







七、UART串口通信
(一)实验讲解
uart 模块主要用于驱动开发板上的异步串口,可以自由对 uart 进行配置。
k210 一共有3个 uart,每个 uart 可以进行自由的引脚映射。
例:IO6 —> RX2 IO7 —> TX2
fm.register(6,fm.fpioa.UART2_TX)
fm.register(7,fm.fpioa.UART2_RX)
1.函数调用
(1)构造函数
machine.UART(uart,baudrate,bits,parity,stop,timeout, read_buf_len)
通过指定的参数新建一个 UART 对象
uartUART 号,[UART.UART1~UART3],使用指定的 UART,可以通过machine.UART.按tab键来补全baudrate: UART 波特率bits: UART 数据宽度,支持5/6/7/8(默认的 REPL 使用的串口(UARTHS)只支持 8 位模式), 默认8parity: 奇偶校验位,支持None, 0(偶校验,1(奇校验 )(默认的 REPL 使用的串口(UARTHS)只支持 None), 默认None
MicroPython 的默认 REPL(交互式解释器)使用的串口是 UARTHS,该串口不支持校验位设置。在 MicroPython 中,默认情况下,UARTHS 的校验位被设置为 None。
stop: 停止位, 支持1,1.5,2, 默认1timeout: 串口接收超时时间read_buf_len: 串口接收缓冲,串口通过中断来接收数据,如果缓冲满了,将自动停止数据接收
(2)使用方法
- 读取串口缓冲中的数据
uart.read(num)
num: 读取字节的数量,一般填入缓冲大小,如果缓冲中数据的数量没有 num 大,那么将只返回缓冲中剩余的数据
- 读取串口缓冲数据的一行
uart.readline(num)
num: 读取行的数量
- 使用串口发送数据
uart.write(buf)
buf: 需要发送到数据
- 注销 UART 硬件,释放占用的资源
uart.deinit()
- 获取用于 REPL 的串口对象
repl_uart()
(二)电脑串口助手实现数据收发。
我们可以用一个USB转 TTL工具,配合电脑上位机串口助手来跟 MicroPython开发板模拟通信。
注意要使用3.3V电平的 USB转串口 TTL工具,本实验我们使用 pyBase的外接串口引脚 ,也就是 Y9 TX)和 Y10 RX),接线示意图如下
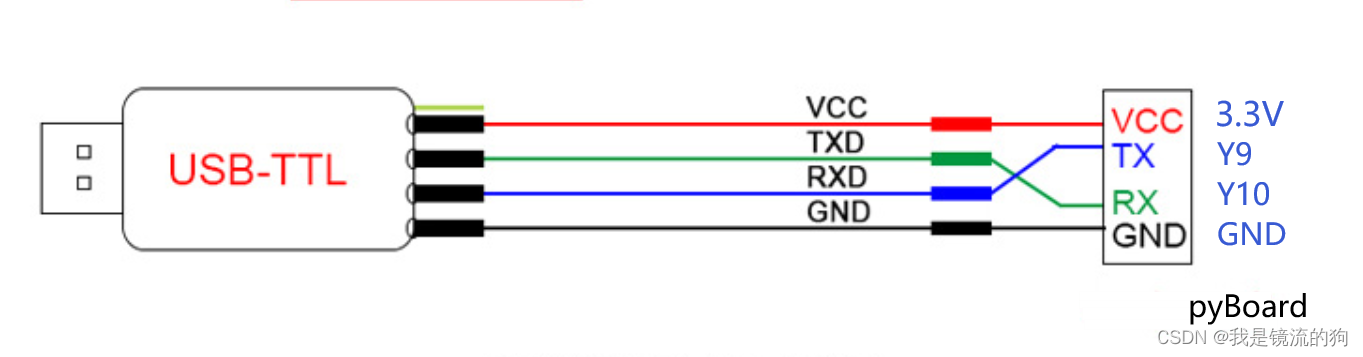
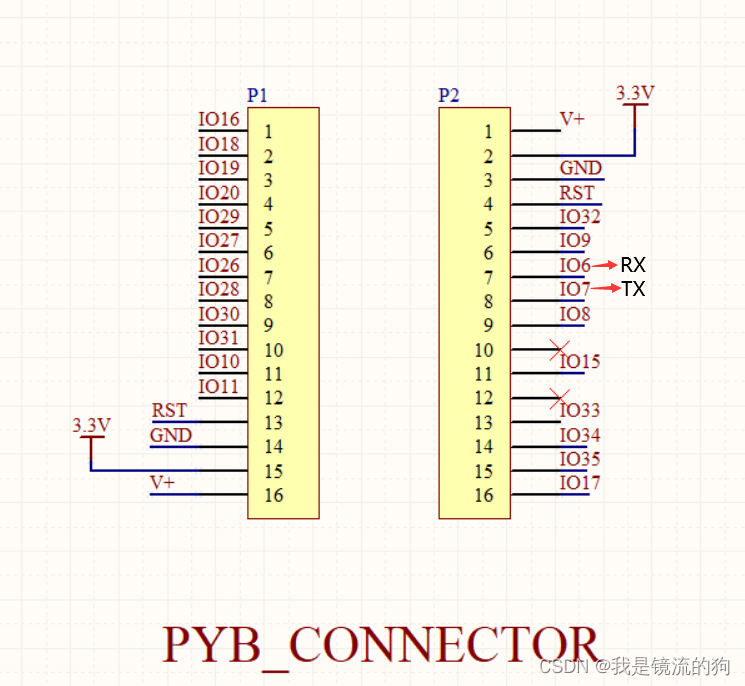
从pyAI-K210原理图可以看到外部 IO6 Y9 RX IO7 Y10 TX。
