







1. KMP 算法介绍
KMP 算法:全称叫做 「Knuth Morris Pratt 算法」,是由它的三位发明者 Donald Knuth、James H. Morris、 Vaughan Pratt 的名字来命名的。KMP 算法是他们三人在 1977 年联合发表的。
- KMP 算法思想:对于给定文本串
T与模式串p,当发现文本串T的某个字符与模式串p不匹配的时候,可以利用匹配失败后的信息,尽量减少模式串与文本串的匹配次数,避免文本串位置的回退,以达到快速匹配的目的。
1.1 朴素匹配算法的缺陷
在朴素匹配算法的匹配过程中,我们分别用指针 i 和指针 j 指示文本串 T 和模式串 p 中当前正在对比的字符。当发现文本串 T 的某个字符与模式串 p 不匹配的时候,j 回退到开始位置,i 回退到之前匹配开始位置的下一个位置上,然后开启新一轮的匹配,如图所示。
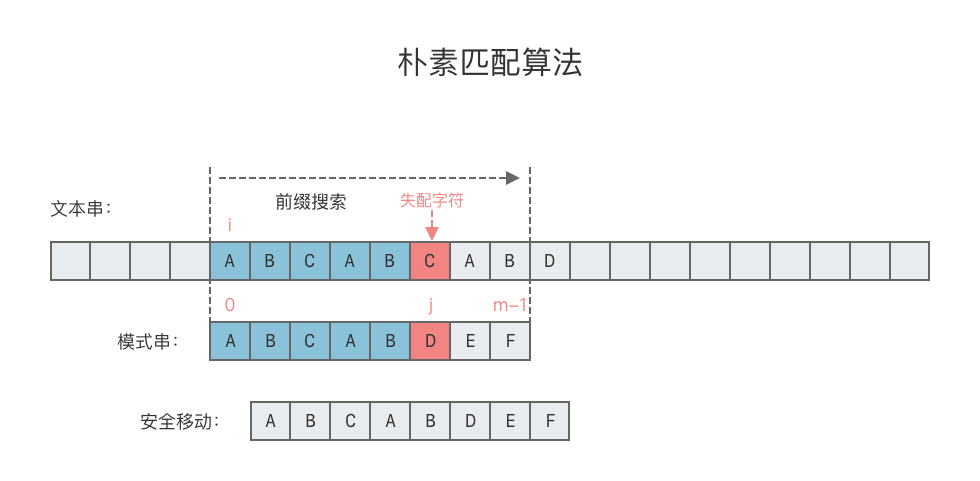
这样,在 Brute Force 算法中,如果从文本串 T[i] 开始的这一趟字符串比较失败了,算法会直接开始尝试从 T[i + 1] 开始比较。如果 i 已经比较到了后边位置,则该操作相当于将指针 i 进行了回退操作。
那么有没有哪种算法,可以让 i 不发生回退,一直向右移动呢?
1.2 KMP 算法的改进
如果我们可以通过每一次的失配而得到一些「信息」,并且这些「信息」可以帮助我们跳过那些不可能匹配成功的位置,那么我们就能大大减少模式串与文本串的匹配次数,从而达到快速匹配的目的。
每一次失配所告诉我们的信息是:主串的某一个子串等于模式串的某一个前缀。
这个信息的意思是:如果文本串 T[i: i + m] 与模式串 p 的失配是下标位置 j 上发生的,那么文本串 T 从下标位置 i 开始连续的 j - 1 个字符,一定与模式串 p 的前 j - 1 个字符一模一样,即:T[i: i + j] == p[0: j]。
但是知道这个信息有什么用呢?
