







第五章 循环和关系表达式
为什么要在for语句中声明变量?
如何在for语句中声明多个变量?
string类字符串有什么优点和缺点?在什么情况下使用它们比较合适?
string类字符串是否可以用于任何类型的数据?有没有一些特殊的情况或限制?
如何选择合适的循环结构?
什么是系统时间单位?
为什么要使用clock_t类型而不是int或long类型?
为什么使用#作为停止标记?是否可以使用其他字符?
初始化二维数组时,是否可以只给部分元素赋值?如果可以,剩余的元素会被赋什么值?
如何使用动态内存分配来创建二维数组?它们有什么优势和缺陷?
- 计算机的功能:计算机除了存储数据外,还可以对数据进行各种操作,如分析、合并、重组、抽取、修改、推断、合成等。
- 程序控制语句:为了发挥计算机的操控能力,程序需要有执行重复的操作和进行决策的工具,如循环和分支语句。
- C++语言:C++使用与常规C语言相同的for循环、while循环、do while循环、if语句和switch语句,这些语句都使用关系表达式和逻辑表达式来控制其行为。
5.1 for 循环
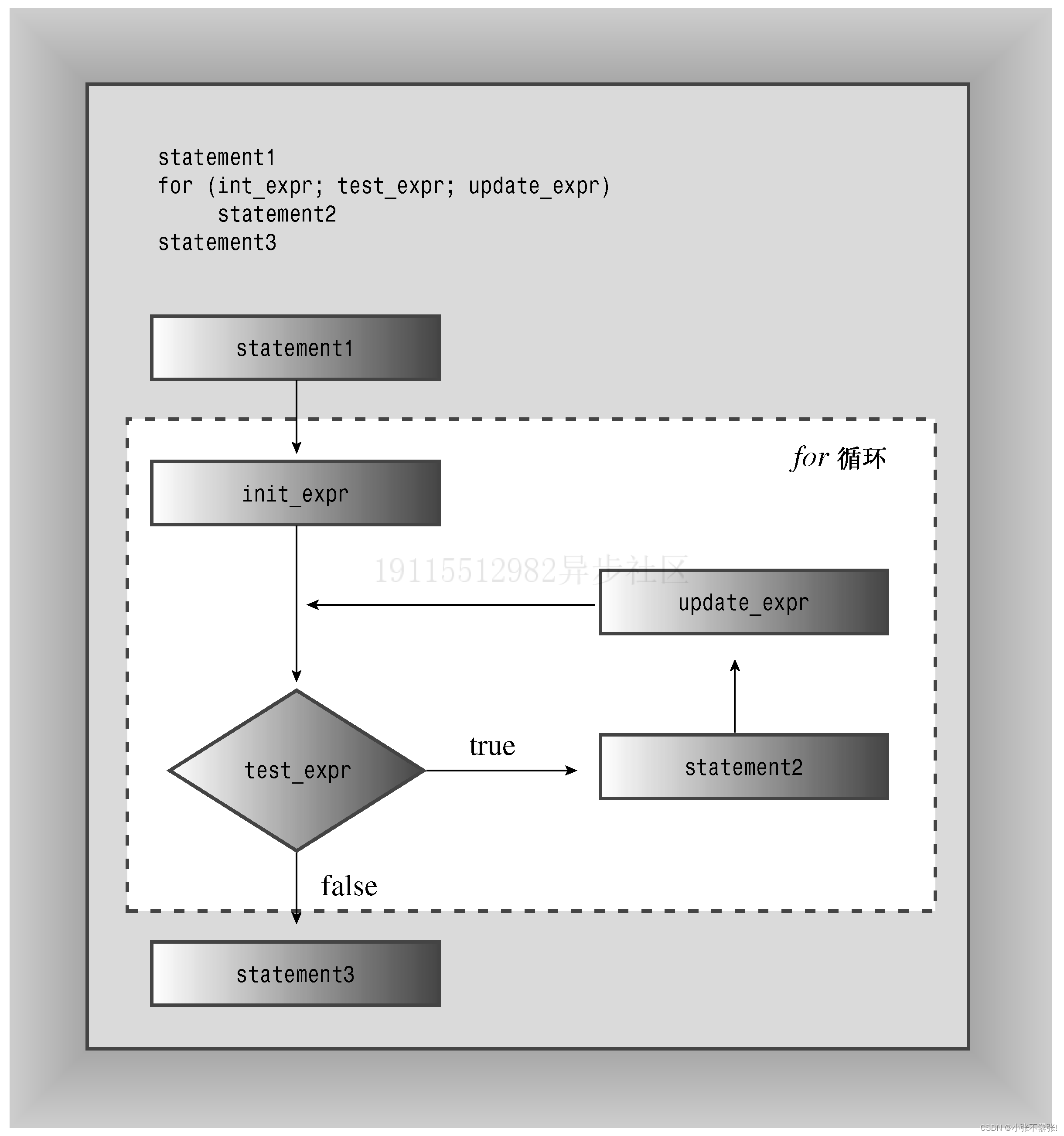
- for循环的结构:for循环由初始化、测试、更新和循环体四个部分组成,用分号隔开,放在圆括号中。循环体可以是一条或多条语句,用花括号括起来。
- for循环的执行过程:for循环首先执行初始化部分,然后执行测试部分,如果测试结果为真,则执行循环体,再执行更新部分,然后重复这一过程,直到测试结果为假,才结束循环。
- 递增运算符:递增运算符(++)是一种特殊的运算符,它将操作数的值加1。它可以用在for循环的更新部分,也可以用在其他地方。
// forloop.cpp -- introducing the for loop
#include <iostream>
int main()
{
using namespace std;
int i; // create a counter
// initialize; test ; update
for (i = 0; i < 5; i++)
cout << "C++ knows loops.\n";
cout << "C++ knows when to stop.\n";
return 0;
}
输出:加粗样式
C++ knows loops.
C++ knows loops.
C++ knows loops.
C++ knows loops.
C++ knows loops.
C++ knows when to stop.
