






前言
课前回顾了KNN,话说怎么还在讲knn...
正文
模型的偏差和方差还是在讲,简单模型偏差小方差大,复杂的反之.
还是系统再讲一下KNN吧
KNN
所在分类
放上图来吧
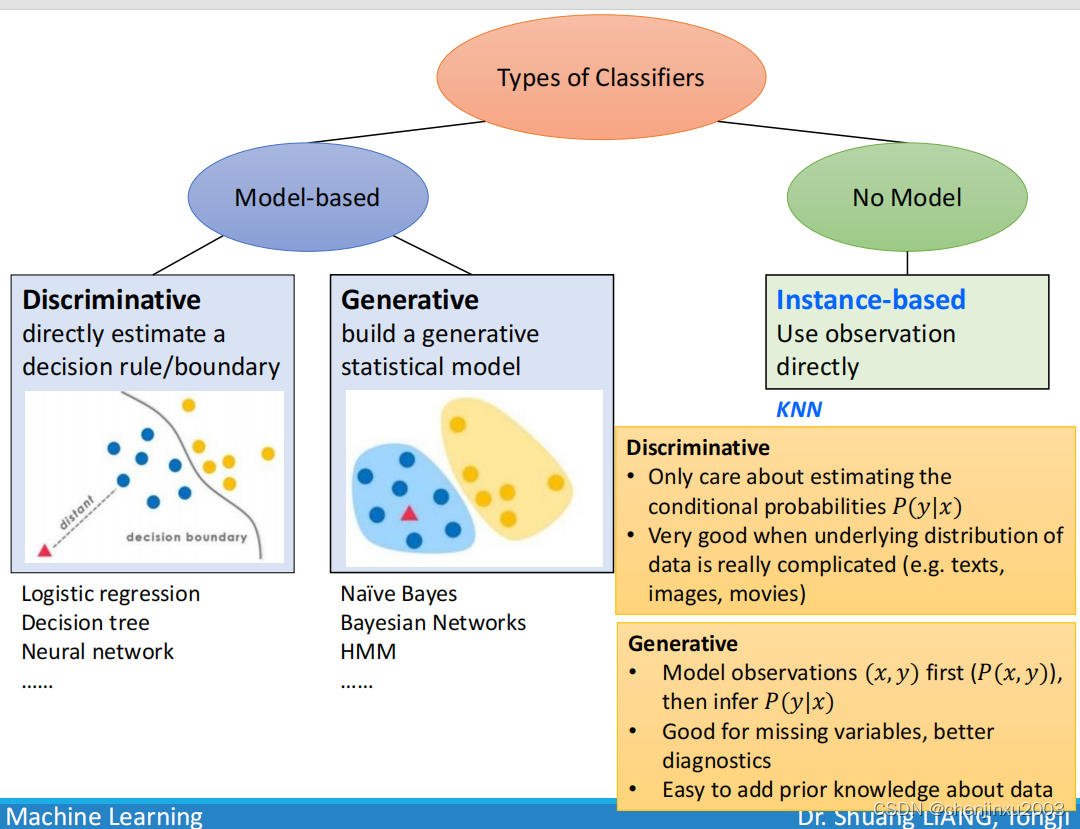
很明显,knn属于物无模型类别的
简单介绍
首先KNN是最常用的分类算法之一,他的思想简单来说就是,根据一个东西周围的东西的类别来判断这个东西本身的类别,换句话来说,KNN 的原理就是当预测一个新的值 x 的时候,根据它距离最近的 K 个点是什么类别来判断 x 属于哪个类别。
第一步:找到最近的点
显然,我们在用KNN算法的时候最重要的一个点就是找到我们需要判断的点附近最近的点,不然我们之后的步骤无法进行

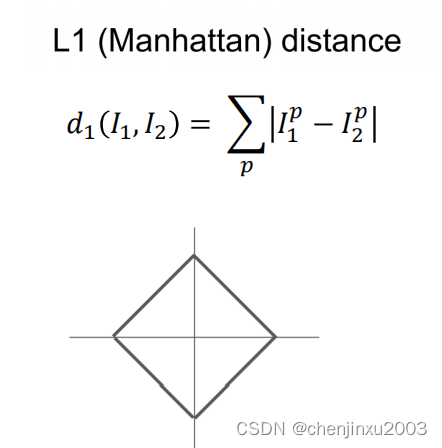
这里就分成了两种:
L1:曼哈顿距离:
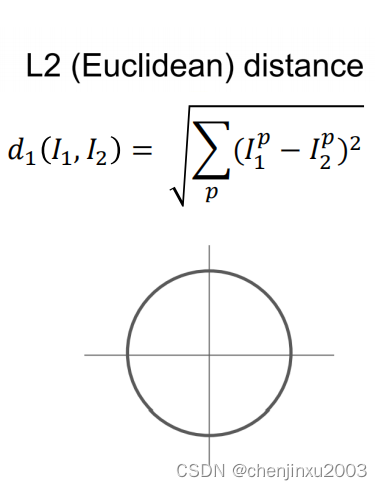
L2:欧式距离:
第二步:选择类别(实际上就是K的取值)
K的取值一般是奇数,因为这样就不会出现平手的情况,然后也不是越大越好,当然也不是越小越好,这点显然,一般来说K的取值在9左右
一点小tips

