







论文:A Survey of Neural Code Intelligence: Paradigms, Advances and Beyond
地址:GitHub:https://github.com/QiushiSun/NCISurvey
文章目录
1.神经语言建模(Neural Language Modeling)时代
神经代码智能(Neural Code Intelligence),即利用深度学习理解、生成和优化代码,正展现出其对人工智能领域变革性的影响。作为连接自然语言与编程语言的桥梁,这一领域不论是从论文数量上还是应用上,在过去几年里已经极大吸引了研究界/工业界的关注。这篇综述论文按领域发展的时间顺序,系统性地回顾了代码智能领域的进步,囊括了超过50个代表性模型及其变种、超过20个类别的代码任务,以及覆盖了超过680项相关工作。本文遵循历史发展脉络,追溯了不同研究阶段的范式转变(例如,从利用RNN建模代码到LLM时代)。同时,本综述也从模型、任务、评测和应用等方面梳理不同阶段的主要学习范式转移。在应用层面,代码智能从最初聚焦于解决特定场景的尝试开始,经历了在其快速扩展期间探索多样化任务的阶段,到目前专注于应对越来越复杂和多样化的现实世界挑战。
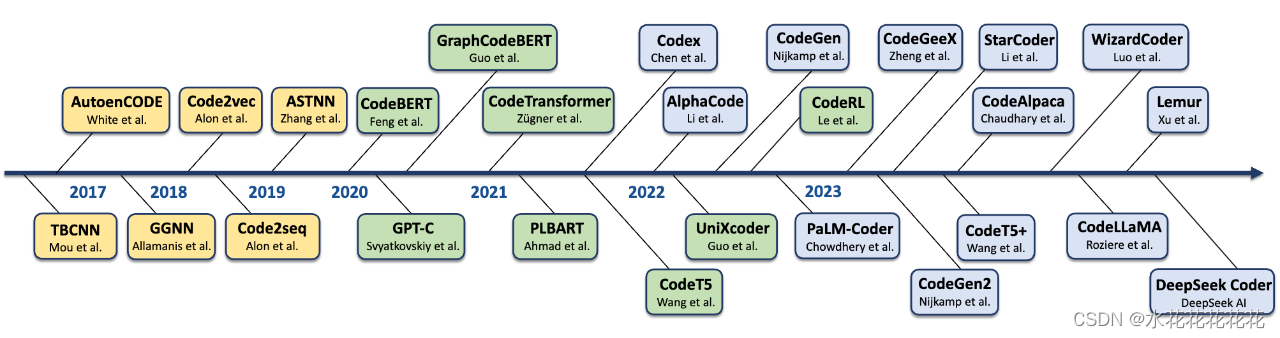
一、代码模型的发展
1.神经语言建模(Neural Language Modeling)时代
神经语言建模时期见证了深度学习来处理code的最早期尝试。在这一时期设计的方法主要依赖于成熟的RNN/CNN结构来建模代码。值得注意的是,这些方法不仅利用了代码的文本信息,还将代码结构,如抽象语法树AST/数据流Data flow以及控制流Control flow从代码中提取出来,并融入建模的过程 ,其发展与Semantic parsing紧密相连。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2148
2148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