5.1.1 for循环的组成部分
- for循环的作用:for循环是一种用来执行重复操作的程序控制语句,它可以方便地控制循环的次数和条件。
- for循环的结构:for循环由四个部分组成,分别是初始化、测试、更新和循环体,它们用分号隔开,放在圆括号中。循环体可以是一条或多条语句,用花括号括起来。
- for循环的执行过程:for循环首先执行初始化部分,然后执行测试部分,如果测试结果为真,则执行循环体,再执行更新部分,然后重复这一过程,直到测试结果为假,才结束循环。
- for循环的特点:for循环是入口条件循环,即在每轮循环之前检查测试条件。for循环可以使用任意表达式作为测试条件和更新部分,只要它们能被转换为bool值。for循环可以使用递增运算符(++)和递减运算符(−−)来简化变量的增减操作。
- 表达式和语句的概念:表达式是值或值与运算符的组合,每个表达式都有值。语句是程序的基本组成单位,可以是表达式加上分号,也可以是其他形式的语句。
- 表达式的值和副作用:表达式的值通常是很明显的,但有些表达式的值不那么直观,如赋值表达式和关系表达式。有些表达式在求值的过程中会改变内存中数据的值,这种现象叫做副作用。副作用可以是预期的效果,也可以是不希望发生的事情。
- for语句的结构和执行过程:for语句是一种用来执行重复操作的程序控制语句,它由四个部分组成,分别是初始化、测试、更新和循环体,它们用分号隔开,放在圆括号中。for语句首先执行初始化部分,然后执行测试部分,如果测试结果为真,则执行循环体,再执行更新部分,然后重复这一过程,直到测试结果为假,才结束循环。
- 非表达式和语句的概念:有些概念不符合“语句=表达式+分号”的模式,如返回语句、声明语句和for语句。这些概念不能被赋值或用作操作数,也没有值。
- for语句的修改规则:C++允许在for语句的初始化部分中声明和初始化变量,这样做可以方便地控制变量的作用域和生命周期。为了实现这一特性,C++修改了for语句的句法,将原来的第一个表达式替换为一个语句,可以是表达式语句或声明语句。
为什么要在for语句中声明变量?我们继续往下走。
如何在for语句中声明多个变量?我们继续往下走。
5.1.2 回到for循环
- 回到for循环的目的:这篇内容使用for循环来完成更多的工作,如计算并存储前16个阶乘,演示了for循环如何与数组和常量协同工作,以及如何在for循环的初始化部分中声明和初始化变量。
- 表达式和语句的区别:表达式是值或值与运算符的组合,每个表达式都有值。语句是程序的基本组成单位,可以是表达式加上分号,也可以是其他形式的语句。不是所有的语句都可以从分号中删除变成表达式,如返回语句、声明语句和for语句。
- 表达式的值和副作用:表达式的值通常是很明显的,但有些表达式的值不那么直观,如赋值表达式和关系表达式。有些表达式在求值的过程中会改变内存中数据的值,这种现象叫做副作用。副作用可以是预期的效果,也可以是不希望发生的事情。一种避免副作用的方法是使用常量或不可修改的变量作为表达式的操作数,另一种避免副作用的方法是使用纯函数或无副作用函数作为表达式的运算符。一种利用副作用的方法是使用赋值运算符或递增运算符等具有副作用的运算符来改变变量的值或状态,另一种利用副作用的方法是使用输入输出函数或其他具有副作用函数来与用户交互或实现某些功能。
5.1.3 修改步长
- 可以通过修改更新表达式来实现不同的步长,例如i = i + by或i = i * i + 10。
- using声明可以让选定的名称可用,而不影响其他名称;using编译指令可以让整个命名空间中的所有名称可用,但可能导致名称冲突。std::是标准命名空间的前缀,可以在名称前加上它来指定使用标准命名空间中的名称。
5.1.4 使用for循环访问字符串
- 这篇内容介绍了如何使用for循环来访问字符串中的每个字符,并给出了一个用C++编写的示例程序。
- 程序使用string对象和数组表示法来存储和操作用户输入的单词,使用size()方法来获取字符串的长度,使用递减运算符来反向遍历字符串,使用cout对象来输出字符串中的字符。
- 程序的运行结果是将用户输入的单词按相反的顺序打印出来,例如将animal打印为lamina。
// forstr1.cpp -- using for with a string
#include <iostream>
#include <string>
int main()
{
using namespace std;
cout << "Enter a word: ";
string word;
cin >> word;
// display letters in reverse order
for (int i = word.size() - 1; i >= 0; i--)
cout << word[i];
cout << "\nBye.\n";
return 0;
}
5.1.5 递增运算符(++)和递减运算符(–)
- 这篇内容介绍了递增运算符(++)和递减运算符(−−)的用法和特点,它们是C++中常用于循环中的运算符,可以将变量的值加1或减1。
- 这两个运算符都有前缀(prefix)和后缀(postfix)两种变体,它们对变量的影响是一样的,但是影响的时间不同。前缀版本是先修改变量的值,然后使用新值计算表达式;后缀版本是先使用变量的当前值计算表达式,然后再修改变量的值。
- 提醒读者不要在同一条语句中对同一个变量递增或递减多次,因为这样会导致不确定的行为,C++没有定义这种语句的正确结果。