顺便,别用knn处理图像
决策树
是一种判别式模型,叶节点就是判断的类别,决策树(Decision Tree)是一种常用的机器学习算法,主要用于分类和回归任务。它是一种监督学习算法,通过一系列的规则对数据进行分割,达到分类或者预测的目的。决策树模型具有很好的解释性,易于理解,被广泛应用于数据挖掘、机器学习等领域。
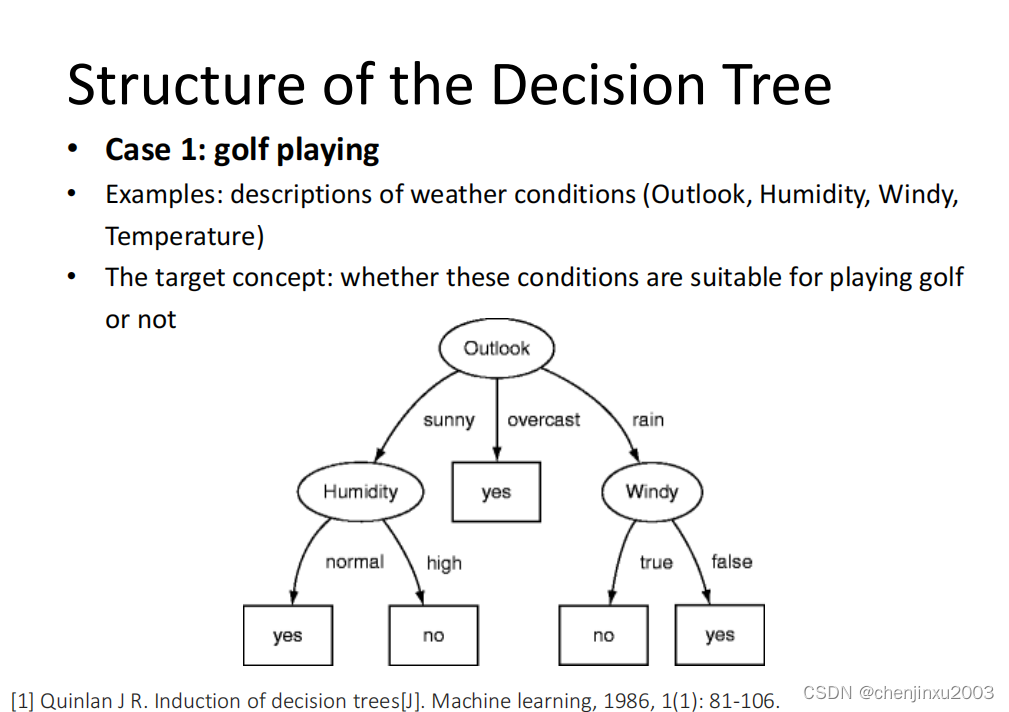
决策树的结构包括以下几个部分:
1. 根节点:包含整个数据集,是决策树的起始点。
2. 内部节点:通常对应于一个特征的测试,它将数据集分割成更小的子集。
3. 叶节点:表示一个类标签,是决策的结果。
4. 分支:连接节点,表示测试的结果。
决策树的主要步骤包括:
1. 特征选择:从训练数据的特征中选择一个特征作为节点的判断标准。
2. 决策树生成:根据特征选择的结果,递归地对数据进行分割,生成决策树。

