







本文为综合多方面资料,后个人总结,用于学习使用;如有不准确、待补充等各种问题,恳请大家一起学习探讨,后将持续进行更新完善。
什么是 LoRA
介绍:固定大模型,增加低秩分解的矩阵来适配下游任务,从而以极小的参数量来实现大模型的间接训练。
LoRA 是受 Instrisic Dimension 内在维度 的启发。Instrisic Dimension 内在维度 是指LLM表现出很好的 few-shot 能力("Few-shot" 是机器学习中的一个术语,指的是在训练过程中,模型仅通过少量的样本数据进行学习。换句话说,few-shot学习是指模型在只接收到非常少的训练样本(通常是几条样本)时,仍然能够很好地进行推理和预测。)利用数千条样本就可以微调一个数十亿参数的LLM,其内在原意是预训练模型拥有极小的内在维度(Instrisic Dimension),即存在一个极低维度的参数,微调它和在全参数空间中微调能起到相同的作用。根据这个启发,LoRA 认为参数更新过程中也存在一个内在秩,对于预训练权重矩阵可以用一个低秩分解来表示参数更新。
LoRA 的实现思路是什么
LoRA 的实现思路为在原模型旁边增加一个旁路,通过低秩分解(先降维再升维)来模拟参数的更新量。训练的时候,原模型固定,只训练降维矩阵 A 和升维矩阵 B ;推理时,可将 BA 加到原参数上,不引入额外的推理延迟;初始化时,A 采用高斯分布初始化,B 初始化为全 0,保证训练开始时旁路为 0 矩阵。LoRA 可插拔式的切换任务,当前任务为 W0+B1A1 ,将 LoRA 部分减掉,换成 B2A2 ,即可实现任务转换。
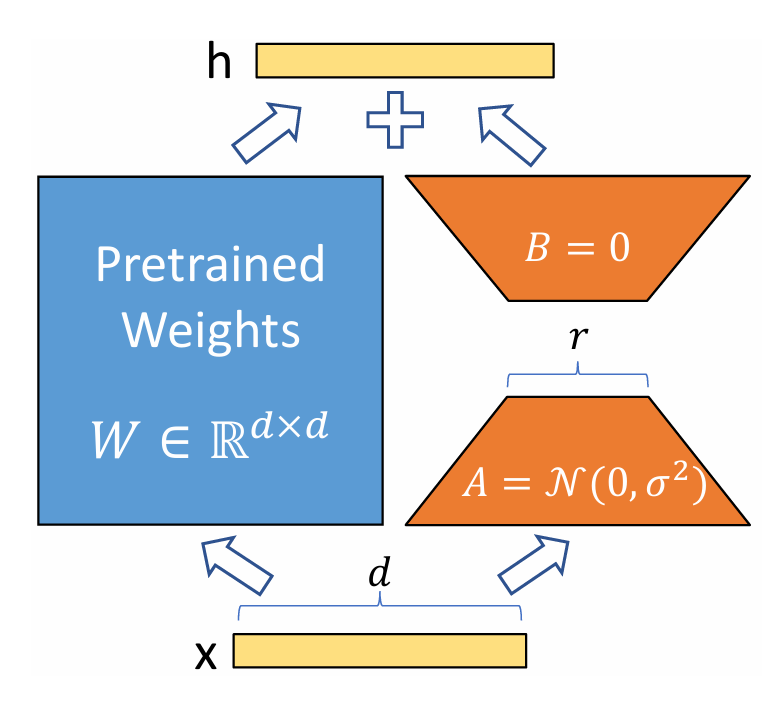
简单来讲,LoRA 的实现就是冻结一个预训练模型的矩阵参数,并选择用 A 和 B 矩阵来替代,在下游任务的时候只需要更新 A 和 B 即可。将训练好的低秩矩阵 BA 与原模型权重 W 合并(相加),即可计算得到新权重。
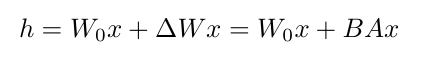
那么对于 LoRA 矩阵初始化的时候为什么要对下采样矩阵 A 随机高斯初始化, 上采样矩阵 B 进行全 0 初始化呢 ?