// plus_one.cpp -- the increment operator
#include <iostream>
int main()
{
using std::cout;
int a = 20;
int b = 20;
cout << "a = " << a << ": b = " << b << "\n";
cout << "a++ = " << a++ << ": ++b = " << ++b << "\n";
cout << "a = " << a << ": b = " << b << "\n";
return 0;
}
输出:
a = 20: b = 20
a++ = 20: ++b = 21
a = 21: b = 21
5.1.6 副作用和顺序点
- 副作用和顺序点的概念,它们与递增运算符和递减运算符的执行时机有关。副作用指的是在计算表达式时对某些东西(如变量的值)进行了修改;顺序点是程序执行过程中的一个点,在这里,进入下一步之前将确保对所有的副作用都进行了评估。
- 在C++中,语句中的分号、完整表达式的末尾、以及一些其他操作都是顺序点。这意味着在这些点之前,赋值运算符、递增运算符和递减运算符执行的所有修改都必须完成。这有助于理解后缀递增或递减运算符何时生效,以及为什么不要在同一条语句中对同一个变量递增或递减多次。
- C++11文档中不再使用“顺序点”这个术语,而是使用“顺序”这个术语,来更清晰地描述多线程编程的情况。
5.1.7 前缀格式和后缀格式
- 前缀格式和后缀格式的区别在于,前缀格式是先修改变量的值,然后使用新值计算表达式;后缀格式是先使用变量的当前值计算表达式,然后再修改变量的值。
- 如果递增或递减表达式的值没有被使用,那么从逻辑上说,使用前缀格式和后缀格式没有任何区别。但是从执行速度上说,可能有细微的差别。对于内置类型,这种差别可以忽略不计;但对于用户定义的类型,如果有用户定义的递增和递减运算符,那么前缀格式的效率会比后缀格式高,因为后缀格式需要复制一个副本,而前缀格式不需要。
5.1.8 递增 / 递减运算符和指针
- 当将递增运算符或递减运算符与指针一起使用时,会根据指针指向的数据类型的大小来调整指针的值,而不是简单地加1或减1。
- 结合使用解除引用运算符(*)和递增运算符或递减运算符来修改指针指向的值,以及不同的组合方式会产生不同的结果。这取决于运算符的位置和优先级,以及前缀格式和后缀格式的区别。
5.1.9 组合赋值运算符
- 组合赋值运算符的概念和用法,它们是一种将算术运算符和赋值运算符合并在一起的简洁的方式,可以对变量进行修改并赋值。
- 每个算术运算符都有其对应的组合赋值运算符,如+=, -=, *=, /=, %=等,它们的作用是将左操作数和右操作数进行相应的运算,并将结果赋给左操作数。因此,左操作数必须能够被赋值,如变量、数组元素、结构成员或通过对指针解除引用来标识的数据。
| 操作符 | 作用 | 示例 |
|---|---|---|
| += | 将L+R赋给L | L += R |
| -= | 将L-R赋给L | L -= R |
| *= | 将L*R赋给L | L *= R |
| /= | 将L/R赋给L | L /= R |
| %= | 将L%R赋给L | L %= R |
5.1.10 复合语句 (语句块)
- 复合语句(语句块),是一种用两个花括号将多条语句合并为一条语句的方式,可以在循环体或其他需要一条语句的地方使用。
- 复合语句的一个特性是,如果在复合语句中定义一个新的变量,则该变量只在复合语句中有效,出了复合语句后就被释放。这样可以避免变量名冲突或作用域混乱的问题。
- 在复合语句中声明一个变量,而外部语句中也有一个同名的变量,那么在复合语句中,新变量会隐藏旧变量;出了复合语句后,旧变量再次可见。
5.1.11 其他语法技巧—逗号运算符
- 逗号运算符的概念和用法,它们是一种将两个或多个表达式合并为一个表达式的方式,可以在需要一个表达式的地方使用,如for循环的控制部分。
- 逗号运算符的两个特性:一是它确保先计算第一个表达式,然后计算第二个表达式,即逗号运算符是一个顺序点;二是它规定,逗号表达式的值是第二部分的值。
- 逗号运算符的优先级和结合性,以及如何避免产生歧义或错误。逗号运算符的优先级是最低的,从左向右结合。为了避免混淆,可以使用圆括号来明确表达式的计算顺序,或者将复杂的表达式拆分成多条语句。
// forstr2.cpp -- reversing an array
#include <iostream>
#include <string>
int main()
{
using namespace std;
cout << "Enter a word: ";
string word;
cin >> word;
// physically modify string object
char temp;
int i, j;
for (j = 0, i = word.size() - 1; j < i; --i, ++j)
{ // start block
temp = word[i];
word[i] = word[j];
word[j] = temp;
} // end block
cout << word << "\nDone\n";
return 0;
}
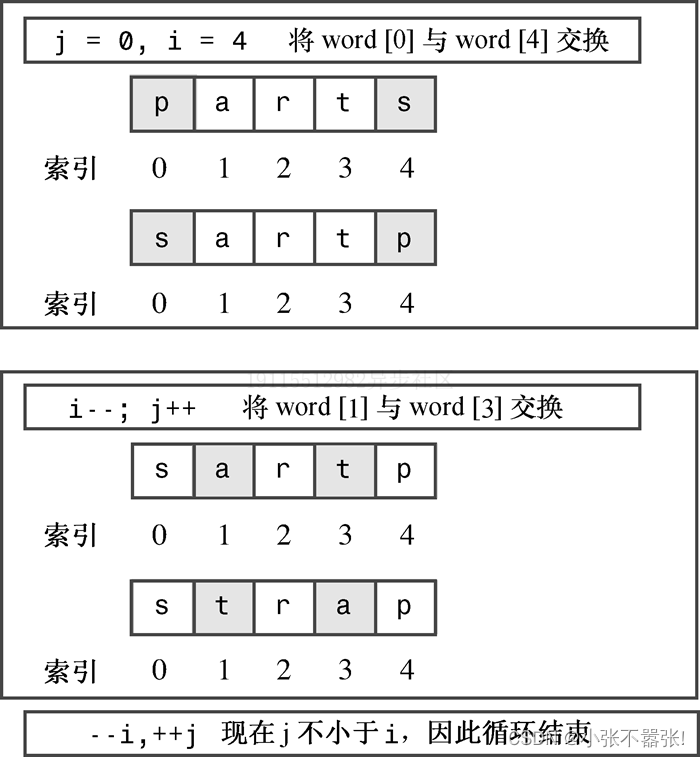
输出:
Enter a word: stressed
desserts
Done
