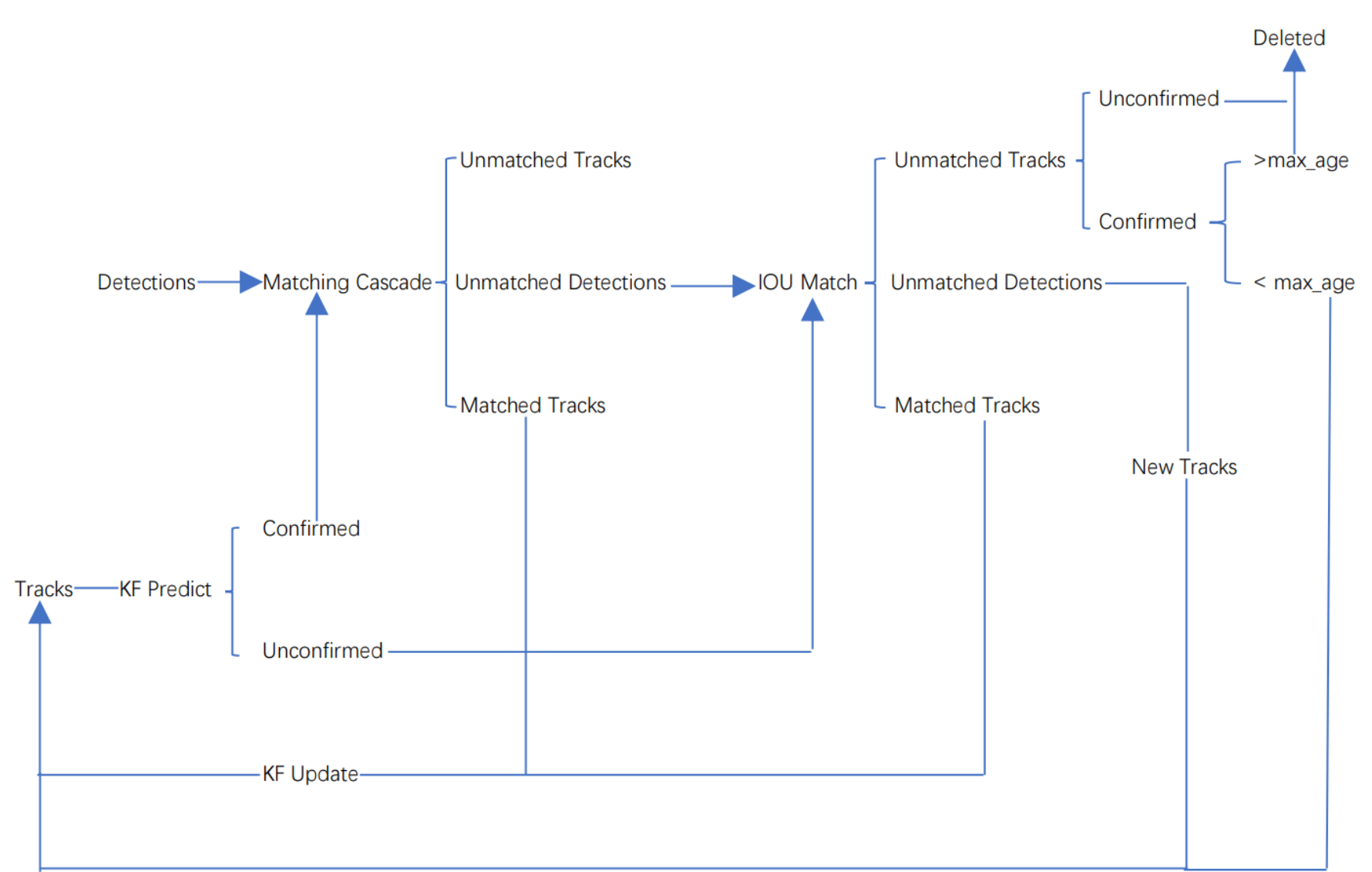
整个算法的工作流程如下:
(1)将第一帧次检测到的结果创建其对应的Tracks。将卡尔曼滤波的运动变量初始化,通过卡尔曼滤波预测其对应的框框。这时候的Tracks一定是unconfirmed的。
(2)将该帧目标检测的框框和第上一帧通过Tracks预测的框框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(3)将(2)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks(因为这个Tracks是不确定态了,如果是确定态的话则要连续达到一定的次数(默认30次)才可以删除)删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(4)反复循环(2)-(3)步骤,直到出现确认态(confirmed)的Tracks或者视频帧结束。
(5)通过卡尔曼滤波预测其确认态的Tracks和不确认态的Tracks对应的框框。将确认态的Tracks的框框和是Detections进行级联匹配(之前每次只要Tracks匹配上都会保存Detections其的外观特征和运动信息,默认保存前100帧,利用外观特征和运动信息和Detections进行级联匹配,这么做是因为确认态(confirmed)的Tracks和Detections匹配的可能性更大)。
(6)进行级联匹配后有三种可能的结果。第一种,Tracks匹配,这样的Tracks通过卡尔曼滤波更新其对应的Tracks变量。第二第三种是Detections和Tracks失配,这时将之前的不确认状态的Tracks和失配的Tracks一起和Unmatched Detections一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(7)将(6)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks(因为这个Tracks是不确定态了,如果是确定态的话则要连续达到一定的次数(默认30次)才可以删除)删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(8)反复循环(5)-(7)步骤,直到视频帧结束。
7.准备YOLOv7格式数据集
如果不懂yolo格式数据集是什么样子的,建议先学习一下该博客。大部分CVer都会推荐用labelImg进行数据的标注,我也不例外,推荐大家用labelImg进行数据标注。不过这里我不再详细介绍如何使用labelImg,网上有很多的教程。同时,标注数据需要用到图形交互界面,远程服务器就不太方便了,因此建议在本地电脑上标注好后再上传到服务器上。
这里假设我们已经得到标注好的yolo格式数据集,那么这个数据集将会按照如下的格式进行存放。
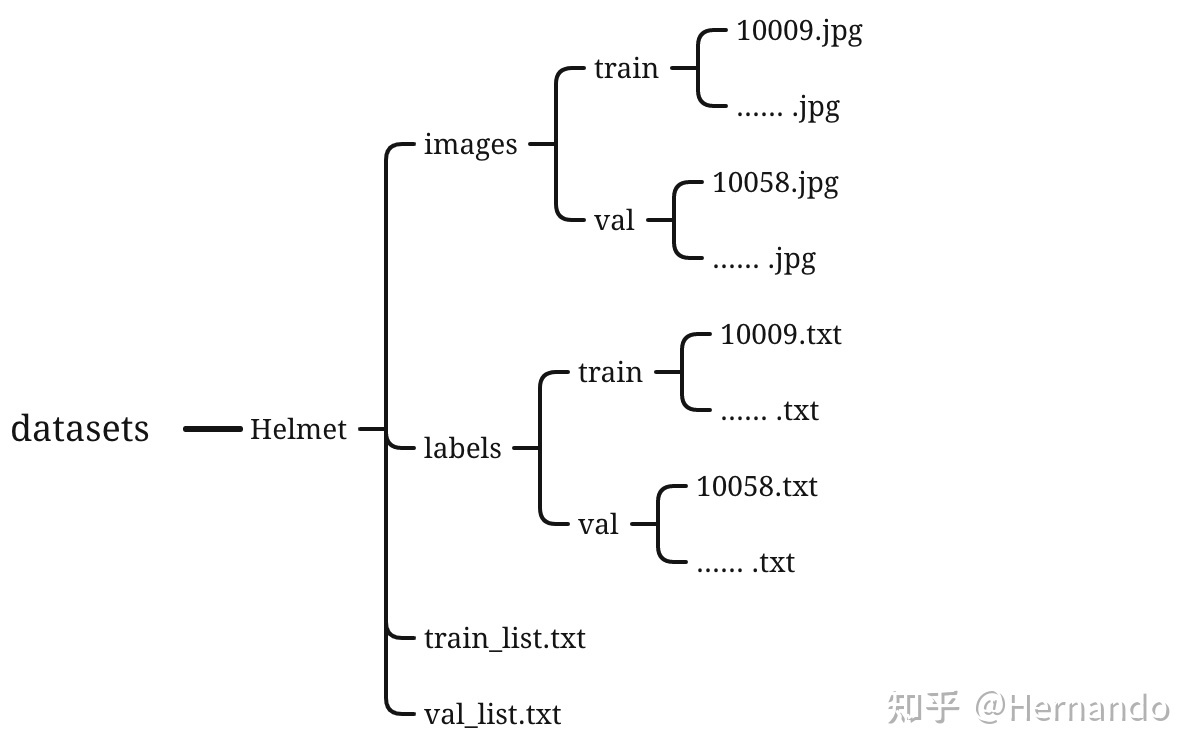
不过在这里面,train_list.txt和val_list.txt是后来我们要自己生成的,而不是labelImg生成的;其他的则是labelImg生成的。
接下来,就是生成 train_list.txt和val_list.txt。train_list.txt存放了所有训练图片的路径,val_list.txt则是存放了所有验证图片的路径,如下图所示,一行代表一个图片的路径。这两个文件的生成写个循环就可以了,不算难。
8.修改配置文件
总共有两个文件需要配置,一个是/yolov7/cfg/training/yolov7.yaml,这个文件是有关模型的配置文件;一个是/yolov7/data/coco.yaml,这个是数据集的配置文件。
第一步,复制yolov7.yaml文件到相同的路径下,然后重命名,我们重命名为yolov7-Helmet.yaml。
第二步,打开yolov7-Helmet.yaml文件,进行如下图所示的修改,这里修改的地方只有一处,就是把nc修改为我们数据集的目标总数即可。然后保存。

第三步,复制coco.yaml文件到相同的路径下,然后重命名,我们命名为Helmet.yaml。
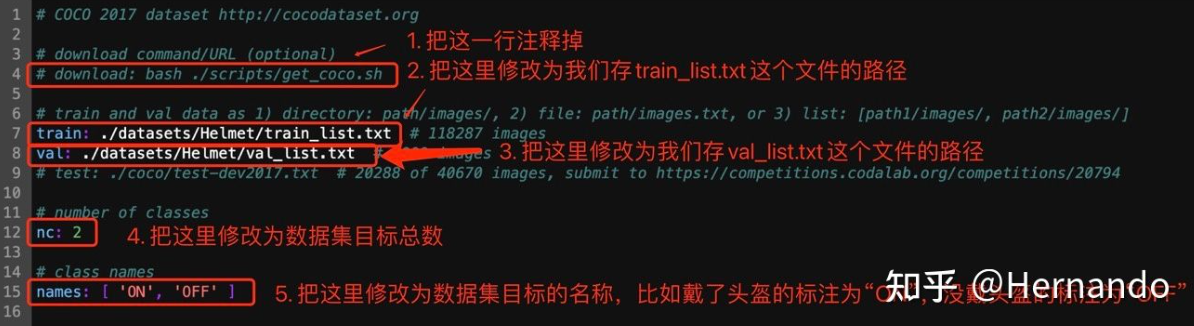
第四步,打开Helmet.yaml文件,进行如下所示的修改,需要修改的地方为5处。