这么初始化是为了保证训练的开始旁路矩阵依然是 0 矩阵,对预训练的参数没有影响。如果 B 初始化为全 0 ,则初始的时候参数的改变量 W' 为 0 ,意味着模型的权重并没有发生任何变化,仍然是原始权重。随着训练的进行, B 的梯度 会逐渐更新,最终学得有意义的权重调整。因此,B 初始化为 0 不会阻碍训练,因为它仍然可以从梯度中学习到非 0 的值。
如果 A 初始化为全 0 ,则 A 的梯度 为 0 ,A 无法更新,导致模型的训练停滞,权重无法学到有意义的调整。
如果 B ,A 全部都初始化为 0 ,那么缺点与深度网络全 0 初始化一样,很容易导致梯度消失(因为此时初始所有神经元的功能都是等价的);如果 B ,A 全部都高斯初始化,那么在网络训练刚开始就会有概率为得到一个过大的偏移值 W' 从而引入太多噪声,导致难以收敛。
LoRA 作用的参数矩阵对比
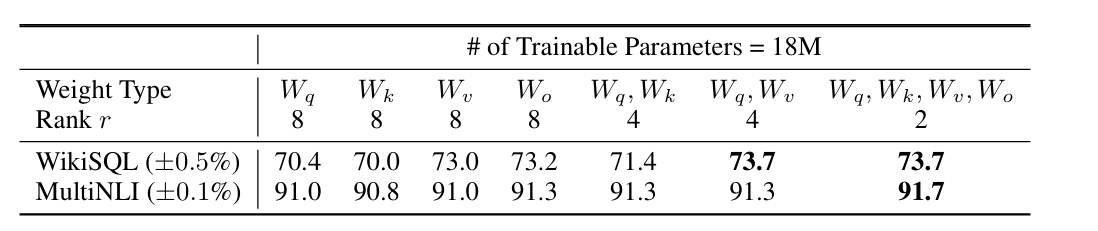
如图可看出,将所有微调参数都放到 attention 的某一个参数矩阵的效果并不好,将可微调参数平均分配到 W_q 和 W_v 的效果最好。
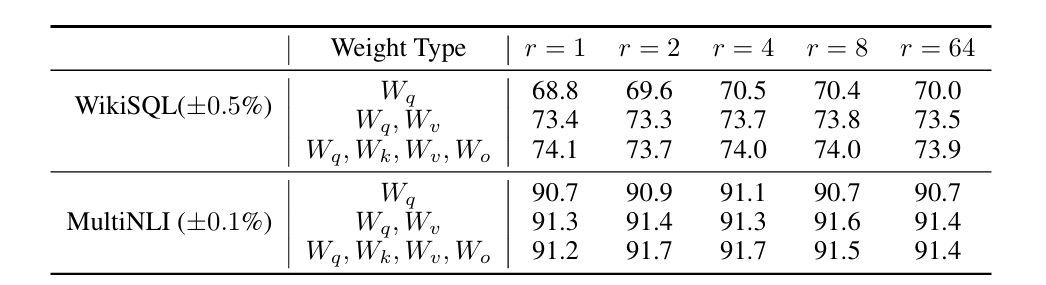
秩的选取:对于一般的任务,r 为 1,2,4,8 足矣,而对于一些领域差距比较大的任务可能需要更大的 rank 。在秩小到 1 或者 2 的时候,LoRA 仍有不错的效果,因此更新参数矩阵可能拥有极小的内在秩。
LoRA 常见问题总结
LoRA 微调的优点是什么?
- 一个中心模型服务多个下游任务,节省参数存储量
- 推理阶段不引入额外计算量
- 与其他参数高效微调方法正交,可有效组合
- 训练任务比较稳定,效果比较好
- LoRA 几乎不添加任何推理延迟,因为适配器权重可以与基本模型合并
- 效果好,可插拔,不引入额外的推理延时
其中,高效微调的原理为:在微调模型的过程中加载预训练参数 进行初始化,并通过 FT(Fine-Tuning微调)的优化目标最大化语言模型概率更新,得到参数
。这样微调方式的主要缺点是得到的增量参数
和初始化参数的维度是一致的,称为全量微调,需要大量资源。高效微调则是用更少的参数表示上述需要学到的参数增量,相当于只微调一部分参数。
LoRA 微调方法为什么能加速训练?
- 只更新了部分参数:比如 LoRA 原论文只更新 Self Attention 参数,实际使用时我们还可以选择只更新部分层的参数
- 减少了通信时间: 由于更新的参数量变少了,所以要传输的数据量也变少了(尤其是多卡训练时),从而减少了传输时间
- 采用了各种低精度加速技术,如 FP16、FP8 或者 INT 8 量化等。
这三部分原因确实能加快训练速度,然而并不是 LoRA 所独有的,事实上几乎所有参数高效方法都具有这些特点。 LoRA 的优点是它的低秩分解很直观,在不少场景下跟全量微调的效果一致,以及在预测阶段不增加推理成本。
LoRA 微调的缺点是什么?
- 参与训练的模型参数量不多,也就百万到千万级别的参数量,效果可能比全量微调差很多
- 在某些情况下,LoRA 插件的加入可能会影响训练过程的稳定性。尽管 LoRA 层并不会直接修改模型的原始参数,但在训练过程中,低秩矩阵的加入可能会引发梯度问题(如梯度爆炸或消失),尤其是在较大规模模型或非常复杂的任务上
- 潜在的过拟合风险,LoRA 在模型中添加了额外的参数,特别是低秩矩阵 A 和 B,这些参数需要根据任务特定数据进行训练。如果训练数据量较少或质量较差,可能会导致 LoRA 模型过拟合于特定任务。基础模型的泛化能力可能因此受到影响,尤其是在没有足够的数据进行微调时

















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









