1. Dataloader使用
- Dataset只是去告诉我们程序,我们的数据集在什么位置,数据集第一个数据给它一个索引0,它对应的是哪一个数据。
- Dataloader就是把数据加载到神经网络当中,Dataloader所做的事就是每次从Dataset中取数据,至于怎么取,是由Dataloader中的参数决定的。
import torchvision
from torch.utils.data import DataLoader
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
img, target = test_data[0]
print(img.shape)
print(img)
# batch_size=4 使得 img0, target0 = dataset[0]、img1, target1 = dataset[1]、img2, target2 = dataset[2]、img3, target3 = dataset[3],然后这四个数据作为Dataloader的一个返回
test_loader = DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
# 用for循环取出DataLoader打包好的四个数据
for data in test_loader:
imgs, targets = data # 每个data都是由4张图片组成,imgs.size 为 [4,3,32,32],四张32×32图片三通道,targets由四个标签组成
print(imgs.shape)
print(targets)
2. Tensorboard展示
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# batch_size=4 使得 img0, target0 = dataset[0]、img1, target1 = dataset[1]、img2, target2 = dataset[2]、img3, target3 = dataset[3],然后这四个数据作为Dataloader的一个返回
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
# 用for循环取出DataLoader打包好的四个数据
writer = SummaryWriter("logs")
step = 0
for data in test_loader:
imgs, targets = data # 每个data都是由4张图片组成,imgs.size 为 [4,3,32,32],四张32×32图片三通道,targets由四个标签组成
writer.add_images("test_data",imgs,step)
step = step + 1
writer.close()
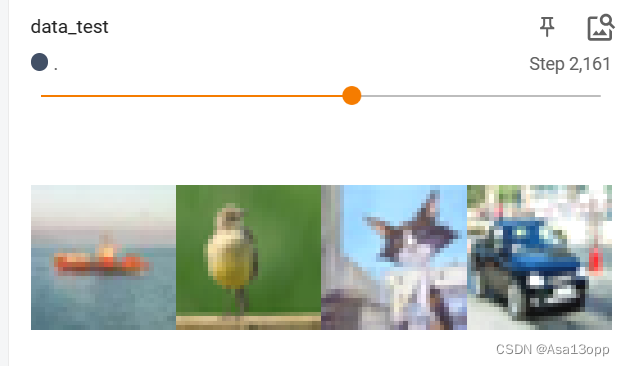
3. Dataloader多轮次
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# batch_size=4 使得 img0, target0 = dataset[0]、img1, target1 = dataset[1]、img2, target2 = dataset[2]、img3, target3 = dataset[3],然后这四个数据作为Dataloader的一个返回
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=True)
# 用for循环取出DataLoader打包好的四个数据
writer = SummaryWriter("logs")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data # 每个data都是由4张图片组成,imgs.size 为 [4,3,32,32],四张32×32图片三通道,targets由四个标签组成
writer.add_images("Epoch:{}".format(epoch),imgs,step)
step = step + 1
writer.close()























 2696
2696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