5.1.12 关系表达式
- 关系运算符的概念和用法,它们是一种用于比较两个值的大小或相等性的运算符,可以返回一个布尔值(true或false),作为决策的依据。
- C++提供了6种关系运算符,分别是<, <=, ==, >, >=, !=,它们的含义和用法都是类似的。它们可以用于数字和字符,但不能用于C风格字符串,可以用于string类对象。
- 关系运算符的优先级和结合性,以及如何避免产生歧义或错误。关系运算符的优先级比算术运算符低,从左向右结合。为了避免混淆,可以使用圆括号来明确表达式的计算顺序,或者将复杂的表达式拆分成多条语句。
| 操作符 | 含义 |
|---|---|
| < | 小于 |
| <= | 小于或等于 |
| == | 等于 |
| > | 大于 |
| >= | 大于或等于 |
| != | 不等于 |
5.1.13 赋值(=)、比较和可能犯的错误
- 赋值运算符(=)和等于运算符(==)的区别和用法,它们是一种用于给变量赋值一种用来比较两个值是否相等的运算符,要注意不要混淆或误用。
- 赋值运算符的作用是将右操作数的值赋给左操作数,而等于运算符的作用是判断两个操作数是否相等,返回一个布尔值(true或false)。它们的优先级和结合性也不同,赋值运算符的优先级较低,从右向左结合;等于运算符的优先级较高,从左向右结合。
- 一个常见的错误,就是在for循环的测试条件中错误地使用了赋值运算符(=),而不是等于运算符(==)。这样会导致循环无法正常终止,甚至修改原来的数据,造成严重的后果。为了避免这种错误,要仔细检查代码,或者使用编译器的警告功能。
5.1.14 C-风格字符串的比较
- C风格字符串的比较的方法和注意事项,它们是一种用于判断两个以空字符结尾的字符数组是否相等或按系统排列顺序的函数,返回一个整数值,表示比较的结果。
- 不能用关系运算符来比较C风格字符串,因为它们只会比较字符串的地址,而不是字符串的内容。相反,应使用strcmp()函数来比较,它接受两个字符串地址作为参数,可以是指针、字符串常量或字符数组名。
- strcmp()函数的返回值的含义和用法。如果两个字符串相同,该函数返回0;如果第一个字符串按系统排列顺序在第二个字符串之前,则返回一个负数;如果第一个字符串按系统排列顺序在第二个字符串之后,则返回一个正数。根据返回值,可以用strcmp()函数来实现等于、不等于、小于、大于等关系运算。
// compstr1.cpp -- comparing strings using arrays
#include <iostream>
#include <cstring> // prototype for strcmp()
int main()
{
using namespace std;
char word[5] = "?ate";
for (char ch = ‘a’; strcmp(word, "mate"); ch++)
{
cout << word << endl;
word[0] = ch;
}
cout << "After loop ends, word is " << word << endl;
return 0;
}
输出:
?ate
aate
bate
cate
date
eate
fate
gate
hate
iate
jate
kate
late
After loop ends, word is mate
5.1.15 比较 string 类字符串
- 比较string类字符串的方法和优势,它们是一种用于存储和操作字符串的类,可以使用关系运算符进行比较,而不需要使用strcmp()函数。
- string类重载了关系运算符的功能,让它们可以用于比较两个string对象或一个string对象和一个C风格字符串,返回一个布尔值(true或false)。它们的优先级和结合性与其他关系运算符相同。
- string类的设计让它们可以作为一个实体或一个聚合对象,从而可以使用数组表示法来提取或修改其中的字符,也可以使用其他成员函数来操作字符串。
// compstr2.cpp -- comparing strings using arrays
#include <iostream>
#include <string> // string class
int main()
{
using namespace std;
string word = "?ate";
for (char ch = ‘a’; word != "mate"; ch++)
{
cout << word << endl;
word[0] = ch;
}
cout << "After loop ends, word is " << word << endl;
return 0;
}
输出:
// compstr2.cpp -- comparing strings using arrays
#include <iostream>
#include <string> // string class
int main()
{
using namespace std;
string word = "?ate";
for (char ch = ‘a’; word != "mate"; ch++)
{
cout << word << endl;
word[0] = ch;
}
cout << "After loop ends, word is " << word << endl;
return 0;
}
string类字符串有什么优点和缺点?在什么情况下使用它们比较合适?