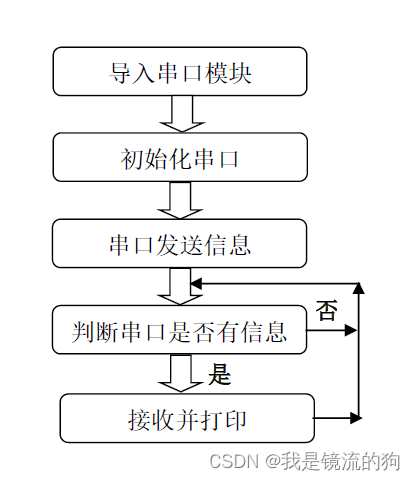
在本实验中我们可以先初始化串口,然后给串口发去一条信息,这样PC机的串口助手就会在接收区显示出来,然后进入循环,当检测到有数据可以接收时候就将数据接收并打印,并通过 REPL打印显示。代码编写流程图如下:
# 引入模块
from machine import UART,Timer
from fpioa_manager import fm
#映射串口引脚
fm.register(6, fm.fpioa.UART1_RX, force=True)
fm.register(7, fm.fpioa.UART1_TX, force=True)
#初始化串口
uart = UART(UART.UART1, 115200, read_buf_len=4096)
uart.write('Hello 01Studio!')
while True:
text=uart.read() #读取数据
if text: #如果读取到了数据
print(text.decode('utf-8')) #REPL打印
uart.write('I got'+text.decode('utf-8')) #数据回传
#用来将字符串 'I got' 和通过解码(decode)将字节数据(byte data)转换为字符串的 text 连接在一起,并通过 UART(通用异步收发传输)发送出去。
补充:decode() 函数
decode() 函数是用于将字节数据解码为字符串的方法。它是字符串对象的一个方法,在Python中常用于处理以特定编码方式编码的字节数据。
在Python 3中,字符串对象被默认视为Unicode字符串(即字符串以UTF-8编码)。当我们从外部源(如文件、网络、传感器等)读取字节数据时,这些数据需要通过解码操作转换为可读的字符串。
decode() 方法的语法如下:
string.decode(encoding)
其中,string 是要解码的字节数据,encoding 是指定的编码方式。常见的编码方式包括 UTF-8、UTF-16、ASCII 等。
例如,如果我们有一段以 UTF-8 编码的字节数据 b'\xe4\xbd\xa0\xe5\xa5\xbd',我们可以使用 decode() 方法将其解码为字符串:
byte_data = b'\xe4\xbd\xa0\xe5\xa5\xbd'
str_data = byte_data.decode('utf-8')
print(str_data) # 输出:你好
通过使用适当的编码方式进行解码,我们可以将字节数据转换为对应的字符串形式,以便于进一步处理和操作。
















 2481
2481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