以刚才图中的例子来说,文本串的子串 T[i: i + m] 与模式串 p 的失配是在第 5 个位置发生的,那么:
- 文本串
T从下标位置i开始连续的5个字符,一定与模式串p的前5个字符一模一样,即:"ABCAB" == "ABCAB"。 - 而模式串的前
5个字符中,前2位前缀和后2位后缀又是相同的,即"AB" == "AB"。
所以根据上面的信息,我们可以推出:文本串子串的后 2 位后缀和模式串子串的前 2 位是相同的,即 T[i + 3: i + 5] == p[0: 2],而这部分(即下图中的蓝色部分)是之前已经比较过的,不需要再比较了,可以直接跳过。
那么我们就可以将文本串中的 T[i + 5] 对准模式串中的 p[2],继续进行对比。这样 i 就不再需要回退了,可以一直向右移动匹配下去。在这个过程中,我们只需要将模式串 j 进行回退操作即可。

KMP 算法就是使用了这样的思路,对模式串 p 进行了预处理,计算出一个 「部分匹配表」,用一个数组 next 来记录。然后在每次失配发生时,不回退文本串的指针 i,而是根据「部分匹配表」中模式串失配位置 j 的前一个位置的值,即 next[j - 1] 的值来决定模式串可以向右移动的位数。
比如上述示例中模式串 p 是在 j = 5 的位置上发生失配的,则说明文本串的子串 T[i: i + 5] 和模式串 p[0: 5] 的字符是一致的,即 "ABCAB" == "ABCAB"。而根据「部分匹配表」中 next[4] == 2,所以不用回退 i,而是将 j 移动到下标为 2 的位置,让 T[i + 5] 直接对准 p[2],然后继续进行比对。
1.3 next 数组
上文提到的「部分匹配表」,也叫做「前缀表」,在 KMP 算法中使用 next 数组存储。next[j] 表示的含义是:记录下标 j 之前(包括 j)的模式串 p 中,最长相等前后缀的长度。
简单而言,就是求:模式串 p 的子串 p[0: j + 1] 中,使得「前 k 个字符」恰好等于「后 k 个字符」的「最长的 k」。当然子串 p[0: j + 1] 本身不参与比较。
举个例子来说明一下,以 p = "ABCABCD" 为例。
next[0] = 0,因为"A"中无有相同前缀后缀,最大长度为0。next[1] = 0,因为"AB"中无相同前缀后缀,最大长度为0。next[2] = 0,因为"ABC"中无相同前缀后缀,最大长度为0。next[3] = 1,因为"ABCA"中有相同的前缀后缀"a",最大长度为1。next[4] = 2,因为"ABCAB"中有相同的前缀后缀"AB",最大长度为2。next[5] = 3,因为"ABCABC"中有相同的前缀后缀"ABC",最大长度为3。next[6] = 0,因为"ABCABCD"中无相同前缀后缀,最大长度为0。
同理也可以计算出 "ABCABDEF" 的前缀表为 [0, 0, 0, 1, 2, 0, 0, 0]。"AABAAAB" 的前缀表为 [0, 1, 0, 1, 2, 2, 3]。"ABCDABD" 的前缀表为 [0, 0, 0, 0, 1, 2, 0]。
在之前的例子中,当 p[5] 和 T[i + 5] 匹配失败后,根据模式串失配位置 j 的前一个位置的值,即 next[4] = 2,我们直接让 T[i + 5] 直接对准了 p[2],然后继续进行比对,如下图所示。
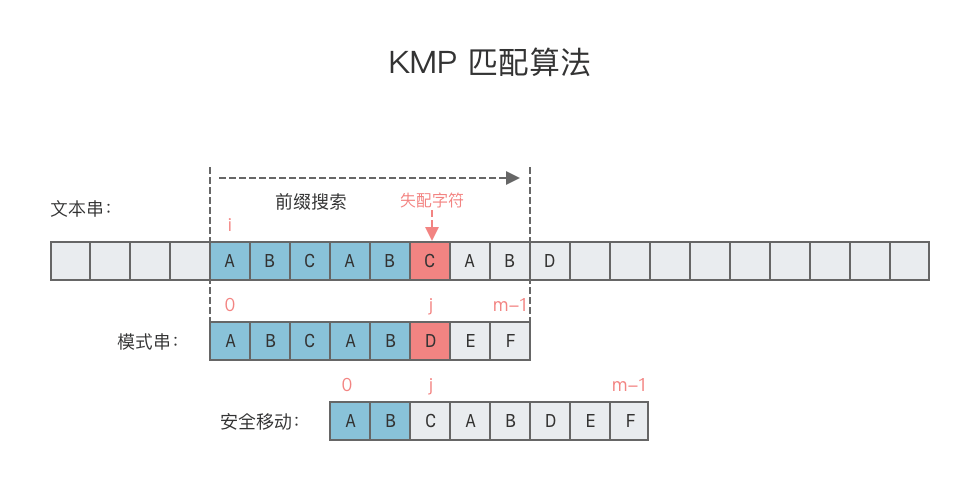
但是这样移动的原理是什么?
