






目录
Topsis简介
TOPSIS算法(Technique for Order Preference by Similarity to Ideal Solution)可翻译为逼近理想解排序法,国内常简称为优劣解距离法。TOPSIS 法是一种常用的综合评价方法,其能充分利用原始数据信息,其结果能精确地反映各评价方案之间的差距。
模型分类与转化
X=[xij]m×n;m为评价对象,n为评价指标;
下面是对评价指标的四种分类:极大型(越大越好),极小型,中间型(某点最优),区间最优型
为方便处理,统一转化为极大型来解决
极小转化为极大型
max-x;若对象均为正数,也可使用1/x
中间最优型转极大值
M=max{|xi-xbest|}, x_i=1-|xi-xbest|/M
区间最优[a,b]转极大型
M=max{a-min(xi),b-max{xi}},x_i=
1-(a-xi)/M x<a
1 a<=x<=b
1-(xi-b)/M x>b
计算得分并归一化
LSTM算法预测
代码来源:matlab help center deep learning toolbox
数据加载处理
data = chickenpox_dataset;
data = [data{:}];
%序列的前 90% 用于训练,后 10% 用于测试。
numTimeStepsTrain = floor(0.9*numel(data));
dataTrain = data(1:numTimeStepsTrain+1);
dataTest = data(numTimeStepsTrain+1:end);
%% 标准化数据
%为了获得较好的拟合并防止训练发散,将训练数据标准化为具有零均值和单位方差。
mu = mean(dataTrain);
sig = std(dataTrain);
dataTrainStandardized = (dataTrain - mu) / sig;
XTrain = dataTrainStandardized(1:end-1);
YTrain = dataTrainStandardized(2:end);定义和训练LSTM网络
%创建 LSTM 回归网络。指定 LSTM 层有 200 个隐含单元
numFeatures = 1;
numResponses = 1;
numHiddenUnits = 200;
layers = [ ...
sequenceInputLayer(numFeatures)
lstmLayer(numHiddenUnits)
fullyConnectedLayer(numResponses)
regressionLayer];
%指定训练选项。
%防止梯度爆炸,将梯度阈值设置为 1。。
options = trainingOptions('adam', ...
'MaxEpochs',10000, ...
'GradientThreshold',1, ...
'InitialLearnRate',0.0001, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropPeriod',1, ...
'LearnRateDropFactor',1, ...
'Verbose',0, ...
'Plots','training-progress');
%使用 trainNetwork 以指定的训练选项训练 LSTM 网络。
net = trainNetwork(XTrain,YTrain,layers,options);预测并返回误差
%预测将来多个时间步的值,使用predictAndUpdateState函数一次预测一个时间步,并在每次预测时更新网络
%状态。对于每次预测,使用前一次预测作为函数的输入。
%使用与训练数据相同的参数来标准化测试数据。
dataTestStandardized = (dataTest - mu) / sig;
XTest = dataTestStandardized(1:end-1);
%要初始化网络状态,先对训练数据 XTrain 进行预测。
%接下来,使用训练响应的最后一个时间步 YTrain(end) 进行第一次预测。
%循环其余预测并将前一次预测输入到 predictAndUpdateState。
%对于大型数据集合、长序列或大型网络,在 GPU 上进行预测计算通常比在 CPU 上快。
%其他情况下,在 CPU 上进行预测计算通常更快。
%对于单时间步预测,请使用CPU。
%使用 CPU 进行预测,请将 predictAndUpdateState 的 'ExecutionEnvironment' 选项设置为 'cpu'。
net = predictAndUpdateState(net,XTrain);
[net,YPred] = predictAndUpdateState(net,YTrain(end));
numTimeStepsTest = numel(XTest);
for i = 2:numTimeStepsTest
[net,YPred(:,i)] = predictAndUpdateState(net,YPred(:,i-1),'ExecutionEnvironment','cpu');