第一处:把代码自动下载COCO数据集的命令注释掉,以防代码自动下载数据集占用内存;第二处:修改train的位置为train_list.txt的路径;第三处:修改val的位置为val_list.txt的路径;第四处:修改nc为数据集目标总数;第五处:修改names为数据集所有目标的名称。然后保存。
9.训练代码
import argparse
import logging
import math
import os
import random
import time
from copy import deepcopy
from pathlib import Path
from threading import Thread
import numpy as np
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
import torch.utils.data
import yaml
from torch.cuda import amp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
import test # import test.py to get mAP after each epoch
from models.experimental import attempt_load
from models.yolo import Model
from utils.autoanchor import check_anchors
from utils.datasets import create_dataloader
from utils.general import labels_to_class_weights, increment_path, labels_to_image_weights, init_seeds, \
fitness, strip_optimizer, get_latest_run, check_dataset, check_file, check_git_status, check_img_size, \
check_requirements, print_mutation, set_logging, one_cycle, colorstr
from utils.google_utils import attempt_download
from utils.loss import ComputeLoss, ComputeLossOTA
from utils.plots import plot_images, plot_labels, plot_results, plot_evolution
from utils.torch_utils import ModelEMA, select_device, intersect_dicts, torch_distributed_zero_first, is_parallel
from utils.wandb_logging.wandb_utils import WandbLogger, check_wandb_resume
logger = logging.getLogger(__name__)
def train(hyp, opt, device, tb_writer=None):
logger.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
save_dir, epochs, batch_size, total_batch_size, weights, rank, freeze = \
Path(opt.save_dir), opt.epochs, opt.batch_size, opt.total_batch_size, opt.weights, opt.global_rank, opt.freeze
# Directories
wdir = save_dir / 'weights'
wdir.mkdir(parents=True, exist_ok=True) # make dir
last = wdir / 'last.pt'
best = wdir / 'best.pt'
results_file = save_dir / 'results.txt'
# Save run settings
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.dump(hyp, f, sort_keys=False)
with open(save_dir / 'opt.yaml', 'w') as f:
yaml.dump(vars(opt), f, sort_keys=False)
# Configure
plots = not opt.evolve # create plots
cuda = device.type != 'cpu'
init_seeds(2 + rank)
with open(opt.data) as f:
data_dict = yaml.load(f, Loader=yaml.SafeLoader) # data dict
is_coco = opt.data.endswith('coco.yaml')
# Logging- Doing this before checking the dataset. Might update data_dict
loggers = {'wandb': None} # loggers dict
if rank in [-1, 0]:
opt.hyp = hyp # add hyperparameters
run_id = torch.load(weights, map_location=device).get('wandb_id') if weights.endswith('.pt') and os.path.isfile(weights) else None
wandb_logger = WandbLogger(opt, Path(opt.save_dir).stem, run_id, data_dict)
loggers['wandb'] = wandb_logger.wandb
data_dict = wandb_logger.data_dict
if wandb_logger.wandb:
weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp # WandbLogger might update weights, epochs if resuming
nc = 1 if opt.single_cls else int(data_dict['nc']) # number of classes
names = ['item'] if opt.single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
assert len(names) == nc, '%g names found for nc=%g dataset in %s' % (len(names), nc, opt.data) # check
# Model
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(rank):
attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint
model = Model(opt.cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (opt.cfg or hyp.get('anchors')) and not opt.resume else [] # exclude keys
state_dict = ckpt['model'].float().state_dict() # to FP32
state_dict = intersect_dicts(state_dict, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(state_dict, strict=False) # load
logger.info('Transferred %g/%g items from %s' % (len(state_dict), len(model.state_dict()), weights)) # report
else:
model = Model(opt.cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
with torch_distributed_zero_first(rank):
check_dataset(data_dict) # check
train_path = data_dict['train']
test_path = data_dict['val']
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