这里还要引入熵的概念,如图
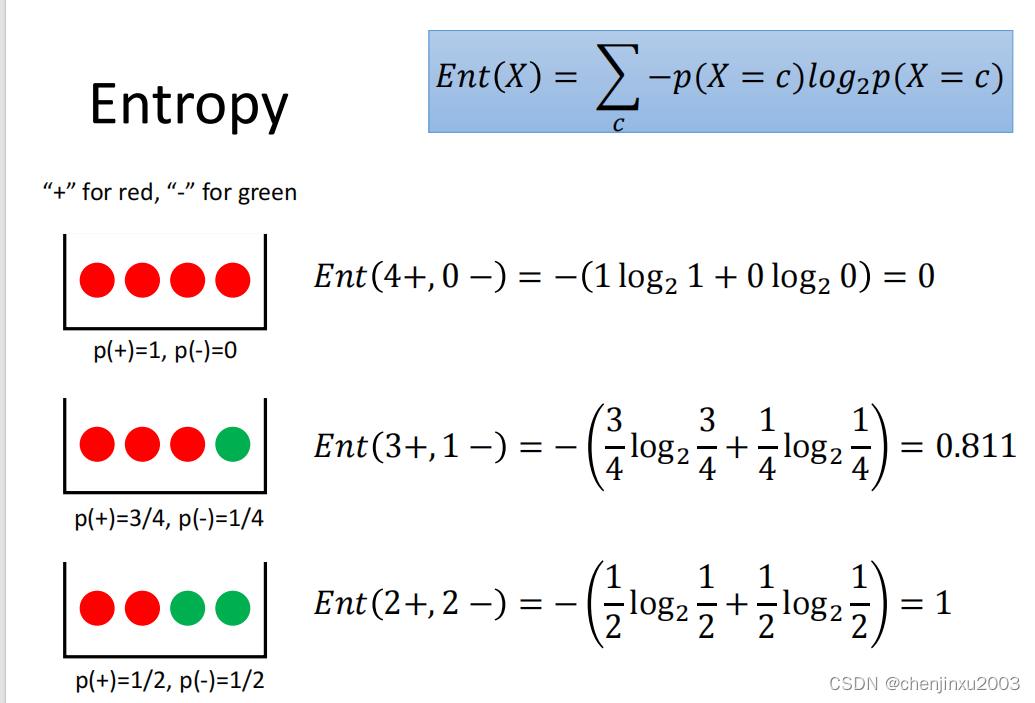
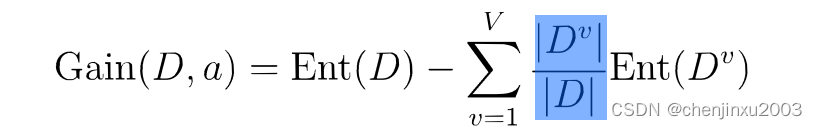
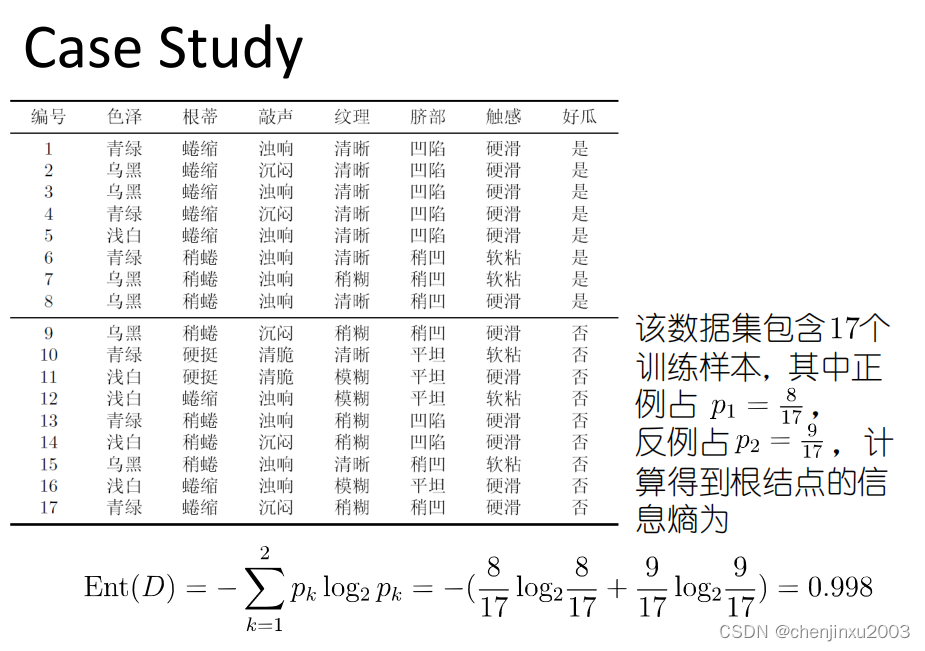
3. 剪枝:为了防止过拟合,需要剪枝来简化决策树模型。剪枝策略主要有预剪枝和后剪枝。
在决策树中,常用的算法有ID3、C4.5和CART。这些算法的主要区别在于特征选择的标准:
- **ID3算法**:使用信息增益作为特征选择的标准。
- **C4.5算法**:使用信息增益率作为特征选择的标准,克服了ID3偏向于选择取值多的特征的不足。
- **CART算法**:使用基尼指数作为特征选择的标准,既可以用于分类也可以用于回归。
决策树的优点包括:
- 易于理解和解释。
- 只需很少的数据准备。
- 能够处理数值型和类别型数据。
- 能够处理多输出问题。
决策树的缺点包括:
- 容易过拟合。
- 对于类别不平衡的数据,决策树可能会产生偏向。
- 决策树的学习能力有限,可能会忽略一些重要的特征关系。
在实际应用中,决策树是一种非常有效的工具,尤其在需要对决策过程进行解释的场合。通过合理的剪枝策略,决策树可以在保持模型简洁的同时,还能具有不错的预测性能。
后记
差不多这样














 1396
1396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