我们继续往下走。
string类字符串是否可以用于任何类型的数据?有没有一些特殊的情况或限制?
我们继续往下走。
5.2 while 循环
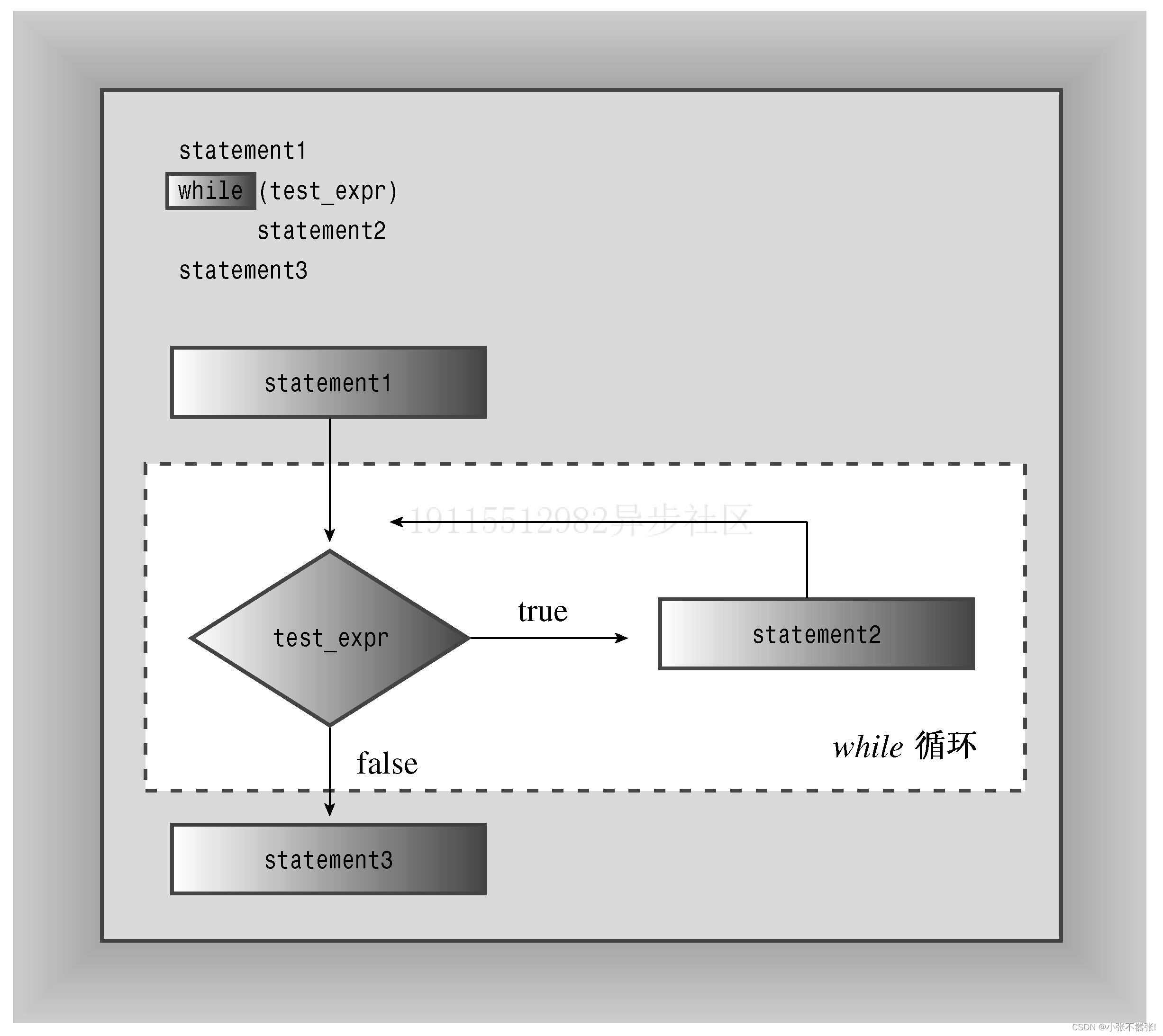
- while循环是一种入口条件循环,它只有一个测试条件和一个循环体。
- while循环的测试条件可以是任何布尔表达式,如果为true,则执行循环体,否则退出循环。
- 循环体中必须有改变测试条件的语句,否则会导致死循环。
- C风格字符串以空值字符(‘\0’)结尾,可以用while循环遍历字符串中的每个字符,直到遇到空值字符为止。
- 要打印字符的ASCII码,需要用强制类型转换将字符转换为整型。
- string对象不使用空值字符标记字符串末尾,需要用其他方法判断字符串的长度。
// while.cpp -- introducing the while loop
#include <iostream>
const int ArSize = 20;
int main()
{
using namespace std;
char name[ArSize];
cout << "Your first name, please: ";
cin >> name;
cout << "Here is your name, verticalized and ASCIIized:\n";
int i = 0; // start at beginning of string
while (name[i] != ‘\0’) // process to end of string
{
cout << name[i] << ": " << int(name[i]) << endl;
i++; // don’t forget this step
}
return 0;
}
下面是该程序的运行情况:
Your first name, please: Muffy
Here is your name, verticalized and ASCIIized:
M: 77
u: 117
f: 102
f: 102
y: 121
分析:
while (name[i] != ‘\0’)
它可以测试数组中特定的字符是不是空值字符。为使该测试最终能够成功,循环体必须修改i的值,这是通过在循环体结尾将i加1来实现的。省略这一步将导致循环停留在同一个数组元素上,打印该字符及其编码,直到强行终止该程序。导致死循环是循环最常见的问题之一。通常,在循环体中忘记更新某个值时,便会出现这种情况。
可以这样修改while行:
while (name[i])
经过这种修改后,程序的工作方式将不变。这是由于name[i]是常规字符,其值为该字符的编码——非零值或true。然而,当name[i]为空值字符时,其编码将为0或false。这种表示法更为简洁(也更常用),但没有程序清单5.13中的表示法清晰。对于后一种情况,“笨拙”的编译器生成的代码的速度将更快,“聪明”的编译器对于这两个版本生成的代码将相同。
5.2.1 for与 while
- for循环和while循环都是重复执行一段代码的结构,它们可以相互转换,但有一些细微的差别。
- for循环通常用于计数循环,它有三个表达式:初始化、测试和更新。while循环通常用于条件循环,它只有一个测试表达式。
- 循环的测试条件可以是任何布尔表达式,如果为true,则执行循环体,否则退出循环。
- 循环体中必须有改变测试条件的语句,否则会导致死循环。
- 循环体可以是一条语句或一个语句块,语句块用花括号括起来。注意不要误用分号或缩进。
我们继续往下走。
5.2.2 等待一段时间:编写延时循环
- 延时循环:使用while循环让程序等待一段时间,可以用于显示消息或控制游戏速度等场景。
long wait = 0;
while (wait < 10000)
wait++; // counting silently
- clock()函数:使用ctime头文件中的clock()函数可以获取程序开始执行后所用的系统时间,返回类型为clock_t,单位为系统时间单位。
// waiting.cpp -- using clock() in a time-delay loop
#include <iostream>
#include <ctime> // describes clock() function, clock_t type
int main()
{
using namespace std;
cout << "Enter the delay time, in seconds: ";
float secs;
cin >> secs;
clock_t delay = secs * CLOCKS_PER_SEC; // convert to clock ticks
cout << "starting\a\n";
clock_t start = clock();
while (clock() - start < delay ) // wait until time elapses
; // note the semicolon
cout << "done \a\n";
return 0;
}
- CLOCKS_PER_SEC:使用ctime头文件中的常量CLOCKS_PER_SEC可以将系统时间单位转换为秒,或者将秒转换为系统时间单位。
- 类型别名:使用#define或typedef关键字可以为已有的类型建立一个新名称,但typedef更灵活更安全,不会创建新类型。