其实在上文 「1.2 KMP 算法的改进」 中的例子中我们提到过了。现在我们将其延伸总结一下,其实这个过程就是利用了前缀表进行模式串移动的原理,具体推论如下。
如果文本串 T[i: i + m] 与模式串 p 的失配是在第 j 个下标位置发生的,那么:
- 文本串
T从下标位置i开始连续的j个字符,一定与模式串p的前j个字符一模一样,即:T[i: i + j] == p[0: j]。 - 而如果模式串
p的前j个字符中,前k位前缀和后k位后缀相同,即p[0: k] == p[j - k: j],并且要保证k要尽可能长。
可以推出:文本串子串的后 k 位后缀和模式串子串的前 k 位是相同的,即 T[i + m - k: i + m] == p[0: k](这部分是已经比较过的),不需要再比较了,可以直接跳过。
那么我们就可以将文本串中的 T[i + m] 对准模式串中的 p[k],继续进行对比。这里的 k 其实就是 next[j - 1]。
2. KMP 算法步骤
3.1 next 数组的构造
我们可以通过递推的方式构造 next 数组。
- 我们把模式串
p拆分成left、right两部分。left表示前缀串开始所在的下标位置,right表示后缀串开始所在的下标位置,起始时left = 0,right = 1。 - 比较一下前缀串和后缀串是否相等。通过比较
p[left]和p[right]来进行判断。 - 如果
p[left] != p[right],说明当前的前后缀不相同。则让后缀开始位置k不动,前缀串开始位置left不断回退到next[left - 1]位置,直到p[left] == p[right]为止。 - 如果
p[left] == p[right],说明当前的前后缀相同,则可以先让left += 1,此时left既是前缀下一次进行比较的下标位置,又是当前最长前后缀的长度。 - 记录下标
right之前的模式串p中,最长相等前后缀的长度为left,即next[right] = left。
3.2 KMP 算法整体步骤
- 根据
next数组的构造步骤生成「前缀表」next。 - 使用两个指针
i、j,其中i指向文本串中当前匹配的位置,j指向模式串中当前匹配的位置。初始时,i = 0,j = 0。 - 循环判断模式串前缀是否匹配成功,如果模式串前缀匹配不成功,将模式串进行回退,即
j = next[j - 1],直到j == 0时或前缀匹配成功时停止回退。 - 如果当前模式串前缀匹配成功,则令模式串向右移动
1位,即j += 1。 - 如果当前模式串 完全 匹配成功,则返回模式串
p在文本串T中的开始位置,即i - j + 1。 - 如果还未完全匹配成功,则令文本串向右移动
1位,即i += 1,然后继续匹配。 - 如果直到文本串遍历完也未完全匹配成功,则说明匹配失败,返回
-1。
3. KMP 算法代码实现
# 生成 next 数组
# next[j] 表示下标 j 之前的模式串 p 中,最长相等前后缀的长度
def generateNext(p: str):
m = len(p)
next = [0 for _ in range(m)] # 初始化数组元素全部为 0
left = 0 # left 表示前缀串开始所在的下标位置
for right in range(1, m): # right 表示后缀串开始所在的下标位置
while left > 0 and p[left] != p[right]: # 匹配不成功, left 进行回退, left == 0 时停止回退
left = next[left - 1] # left 进行回退操作
if p[left] == p[right]: # 匹配成功,找到相同的前后缀,先让 left += 1,此时 left 为前缀长度
left += 1
next[right] = left # 记录前缀长度,更新 next[right], 结束本次循环, right += 1
return next
# KMP 匹配算法,T 为文本串,p 为模式串
def kmp(T: str, p: str) -> int:
n, m = len(T), len(p)
next = generateNext(p) # 生成 next 数组
j = 0 # j 为模式串中当前匹配的位置
for i in range(n): # i 为文本串中当前匹配的位置
while j > 0 and T[i] != p[j]: # 如果模式串前缀匹配不成功, 将模式串进行回退, j == 0 时停止回退
j = next[j - 1]
if T[i] == p[j]: # 当前模式串前缀匹配成功,令 j += 1,继续匹配
j += 1
if j == m: # 当前模式串完全匹配成功,返回匹配开始位置
return i - j + 1
return -1 # 匹配失败,返回 -1
print(kmp("abbcfdddbddcaddebc", "ABCABCD"))
print(kmp("abbcfdddbddcaddebc", "bcf"))
print(kmp("aaaaa", "bba"))
print(kmp("mississippi", "issi"))
print(kmp("ababbbbaaabbbaaa", "bbbb"))
4. KMP 算法分析
- KMP 算法在构造前缀表阶段的时间复杂度为
O
(
m
)
O(m)
O(m),其中
m
m
m 是模式串
p的长度。 - KMP 算法在匹配阶段,是根据前缀表不断调整匹配的位置,文本串的下标
i并没有进行回退,可以看出匹配阶段的时间复杂度是 O ( n ) O(n) O(n),其中 n n n 是文本串T的长度。 - 所以 KMP 整个算法的时间复杂度是 O ( n + m ) O(n + m) O(n+m),相对于朴素匹配算法的 O ( n ∗ m ) O(n * m) O(n∗m) 的时间复杂度,KMP 算法的效率有了很大的提升。














 853
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









