







1. 池化层原理
- 最大池化层有时也被称为下采样。
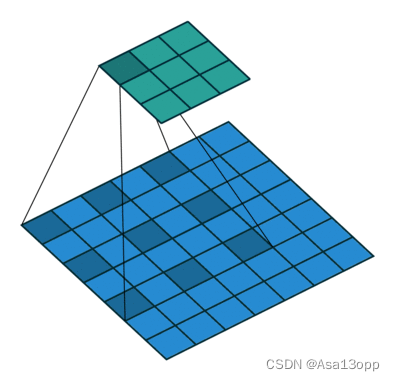
- dilation为空洞卷积,如下图所示。
- Ceil_model为当超出区域时,只取最左上角的值。
- 池化使得数据由5 * 5 变为3 * 3,甚至1 * 1的,这样导致计算的参数会大大减小。例如1080P的电影经过池化的转为720P的电影、或360P的电影后,同样的网速下,视频更为不卡。
2.torch.nn.MaxPool2d
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1,
return_indices=False, ceil_mode=False)
kernel_size (Union[int, Tuple[int, int]]) – the size of the window to take a max over
stride (Union[int, Tuple[int, int]]) – the stride of the window. Default value is
kernel_sizepadding (Union[int, Tuple[int, int]]) – Implicit negative infinity padding to be added on both sides
dilation (Union[int, Tuple[int, int]]) – a parameter that controls the stride of elements in the window
return_indices (bool) – if
True, will return the max indices along with the outputs. Useful for torch.nn.MaxUnpool2d laterceil_mode (bool) – when True, will use ceil instead of floor to compute the output shape
当 ceil_mode=True 时,如果滑动窗口在左填充内边距内启动,则允许它们越界或输入。将在右侧填充区域开始的滑动窗口将被忽略。

3. 池化层处理图片
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool(input)
return output
tudui = Tudui()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = tudui(imgs)
writer.add_images("output", output, step)
step = step + 1
















 1324
1324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