typedef typeName aliasName; - 什么是系统时间单位?
我们继续往下走。
- 为什么要使用clock_t类型而不是int或long类型?
我们继续往下走。
5.3 do while 循环
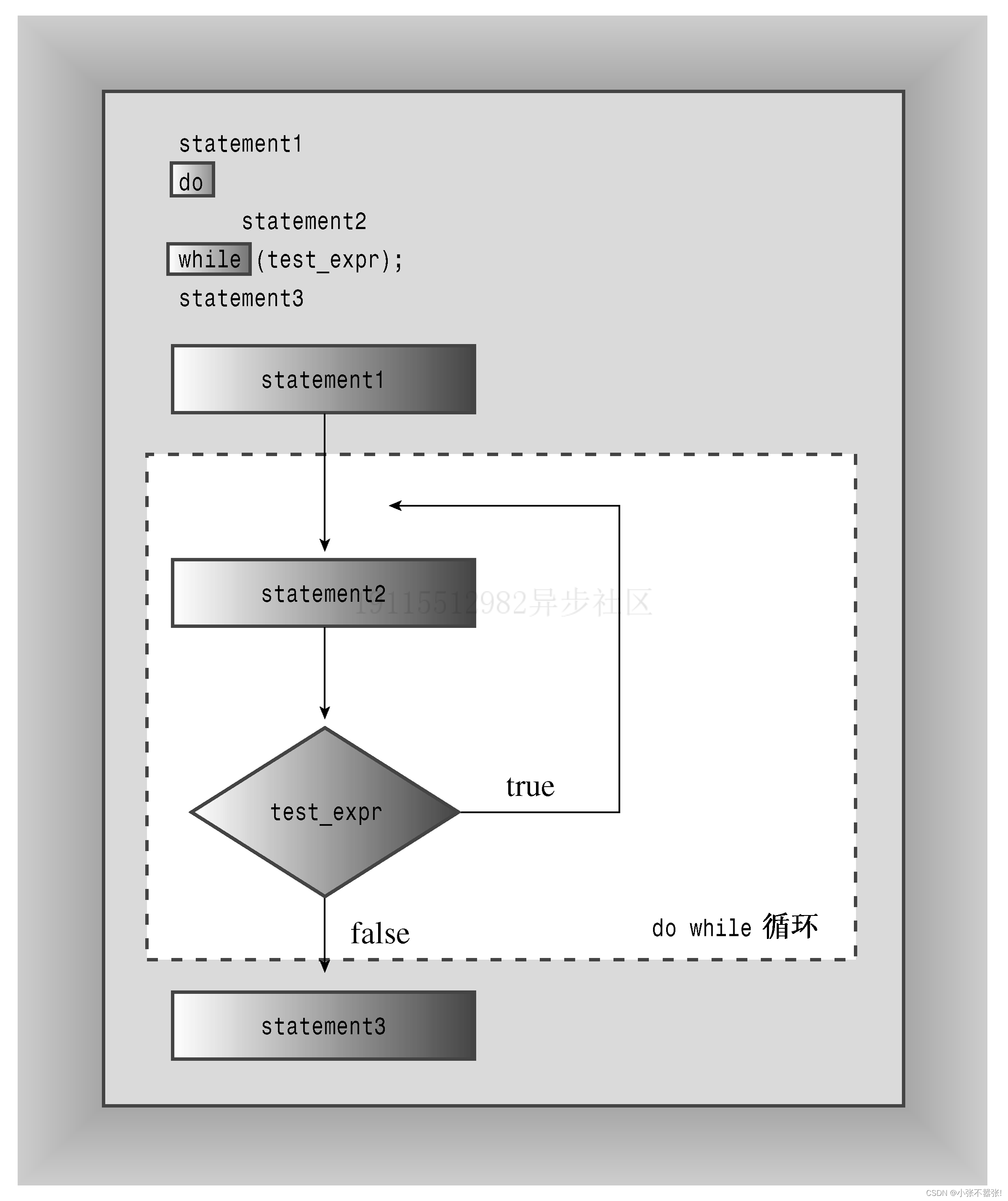
- do while循环:一种出口条件循环,先执行循环体,再判断测试表达式,如果为真则继续循环,否则退出循环。这种循环至少执行一次。
- do while循环的语法:
do { body } while (test-expression); - do while循环的应用场景:当需要先获取用户输入或执行某些操作,然后再检查条件是否满足时,可以使用do while循环。例如,程序清单5.15中,要求用户输入一个数字,然后判断是否等于7。
- 奇特的for循环:有时会看到for(;;)这样的无限循环,它利用了for循环中空测试条件被视为真的特性。但这种写法不易于阅读和理解,通常使用while或do while循环更清晰。
5.4 基于范围的for循环 (C++11)
- 基于范围的for循环:一种C++11新增的循环,可以简化对数组或容器类的每个元素执行相同操作的任务。它的语法是:
for (loop variable : range) { body } - 基于范围的for循环的循环变量:可以是值类型或引用类型,如果是值类型,则循环变量是数组或容器类元素的副本,不能修改原始元素;如果是引用类型,则循环变量是数组或容器类元素的别名,可以修改原始元素。
- 基于范围的for循环的范围:可以是数组或容器类对象,也可以是初始化列表,如{3, 5, 2, 8, 6}。
double prices[5] = {4.99, 10.99, 6.87, 7.99, 8.49};
for (double x : prices)
cout << x << std::endl;
5.5 循环和文本输入
知道循环的工作原理后,来看一看循环完成的一项最常见、最重要的任务:逐字符地读取来自文件或键盘的文本。例如,读者可能想编写一个能够计算输入中的字符数、行数和字数的程序。传统上,C++和C语言一样,也使用while循环来完成这类任务。下面介绍这是如何完成的。即使熟悉C语言,也不要太快地浏览本节和下一节。尽管C++中的while循环与C语言中的while循环一样,但C++的I/O工具不同,这使得C++循环看起来与C语言循环有些不同。事实上,cin对象支持3种不同模式的单字符输入,其用户接口各不相同。下面介绍如何在while循环中使用这三种模式。
5.5.1 使用原始的 cin进行输入
// textin1.cpp -- reading chars with a while loop
#include <iostream>
int main()
{
using namespace std;
char ch;
int count = 0; // use basic input
cout << "Enter characters; enter # to quit:\n";
cin >> ch; // get a character
while (ch != ‘#’) // test the character
{
cout << ch; // echo the character
++count; // count the character
cin >> ch; // get the next character
}
cout << endl << count << " characters read\n";
return 0;
}
下面是该程序的运行情况:
see ken run#really fast
seekenrun
9 characters read
- 程序清单:这是一个使用while循环读取键盘输入的字符的程序,它在遇到#字符时停止读取,并回显和计数输入的字符。为什么使用#作为停止标记?是否可以使用其他字符?
我们继续往下走。
- cin的特点:cin在读取char值时会忽略空格和换行符,因此输入中的空格不会被显示或计数。另外,cin的输入是缓冲的,只有在用户按下回车键后才会发送给程序。
- 循环的设计:该程序在循环之前读取第一个字符,以便测试第一个字符是否是#。如果不是,则进入循环,显示字符,增加计数,然后读取下一个字符。这样可以保证循环能够正确地结束。
5.5.2 使用 cin.get (char)进行补救
// textin2.cpp -- using cin.get(char)
#include <iostream>
int main()
{
using namespace std;
char ch;
int count = 0;
cout << "Enter characters; enter # to quit:\n";
cin.get(ch); // use the cin.get(ch) function
while (ch != ‘#’)
{
cout << ch;
++count;
cin.get(ch); // use it again
}
cout << endl << count << " characters read\n";
return 0;
}
下面是该程序的运行情况:
Enter characters; enter # to quit:
Did you use a #2 pencil?