end
%使用先前计算的参数对预测去标准化。
YPred = sig*YPred + mu;
YTest = dataTest(2:end);
error2=double((YPred-YTest));BP神经网络预测
数据处理
for i=1:488
y(i,1)=data(i+10);
for j=1:10
x(i,j)=data(i+j-1);
end
end
%读取数据
input=x;
output=y;
%训练集,测试集
input_train=input(1:439,:)';
output_train=output(1:439,:)';
input_test=input(440:end,:)';
output_test=output(440:end)';
%数据归一化
[inputn,inputs]=mapminmax(input_train,0,1);%归一化至(0,1)区间
[outputn,outputs]=mapminmax(output_train);
inputn_test=mapminmax('apply',input_test,inputs);%inputs记录映射信息构建BP神经网络并返回预测值与真实值的误差
%构建bp神经网络
net=newff(inputn,outputn,10)
%网络参数
net.trainparam.epochs=10000;%训练次数
net.trainparam.lr=0.0001%学习效率
net.dividefcn='';
%bp神经网络训练
net=train(net,inputn,outputn);
%bp神经网络测试
an=sim(net,inputn_test);%用训练好的模型进行仿真
test_simu=mapminmax('reverse',an,outputs);%预测结果反归一化
error2=test_simu-output_test;%预测值与真实值的误差
利用Topsis算法比较两方案的优劣性
数据处理
正向化与标准化
data=[error1;error2];%中间型指标,0为最优
[m,n]=size(data);
k=size(error1,2);
%正向化
sum=0;
for j=1:n
M=max(abs(data(:,j)));
for i=1:m
data(i,j)=1-abs(data(i,j)-M)/M;
sum=sum+data(i,j)^2;
end
end
%标准化
data=data/sqrt(sum);归一化并计算得分
%这里每一个评价指标等价,无需引入权重矩阵
score=zeros(m,1);
for i=1:m
sum1=0;
sum2=0;
for j=1:n
z1=max(data(:,j));%最大值
z2=min(data(:,j));%最小值
sum1=sum1+(data(i,j)-z1)^2;%与最大值的距离
sum2=sum2+(data(i,j)-z2)^2;%与最小值的距离
s1=sum1^0.5;
s2=sum2^0.5;
score(i)=s2/(s1+s2);
end
end
排序得出结果
关于sort参考matab sort的使用
%排序
[a,b]=sort(score);
[c,d]=sort(b);
disp(d)
score返回值:[0.503574758258623;0.496425241741377]
返回值:2 1 (谁越大序号越大)说明此例中LSTM时序预测略优于BP神经网络预测
附error1与errro2的图像对比:
k=size(error1,2);
x=linspace(1,10,k);
plot(x,error1,x,error2);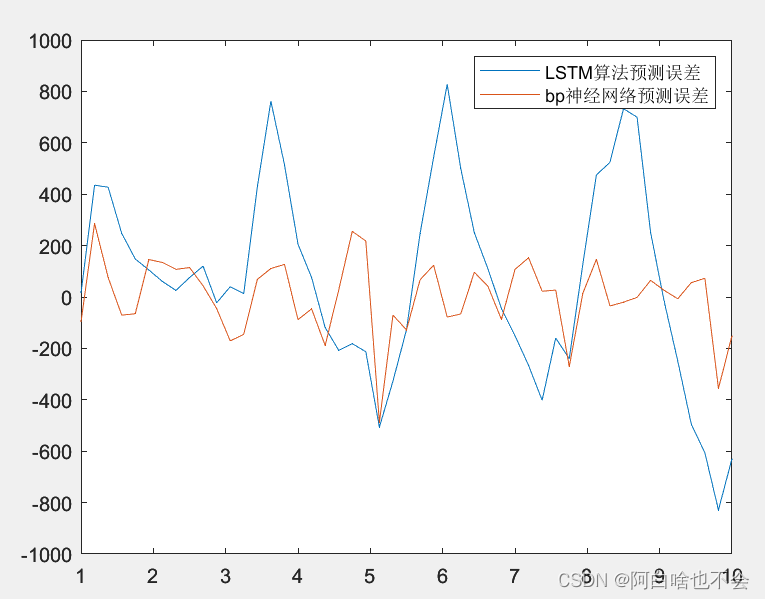
补充说明和疑问
补充:本文中LSTM预测与BP神经网络预测的迭代次数均为10000,学习速率均为0.0001,其中LSTM的程序跑了6分钟左右
LSTM简介
长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式。在标准RNN中,这个重复的结构模块只有一个非常简单的结构,例如一个tanh层。——百度词条LSTM
疑问
由于LSTM的特性,其常被用来预测股票价格的趋势。本文中的例子原data对应的图形与相应代码:
plot(data)
xlabel('Month')
ylabel('Cases')
title('Monthly Cases of Chickenpox')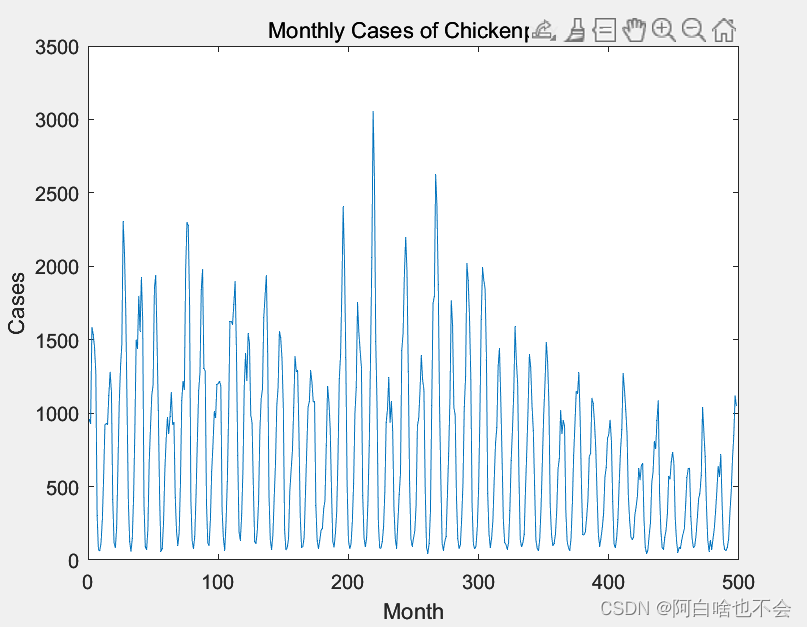
发现它与股票价格走向图有相似之处,但LSTM预测效果并不好,较BP神经网络预测误差区间更大,且由Topsis模型得出LSTM算法在此例中预测效果与BP无明显区别(score非常接近)。
希望得到合理的解释















 1311
1311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