Did you use a
14 characters read
- 程序清单:这是一个使用cin.get(char)函数来读取键盘输入的字符的程序,它在遇到#字符时停止读取,并回显和计数输入的字符,包括空格和换行符。
- cin.get(char)的特点:cin.get(char)函数不会忽略空格和换行符,因此可以处理所有的输入字符。它也是一个缓冲的输入,只有在用户按下回车键后才会发送给程序。
- 引用类型:cin.get(char)函数的参数是一个引用类型,这是C++新增的一种类型,它可以让函数修改其参数的值,而不需要传递参数的地址。这与C语言中的函数调用方式不同。
5.5.3 使用哪一个 cin.get()
- cin.get()的重载:cin.get()有多个版本,根据参数的类型和个数,可以读取不同的字符。例如,cin.get(name, ArSize)可以读取一个字符串,cin.get(ch)可以读取一个字符,cin.get()可以读取下一个输入字符。
- 基本输入和无缓冲输入:程序使用了基本输入,因此cin会忽略空格和换行符。这也导致了输入被缓冲,只有在用户按下回车键后,输入才会被发送给程序。如果想要实现无缓冲输入,可以使用ncurses库或者其他类似的库来控制控制台界面。
5.5.4 文件尾条件
- 文件尾条件:程序可以通过检测文件尾(EOF)来结束从文件或键盘的输入循环。不同的操作系统和编程环境有不同的方法来模拟EOF,如Ctrl+Z或Ctrl+D。
- cin对象的状态:当检测到EOF后,cin对象会设置两个位(eofbit和failbit)来表示输入失败。可以使用cin.eof()或cin.fail()方法来检查这些位的状态,如果为true,则表示输入已经结束。
- 函数重载:cin.get()有多个版本,根据参数的类型和个数,可以读取不同的字符。这是一种OOP特性,称为函数重载,允许创建多个同名函数,只要它们的参数列表不同。
- 常见的字符输入做法:可以使用while循环和cin.get()来读取每个字符,直到遇到EOF。可以使用!运算符、bool转换或返回值来简化循环的测试条件。
5.5.5 另一个 cin.get() 版本
- 另一个cin.get()版本:不接受任何参数的cin.get()成员函数可以返回输入中的下一个字符,类似于C语言中的getchar()函数。该函数在到达EOF时,会返回一个特殊值EOF,因此需要将返回值赋给int变量,而不是char变量。
- cout.put()函数:可以使用cout.put()函数来显示字符,类似于C语言中的putchar()函数。该函数的参数类型为char,而不是int。
| 属性 | cin.get(ch)的描述 | ch=cin.get()的描述 |
|---|---|---|
| 传递输入字符的方式 | 赋给参数ch | 将函数返回值赋给ch |
| 用于字符输入时的返回值 | istream对象(执行bool转换后为true) | int类型的字符编码 |
| 到达EOF时函数的返回值 | istream对象(执行bool转换后为false) | EOF(End of File) |
5.6 嵌套循环和二维数组
- 二维数组:二维数组是由数组组成的数组,可以看作是一个表格,有行和列。例如,可以用二维数组来表示不同城市的最高温度或者游戏角色的位置。
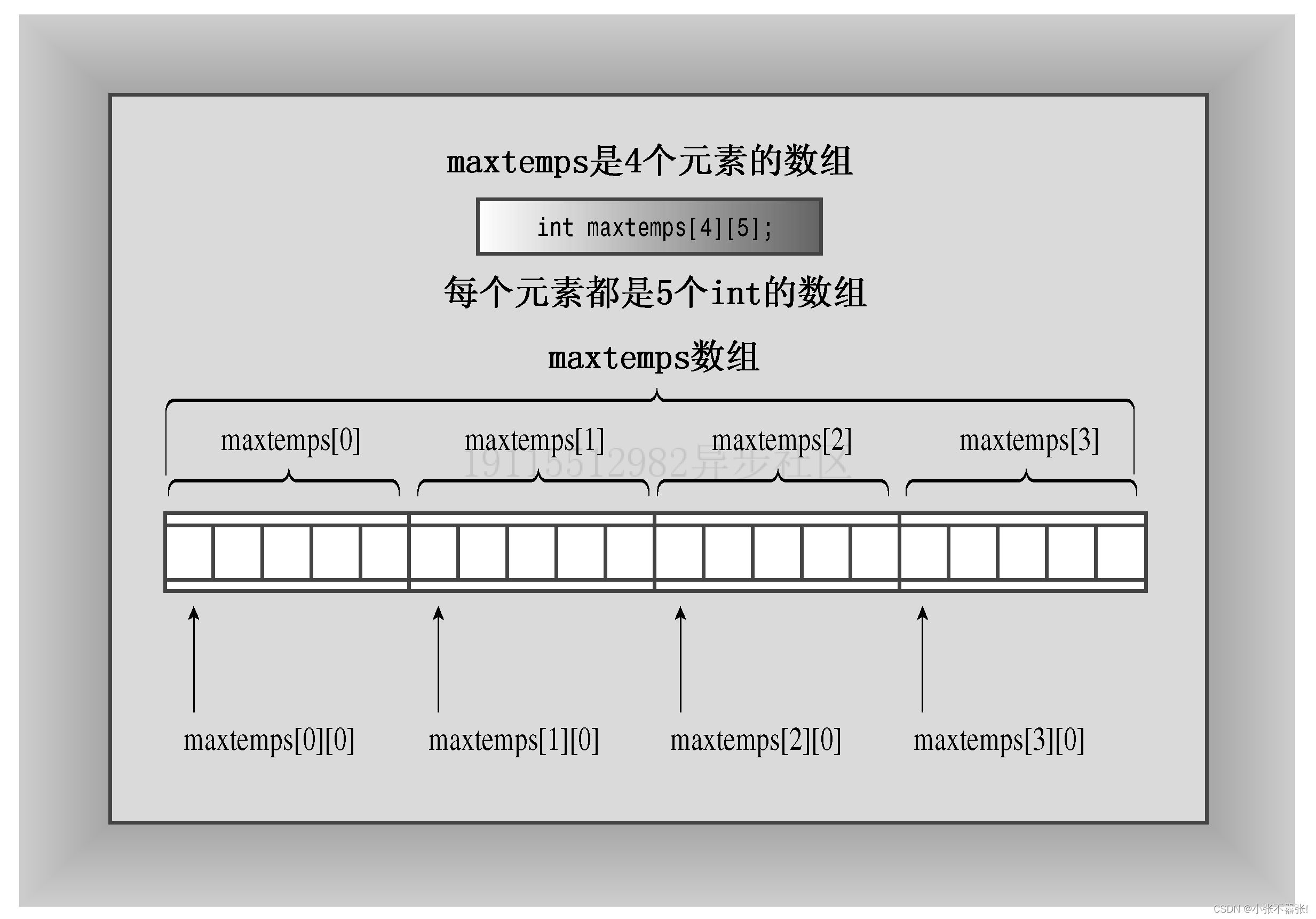
- 二维数组的声明:二维数组的声明格式为
type name[rows][cols],其中type是元素的数据类型,name是数组的名称,rows和cols是行数和列数。例如,int maxtemps[4][5]声明了一个由4个元素组成的数组,每个元素都是一个由5个整数组成的数组。 - 二维数组的访问:二维数组的访问格式为
name[row][col],其中row和col是下标,表示行号和列号。例如,maxtemps[0][0]表示第一行第一列的元素。可以使用嵌套for循环来遍历二维数组的所有元素。

5.6.1 初始化二维数组
- 初始化二维数组:初始化二维数组是在创建二维数组时,为其所有元素赋予初始值的过程。
- 初始化二维数组的方法:初始化二维数组的方法是使用花括号括起的值列表,其中每一行的值也用花括号括起,并用逗号分隔。例如,
int maxtemps[4][5] = // 2-D array
{
{96, 100, 87, 101, 105}, // values for maxtemps[0]
{96, 98, 91, 107, 104}, // values for maxtemps[1]
{97, 101, 93, 108, 107}, // values for maxtemps[2]
{98, 103, 95, 109, 108} // values for maxtemps[3]
};
初始化了一个4行5列的二维数组。
- 初始化二维数组的好处:初始化二维数组的好处是可以省去逐个赋值的步骤,提高代码的效率和可读性。初始化二维数组时,是否可以只给部分元素赋值?如果可以,剩余的元素会被赋什么值?
我们继续往下走。
5.6.2 使用二维数组
// nested.cpp -- nested loops and 2-D array
#include <iostream>
const int Cities = 5;
const int Years = 4;
int main()
{
using namespace std;
const char * cities[Cities] = // array of pointers
{ // to 5 strings
"Gribble City",
"Gribbletown",
"New Gribble",
"San Gribble",
"Gribble Vista"
};
int maxtemps[Years][Cities] = // 2-D array
{
{96, 100, 87, 101, 105}, // values for maxtemps[0]
{96, 98, 91, 107, 104}, // values for maxtemps[1]
{97, 101, 93, 108, 107}, // values for maxtemps[2]
{98, 103, 95, 109, 108} // values for maxtemps[3]
};
cout << "Maximum temperatures for 2008 - 2011\n\n";
for (int city = 0; city < Cities; ++city)
{
cout << cities[city] << ":\t";
for (int year = 0; year < Years; ++year)
cout << maxtemps[year][city] << "\t";
cout << endl;
}
// cin.get();
return 0;
}
下面是该程序的输出:
Maximum temperatures for 2008 - 2011
Gribble City: 96 96 97 98
Gribbletown: 100 98 101 103
New Gribble: 87 91 93 95
San Gribble: 101 107 108 109
Gribble Vista: 105 104 107 108
- 使用二维数组:使用二维数组是一种处理表格数据的方法,可以用两个下标来访问每个元素,表示行和列。
- 使用嵌套循环:使用嵌套循环是一种遍历二维数组的方法,可以用一个外层循环来控制行,一个内层循环来控制列,或者反过来。
- 使用字符串指针数组:使用字符串指针数组是一种存储字符串的方法,可以用一个指针数组来保存每个字符串的地址,而不是用一个二维字符数组来复制每个字符串。如何使用动态内存分配来创建二维数组?它们有什么优势和缺陷?
我们继续往下走。
小思考🤔️
为什么要在for语句中声明变量?
答:
一种原因是为了避免变量名的冲突,如果在for语句外部已经有一个同名的变量,那么在for语句中声明一个新的变量可以避免混淆。另一种原因是为了节省内存空间,如果在for语句中声明一个变量,那么它只会在循环期间存在,当循环结束后,它就会被销毁,从而释放内存空间。
如何在for语句中声明多个变量?
答:
一种方法是使用逗号分隔多个声明,例如:
// 在for语句中声明两个整数变量
for (int i = 0, j = 10; i < j; i++, j--)
{
// do something with i and j
}
另一种方法是使用花括号括起多个声明,例如:
// 在for语句中声明一个整数变量和一个字符串变量
for (int i = 0; i < 5; i++)
{
string s = "Hello";
// do something with i and s
}
string类字符串有什么优点和缺点?在什么情况下使用它们比较合适?
答:
string类字符串的优点是可以实现对字符串的简单和直观的操作,如比较、赋值、拼接、查找、替换等,而不需要考虑空字符、内存分配、数组长度等问题。缺点是可能会占用更多的内存空间,或者与一些只接受C风格字符串的函数不兼容。在需要对字符串进行频繁或复杂的操作的情况下,使用string类字符串比较合适。
string类字符串是否可以用于任何类型的数据?有没有一些特殊的情况或限制?
答:
string类字符串可以用于存储和操作任何类型的字符数据,如字母、数字、标点符号、空格等。但是不能用于存储二进制数据,如图片、音频、视频等。也不能将不同类型的数据进行拼接或比较,如整数、浮点数、字符、string类对象等。
如何选择合适的循环结构?
答:
选择合适的循环结构取决于循环的目的和逻辑。一般来说,如果循环的次数是固定的或可以预先计算的,那么使用for循环比较方便;如果循环的次数是不确定的或取决于某些外部条件,那么使用while循环比较灵活。
什么是系统时间单位?
答:
系统时间单位是指clock()函数返回值的最小单位,它可能与秒不同,具体取决于操作系统和硬件平台。例如,在Windows上,系统时间单位是毫秒(千分之一秒),而在Linux上,系统时间单位是微秒(百万分之一秒)。
为什么要使用clock_t类型而不是int或long类型?
答:
使用clock_t类型可以保证与clock()函数的返回类型一致,避免了可能的溢出或截断错误。因为clock_t类型是根据不同的系统自动定义的,它可以适应不同的系统时间单位和范围。例如,在某些系统上,clock_t可能是unsigned long类型,在其他系统上可能是long long类型。
为什么使用#作为停止标记?是否可以使用其他字符?
答:
使用#作为停止标记是因为它不常用于正常的文本输入,因此可以避免与用户想要输入的内容冲突。也可以使用其他不常用的字符,如$或@等。
初始化二维数组时,是否可以只给部分元素赋值?如果可以,剩余的元素会被赋什么值?
答:
初始化二维数组时,可以只给部分元素赋值,剩余的元素会被赋为0。例如,
int maxtemps[4][5] = {{96}, {98}};会将maxtemps[0][0]赋为96,maxtemps[1][0]赋为98,其他元素都赋为0。
如何使用动态内存分配来创建二维数组?它们有什么优势和缺陷?
答:
使用动态内存分配来创建二维数组的方法是:
- 首先,创建一个指向指针的指针变量,例如
int** arry;,这个变量将指向一个指针数组,每个指针都将指向一个一维数组。- 然后,使用new运算符为指针数组分配内存,指定其大小为行数,例如
arry = new int*[row];,这样就创建了一个由row个指针组成的数组。- 接着,使用循环为每个指针分配内存,指定其大小为列数,例如
for (int i = 0; i < row; i++) arry[i] = new int[col];,这样就为每个指针创建了一个由col个整数组成的数组。- 最后,使用双重下标来访问和操作二维数组的元素,例如
arry[i][j] = 10;或者cout << arry[i][j] << " ";。使用动态内存分配来创建二维数组的优势有:
- 可以根据需要动态地改变数组的大小,而不是在编译时就固定。
- 可以节省内存空间,因为只分配实际需要的空间,而不是预先分配最大可能的空间。
- 可以避免内存碎片化的问题,因为可以释放不再需要的空间。
使用动态内存分配来创建二维数组的缺陷有:
- 需要手动管理内存的分配和释放,否则可能造成内存泄漏或者访问无效的内存地址。
- 需要多次调用new和delete运算符,这会增加程序的运行时间和复杂度。
- 不能直接将动态分配的二维数组作为函数参数传递,需要额外地传递行数和列数。















 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









